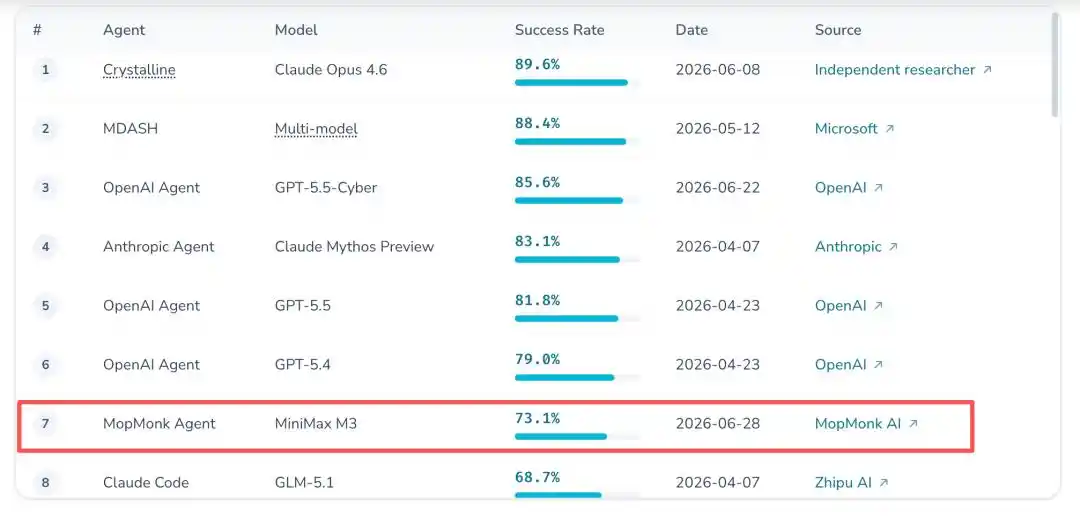
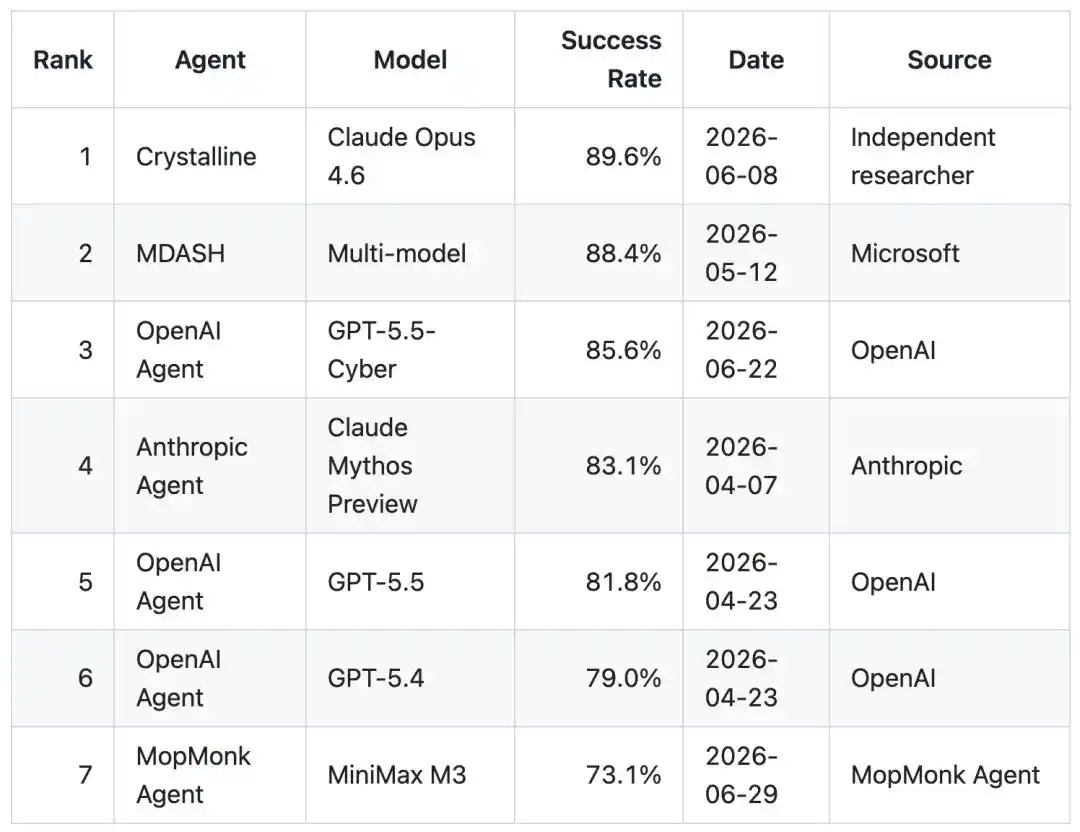
Thật điên rồ! Một AI Trung Quốc bí ẩn không có cả trang web chính thức, với tỷ lệ thắng 73.1% đã lao vào top 7 CyberGym toàn cầu, đuổi sát nút OpenAI. Cả mạng đang truyền tay nhau, đây rốt cuộc là cao thủ của nhà ai?
Mấy ngày nay, trên một bảng xếp hạng nơi các gã khổng lồ AI toàn cầu đang đánh nhau kịch liệt, đột nhiên xuất hiện một cái tên chưa ai từng nghe đến.
Nó tên là MopMonk (Tăng nhân quét đất).
Không có buổi họp báo long trọng, không có bài viết dài trên blog chính thức, không có tiếng trống tiếng chiêng trên mạng xã hội.
Nó cứ thế đột ngột xuất hiện, thẳng tiến xông vào top 10 CyberGym toàn cầu.
Với tỷ lệ thành công 73.1%, cách biệt cực nhỏ so với OpenAI, một lần nữa phá vỡ điểm số cao nhất lịch sử của đội Trung Quốc trên bảng xếp hạng này.
Điều kỳ diệu nhất trong toàn bộ sự việc là cho đến tận hôm nay, không ai biết được chân tướng của nó.
Bảng xếp hạng CyberGym này, quan trọng đến mức nào?
Thành tích lần này của MopMonk rốt cuộc chấn động đến mức nào? Hãy nhìn vào võ đài mà nó đang đứng.
CyberGym, do đội ngũ UC Berkeley dốc sức xây dựng, luận văn cốt lõi được chọn vào hội nghị đỉnh cao ICLR 2026.

Cổng thông tin: https://arxiv.org/pdf/2506.02548
Là một trong những tiêu chuẩn công khai có thẩm quyền nhất trong lĩnh vực đánh giá năng lực an ninh mạng của AI, nơi đây xứng danh là 'La sát trường' của các mô hình lớn —
Ngay cả những ngôi sao đỉnh cao cấp độ như GPT-5.5-Cyber, Claude Mythos, cũng từng sát phạt nhau trên bảng xếp hạng này.
Toàn bộ chuẩn đánh giá tập trung vào 'chân thực như chiến trường':
1507 ví dụ lỗ hổng, 188 dự án lớn mã nguồn mở, tất cả đề thi đều lấy từ những lỗ hổng lịch sử thực tế được Google OSS-Fuzz lắng đọng lại.

Nhìn từ góc độ đánh giá, đây là một bước đột phá vượt cấp.
Quy mô của nó, gấp tới 7.5 lần so với chuẩn công khai lớn nhất trước đó (NYU CTF, khoảng 200 đề), thậm chí còn vượt xa 'tiền bối' như CVE-Bench cả một cấp số.
Càng chết người hơn là độ khó, CyberGym không làm bài trắc nghiệm.
Nó yêu cầu AI phải hoàn thành suy luận sâu trong các dự án thực tế, động là hàng nghìn tệp, hàng triệu dòng mã.
Chính vì đủ lớn, đủ thật, đủ khó, CyberGym mới có được 'tính phân biệt' —
Nó có thể cắt ra từng đường, từng nét sự chênh lệch năng lực thực sự giữa các mô hình khác nhau, giữa các khung Agent khác nhau.
Không trách giới an ninh, trực tiếp phong nó là 'Thế vận hội Olympic của lĩnh vực an ninh AI'.
Cũng chính vì vậy, hầu như tất cả người chơi hàng đầu toàn cầu đều có mặt, Microsoft, OpenAI, Anthropic, Google, Meta, Zhipu......
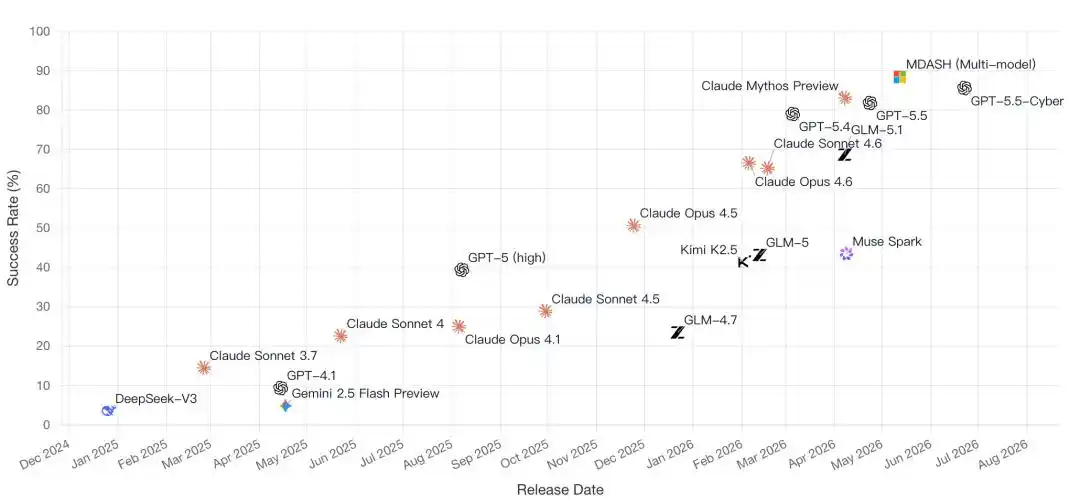
Bản thân bảng xếp hạng CyberGym, đang chứng kiến một sự chuyển hướng then chốt trong cạnh tranh AI:
Từ việc so ai nhiều tham số, chuyển sang so Agent của ai thực sự hoàn thành được công việc.
Một ký hiệu phương Đông xa lạ, đột nhiên xuất hiện giữa các gã khổng lồ AI Thung lũng Silicon
Ai có thể ngờ, chính trên võ đài dựa nhiều nhất vào 'thực lực cứng' này, lại xuất hiện một 'ngựa ô' 'không tra được là ai'.
Gạt bỏ màn sương, tình báo đã nắm được hiện nay của chúng tôi chỉ có ba điều:
Ký hiệu bí ẩn: MopMonk (Tăng nhân quét đất)
Mô hình nền tảng: MiniMax M3
Thành tích bảng xếp hạng: Xông vào top 7 CyberGym toàn cầu, Trung Quốc xếp nhất
Theo lẽ thường, đội ngũ đạt được thành tích như vậy, báo cáo kỹ thuật và họp báo đáng lẽ phải tràn ngập khắp nơi.
Nhưng trên bảng xếp hạng đầy cao thủ này, MopMonk lại là 'dị loại' triệt để nhất: chỉ vứt ra một báo cáo kỹ thuật, đội ngũ, công ty, tọa độ, đều không tra ra là ai.
Sự va chạm giữa 'cấu hình đỉnh cao, thông tin trần trụi' này, bản thân đã chứa đầy kịch tính kiểu võ hiệp phương Đông.
Người quen thuộc Kim Dung, đều hiểu sức nặng của ba chữ 'Tăng nhân quét đất' trong 'Thiên long bát bộ' —
Lão hòa thượng quét mấy chục năm ở Tàng kinh các Thiếu Lâm, không ai nhớ tên, vừa ra tay đã trấn áp được hai đại cao thủ Tiêu Viễn Sơn, Mộ Dung Bác.
Nhân vật kém nổi bật nhất, lại ẩn chứa công phu sâu nhất.

Dám dùng danh hiệu 'Tăng nhân quét đất' đến khiêu chiến, đội ngũ này rõ ràng đối với thực lực của mình, có một sự tự tin cực kỳ lạnh lùng!
Manh mối then chốt hơn, ẩn giấu trong nền tảng kỹ thuật của nó — Mô hình nền tảng MopMonk chọn, là MiniMax M3.
Là một nền tảng mã nguồn mở đến từ Thượng Hải, M3 xứng danh là chiến sĩ lục giác, trực tiếp tập hợp ba vũ khí chủ lực cốt lõi: năng lực lập trình tiên phong, ngữ cảnh siêu dài 1M, và đa phương thức nguyên sinh.
Một bên là 'biểu tượng văn hóa' đậm chất phương Đông, bên kia là nền tảng kỹ thuật mang nhãn hiệu thuần Trung Quốc.
Đặt hai manh mối này lên bàn, phạm vi đã thu hẹp lại rất nhiều. Tất cả đầu mối đều ngầm ám chỉ cùng một kết luận:
Đây phần lớn là một đội Trung Quốc.
Chìa khóa thắng bại, nằm ở Harness
Gạt bỏ bí ẩn thân phận, với tư cách là người theo dõi công nghệ AI lâu dài, chúng tôi càng muốn làm rõ một vấn đề:
MopMonk thắng dựa vào cái gì?
Muốn trả lời câu hỏi này, phải quay lại cái lõi khó nhất của CyberGym — nó kiểm tra căn bản không phải là 'biết hay không', mà là 'làm được hay không'.
Phán đoán một đoạn mã có lỗ hổng hay không, đối với các mô hình lớn ngày nay đã không còn quá khó.
Nhưng CyberGym kiểm tra là bước tiếp theo, cũng là bước chết người nhất: tạo ra một đầu vào có thể kích hoạt lỗ hổng, tức là PoC.
Nó phải kích hoạt được trên 'phiên bản có lỗ hổng', thất bại trên 'phiên bản đã sửa', và thông qua xác minh thực thi của môi trường chuẩn.
Rào cản này, khó khăn hơn tưởng tượng rất nhiều.
Điều kiện kích hoạt lỗ hổng, thường rải rác giữa đường dẫn mã, logic phân tích, môi trường xây dựng, harness kiểm thử và định dạng đầu vào, phải từng chút một ghép lại.
Càng hố hơn là, cho dù PoC chạy sập chương trình ở local, cũng chưa chắc tính. Chỉ cần không thỏa mãn phán định vi sai 'kích hoạt ở bản lỗi, không kích hoạt ở bản sửa', vẫn tốn công vô ích.
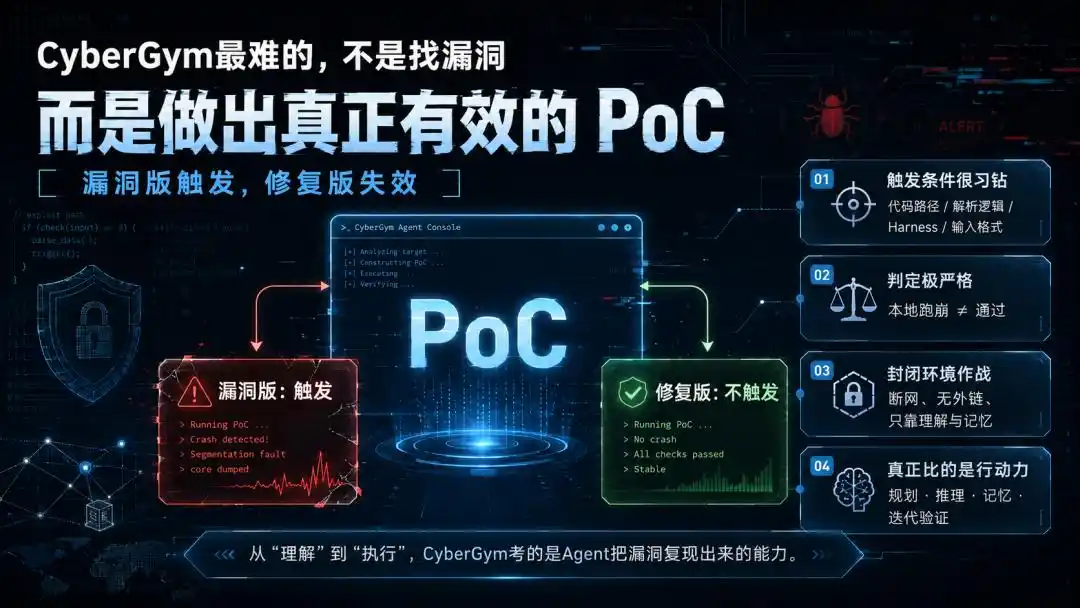
Bước này, kéo nhiệm vụ từ 'hiểu' hoàn toàn vào 'thực thi'. Và là một loại thực thi rất đặc biệt —
Toàn bộ kỳ thi, diễn ra trong một môi trường khép kín, ngắt mạng.
Không có tìm kiếm bên ngoài để cầu cứu, không có bất kỳ 'tài nguyên ngoài trường' nào, AI có thể dựa vào, chỉ có hiểu biết về kho mã trước mắt, và ký ức nó tự tích lũy từng bước.
Trong điều kiện như vậy mà 'tái hiện' được lỗ hổng, dựa vào một bộ năng lực xâu chuỗi với nhau:
Quy hoạch gọi công cụ: khi nào cần đọc tệp, khi nào cần chạy kiểm thử, khi nào cần quay đầu sửa phương án;
Suy luận nhiều vòng: lần trước không kích hoạt, rốt cuộc vấn đề ở đâu, lần sau nên điều chỉnh thế nào;
Quản lý bộ nhớ: lưu lại mã đã đọc, đầu vào đã thử, hố đã vấp một cách có cấu trúc, chứ không phải mỗi vòng lại đọc lại từ đầu;
Xác minh lặp: từng bước tiến gần điểm tới hạn đó, cho đến khi lỗ hổng thực sự được tái hiện.
Nói cách khác, cốt lõi đấu tranh của CyberGym, là 'năng lực hành động' của Agent, 'chỉ số thông minh' của mô hình chỉ là vé vào cửa.
Mà mắt xích then chốt biến 'thông minh' thành 'năng lực hành động', chính là từ bị đánh giá thấp nhất trong toàn bộ lĩnh vực Agent ngày nay — Harness.
Harness, là 'tầng điều phối' giữa mô hình với công cụ bên ngoài, môi trường thực thi.
Nó chịu trách nhiệm sắp xếp công cụ, quản lý trạng thái ngữ cảnh, thu hồi và cấp lại phản hồi thực thi.
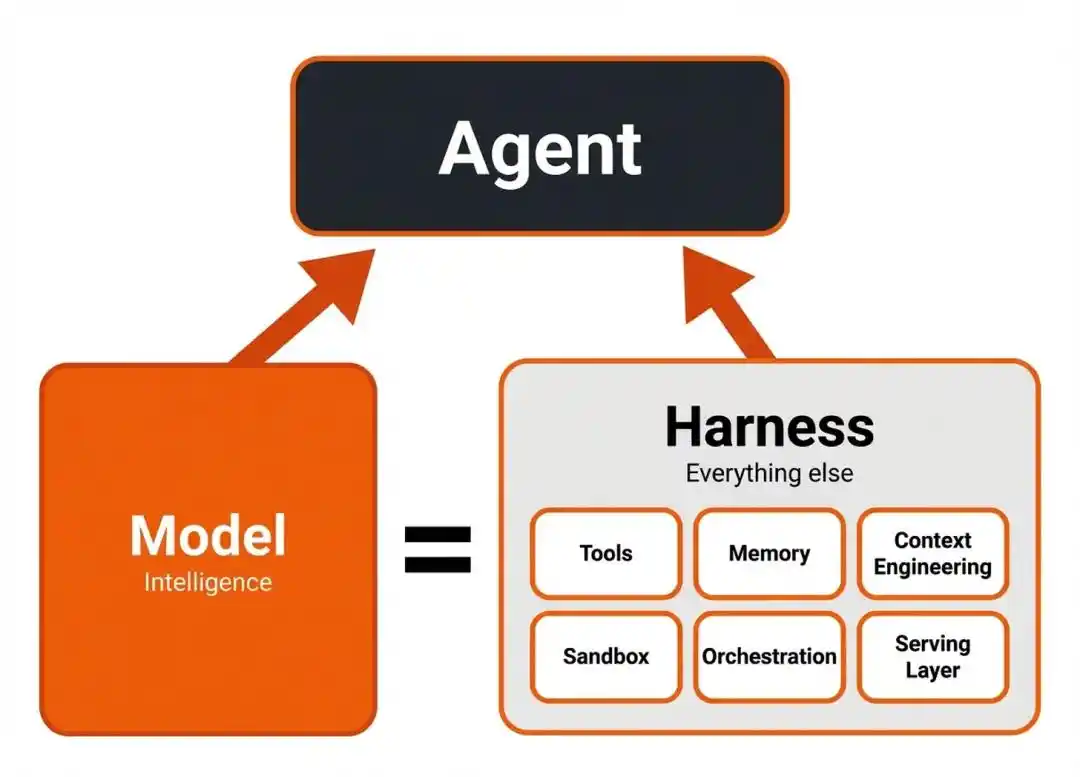
Nói đơn giản, mô hình là bộ não, chịu trách nhiệm suy nghĩ 'lỗ hổng có thể ở đâu, bước tiếp theo nên đào thế nào'.
Harness là chân tay cộng hệ thần kinh, chịu trách nhiệm biến ý nghĩ của bộ não thành một loạt động tác thực tế —
Mở tệp nào, chạy lệnh nào, nhận báo lỗi rồi điều chỉnh thế nào, vòng trước thất bại vòng sau sửa thế nào.
Trên nhiệm vụ như CyberGym, phải chạy vài chục đến hàng trăm vòng, phải thử sai đi thử lại trong hàng triệu dòng mã, Harness tốt xấu, trực tiếp quyết định chỉ số thông minh của mô hình có thể chuyển hóa thành sức chiến đấu hay không.
Một mô hình thông minh + một Harness tầm thường, kết quả thường là 'nghĩ được, làm không được';
Một mô hình năng lực vững chắc + một Harness mạnh được thiết kế riêng cho đào lỗ hổng, mới có thể chạy ra thành tích trên nhiệm vụ dài hạn như vậy.
Agent 'đo ni đóng giàu' cho đào lỗ hổng
Ngày nay, thông qua báo cáo kỹ thuật GitHub, mạch kỹ thuật của MopMonk, đã rõ ràng:
Một hệ thống đa Agent an ninh mới được thiết kế riêng cho đào lỗ hổng, mà nền tảng tư duy hỗ trợ vận hành, chính là MiniMax M3.

Địa chỉ GitHub: https://github.com/MopMonkAI/MopMonkAgent
Như đã nói, M3 là mô hình mã nguồn mở hiếm có hiện nay, có thể tập hợp năng lực mã hóa đỉnh cao, ngữ cảnh triệu token cùng đa phương thức nguyên sinh trong một kiến trúc duy nhất.
Nhìn qua điểm chạy là hiểu: SWE-Bench Pro chiếm 59.0%, Terminal-Bench 2.1 đạt 66.0%, MCP Atlas đạt 74.2% —
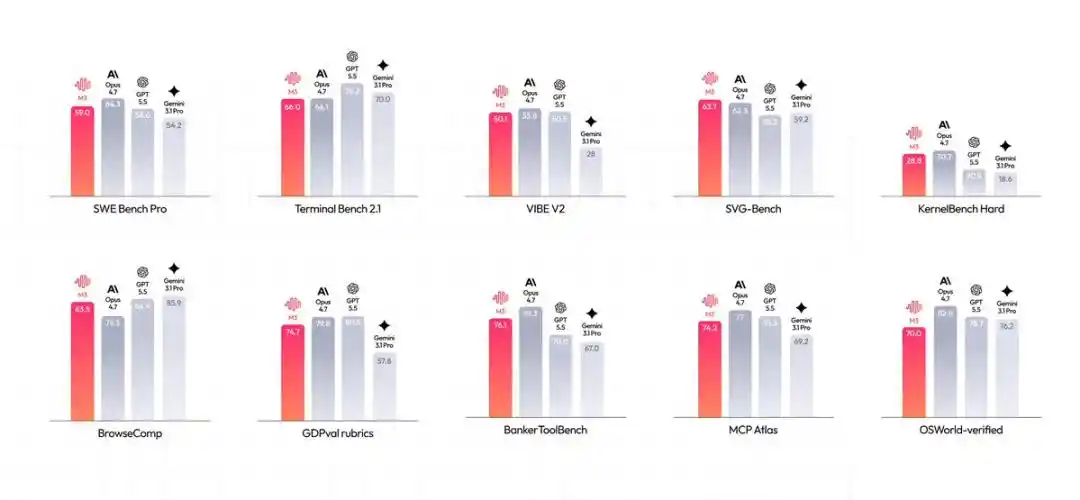
Những con số sáng giá này, đạp trúng nhu cầu cứng rắn nhất khi Agent bước vào chiến trường thực chiến.
Hơn nữa, nó còn có thể tự lặp, tự sửa lỗi trong nhiệm vụ dài đến mười mấy tiếng.
Nói cách khác, M3 đóng vai trò 'bộ não mạnh nhất' vừa có năng lực phân tích mã đỉnh cao, trí nhớ siêu dài, vừa thành thạo gọi công cụ.
Đối với nhiệm vụ như CyberGym, động là phải nuốt cả kho mã, chạy vài chục vòng, cửa sổ ngữ cảnh 1M gần như là nhu cầu bắt buộc.
Mà khung Agent an ninh MopMonk này làm, là khuếch đại năng lực của bộ não M3 thành năng lực thực thi đào lỗ hổng.
'Nội công tâm pháp' của nó, nhìn từ chi tiết kỹ thuật công khai trên GitHub, cốt lõi là ba chiêu —
Chiêu thứ nhất, 'bộ nhớ lỗ hổng' có cấu trúc.
Nó không đơn giản xếp chồng lịch sử trò chuyện, cũng không nhồi ngữ cảnh siêu dài một lần cho mô hình, mà là tổ chức một 'bộ nhớ sự thật nhiệm vụ' có thể cập nhật bền vững, xoay quanh mấy loại đối tượng then chốt nhất trong đào lỗ hổng:
Mục tiêu lỗ hổng, đường dẫn mã, định dạng đầu vào, PoC ứng viên, bằng chứng thất bại, trạng thái xác minh, và bộ nhớ 'ràng buộc bước tiếp theo'.
Loại cuối cùng càng thấy công lực: nó không sinh ra kế hoạch trừu tượng chung chung, mà trực tiếp từ bằng chứng hiện tại, tinh luyện ra ràng buộc cứng bắt buộc phải thỏa mãn cho lần thử nghiệm tiếp theo.
Ví dụ, 'lần này phải bao phủ nhánh đó', 'nên điều chỉnh trường nào', 'cần loại trừ nguyên nhân thất bại loại nào'.
Thiết kế bộ nhớ như vậy, biến việc đào lỗ hổng từ 'thử sai lặp lại từ đầu' thành 'quá trình hội tụ dựa trên bằng chứng'.
Mỗi lần đọc mã, mỗi kết quả thực thi, mỗi lần gửi thất bại, đều được chuyển hóa thành ràng buộc có thể tái sử dụng cho lần sinh PoC tiếp theo.

Chiêu thứ hai, 'đào lỗ hổng' được điều khiển bởi bộ nhớ.
Trong nhiệm vụ đào lỗ hổng, hệ thống đầu tiên thông qua quét kho mã, và lấy đường dẫn kích hoạt ứng viên cùng thông tin thư mục làm điểm khởi đầu quy hoạch, để khởi tạo bộ nhớ lỗ hổng.
Sau đó, nó từng bước tiến lên, cố gắng hội tụ đến vị trí mã cụ thể kích hoạt sập.
Sau đó, mỗi lần thử khám phá đều sẽ đọc bộ nhớ hiện tại, kiểm thử một giả thuyết cụ thể, và ghi kết quả trở lại bộ nhớ.
Như vậy, mô hình không cần mỗi vòng đều đọc lại toàn bộ nhiệm vụ từ đầu, mà từ bộ nhớ có cấu trúc này, điều chính xác ra mảnh bằng chứng liên quan nhất tại thời điểm đó —
Vừa giảm mạnh gánh nặng ngữ cảnh dài, lại vừa khiến mỗi lần biến dị của PoC ứng viên, đều có thể kế thừa kiến thức về đường dẫn mã và định dạng đầu vào tích lũy trước đó, khiến tìm kiếm càng thu hẹp càng chuẩn.
Trong ngân sách khám phá nghiêm ngặt, thời gian do đó được dành hết sức có thể cho 'giả thuyết mới', mật độ thử nghiệm hiệu quả tăng thẳng đứng.
Chiêu thứ ba, 'khám phá song song đa Agent' dưới bộ nhớ chia sẻ.
Nhiều lần thử khám phá, chia sẻ cùng một bộ nhớ lỗ hổng, có thể từ đầu mối bản vá, lối vào harness, trường định dạng tệp, loại sanitizer, điều kiện biên giới... tiến lên đồng thời, và kế thừa lẫn nhau kinh nghiệm thất bại cùng kết quả xác minh.
Điều này vừa mở rộng phạm vi bao phủ, lại tránh được khám phá lặp vô hiệu.
Như vậy có thể thấy, MopMonk đã biến việc tái hiện lỗ hổng, từ một cuộc thử sai lặp lại mở, thành một quá trình 'có thể tích lũy, có thể ràng buộc, có thể xác minh' cập nhật bộ nhớ.
Ba chiêu hợp nhất, hoàn toàn dựa vào 'nội công' lắng đọng, tinh luyện, tái sử dụng từng chút trong nhiệm vụ, đã biến một nền tảng mã nguồn mở mạnh mẽ, điều động thành binh sĩ đặc chủng trên chiến trường đào lỗ hổng.
Cuối cùng, nó chạy ra tỷ lệ thành công 73.1%.
Nền tảng chịu trách nhiệm 'nghĩ sâu', Harness chịu trách nhiệm 'nhớ chắc, điều chuẩn, đánh vững'.
Hai bên kết hợp sâu, cuối cùng mới đúc nên thành tích đột phá đáng chú ý trên bảng xếp hạng.
Một phán đoán có giá trị hơn 'chất đống tham số'
Chân chính gợi mở của sự việc này là —
Mấy năm qua, quán tính của ngành là 'chất đống tham số': tham số càng lớn, mô hình càng mạnh, bảng xếp hạng càng cao.
Nhưng nhiệm vụ tấn công phòng thủ thực tế như CyberGym đưa ra một đáp án khác: quyết định thắng bại, ngày càng là năng lực thực thi của Agent, là độ dày của tầng kỹ thuật Harness này.
Theo báo cáo kỹ thuật GitHub, giá trị của phương pháp này rơi vào ba điểm:
Năng lực mô hình nền mạnh mẽ, cung cấp cơ sở tìm kiếm;
Bộ nhớ lỗ hổng có cấu trúc, cung cấp cơ chế hội tụ;
Khám phá đa trí tuệ nhân tạo dưới bộ nhớ chia sẻ, trong ngân sách hữu hạn nâng cao hiệu quả chi phí.
Nền tảng quyết định trần năng lực, còn Harness lấy bộ nhớ làm trung tâm này, quyết định năng lực này cuối cùng có thể đổi được bao nhiêu.
Càng chết người hơn là thuộc tính lãi kép của nó:
Mô hình nền sẽ thay đổi từng đời, hôm nay dùng M3, ngày mai có thể dùng mô hình mã nguồn mở mới hơn.
Nhưng một Harness được mài giũa lặp đi lặp lại bởi chiến trường thực tế, lắng đọng kinh nghiệm tấn công phòng thủ, là tài sản có thể vượt qua lặp nền tảng, tiếp tục sinh lãi kép.
Tóm lại, giá trị lâu dài của MopMonk Harness, có thể còn lớn hơn 'chất đống thêm một lần tham số'.
Đây chính là lý do căn bản khiến nội bộ ngành bắt đầu xem xét nghiêm túc, 'Tăng nhân quét đất' bí ẩn này:
Mọi người muốn xem, không chỉ là nó đạt bao nhiêu điểm, mà là nó chỉ ra một con đường đưa nền tảng mã nguồn mở đến cực hạn.
Vậy, 'Tăng nhân quét đất' rốt cuộc là ai?
Đi một vòng, chúng ta lại quay về vấn đề ban đầu, cũng khiến người ta khó chịu nhất.
MopMonk, rốt cuộc là ai?!
Ghép manh mối lại: Ký hiệu tràn đầy võ hiệp phương Đông + nền tảng MiniMax của công ty Thượng Hải + một thân 'nội công' lĩnh vực an ninh.
Gần như tất cả mũi tên, đều chỉ về cùng một phán đoán: Đây là một công ty an ninh AI đến từ Trung Quốc, rất có thể ở ngay Thượng Hải.
Cũng có người theo góc độ thích ứng hai chiều giữa mô hình nền và Agent, đoán mù nó có liên quan không rời với đội ngũ nguyên sinh mô hình lớn AI.
Các phiên bản suy đoán khác nhau truyền tay nhau trong dân gian, nhưng đến nay không ai có thể tung ra bằng chứng xác thực.
Bạn nghĩ, MopMonk sẽ là cao thủ nhà ai? Bình luận, đợi bạn tiết lộ.
Bài viết này đến từ tài khoản công chúng WeChat "New Zhiyuan", tác giả: ASI Revelation








