Biên tập viên ghi chú: Bài viết này giới thiệu một hệ thống kiến thức cá nhân được xây dựng dựa trên Claude Code và Obsidian, cốt lõi của nó không còn là cách dùng "truy vấn mỗi lần, tìm kiếm tạm thời" trong chế độ RAG truyền thống, mà là nỗ lực để AI liên tục xây dựng và duy trì một kho kiến thức (Wiki) có thể phát triển.
Về cấu trúc, hệ thống này có thể được chia thành ba tầng:
· Thứ nhất, là tầng dữ liệu thô, bao gồm các nguồn đầu vào không thể sửa đổi như ghi chú, bài viết, nội dung chép lại;
· Thứ hai, là kho kiến thức có cấu trúc do AI duy trì, hoàn thành việc tham chiếu chéo và xây dựng mối quan hệ thông qua các cập nhật liên tục;
· Thứ ba, là tầng quy tắc Schema, dùng để quy phạm cách thức tổ chức kiến thức và logic vận hành hệ thống.
Xoay quanh cấu trúc này, hệ thống vận hành thông qua ba thao tác cốt lõi: Ingest (Tiếp nhận), liên tục đưa thông tin bên ngoài vào hệ thống; Query (Truy vấn), thực hiện việc gọi kiến thức tức thời; Lint (Kiểm tra), dùng để kiểm tra tính nhất quán cấu trúc và sửa chữa các vấn đề tiềm ẩn.
Trong cơ chế này, kiến thức không còn dừng lại ở kết quả đối thoại một lần, mà thông qua vòng lặp "ghi vào - sắp xếp - tái sử dụng", dần dần lắng đọng thành tài sản dài hạn có thể tái sử dụng. Tác giả từ đó đề xuất rằng mô hình này khiến kiến thức có hiệu ứng tích lũy giống như "lãi kép": một mặt giảm bớt gánh nặng nhận thức cho cá nhân, mặt khác nâng cao độ chính xác và tính nhất quán ngữ cảnh của đầu ra mô hình.
Tuy nhiên, việc vận hành hiệu quả của hệ thống này cũng dựa trên một tiền đề - đó là đầu vào và bảo trì liên tục. Nếu thiếu sự bổ sung dữ liệu ổn định và cập nhật cấu trúc, "bộ não thứ hai" này sẽ khó hình thành hiệu ứng tích lũy thực sự, và ưu thế của nó cũng sẽ theo đó mà suy yếu.
Dưới đây là nguyên văn:
Claude Code + Obsidian, là bộ đôi AI mạnh mẽ nhất mà tôi từng dùng.
Tôi gần như đã xây dựng được một "bộ não thứ hai AI", đưa tất cả nội dung về suy nghĩ, đọc, viết, nghiên cứu trực tuyến,... của tôi vào đó. Bên trong nó chứa kế hoạch kinh doanh của tôi, tất cả video YouTube tôi đã đăng, các bài viết đã viết, và mọi thứ quan trọng đối với tôi.
Claude Code + Obsidian đã nhanh chóng nổi tiếng trên các nền tảng, và điều đó không phải ngẫu nhiên.
Đối với cá nhân tôi, hệ thống AI này đã giảm bớt đáng kể gánh nặng nhận thức, cho phép tôi tập trung năng lượng vào những việc thực sự quan trọng - cho dù là công việc kinh doanh hay cuộc sống cá nhân.

Hệ thống này trông có vẻ hơi phức tạp, nhưng thực ra việc thiết lập chỉ mất 5 phút. Quan trọng hơn, nó có cơ chế ghi nhớ, sẽ không ngừng tự tối ưu hóa theo thời gian sử dụng.
Tiếp theo, tôi sẽ hướng dẫn bạn từng bước để tái tạo hệ thống "bộ não thứ hai AI" này, nó thực sự có thể nâng cao hiệu suất của bạn một cách thiết thực.
Bạn nên đọc đến cuối bài - tôi sẽ đính kèm một bảng tra cứu nhanh thao tác Claude Code + Obsidian đầy đủ, cùng tất cả tài nguyên được đề cập trong bài (hoàn toàn miễn phí).
Trước khi bắt đầu
Hệ thống này không phải do tôi tự sáng tạo, cảm hứng của nó đến từ một bài đăng Twitter gây bão cách đây vài ngày của Andrej Karpathy về "kho kiến thức LLM".
Đọc thêm: https://x.com/karpathy/status/2039805659525644595
Bài đăng này nhanh chóng trở nên nổi tiếng vì nó cung cấp ý tưởng giải quyết một điểm đau then chốt trong sự phát triển AI hiện tại.
Vấn đề đó là: mỗi khi bạn bắt đầu một cuộc trò chuyện mới, hoặc chuyển sang một công cụ AI mới, bạn đều phải liên tục nhập lại prompt, bổ sung ngữ cảnh, gần như là bắt đầu lại từ đầu.
Và sau khi kết hợp bộ prompt hệ thống này với Obsidian và Claude Code, vấn đề đó có thể được giải quyết triệt để, đồng thời nâng cao đáng kể chất lượng đầu ra của AI.
Hệ thống này vận hành như thế nào?
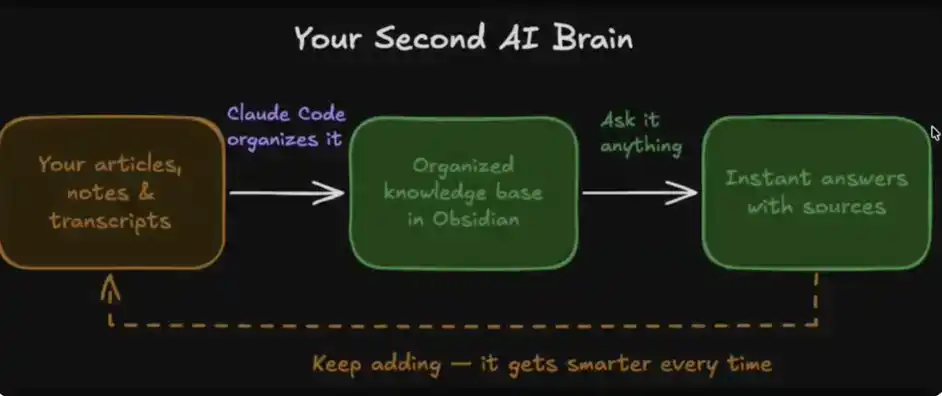
Toàn bộ hệ thống được cấu thành từ bốn mô-đun cốt lõi:
1、Dữ liệu của bạn: bao gồm bài viết, ghi chú, nội dung chép lại, ý tưởng,...
2、Cách thức tổ chức: được Claude Code tự động hoàn thành việc sắp xếp trong Obsidian
3、Gọi tức thời: Bạn có thể hỏi "cơ sở dữ liệu" này bất cứ lúc nào để nhận câu trả lời
4、Trí nhớ tiến hóa: Hệ thống sẽ trở nên thông minh hơn liên tục theo thời gian sử dụng
Sức mạnh thực sự của hệ thống này là gì?
Là con người, băng thông nhận thức của chúng ta là có hạn. Chúng ta sẽ quên, đôi khi cũng khó kết nối các ý tưởng khác nhau, và rốt cuộc thì thông tin có thể theo dõi và xử lý đồng thời là có giới hạn.
Và với sự trợ giúp của hệ thống gồm bốn mô-đun này, bạn thực chất đang giải phóng gánh nặng nhận thức của mình, giao phó công việc "kết nối, sắp xếp và hiểu thông tin" cho Obsidian và Claude Code.
Ý tưởng của bạn bắt đầu được kết nối một cách có hệ thống, một ghi chú có thể tự động liên kết đến một ghi chú khác, và bạn có thể tái trích xuất, kết hợp và gọi những nội dung này thông qua Claude bất cứ lúc nào.
Trong cấu trúc như vậy, kiến thức của bạn không còn rời rạc, mà là một mạng lưới có thể được gọi và tổ chức lại liên tục - hầu như không có giới hạn.
Cách thiết lập bộ não AI của bạn trong 5 phút
1、Tải xuống Obsidian
Trang web chính thức: https://obsidian.md/
2、Tạo Kho (Vault) của bạn
Sau khi tải xuống hoàn tất, Obsidian sẽ nhắc bạn tạo một "Kho" (Vault).
Bạn có thể hiểu nó là một thư mục trên máy tính, chúng ta sẽ lưu trữ tất cả nội dung ở đây và để Claude Code truy cập, quản lý những dữ liệu này.
Tên của Kho này có thể đặt tùy ý - ví dụ bản thân tôi gọi nó là "Obsidian Vault".
Kho này chính là nơi Obsidian dùng để lưu trữ tất cả dữ liệu và ghi chú của bạn, tất cả nội dung sẽ được lưu dưới dạng file MD (Markdown).
3、Thiết lập Claude Code
Tiếp theo, bạn cần cấu hình một cách thức để truy cập Claude Code. Đối với tôi (và rất có thể là đối với hầu hết mọi người), cách đơn giản nhất là sử dụng trực tiếp ứng dụng khách trên desktop.
Trong giao diện trò chuyện chính, nhấp vào "Select Folder (Chọn thư mục)", sau đó tìm đến Obsidian Vault bạn vừa tạo và chọn nó.
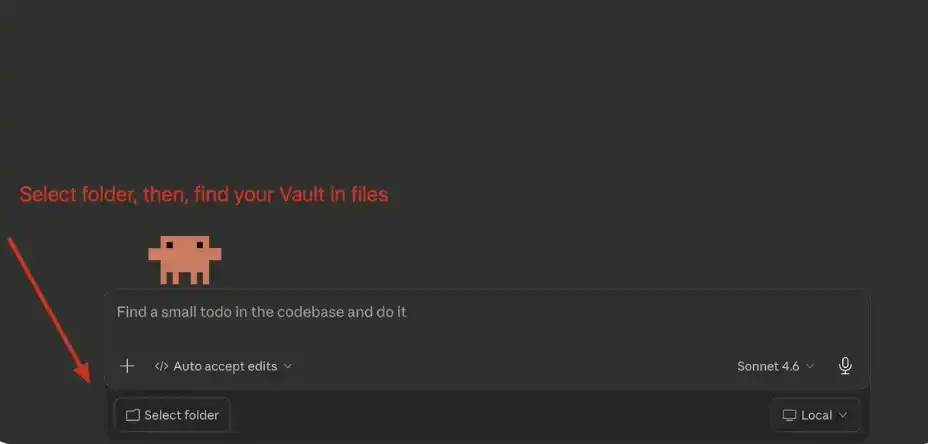
4、Thiết lập Prompt Hệ thống (System Prompt)
Sau khi bạn chọn xong thư mục, bước tiếp theo là dán prompt hệ thống của Andrej Karpathy vào hộp trò chuyện chính.
Bạn có thể sao chép prompt này tại đây: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f

Đầu vào của bạn sẽ như thế này:
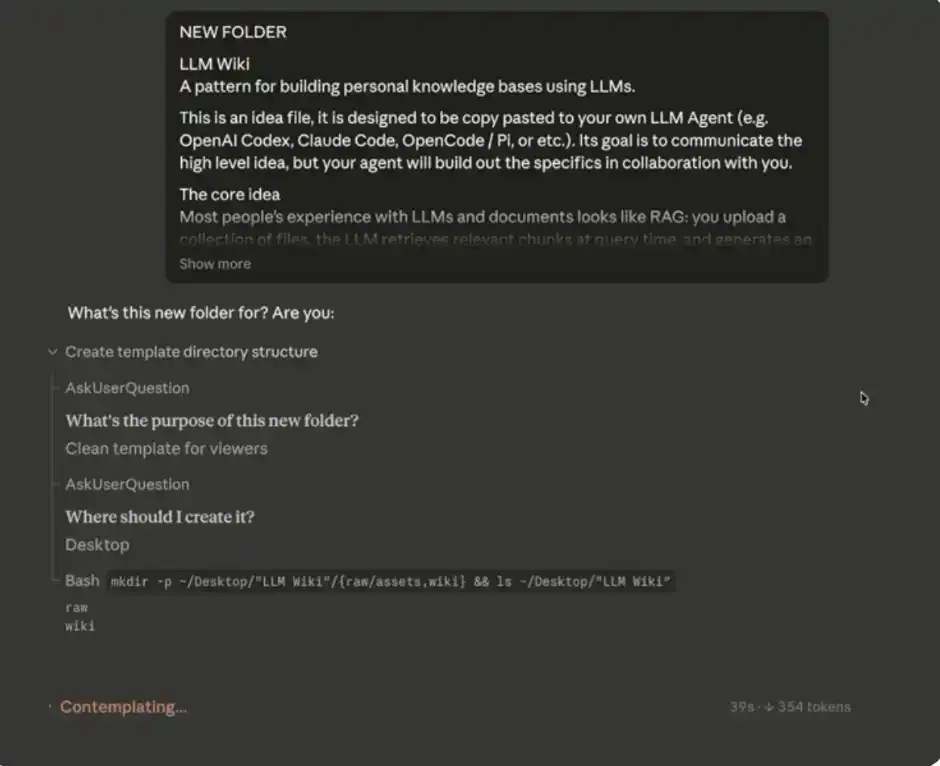
Mẹo nhỏ: Nếu bạn không muốn, cũng hoàn toàn không cần phải mở Obsidian thủ công. Chỉ cần giao thư mục MD (tức là Kho của bạn) và dữ liệu liên quan cho Claude Code, nó có thể trực tiếp đọc, ghi và sửa đổi các file này - và những nội dung này sẽ tự động đồng bộ hóa với "bộ não thứ hai" Obsidian của bạn.
5、Xây dựng cơ sở dữ liệu của bạn
Sau khi bạn nhập xong prompt hệ thống nói trên, Claude Code sẽ bắt đầu hỏi bạn về một số nguồn dữ liệu, dùng để khởi tạo và dần dần lấp đầy "bộ não thứ hai" của bạn.
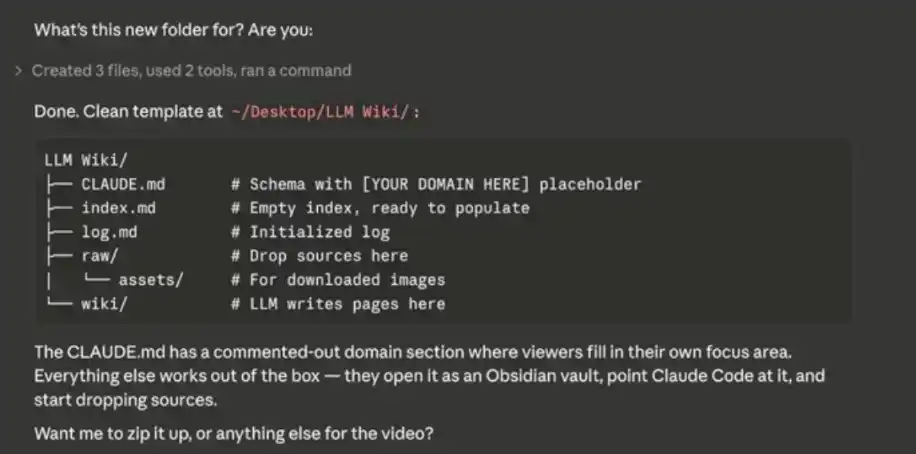
Bạn có thể hình dung Obsidian như một "quyển sổ tay trắng" - lúc đầu cần bạn chủ động nhập nội dung, cơ sở dữ liệu mới dần được xây dựng. Nội dung có thể nhập vào bao gồm: ghi chú, file CSV, file Markdown / văn bản,...
Một số đề xuất hữu ích:
· Xuất dữ liệu từ công cụ ghi chú hiện có của bạn
· Nếu bạn dùng Notion, có thể xuất ra file CSV
· Để Claude (hoặc mô hình lớn khác) sắp xếp một bản thông tin về bạn, dùng để khởi tạo "bộ não thứ hai" của bạn
· Nhập một lần các bài viết, mục đã lưu, ý tưởng,... mà bạn đã có - đây là thời điểm tốt nhất để thiết lập dữ liệu ban đầu, sau này cũng có thể bổ sung bất cứ lúc nào
Cần lưu ý rằng, một cơ sở dữ liệu có lượng dữ liệu lớn như của tôi, không phải là có thể hoàn thành ngay lập tức, mà là được hình thành thông qua việc liên tục nhập vào và tích lũy dần dần theo thời gian.

Vậy là xong, "bộ não thứ hai AI" của bạn đã được thiết lập và có thể bắt đầu chạy. Tiếp theo, tôi sẽ chia sẻ thêm một số mẹo nâng cao để giúp bạn sử dụng nó hiệu quả hơn.
Mẹo nâng cao (Pro Tips)
1、Tiện ích mở rộng Obsidian cho Chrome
Nếu bạn muốn thêm dữ liệu vào hệ thống dễ dàng hơn, chỉ cần cài đặt tiện ích mở rộng Obsidian cho Chrome. Nó cho phép bạn khi duyệt web, chỉ cần nhấp vào "Add to Obsidian (Thêm vào Obsidian)" để lưu nội dung trực tiếp vào kho kiến thức của bạn. Điều này sẽ khiến quá trình xây dựng "bộ não thứ hai" trở nên rất thuận tiện.
Bản thân tôi cũng thường dùng tính năng này để thu thập bài báo, dữ liệu web, tài liệu nghiên cứu,...
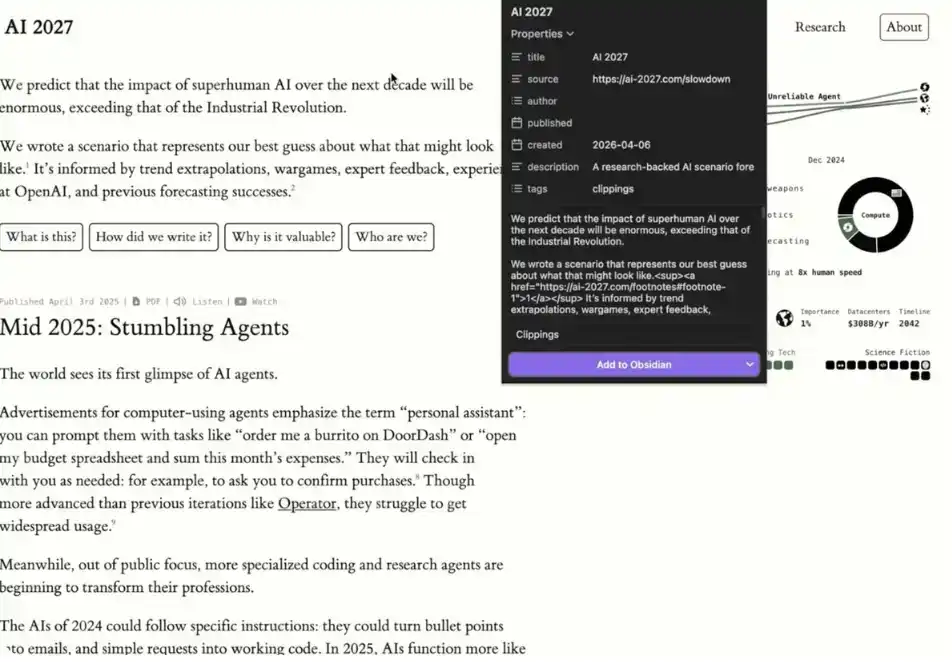
Cần lưu ý rằng, dữ liệu được thêm qua tiện ích mở rộng, ban đầu chỉ là một "nguồn dữ liệu đơn lẻ".
Tiếp theo bạn có thể nói với Claude Code: "Tôi vừa thêm [x] vào Obsidian, hãy giúp tôi tích hợp những nội dung này vào Wiki của tôi."
Claude Code sẽ tự động thiết lập mối liên hệ giữa dữ liệu mới này với nội dung đã có, tạo liên kết, khiến nó thực sự hòa nhập vào "bộ não thứ hai" của bạn. Đây cũng là lý do khiến bộ công cụ này mạnh mẽ.
2、Tách biệt các Kho (Vault)
Andrej Karpathy đề xuất sử dụng hai Kho (Vault) độc lập:
· Một dành cho nội dung công việc / thương mại
· Một dành cho quản lý cuộc sống cá nhân / mục tiêu
Trải nghiệm sử dụng của bản thân tôi cũng vậy, cấu trúc như thế này là rõ ràng và hiệu quả nhất.
3、Tính thực dụng
Tôi phát hiện ra một cách dùng có giá trị nhất của hệ thống này, thực ra rất đơn giản: làm cho prompt LLM của bạn chính xác hơn.
Khi mô hình có thể truy cập đầy đủ thông tin cá nhân, kế hoạch kinh doanh, bối cảnh viết lách,... của bạn, nó có thể tạo ra những prompt được "tùy chỉnh" hơn, gần với tình huống thực tế hơn (thậm chí là "Super Prompt").
Tất nhiên, công dụng của hệ thống này không chỉ có vậy, nhưng nếu bạn chỉ muốn bắt đầu từ một kịch bản thiết thực nhất, tôi sẽ khuyến nghị mạnh mẽ bạn nên bắt đầu từ "nâng cao chất lượng Prompt".
4、Orphans (Nút đơn lẻ)
Trong Obsidian, "Orphans" đề cập đến những điểm dữ liệu chưa được kết nối với các ghi chú khác.
Tính năng này rất hữu ích, vì nó có thể giúp bạn:
· Tìm thấy những ý tưởng chưa được tích hợp
· Phát hiện các "vùng yếu" trong cơ sở dữ liệu
· Đánh giá nội dung nào đáng được mở rộng hoặc đào sâu thêm
Nói cách khác, nó không chỉ là một công cụ sắp xếp, mà còn là một cơ chế giúp bạn phát hiện điểm mù trong suy nghĩ.

Bạn có thể nhấp vào "ba chấm" ở góc trên bên phải, tìm và bật công tắc Orphans, để xem哪些 nội dung chưa thiết lập liên kết.
Nhược điểm tiềm ẩn của hệ thống này
Phía trước chúng ta đã nói nhiều về ưu điểm, kịch bản sử dụng và phương pháp tối ưu hóa, vậy thì thiếu sót của nó là gì? Trường hợp nào bạn không thích hợp để sử dụng hệ thống này?
1、Người không quen với trực quan hóa
Một ưu thế cốt lõi của hệ thống này, là có thể trình bày dữ liệu một cách trực quan. Nếu bản thân bạn không phụ thuộc hoặc không quen với cách thức này, thì sự trợ giúp của nó đối với bạn có thể khá hạn chế.
2、Cần chi phí bảo trì nhất định
Nếu bạn không muốn liên tục bảo trì một cơ sở dữ liệu, thì hệ thống này có thể không phù hợp với bạn. Mặc dù chi phí bảo trì không cao, nhưng nếu không liên tục nhập dữ liệu vào "bộ não thứ hai", nó sẽ khó phát huy giá trị.
3、Chiếm dụng dung lượng lưu trữ
Tất cả nội dung sẽ được lưu trữ cục bộ dưới dạng file Markdown, điều này sẽ chiếm một không gian thiết bị nhất định. Điểm này cũng cần được cân nhắc trước.





