Хотите узнать, какая большая языковая модель действительно сильнее всего в реальных задачах агента OpenClaw?
MyToken на основе сайта с тестами подготовил прозрачный бенчмарк, сфокусированный на оценке практических способностей ИИ-агентов для программирования, рассматривая только одно ключевое измерение — успешность (скорость и стоимость относятся к другим независимым измерениям, которые будут проанализированы отдельно позже). Полностью открытый, воспроизводимый, представляющий только строгие стандарты тестирования + актуальный Топ-10 рейтинг по успешности.
I. Измерение для оценки:Успешность
Конкретный стандарт: доля задач, которые ИИ-агент точно и полностью выполняет. Каждая задача использует высокостандартизированный процесс:
-
Точные пользовательские промпты (Prompt)
Отправляются агенту для имитации реальных сценариев пользовательских запросов
-
Ожидаемое поведение (Expected Behavior)
Указываются приемлемые способы реализации и ключевые моменты принятия решений
-
Критерии оценки (checklist)
Предоставляется атомизированный список критериев успеха для поэтапной проверки
II. Три метода оценки
В этом тестировании в основном используются 3 метода оценки:
-
Автоматическая проверка: Python-скрипты напрямую проверяют объективные результаты, такие как содержимое файлов, записи выполнения, вызовы инструментов
-
Судья LLM-модель: Claude Opus выставляет оценки по подробной шкале (качество контента, уместность, полнота и т.д.)
-
Смешанный режим: сочетание автоматической объективной проверки и качественной оценки судьей LLM
Все определения задач, промпты, логика оценки полностью открыты для повторного тестирования и проверки.
III. Задачи, используемые для оценки
Этот бенчмарк охватывает 23 задачи разных категорий. Охватывает множество измерений: базовое взаимодействие, операции с файлами/кодом, создание контента, исследовательский анализ, вызов системных инструментов, постоянство памяти и другие, что高度 соответствует повседневным сценариям использования OpenClaw разработчиками:
-
Sanity Check(Автоматизация) — Обработка простых инструкций и корректный ответ на приветствие
-
Calendar Event Creation(Автоматизация) — Генерация стандартного ICS-файла календаря на естественном языке
-
Stock Price Research(Автоматизация) — Запрос актуальной цены акций и вывод отформатированного отчета
-
Blog Post Writing(Судья LLM) — Написание структурированного Markdown-блога объемом около 500 слов
- Weather Script Creation(Автоматизация) — Написание Python-скрипта для погодного API с обработкой ошибок
-
Document Summarization(Судья LLM) — 3-этапное сжатое изложение основных тем
-
Tech Conference Research(Судья LLM) — Исследование и систематизация информации о 5 реальных tech-конференциях (название, дата, место, ссылка)
-
Professional Email Drafting(Судья LLM) — Вежливый отказ от встречи с предложением альтернативы
-
Memory Retrieval from Context(Автоматизация) — Точное извлечение дат, участников, технологического стека и т.д. из проектных заметок
-
File Structure Creation(Автоматизация) — Автоматическое создание стандартной структуры проекта, README, .gitignore
-
Multi-step API Workflow(Смешанный) — Чтение конфигурации → Написание скрипта вызова → Полная документация
-
Install ClawdHub Skill(Автоматизация) — Установка из репозитория навыков и проверка работоспособности
-
Search and Install Skill(Автоматизация) — Поиск погодных навыков и корректная установка
-
AI Image Generation(Смешанный) — Генерация и сохранение изображения по описанию
-
Humanize AI-Generated Blog(Судья LLM) — Преобразование машинного контента в естественную разговорную речь
-
Daily Research Summary(Судья LLM) — Синтез связного ежедневного резюме из нескольких документов
-
Email Inbox Triage(Смешанный) — Анализ нескольких писем и составление отчета по степени срочности
-
Email Search and Summarization(Смешанный) — Поиск в архиве писем и извлечение ключевой информации
-
Competitive Market Research(Смешанный) — Анализ конкурентов в области корпоративных APM
-
CSV and Excel Summarization(Смешанный) — Анализ табличных файлов и вывод инсайтов
-
ELI5 PDF Summarization(Судья LLM) — Объяснение технического PDF-файла языком, понятным 5-летнему ребенку
-
OpenClaw Report Comprehension(Автоматизация) — Точный ответ на конкретные вопросы из PDF-отчета исследования
-
Second Brain Knowledge Persistence(Смешанный) — Межсессионное хранение и точное воспроизведение информации
IV. Ключевой вывод: Рейтинг Топ-10 больших моделей по успешности (Лучший %/Средний %)
-
Данные обновлены по состоянию на 7 апреля 2026 года
-
Лучший % — наивысшая единичная успешность, Средний % — средняя успешность за несколько попыток, лучше отражает стабильность
以下是成功率最高的前十模型
-
anthropic/claude-opus-4.6(Anthropic) — 93.3% / 82.0%
-
arcee-ai/trinity-large-thinking(Arcee AI) — 91.9% / 91.9%
-
openai/gpt-5.4(OpenAI) — 90.5% / 81.7%
-
qwen/qwen3.5-27b(Qwen) — 90.0% / 78.5%
-
minimax/minimax-m2.7(MiniMax) — 89.8% / 83.2%
- anthropic/claude-haiku-4.5(Anthropic) — 89.5% / 78.1%
-
qwen/qwen3.5-397b-a17b(Qwen) — 89.1% / 80.4%
-
xiaomi/mimo-v2-flash(Xiaomi) — 88.8% / 70.2%
-
qwen/qwen3.6-plus-preview(Qwen) — 88.6% / 84.0%
-
nvidia/nemotron-3-super-120b-a12b(NVIDIA) — 88.6% / 75.5%
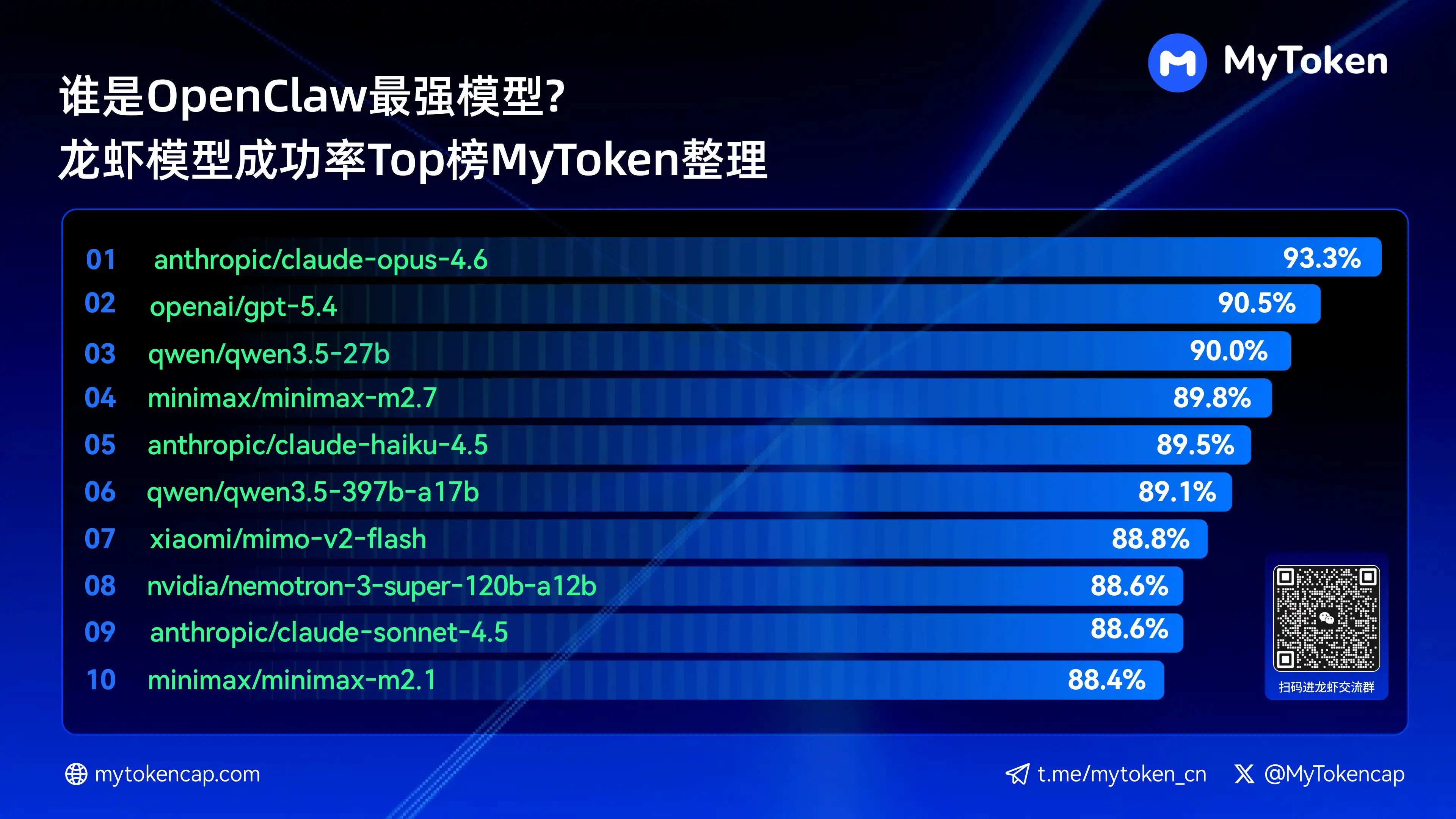
Claude Opus 4.6 в настоящее время лидирует с наивысшей успешностью 93.3%, но Trinity от Arcee демонстрирует впечатляющие результаты по средней стабильности. Серия Qwen также имеет несколько моделей в топ-10, показывая большой потенциал с точки зрения соотношения цены и качества. Успешность — это базовый порог, последующие измерения скорости и стоимости будут further влиять на фактический опыт.
Этот бенчмарк из 23 задач полностью прозрачен, настоятельно рекомендуем протестировать его в соответствии с вашими сценариями. Больше рейтингов других моделей ждите в即将推出的 функции рейтинга агентов от MyToken.
(Данные来源于открытого бенчмарка тестирования агентов OpenClaw от PinchBench, постоянно обновляются.)





