Оригинальная статья | Odaily 星球日报 (@OdailyChina)
Автор | Asher (@Asher_0210)

Самое оживленное место на этом Чемпионате мира — не только на поле.
По мере роста ажиотажа вокруг предсказаний, связанных с турниром, все больше пользователей начинают вкладывать реальные деньги в сделки. Кто победит, какой будет счет, будет ли сенсация, будут ли красные карточки, какой игрок забьет гол — темы, которые раньше были предметом предматчевых споров болельщиков, теперь разбиваются на отдельные прогнозные события, доступные для торговли.
А когда прогноз превращается в сделку, пользователям нужны уже не только эмоции и интуиция: изменения коэффициентов, форма команды, информация о травмах, история противостояний, настроения рынка — все это становится материалом для анализа перед сделкой. В этом процессе модели ИИ все чаще вовлекаются в сценарии прогнозирования результатов матчей ЧМ.
Большие языковые модели, такие как Qwen, ChatGPT, Gemini, Claude, DeepSeek, Qwen и Copilot, могут не только ответить на вопрос "Какая команда с большей вероятностью победит", но и дать прогноз счета, вероятность сенсации, риск удалений, анализ игры ключевых игроков и хода матча. Для участников рынка прогнозов предматчевый анализ ИИ становится еще одним источником информации помимо коэффициентов, новостей, статистики команд и рыночных настроений.
Однако в конечном счете прогноз должен вернуться к самой игре.
С официальным стартом Чемпионата мира результаты первых матчей уже известны. Те анализы от ИИ, которые пользователи использовали для помощи в принятии решений перед играми, наконец можно сравнить с реальностью: попал ли прогнозируемый счет, предвидела ли модель возможную сенсацию, сколько деталей, таких как красные карточки, победные голы на последних минутах и ход игры, действительно было уловлено моделями.
Первой, кто привлек внимание, стал Qwen
Самый эффектный эпизод в первый день чемпионата, несомненно, связан с Qwen.
Перед стартовым матчем Мексика — ЮАР, Qwen дал прогноз: Мексика 2:0 ЮАР. После окончания игры счет действительно оказался 2:0. Что еще интереснее, в матче было показано в общей сложности три красные карточки, что в целом совпадает с оценкой риска от Qwen перед матчем: "Защита ЮАР действует грубо, возможно, они рано останутся в меньшинстве".

Если бы он просто предсказал победу Мексики, это не было бы большим сюрпризом. Как одной из стран-хозяек, Мексике и так отдавалось предпочтение. Но Qwen на этот раз попал в более конкретные детали матча: счет 2:0, риск красных карточек у ЮАР, а также постепенное увеличение отрыва по ходу второй половины игры.
Сразу после этого, в матче Южная Корея — Чехия, Qwen снова дал прогноз: Южная Корея 2:1.
Этот матч перед игрой предсказать было непросто. У Чехии была физическая мощь, угроза со стандартов и привычный опыт выступлений на крупных турнирах, характерный для европейских команд. Ход игры действительно не был односторонним: Чехия первой вышла вперед, Южная Корея сравняла счет, игра надолго замерла на отметке 1:1. Лишь на последних минутах южнокорейцы забили победный гол, и счет окончательно стал 2:1.
Это придало прогнозу Qwen еще больше "сценарности". Победителя можно определить по формальным силам сторон, прогноз счета может быть удачей, но такие детали процесса, как красные карточки, камбэк, победный гол на последних минутах, заставляют по-настоящему задуматься, что "тут что-то есть". После двух матчей первого дня Qwen первым поднял интерес к прогнозам ЧМ от ИИ.
Copilot: Блестящие попадания и явные провалы
Перед турниром USA Today попросила Copilot предсказать все 104 матча этого Чемпионата мира. Судя по уже завершенным играм, в этом прогнозе есть как яркие моменты, так и явные промахи.
Особенно выделяются прогнозы на три матча.
На стартовый матч Мексика — ЮАР Copilot дал прогноз Мексика 2:0, и конечный счет точно совпал. В матче Южная Корея — Чехия он предсказал победу Южной Кореи 2:1, что также совпало с результатом. А в матче Бразилия — Марокко Copilot снова дал прогноз 1:1, и Бразилия действительно сыграла вничью с Марокко.
Особенно высока ценность попадания в матче Бразилия 1:1 Марокко. Бразилия, в конце концов, — традиционный гранд, и по составу и вниманию она находится в первой шеренге. Хотя Марокко вышло в полуфинал на прошлом ЧМ, напрямую предсказывать ничью с Бразилией перед игрой — не самый безопасный выбор. В итоге, после окончания матча Бразилия не смогла стартовать с победы, а Марокко продолжило демонстрировать свою стойкость на крупных турнирах. Прогноз Copilot на эту игру действительно был "гениальной догадкой".
Но слабые стороны Copilot также быстро проявились.
Он предсказал победу Канады над Боснией со счетом 2:1, но команды сыграли 1:1; предсказал минимальную победу Швейцарии над Катаром 1:0, но Швейцария также сыграла вничью; предсказал победу США над Парагваем 2:0 — направление верное, но фактический счет 4:1, атакующий потенциал был явно недооценен.
Более явные провалы произошли в нескольких матчах с сенсациями и играх, где фавориты не оправдали ожиданий.
В матче Турция — Австралия Copilot предсказал победу Турции 2:1, но Австралия сенсационно выиграла 2:0. В матче Эквадор — Кот-д'Ивуар он предсказал победу Эквадора 2:1, но Кот-д'Ивуар победил 1:0. В матче Нидерланды — Япония он предсказал победу Нидерландов 2:1, но Япония дважды отыгрывалась, и в итоге команды сыграли 2:2. В матче Швеция — Тунис он предсказал 1:1, но Швеция разгромила соперника со счетом 5:1.
То, что Copilot смог угадать точный счет в матчах Мексики, Южной Кореи и Бразилии, показывает, что он не просто дает ответ в пользу фаворита. Но такие матчи, как победа Австралии над Турцией, ничья Катара со Швейцарией и ничья Японии с Нидерландами, также выявили его все еще консервативные оценки в отношении сенсаций и ничьих.
ChatGPT: Анализ полный, но сенсации ловит не очень точно
По сравнению с полным прогнозом Copilot на все матчи, ChatGPT больше похож на "игрока, анализирующего ситуацию перед матчем".
В прогнозе на стартовый матч ChatGPT предсказал Мексике победу 2:0 над ЮАР, и конечный счет совпал. Причины, которые он привел, также были довольно полными: домашнее преимущество Мексики, ее текущая форма, слабость в атаке у ЮАР, а также такие факторы, как высокогорье Мехико и атмосфера на стадионе. В этом прогнозе ChatGPT не просто дал результат, но и логика его суждений совпала с результатом матча.
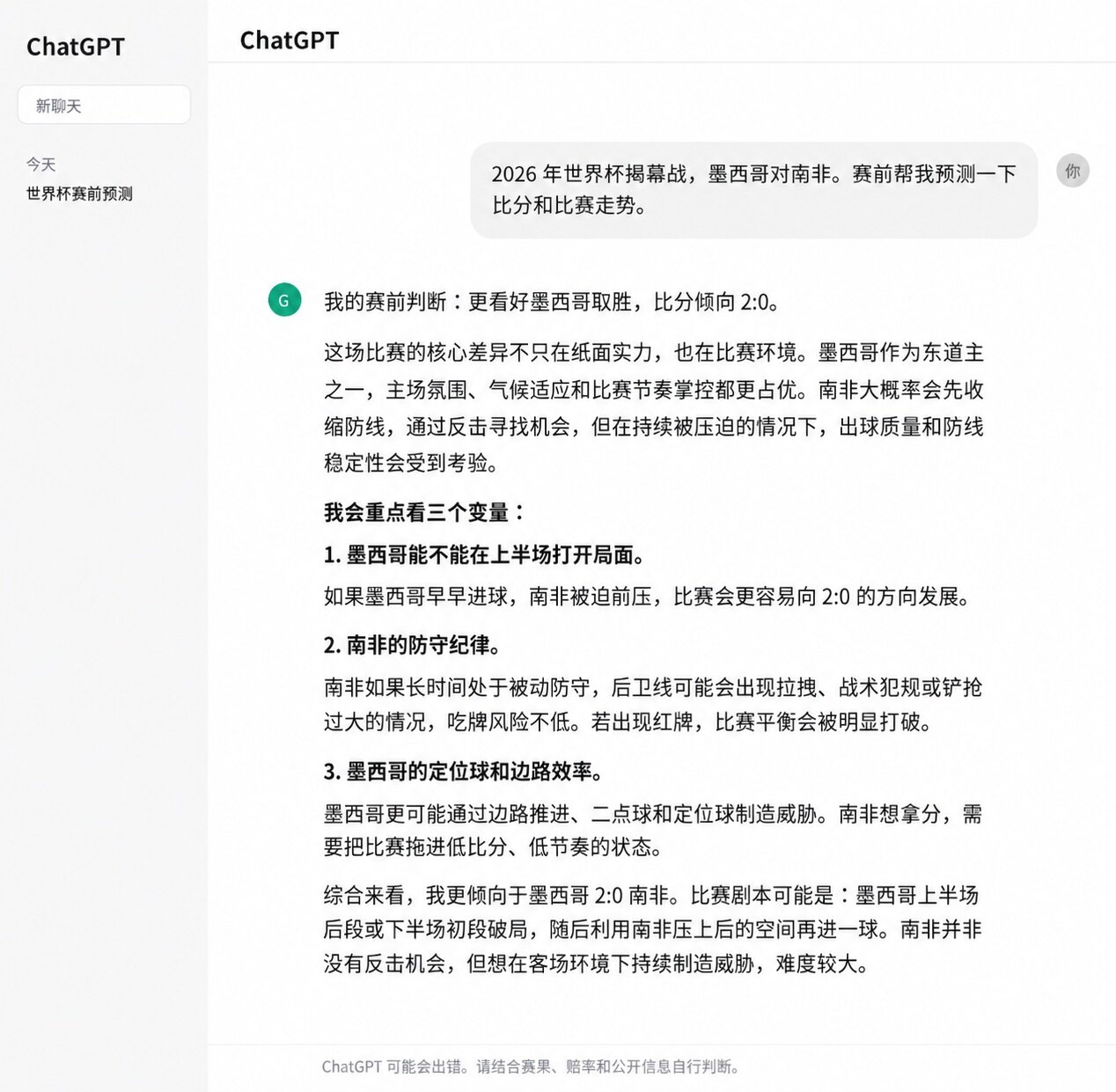
Но в полном прогнозе на матчи Чемпионата мира стабильность ChatGPT оказалась не такой высокой. Хотя он угадал счет 2:0 в матче Мексика — ЮАР и 1:1 в матче Бразилия — Марокко, а также верно определил победителей в нескольких матчах, таких как Шотландия, Германия, Швеция. Но в играх Южная Корея 2:1 Чехия, Катар 1:1 Швейцария, Австралия 2:0 Турция, Япония 2:2 Нидерланды — прогнозы ChatGPT указывали на команды, сильнее по формальным показателям. Например, что Швейцария должна победить Катар, Турция — Австралию, Нидерланды — одержать минимальную победу над Японией.
У ChatGPT нет недостатка в способности делать прогнозы, он может детально разобрать силу команды, домашние условия, текущую форму, а в некоторых матчах даже угадать счет. Но судя по текущим результатам, он лучше умеет объяснять "почему фаворит выглядит более логично", а не заранее выявлять, какие матчи могут пойти не по сценарию фаворита.
Gemini, Grok, Claude: Один и тот же матч — разные модели пишут разные сценарии
Помимо Qwen, Copilot и ChatGPT, некоторые пользователи соцсетей давали один и тот же матч на анализ нескольким моделям для предматчевого прогноза.
На примере стартового матча Мексика — ЮАР, один блогер одновременно протестировал четыре модели ИИ: ChatGPT, Gemini, Grok и Claude. Результаты показали, что ChatGPT и Gemini оба дали прогноз Мексика 2:0 ЮАР, и конечный счет точно совпал; Grok предсказал Мексика 2:1, Claude предсказал Мексика 3:1 — хотя оба правильно определили победу Мексики, точный счет не угадали.
В этом прогнозе на стартовый матч разные модели дали три разных "сценария". ChatGPT Go и Gemini Pro оказались ближе к реальной игре: Мексика доминирует, у ЮАР проблемы в атаке, в итоге сухой счет. Grok скорее дал относительно открытый вариант счета, предположив, что у ЮАР будет ответный гол. Claude Sonnet ожидал от Мексики более высокой результативности, дав вариант 3:1 — более разгромный счет.
Итог
Поскольку объем доступных для ретроспективного анализа прогнозов ИИ все еще ограничен, на данном этапе нельзя напрямую судить, какая модель лучше всего "разбирается в футболе".
Но если судить только по нескольким уже завершенным матчам, различия уже начали проявляться. На данный момент Qwen запомнился больше всех, в первый день подряд угадав счет 2:0 в матче Мексика — ЮАР и 2:1 в матче Южная Корея — Чехия, а также попав в риск красных карточек и ход игры — это яркое выступление на маленькой выборке. Однако, сможет ли он продолжать попадать в дальнейшем, потребует проверки на большем количестве матчей.
У Copilot и ChatGPT у обоих были яркие моменты с угадыванием точного счета, но также выявилась общая проблема — в матчах, отклоняющихся от формального паритета сил, таких как победа Австралии над Турцией, ничья Катара со Швейцарией, ничья Японии с Нидерландами, их оценки все еще недостаточно чувствительны.
Что касается таких моделей, как Gemini, Grok, Claude, в настоящее время общедоступные примеры в основном сосредоточены на единичных матчах или сравнениях в соцсетях. Ценность для справки есть, но для прямого ранжирования они еще не подходят.
ИИ уже может стать одним из источников информации для пользователей рынка прогнозов на Чемпионат мира, но до эталона ему еще далеко. В дальнейшем Odaily星球日报 также продолжит собирать предматчевые прогнозы различных моделей и по мере продвижения турнира постоянно сверяться с результатами: какие модели просто удачно стартовали, а какие действительно смогут выдержать проверку результатами в большем количестве матчей.





