Автор: qinbafrank
В феврале в статье «Что означает эта война капитальных затрат?» мы обсуждали, что ключевые звенья в цепочке поставок вычислительных мощностей по-прежнему могут захватывать наибольшую ценность: чипы, сборка и тестирование, память, оптические модули и т.д. Те сектора, где мощности трудно быстро расширить или которые имеют чрезвычайно высокий защитный барьер, будут пользоваться выгодами огромных капитальных затрат;
Пространство для оптимизации эффективности по-прежнему велико: дистилляция, квантизация, MoE, специализированные чипы, жидкостное охлаждение, термоядерный синтез (в долгосрочной перспективе) на стороне вывода могут снизить энергопотребление и стоимость единицы вычислительной мощности еще в 10–100 раз. Возможности нужно искать именно в этих направлениях.
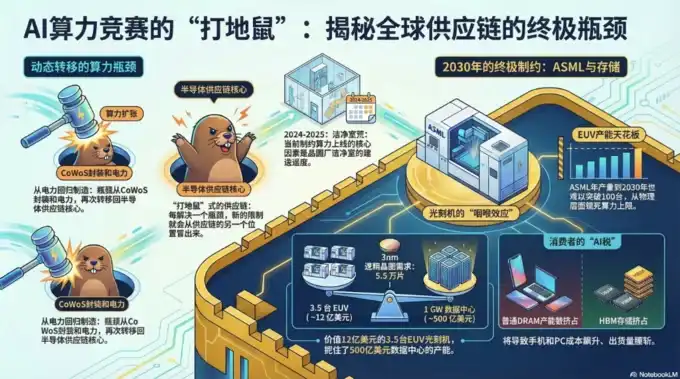
Недавно множество инвестиционных банков, таких как Morgan Stanley, J.P. Morgan, Bank of America, Goldman Sachs, UBS, Citigroup, Bernstein, HSBC, выпустили обновленные отчеты, связанные с ИИ/полупроводниками/электроэнергией/памятью. Узкие места в ИИ-оборудовании уже расширились с одного измерения «поставки GPU» до коллективного напряжения в пяти измерениях: электроэнергия, чипы, память, оборудование, материалы,
Масштабы спроса на ИИ уже вышли за пределы всех прогнозных интервалов традиционного планирования электроснабжения, производственных мощностей полупроводникового оборудования, ценовых моделей памяти и допущений по установке роботов.
Глобальное тематическое исследование Morgan Stanley указывает, что глобальное недельное потребление токенов большими языковыми моделями за 3 месяца выросло с 6,4 триллиона до 22,7 триллиона, что составляет увеличение в 2,5 раза. Дефицит электроэнергии для центров обработки данных в США в 2025-28 годах составляет 55 гигаватт; J.P. Morgan в своем первом покрытии проектных облигаций для высокопроизводительных вычислений в ЦОДах напрямую приводит цифру дефицита «122 гигаватта, требующих финансирования в ближайшие 5 лет». Пятилетний план электроснабжения США вырос со 101 гигаватта до 230 гигаватт, при этом 44% новых проектов ожидают подключения к сети более 4 лет; В новом отчете Bank of America о целевой цене для Alphabet капитальные затраты на 2026 год напрямую пересмотрены в сторону увеличения до 181,5 миллиарда долларов, что вдвое больше, а свободный денежный поток упал на 62%. Эти три набора данных не являются результатом одной и той же структуры, а представляют собой независимые картины, полученные тремя независимыми организациями на разных исследовательских путях.
Эволюция узких мест в полупроводниковой цепочке поставок (особенно в области ИИ-вычислений) явно прогрессирует в следующем порядке: «Вычисления (GPU) → Память (HBM и др.) → Оптическая взаимосвязь → Электроэнергия/Жидкостное охлаждение». Это консенсус отрасли на 2025-2026 годы. По мере того как кластеры для обучения/вывода ИИ расширяются от отдельных стоек (десятки GPU) до сверхмасштабных (тысячи и десятки тысяч GPU), каждый раз, когда устраняется узкое место в одном звене, сразу же обнажается следующее физическое/цепочное ограничение, формируя «Леонтьевские» комплементарные ограничения (без одного из звеньев поставки невозможны).
Необходимо понять, почему происходит такая эволюция, текущее состояние и лежащие в основе физические/инженерные причины:
1. Узкое место первого этапа: GPU-вычисления (доминировало в 2022-2024 гг.) Ключевое ограничение:
Производственные мощности самих передовых GPU (таких как NVIDIA Hopper H100 → Blackwell B200 → Rubin) + передовая упаковка.
Почему это узкое место: Большим моделям ИИ требуется огромное количество параллельных вычислений. Техпроцессы TSMC 4нм/3нм/2нм + производственные мощности CoWoS (2.5D/3D упаковка) в какой-то момент стали главной точкой сбоя. Даже если передних пластин хватает, возможности по сборке логических чипов и чипов HBM в единый модуль не поспевают, и целый GPU не может быть произведен.
Ситуация с ослаблением: TSMC активно наращивает мощности CoWoS (удвоение в 2024-2025 гг.), NVIDIA Blackwell уже поставляется в больших объемах. Но это лишь разблокировало звено «вычислений», сразу же обнажив новые проблемы.
2. Узкое место второго этапа: Память (HBM - память с высокой пропускной способностью, стала самой дефицитной в 2024-2025 гг.)
Ключевое ограничение: Производственные мощности HBM3/HBM3e/HBM4.
Почему стало следующим узким местом: Мощность GPU выросла, но параметры моделей взрывно увеличились (триллионы и даже десятки триллионов), перемещение данных (пропускная способность памяти) стало «стеной памяти». HBM может передавать несколько ТБ данных в секунду, что более чем в 20 раз быстрее обычной памяти DDR. Поскольку HBM расположена вплотную к логическому чипу, данные не нужно передавать далеко, что экономит энергию.
Одному GPU B200 требуется 192GB+ HBM3e, общий объем HBM в одной стойке (NVL72) уже достиг 30-40 ТБ, и требования к пропускной способности намного превышают возможности традиционной DRAM.
Текущее состояние цепочки поставок: Только SK Hynix, Samsung и Micron могут производить HBM в промышленных масштабах. Процесс сложен (кремниевые сквозные отверстия TSV + стекирование). На 2025 год всё уже продано, на 2026 год по-прежнему дефицит, цены выросли на 246% по сравнению с прошлым годом. Даже если чипы GPU готовы, без HBM сборка и поставка невозможны, что приводит к задержкам развертывания целых ИИ-кластеров.
Результат: Память превратилась из «товара» в стратегически критический элемент. Её доля в капитальных затратах может достигать 30%.
3. Узкое место третьего этапа: Оптическая взаимосвязь (переход происходит в 2025-2026 гг.)
Ключевое ограничение: Физические пределы медных кабелей (NVLink/NVSwitch) по пропускной способности, расстоянию, энергопотреблению и весу.
Почему неизбежен переход на оптику: Внутри одной стойки (72 GPU) еще можно обойтись медными кабелями, но для расширения на несколько стоек и даже тысячи GPU взаимосвязь медными кабелями становится проблематичной: сильное затухание (при пропускной способности 1.8 ТБ/с эффективное расстояние < 1 метра), взрывной рост веса (стойка NVL72 содержит более 5000 медных кабелей общим весом 1,36 тонны), высокое энергопотребление (съемные оптические модули, заменяющие медь, потребляют дополнительно 20 000 Вт). Целостность сигнала, задержка, охлаждение — всё это не может поддерживать более крупные кластеры.
Решение: Переход на оптическую взаимосвязь (CPO - совместная упаковка с оптикой + кремниевая фотоника). Оптические двигатели размещаются непосредственно рядом с GPU/ASIC, для масштабирования используются оптические волокна, что обеспечивает более высокую плотность пропускной способности, более низкое энергопотребление на бит и большую дальность.
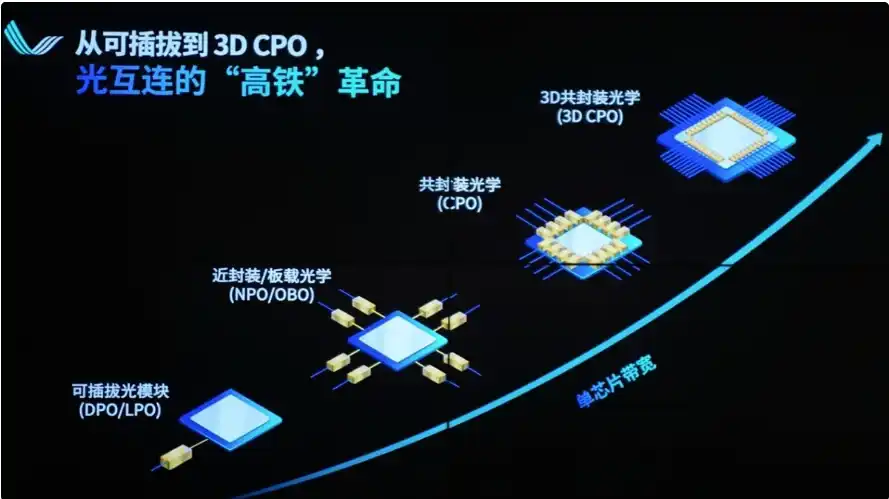
NVIDIA на конференции GTC 2026 года сделала большую ставку на это, уже инвестировала в оптические компании, спрос на оптические модули 800G/1.6T взрывно растет. Lumentum, Broadcom, Coherent, Ayar Labs и другие становятся новыми победителями.
Текущий прогресс: Медные кабели достигли предела. Оптическая взаимосвязь превращается из «опции» в «необходимость», преодолевая потолок производительности ИИ-центров обработки данных.
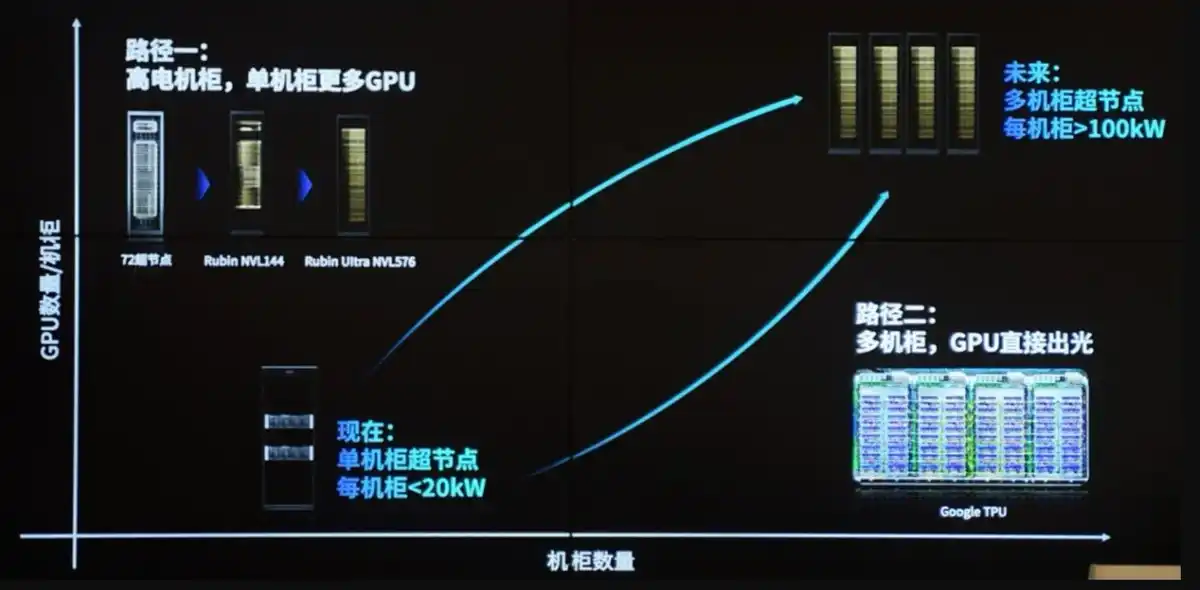
4. Узкое место четвертого этапа (самое передовое на данный момент): Электроэнергия + Жидкостное охлаждение (с 2026 года становится окончательным физическим ограничением) Ключевое ограничение: Стена энергопотребления + Стена теплоотвода + Подключение к электросети.
Почему это конечное узкое место: Каждый GPU вырос с 300 Вт до 700-1200 Вт, отдельная стойка выросла с 10-20 кВт (эпоха CPU) до 120-200+ кВт и даже выше. Физический предел традиционного воздушного охлаждения составляет всего 20-50 кВт, уровень шума, воздушный поток и энергопотребление становятся неприемлемыми.
Сторона электроснабжения: Центрам обработки данных требуется электроснабжение гигаваттного уровня, очереди на подключение к сети могут достигать нескольких лет, сроки поставки трансформаторов, твердотельных трансформаторов и другого оборудования увеличились до 100 недель. Генеральный директор Microsoft прямо заявил: «Есть GPU, но некуда их подключить».
Сторона жидкостного охлаждения: Необходим переход на Direct-to-Chip (прямое жидкостное охлаждение чипов) или иммерсионное охлаждение в сочетании с микрофлюидными технологиями, холодными пластинами и т.д. TSMC уже продемонстрировала кремниевое жидкостное охлаждение на платформе CoWoS, поддерживающее TDP > 2,6 кВт. Компании по жидкостному охлаждению/теплоуправлению, такие как Vertiv (VRT), становятся новым ядром инфраструктуры.
Цепная реакция: Требования к PUE (эффективности использования энергии) < 1,2, утилизация отработанного тепла, подключение ядерной/новой энергетики — все это становится новыми темами. Даже если все предыдущие звенья решены, без электричества и охлаждения стойки не могут быть запущены.
Фундаментальная логика передачи узких мест в цепочке ИИ-вычислительных мощностей ИИ-вычисления — это не проблема «отдельной точки», а системная функция производства Леонтьева — GPU, HBM, взаимосвязь, электроэнергия, охлаждение должны соответствовать по самому низкому «короткому звену». Крупнейшие облачные провайдеры (Google, Microsoft, Meta и др.) каждый раз, устраняя одну проблему, немедленно направляют капитал и инновации к следующему звену.
В настоящее время (2026 год) происходит переходный период «ускоренного внедрения оптической взаимосвязи + массового коммерческого использования электроэнергии/жидкостного охлаждения». В будущем могут появиться новые узкие места (например, лазеры, материалы для волокон или сетевые трансформаторы), но эта цепочка «вычисления → память → оптика → электричество/охлаждение» уже стала общепризнанным путем в отрасли.
Это также объясняет, почему инвестиционная логика смещается с NVIDIA/TSMC на тройку лидеров по HBM (SK Hynix и др.), производителей оптики (Lumentum, Coherent), инфраструктуру жидкостного охлаждения/электроснабжения (Vertiv, соответствующие компании по производству блоков питания).
Каждый перенос узкого места перераспределяет стоимость во всей цепочке полупроводников + центров обработки данных.








