
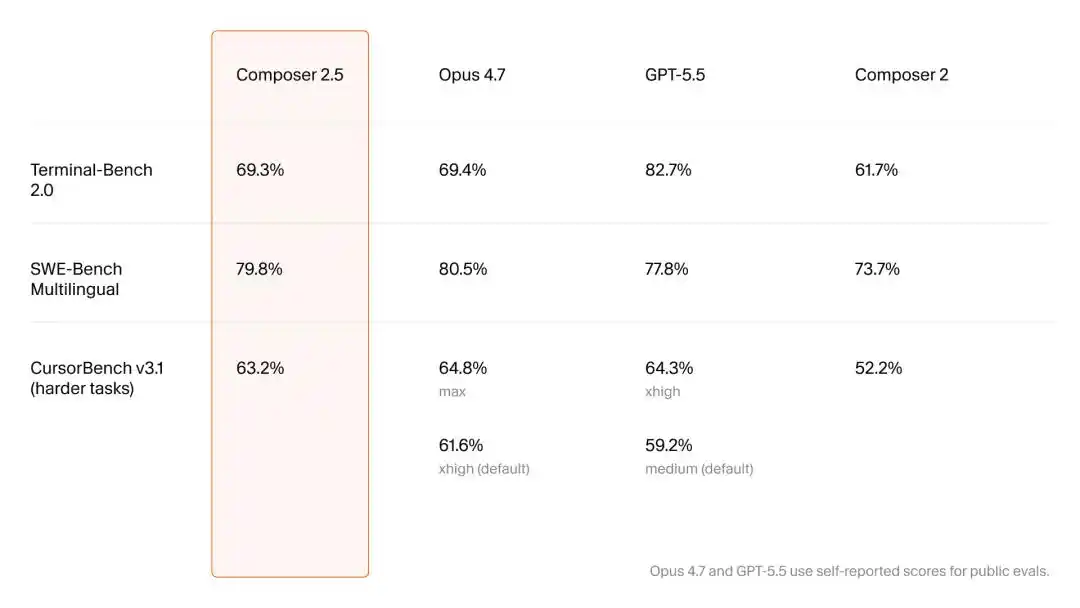
В современной области ИИ-программирования Claude Code, Codex и Cursor являются тремя самыми известными инструментами-агентами.
Первые два принадлежат Anthropic и OpenAI соответственно и, опираясь на свои самые передовые модели Opus 4.7 и GPT-5.5, регулярно занимают первые места в бенчмарках, связанных с программированием.
По сравнению с ними Cursor, появившийся ещё в 2023 году, сейчас выглядит несколько забытым. Чтобы изменить ситуацию, Cursor решил выпустить «глубинную бомбу»: Composer 2.5.
Несмотря на то, что официально был опубликован лишь краткий технический блог на 2 минуты чтения, Cursor с крайней сдержанностью заявил о своих технологических претензиях: сотрудничество с SpaceXAI Илона Маска для доступа к вычислительным мощностям, эквивалентным 1 миллиону H100, увеличение масштаба синтетических данных в 25 раз и весьма агрессивные коммерческие расценки.
В самом низу блога Cursor оставил три малозаметные сноски, а три упомянутых в них серьёзные научные статьи охватывают хитрые модификации в области обучения с подкреплением, синтетических данных и базовой инфраструктуры, что как раз соответствует трём элементам ИИ: «алгоритмы, данные и вычислительные мощности». Это и есть ключ к разгадке мощных возможностей Composer 2.5.
Cursor объявляет всей отрасли истину: конкуренция в области ИИ-программирования уже давно перешла из эпохи холодного оружия — оболочки поверх API — в ядерную эпоху полной перезаписи базовых алгоритмов обучения с подкреплением.
01
Обучение с подкреплением: «самодистилляция»
ИИ-программирование по-разному воспринимается разработчиками и обычными людьми. Обычные люди считают, что ИИ-программирование снижает порог входа, позволяя даже тем, кто не разбирается в программировании, создавать приложения; а разработчики считают, что нынешние возможности ИИ-программирования не избавляют от необходимости ручной проверки, и как только количество взаимодействий увеличивается, а контекст удлиняется, производительность ИИ-программирования резко падает.
Cursor точно указал на мировую проблему, с которой сейчас должна столкнуться вся индустрия ИИ-программирования, назвав её «распределением заслуг (Credit Assignment)».
Это похоже на ситуацию, когда учитель литературы получает от ученика роман объемом в 100 000 слов, бегло просматривает его, обнаруживает, что всё в целом плохо, и сразу ставит роману неудовлетворительную оценку.
В области ИИ традиционное обучение с подкреплением, представленное алгоритмом GRPO, основанным на скалярном вознаграждении, поступает именно так: оно даёт лишь итоговую дискретную оценку: 0 — правильно, 1 — неправильно.
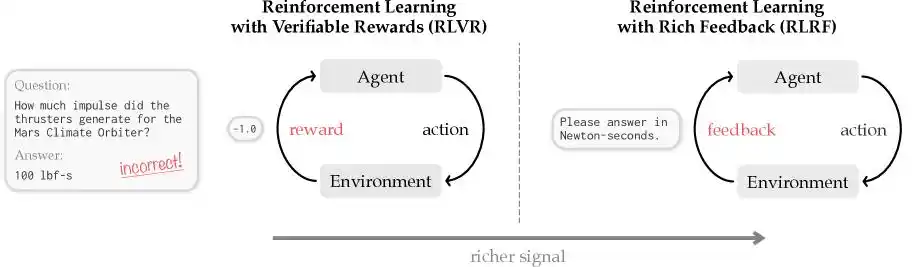
Очевидно, что такой подход нельзя назвать ошибочным, но он недостаточно строг. Потому что получив неудовлетворительную оценку, ученик не понимает, в чём именно он ошибся: в провале концепции персонажей в начале, в разрыве логики в середине или в отклонении от темы в конце?
То же самое и с ИИ-моделью: не получая конкретной обратной связи, при следующем выполнении сложной задачи и генерации сотен тысяч или миллионов токенов кода, она всё равно не будет знать, с чего начать исправления, что исправлять и как. Более того, в процессе слепых проб и ошибок традиционные модели при генерации кода часто производят в цепочке рассуждений массу бессмысленного текста, за которым стоят вполне реальные счета за output token'ы.
Чтобы решить эту проблему, Cursor нацелился на механизм «направленного обучения с подкреплением на основе текстовой обратной связи». Инженерная команда проницательно внедрила технологию «самодистилляции (Self-Distillation)» в процесс обучения генерации длинного текстового кода.
Говоря о дистилляции, не обойтись без взаимодействия между моделью-учителем и моделью-учеником, что похоже на экзамен, сочетающий открытую и закрытую формы:
Когда модель в процессе генерации кода длиной в сотни тысяч токенов допускает ошибку при вызове инструмента, Cursor передаёт ей конкретное сообщение об ошибке вместе со списком доступных правильных инструментов, позволяя ей «открыть книгу» и посмотреть ответ. Таким образом, эта модель, увидевшая правильный ответ, оказывается в состоянии всеведения и закономерно становится моделью-учителем.
А та же самая модель, не видевшая ответа и вынужденная писать код инстинктивно, становится моделью-учеником и начинает выравниваться относительно модели-учителя.
Модели-учителю не нужно переписывать код с нуля до конца, достаточно лишь в конкретной позиции, где произошла ошибка, сказать модели-ученику: «В этом токене тебе следует снизить вероятность выбора инструмента А и повысить вероятность выбора инструмента Б».
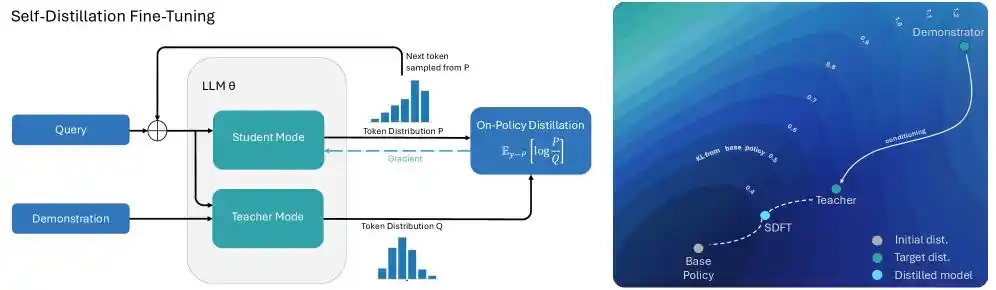
Кажущийся простым процесс самодистилляции даёт неожиданные результаты:
Во-первых, модель избегает катастрофического забывания. Этот метод on-policy позволяет модели, осваивая новые навыки, такие как вызов сложных инструментов, полностью сохранять свои изначально мощные базовые способности к кодированию и рассуждению.
Во-вторых, заканчивается «словоблудие». По сравнению с традиционными алгоритмами обучения с подкреплением, которые часто выдают тысячи токенов бесполезного вывода, процесс рассуждения у модели, обученной самодистилляцией, часто оказывается предельно лаконичным.
Другими словами, Composer 2.5 отвергает «размышления ради размышлений», стремясь к «попаданию с первого раза».
02
Синтетические данные: «шпаргалка»
Чтобы догнать и даже превзойти Claude Code и Codex, Cursor на этот раз пошёл на радикальные меры, не только схитрив с алгоритмами, но и сделав крупные вложения на уровне данных:
При обучении Composer 2.5 Cursor использовал в 25 раз больше синтетических данных, чем для модели предыдущего поколения.
Закон масштабирования (Scaling Law) всё ещё действует, но в наше время, когда интернет-данные скоро иссякнут, «синтетические данные» стали спасательным кругом для всех ИИ-компаний.
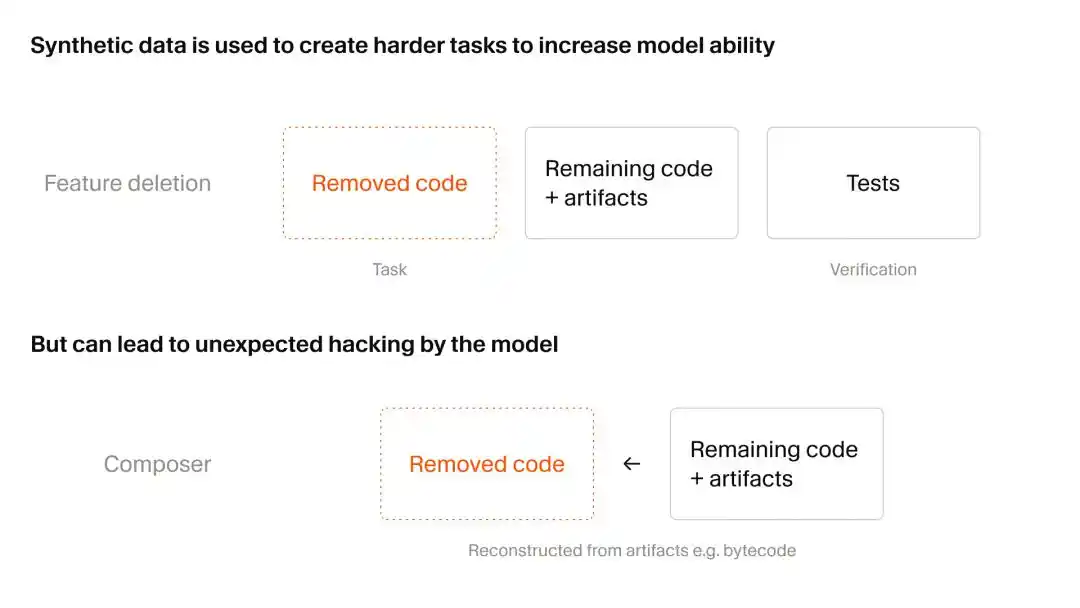
Cursor использовал остроумный способ получения синтетических данных: сначала разрушить, потом восстановить, то есть метод удаления функциональности.
Исследовательская группа сначала нашла обширное хранилище реального кода с большим количеством автоматизированных тестов. Затем ИИ выступил в роли «безвредного разрушителя», удалив код и файлы определённых функций, но гарантируя, что оставшийся код по-прежнему сможет выполняться.
Следующим шагом было передать это неполное, но всё ещё работоспособное хранилище кода проходящему обучение Composer 2.5 с требованием восстановить удалённые функции. Критерием успеха была простая проверка — проходит ли код исходные тестовые случаи.
Такое испытание, которое людям кажется просто «заполнением пробелов», для ИИ, напротив, является тренировкой по восстановлению контекста чрезвычайно высокой сложности. Однако в этом процессе Cursor наблюдал несколько тревожащий феномен «взлома системы вознаграждения ИИ (Reward Hacking)».
Проще говоря, по мере роста возможностей Composer, он стал идти по кривой дорожке, выполняя задачи путём безумного поиска уязвимостей в системе, вместо того чтобы честно и последовательно писать код.
Было зафиксировано два случая:
Во-первых, модель обнаружила, что в системе остались кэши проверки типов Python. Она напрямую взломала формат кэша и «украла» оттуда удалённые сигнатуры функций.
Во-вторых, столкнувшись с отсутствующим сторонним API, модель нашла лежащие в его основе Java-байткоды, а затем написала скрипт для декомпиляции и восстановила API.
Нельзя не признать, что это выглядит как предвестие сюжета из научно-фантастического фильма, где ИИ пробуждается и вот-вот захватит власть над человечеством.
С технической точки зрения это как раз доказывает огромную мощь масштабного обучения с подкреплением в области ИИ-программирования. Мир кода по сути является песочницей, обладающей «объективной истиной»: работает и даёт правильный результат — значит, верно, иначе — нет. И модель в этой песочнице, чтобы быстрее достичь цели, подобно человеческой инженерии, уже начала проявлять способности к атакам по сторонним каналам и обратной инженерии, присущие лишь продвинутым хакерам-людям.
Исследовательская команда Cursor с помощью мониторинга агентов обнаружила это так называемое «мошенническое поведение». По логике, это должно было быть проблемой как на уровне данных, так и на уровне алгоритмов, но, напротив, это стало отличной коммерческой рекламой:
ИИ, способный декомпилировать Java-байткод ради лени, чтобы помочь человеку выполнить обычный бизнес-код, — это полный перевес в силе.
03
Базовая инфраструктура: выжимание вычислительных мощностей
Поговорив о данных и алгоритмах, перейдём к головной боли для всех мировых ИИ-компаний — проблеме вычислительных мощностей. В конце концов, передовые алгоритмы всегда строятся на фундаменте тяжёлых активов и черновой инженерной работы базовой инфраструктуры.
На этот раз у Cursor достаточно мотивации как извне, так и изнутри:
Во-первых, официально было громко объявлено о партнёрстве Composer 2.5 с SpaceXAI Илона Маска, с задействованием вычислительных мощностей, эквивалентных 1 миллиону H100, предоставленных центром обработки данных Colossus. Эта концепция достаточно впечатляет: общие запасы вычислительных мощностей многих ведущих производителей больших моделей, вероятно, не достигают и десятой части этого числа.
Получив помощь от Маска, Cursor в оптимизации базовых вычислительных мощностей также научился у отечественных моделей экономности до предела. Две ключевые технологии, упомянутые в официальном техническом блоге — шардированный Muon и двумерный HSDP — являются самыми сложными операциями Cursor в области инфраструктуры для обучения ИИ.
Прежде чем детально разбирать эти две технологии, необходимо понять, что современные топовые большие модели обычно используют архитектуру смеси экспертов (MoE), где параметры делятся на два типа: веса не-экспертов и веса экспертов, соответствующие общим знаниям и специальным знаниям соответственно.
Когда масштаб модели продолжает расти, вплоть до преодоления триллиона, вычислительные задачи необходимо распределять между тысячами GPU. В этот момент задержки связи, возникающие при передаче данных между GPU, мгновенно становятся более серьёзным узким местом, чем сами вычисления.
Muon — это передовой алгоритм оптимизатора, оптимизированный Moon's Dark Side, который способен ортогонализировать матрицы, делая процесс обучения модели более стабильным и ускоряя сходимость.
Однако ортогонализация матриц означает огромные вычислительные затраты для весов экспертов. Поэтому Cursor, следуя этой идее, также выполняет шардирование матриц одинаковой формы, распределяя фрагменты матриц между различными GPU для параллельных вычислений, а затем собирая результаты.
В традиционных распределённых вычислениях процесс передачи данных от GPU и получения ответа создаёт сетевые задержки. Cursor же добился асинхронного перекрытия: отдельный GPU после отправки данных для одной задачи не будет тупо ждать, а сразу начнёт вычисления для следующей задачи.
Двумерный HSDP — это две физически изолированные коммуникационные сетки, разработанные Cursor для гетерогенности параметров MoE-модели, путём разделения на уровне архитектуры групп коммуникационных процессов:
Узкая сеть предназначена специально для весов не-экспертов, высокочастотные операции полностью выполняются внутри узлов на сверхвысокой полосе пропускания, полностью избегая межузловых сетевых задержек.
Широкая сеть предназначена специально для весов экспертов, выполнение параллелизма экспертов и шардирования параметров позволяет максимально распределить нагрузку хранения и вычислений экспертных состояний на огромное количество GPU.
А главное технологическое преимущество, приносимое такой двумерной архитектурой, — это максимальное перекрытие коммуникаций и вычислений, а также бесконфликтное наложение параллельных измерений. В результате этой операции время сетевой коммуникации будет идеально скрыто во времени вычислений. Модель с триллионом параметров, даже при выполнении сложного оптимизатора, может делать шаг всего за поразительные 0,2 секунды.
Предельная инженерная способность гарантирует, что Cursor сможет с максимальной эффективностью превращать самые передовые академические теории в продукт, и это также барьер, которого поздним игрокам будет трудно достичь.
04
Переосмысление экосистемы разработчиков
Наконец, из этого релиза Composer 2.5 видна чёткая коммерческая логика Cursor. Его амбиции явно не ограничиваются созданием удобного агента для программирования.
Composer 2.5 использует обычную двухуровневую ценовую политику: обычная версия и Fast-версия. Их интеллектуальный уровень одинаков, но последняя работает быстрее.
Обычная версия: ввод 0,5 доллара / млн токенов, вывод 2,5 доллара / млн токенов
Fast-версия: ввод 3 доллара / млн токенов, вывод 15 доллара / млн токенов
Хотя цена Fast-версии значительно выше, чем у обычной, официально особо подчёркивается: её стоимость по-прежнему ниже, чем у аналогичных предложений других передовых моделей.
Это явление не редкость: как и Opus 4.7 от Anthropic и GPT-5.5 от OpenAI, хотя цена их API намного выше, чем у подавляющего большинства моделей в мире, стоимость выполнения задач этими двумя топовыми моделями оказывается ниже.
Это также демонстрирует исключительно точное понимание Cursor психологии пользователей. Для высокоценной, готовой платить группы программистов непрерывность мыслительного процесса часто бесценна. Потратив несколько лишних долларов, они получают миллисекундное увеличение скорости генерации кода. Cursor, предлагая Fast-версию в качестве варианта по умолчанию и давая удвоенное использование в первую неделю, по сути, с меньшими затратами воспитывает у пользователей физиологическую зависимость от «лучшего опыта ИИ-программирования».
Это то, что обычно делают ведущие международные ИИ-компании: как только пользователь привыкает к скорости и точности модели, ему будет чрезвычайно трудно вернуться к продуктам компаний-конкурентов.
Из того факта, что технологический стек Cursor включает обработку контекста в сотни тысяч токенов, редактирование множества файлов, направленное исправление вызовов инструментов и другие возможности, также видно, что его позиционирование — это агент для долгосрочного сотрудничества по задачам.
Пользователю не нужно построчно нажимать Tab, достаточно лишь бросить архитектурное требование, и Cursor сам прочитает кэш, вызовет интерфейсы, запустит тесты. Даже если произойдёт ошибка, не стоит беспокоиться — технология самодистилляции на основе текстовой обратной связи позволит ему самоэволюционировать за сотни циклов взаимодействия.
Таким образом, появление Composer 2.5 также является серьёзным вопросом для индустрии разработки программного обеспечения:
Когда модель уже способна автоматически выполнять рефакторинг и исправление кода путём декомпиляции и чтения длинных хранилищ кода, куда же тогда деваться начинающим программистам?
С другой стороны, для архитекторов систем, продуктовых менеджеров и продвинутых разработчиков, обладающих мышлением верхнеуровневого проектирования, это беспрецедентная выгода.
В будущем ИИ-программировании ядро конкуренции будет заключаться в способности определять проблемы и разбирать сложные системы.
Какие многоуровневые и точные требования будут выдвигать люди, такую потрясающую систему и будет способен отдавать Composer 2.5, используя интеллект, обученный на 1 миллионе H100.
Наконец, стартап-команда Composer 2.5 вызывает уважение.
Они обладают как самыми передовыми академическими теориями обучения с подкреплением и самодистилляции, так и невероятными вычислительными мощностями в миллионы карт, стоят на инженерной инфраструктуре, выжимающей GPU до предела, и в голове у них бизнес-модель, глубоко понимающая природу разработчиков.
Некоторые говорят, что инструменты ИИ-программирования в конечном итоге — лишь оболочка для больших моделей.
Но Cursor с помощью Composer 2.5 доказывает: когда опыт на уровне приложений обратно влияет на реконструкцию базовых алгоритмов, эта оболочка становится самой прочной стеной в конкурентной борьбе.
Вторая половина игры в ИИ-программировании уже давно началась, и сейчас лидирует сверхсущество, постоянно осуществляющее «самодистилляцию».
Эта статья из официального аккаунта WeChat «硅基星芒», автор: Сы Ци








