Одна строка import, тонкая настройка большой модели MoE ускоряется в 3,7 раза.
Последние исследования NVIDIA теперь с открытым исходным кодом: NeMo AutoModel, специально разработанный для масштабного построения и тонкой настройки генеративных моделей ИИ.
На основе Hugging Face Transformers v5, NeMo AutoModel позволяет, не меняя API кода, лишь добавив одну строку import, реализовать более быструю тонкую настройку моделей MoE.

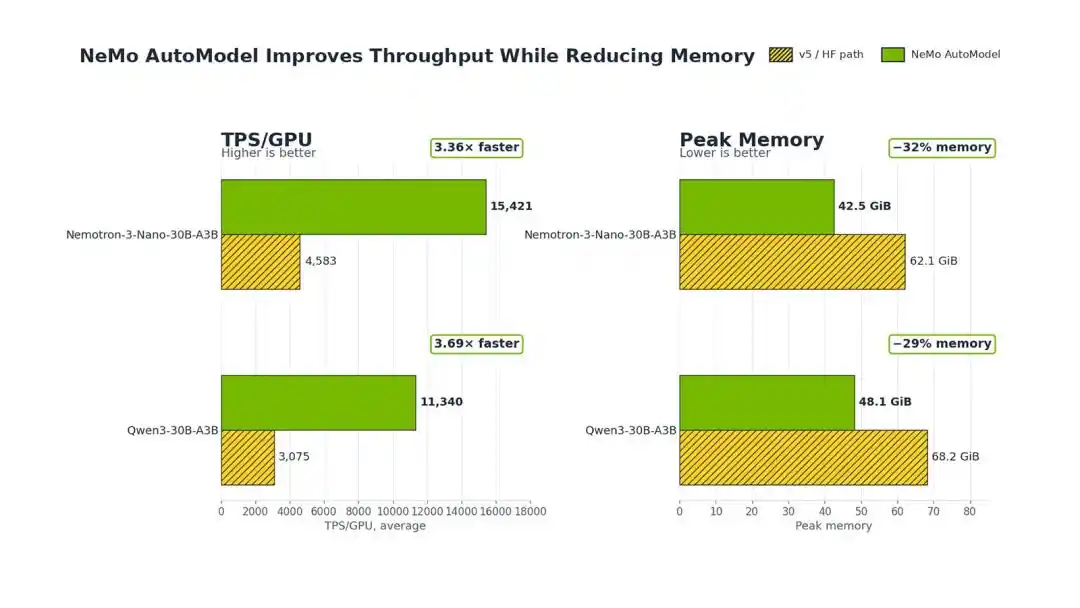
Эксперименты показывают, что по сравнению с оригинальной версией Transformers v5 от Hugging Face, NVIDIA NeMo AutoModel позволяет достичь повышения пропускной способности обучения в 3,4-3,7 раза при тонкой настройке MoE и сократить использование видеопамяти GPU на 29%-32%.
На одном узле с 8xH100 80GB GPU, на примере Qwen3-30B-A3B, NeMo AutoModel напрямую повышает TPS/GPU (пропускную способность на GPU в секунду) с 3075 до 11340, увеличение в 3.69 раза.
Анализ ключевых технологий
MoE уже стала основной архитектурой для современных передовых моделей, но MoE также создает новые вызовы для эффективного обучения:
Параллелизм экспертов, слияние коммуникаций, оптимизация ядра... Для поддержки этих сложных инженерных задач необходима соответствующая инфраструктура.
Transformers v5 от HuggingFace — это наиболее часто используемая в настоящее время «универсальная основа» для обучения MoE. Версия v5 улучшила нативную поддержку MoE, добавив базовые возможности MoE, такие как expert backends, dynamic weight loading, распределенное выполнение.

На этот раз подход NVIDIA заключается в том, чтобы, опираясь на достижения предшественников, сохранить совместимость с API HuggingFace Transformers, позволяя пользователям без серьезных изменений кода получить более высокую пропускную способность обучения и меньшее использование видеопамяти при тонкой настройке MoE.
Конкретно, NeMo AutoModel на основе Transformers v5 добавляет Параллелизм Экспертов (EP), DeepEP и TransformerEngine.
Параллелизм Экспертов (Expert Parallelism)
Технология параллелизма экспертов в основном используется для снижения нагрузки на память.
EP распределяет веса экспертов на несколько GPU, и каждая видеокарта больше не содержит полные параметры всех экспертов, а только часть из них.
Например, на 8 GPU с ep_size=8, веса экспертов распределены на 8 GPU, занимаемая MoE память на каждом GPU может снизиться до 1/8 от исходной.
Согласно результатам экспериментов, для Qwen3 эта технология может снизить пиковое использование памяти с 68.2 GiB до 48.1 GiB, снижение на 29%.
Для модели Nemotron Nanomo, использование памяти снизилось с 62.1 GiB до 42.5 GiB, снижение на 32%.
Освобожденное пространство можно использовать для поддержки большего размера пакета (batch size) или более длинных последовательностей.
DeepEP
DeepEP реализует слияние вычислений и коммуникаций.
В традиционном подходе между распределением токенов и вычислениями экспертов существуют явные затраты на коммуникацию. DeepEP интегрирует операции распределения и комбинирования токенов в оптимизированное GPU ядро, добиваясь перекрытия процессов коммуникации и вычислений экспертов.
TransformerEngine
Ядро TransformerEngine обеспечивает ускорение для различных ключевых операций.
Эта технология предоставляет реализации слияния механизма внимания, линейных слоев и RMSNorm и т.д., ускоряя не только слои MoE, но и обычные Transformer слои.
Одна строка import, 3-кратное ускорение
Подводя итог, для тех, кто уже использует Transformers v5, NVIDIA NeMo AutoModel предлагает безболезненный вариант обновления:
Достаточно добавить одну строку кода import, чтобы получить 3-кратное ускорение тонкой настройки MoE.

На Qwen3-30B-A3B и Nemotron 3 Nano 30B-A3B, по сравнению с Transformers v5, данное решение позволяет достичь повышения пропускной способности обучения в 3.4-3.7 раза при одновременном снижении потребления памяти на 29%-32%.
NVIDIA также продемонстрировала результаты полной тонкой настройки параметров (full-parameter fine-tuning) для Nemotron 3 Ultra 550B A55B на 16 узлах H100, 128 GPU.
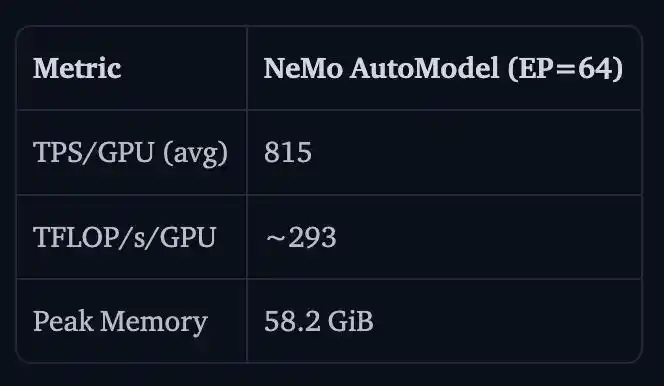
TPS/GPU составляет 815, TFLOP/s/GPU примерно 293, пиковое использование памяти — 58.2 GiB.
Причина отсутствия сравнения с v5 здесь в том, что Transformers v5 при таком масштабе просто исчерпает всю память ̄_(ツ)_/ ̄
Если интересно, NVIDIA уже выложила код, конфигурации и скрипты бенчмарков на GitHub: https://github.com/NVIDIA-NeMo/Automodel/tree/blog/transformers-v5-automodel/blog_experiments
Конкретное руководство по использованию здесь: https://docs.nvidia.com/nemo/automodel/latest/get-started/hf-compatibility
Статья из официального аккаунта WeChat «Квантовый бит», автор: Юй Ян






