22 июня 2026 года новая модель Fugu от Sakana AI вызвала ажиотаж в сообществе ИИ. На строгих тестах SWE-Bench Pro и TerminalBench, Fugu Ultra набрала 73,7 и 82,1 балла соответственно, превзойдя GPT-5.5 и Claude Opus 4.8, и даже заявила о сопоставимости с моделями Fable 5 и Mythos Preview, ограниченными экспортными ограничениями. Неожиданностью стало то, что ядром этой системы, достигшей вершины в инженерных и логических способностях, является не гигантская модель с триллионами параметров, а модель всего с 7B параметрами. Она не выполняет задачи сама, а выступает в роли "прораба", динамически распределяя задачи между ведущими мировыми большими моделями. Эта архитектура, идущая вразрез с обычной логикой, не только разрушает миф о том, что "параметры равны справедливости", но и отражает путь Японии к прорыву в области ИИ в условиях ограниченных вычислительных мощностей.
"Прораб" с 7B параметрами: Контринтуитивная архитектура Fugu
Чтобы понять странность Fugu, нужно сначала посмотреть на её происхождение. Sakana AI была основана в Токио в 2023 году соавтором статьи о Transformer Лионом Джонсом и бывшим исследователем Google Дэвидом Ха. С самого рождения компания несла в себе гены "вдохновленной природой" философии, стремясь использовать эволюционные алгоритмы и коллективный интеллект природы для решения проблем ИИ. В 2025 году Sakana AI получила инвестиции от гигантов, таких как NVIDIA и Google, и была оценена более чем в 25 миллиардов долларов. Но даже при поддержке гигантов, в самой Японии по-прежнему не хватает такой крупной инфраструктуры для вычислений и пулов данных, как в Китае и США. В условиях этих ограничений ресурсов Sakana AI не стала идти напролом, создавая модели с сотнями миллиардов параметров, а выбрала путь "оркестровки".
Официальное позиционирование Fugu — это "система оркестровки множественных агентов, действующая как единая базовая модель". В традиционной архитектуре ИИ большая модель — это "монолитный зверь": пользователь вводит промт, модель вычисляет от первого слоя нейронной сети до последнего и выводит результат. Этот режим чрезвычайно эффективен при решении простых проблем, но при столкновении со сложными многоэтапными инженерными задачами часто возникают галлюцинации или логические разрывы.
Fugu кардинально меняет эту парадигму. Её ядро — это модель с 7B параметров, обученная методом обучения с подкреплением, называемая RL Conductor. Эта 7B-модель сама по себе не генерирует окончательный ответ напрямую, а играет роль "прораба". Когда пользователь отправляет задачу через единый API, совместимый с OpenAI, RL Conductor динамически анализирует тип задачи, а затем распределяет подзадачи среди ведущих мировых моделей в пуле агентов, таких как GPT-5, Gemini 3.1 Pro или Claude Opus 4.8. Он отвечает за планирование, проверку и синтез выводов этих моделей, в конечном итоге выдавая результат, прошедший многократную проверку.
Теоретической основой этой архитектуры стали две статьи ICLR 2026: «TRINITY: An Evolved LLM Coordinator» и «Learning to Orchestrate Agents in Natural Language with the Conductor». В статьях подробно излагается, как с помощью обучения с подкреплением заставить модель с малым числом параметров "дирижировать" большими моделями. Это меняет парадигму Test-time scaling (масштабирования во время тестирования). Раньше вычислительные мощности в основном использовались для глубоких логических рассуждений внутри модели, то есть для того, чтобы модель "упорно" находила один ответ; теперь вычислительные мощности используются для внешнего планирования, проверки и синтеза. Традиционная большая модель — это универсальный монолит, Fugu — это команда экспертов. RL Conductor с 7B параметрами доказал, что количество параметров модели больше не является единственным стандартом, определяющим способности; умение вызывать инструменты и внешних агентов также может привести к скачку производительности.
Правда за баллами: Сравнение с Fable и превосходство над GPT-5.5
Непосредственной причиной сенсации, вызванной Fugu, стали её результаты в строгих тестах. В индустрии ИИ результаты тестов — это твердая валюта для измерения возможностей модели, но разные тесты делают акцент на совершенно разных аспектах. SWE-Bench Pro и TerminalBench 2.1, выбранные Sakana AI, — это "крепкие орешки", ориентированные на реальную инженерную среду.
SWE-Bench Pro фокусируется на способностях в области программной инженерии, требуя от модели локализовать и исправить ошибки в реальных кодовых базах. Согласно данным, опубликованным в консоли Sakana AI, Fugu Ultra набрала 73,7 балла в SWE-Bench Pro. Для сравнения: Claude Opus 4.8 — 69,2 балла, GPT-5.5 — 58,6, Gemini 3.1 Pro — 54,2. На другом тесте TerminalBench 2.1, проверяющем способности к системным операциям, Fugu Ultra набрала 82,1 балла, превзойдя GPT-5.5 (78,2) и Opus 4.8 (74,6). Эти два теста проверяют не только способность модели генерировать код, но и её логическую стабильность и способность вызывать инструменты в многоэтапных, длинных задачах. Лидерство Fugu Ultra означает, что при решении сложных инженерных проблем она реже, чем монолитные модели, дает сбои на полпути или отклоняется от цели.
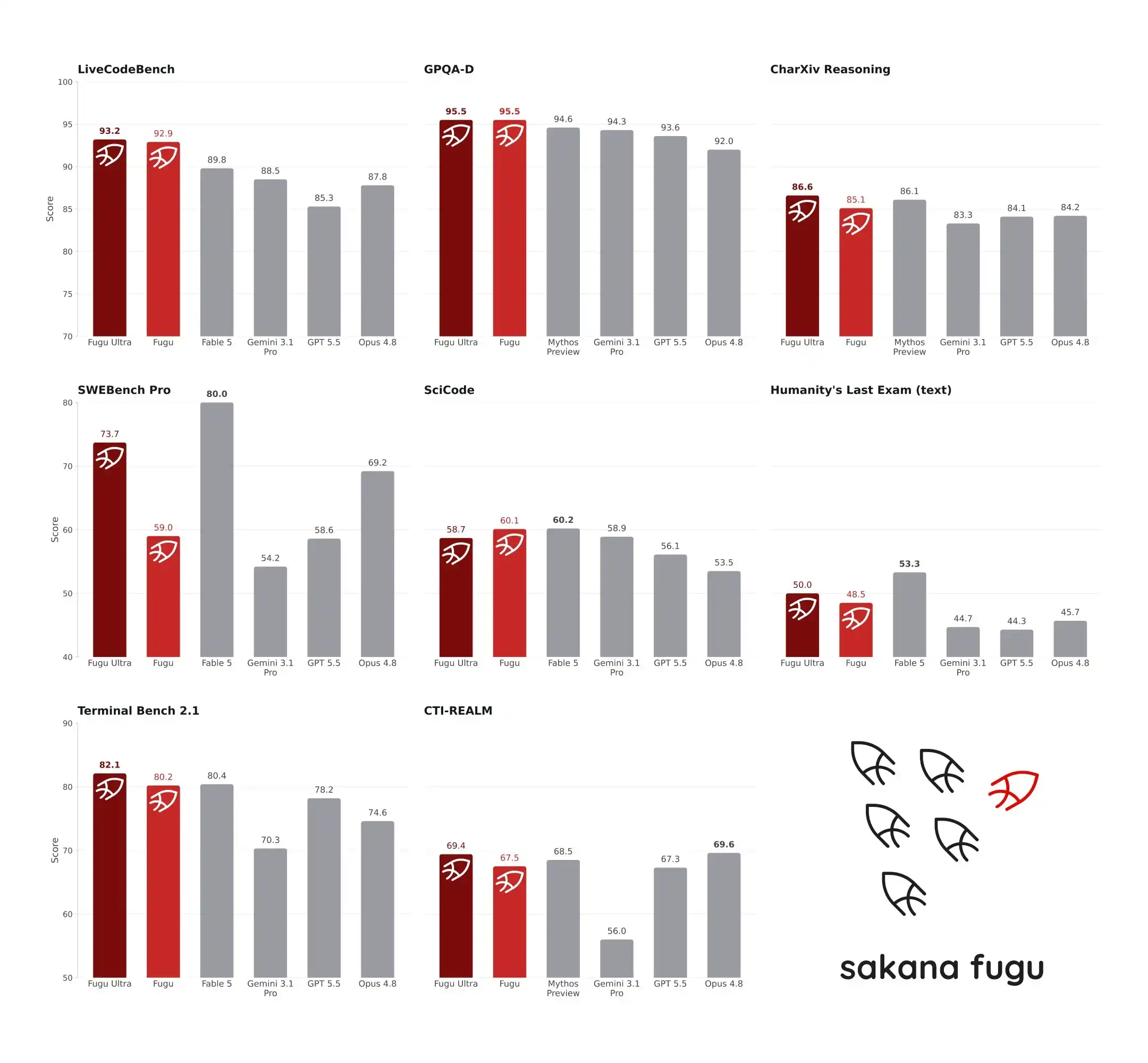
Больше внимания привлекло сравнение Fugu с Fable 5 и Mythos Preview. Серия Fable от Anthropic и серия Mythos от другой передовой лаборатории представляют собой вершину современных возможностей логического вывода в ИИ. Однако из-за экспортных ограничений или неполного раскрытия информации эти две модели не входят в пул агентов Fugu. Sakana AI официально заявила, что Fugu Ultra "сравнима" с Fable 5 и Mythos Preview в инженерных и научных тестах, но важно понимать, что это сравнение не основано на тестах в одном пуле. Результаты Fugu основаны на фактических результатах работы её собственной системы, в то время как данные Fable и Mythos основаны на отчетных баллах, опубликованных их производителями.
Такой подход к сравнению вызвал некоторые споры в сообществе разработчиков. Некоторые считают, что условия тестирования в разных системах и средах трудно полностью выровнять, и прямое сравнение баллов несправедливо. Но другие разработчики отмечают, что в отсутствие единой среды для реальных тестов ссылка на данные отчетов производителей является отраслевой практикой. Оставив в стороне споры о сравнении с Fable и Mythos, превосходство Fugu Ultra над GPT-5.5 и Opus 4.8 в SWE-Bench Pro и TerminalBench 2.1 является реальным сравнением в одинаковых условиях. Это превосходство достигнуто не потому, что базовая модель Fugu умнее GPT-5.5, а потому, что RL Conductor лучше справляется с декомпозицией задач и распределением экспертов. В экспериментах, требующих многораундовых рассуждений и проверок, таких как AutoResearch, сборка кубика Рубика и механическое проектирование, Fugu также последовательно демонстрирует преимущества. Это показывает, что при обработке "длинных, запутанных, многоэтапных" рабочих процессов реального мира архитектура с оркестровкой множественных агентов действительно более устойчива, чем монолитная модель.
Тестирование в реальных сценариях разработки: Проверка кода и стабильность длинных сессий
Для разработчиков и пользователей инструментов ИИ результаты тестов — это лишь ориентир; то, что действительно определяет, хороша ли модель, — это её производительность в реальных рабочих сценариях. Перед выпуском Fugu прошла бета-тестирование почти у 500 ранних пользователей, и их отзывы раскрыли уникальную ценность Fugu в практическом применении.
Проверка кода — один из наиболее часто используемых разработчиками сценариев ИИ. Традиционные монолитные модели при проверке кода часто могут найти только поверхностные синтаксические ошибки или распространенные логические уязвимости. В бета-тестировании некоторые разработчики отметили, что Fugu проявила необычайную тщательность в проверке кода, способную обнаружить глубокие архитектурные ошибки, в то время как другие инструменты часто находили лишь несколько поверхностных проблем. Эта разница проистекает из архитектуры Fugu. Когда RL Conductor получает задачу проверки кода, он может вызывать модели, специализирующиеся на статическом анализе, логических рассуждениях и проверке безопасности, для перекрестной проверки одного и того же фрагмента кода с разных углов. Этот режим "консилиума экспертов", естественно, позволяет обнаружить больше скрытых проблем, чем "единоборство" одной модели.
Еще одно часто упоминаемое преимущество — стабильность длинных сессий. При создании продуктов с ИИ-агентами одна из самых больших головных болей для разработчиков — это "дрейф личности" модели в длинных разговорах. По мере увеличения количества раундов диалога монолитная модель часто забывает первоначальные настройки или отклоняется в следовании инструкциям. Некоторые руководители компаний после тестирования отметили, что Persona (личность) Fugu в длинных сессиях исключительно стабильна и почти не подвержена дрейфу. Это связано с тем, что сам RL Conductor не отвечает за поддержание памяти длинного текста; он только отвечает за точный выбор наиболее подходящей базовой модели для генерации ответа в каждом раунде диалога на основе текущего контекста. Эта архитектура "разделения управления и генерации" значительно повышает стабильность агента при длительной работе.
В области кибербезопасности Fugu также продемонстрировала сквозную практическую способность. В тестах Fugu могла независимо выполнить полный процесс от разведки, обнаружения уязвимостей XSS/SQLi до проверки аутентификации и сгенерировать полный отчет о тестировании на проникновение, при этом строго соблюдая инструкции не нарушать границы системы. Выполнение таких сложных задач зависит от точной оркестровки RL Conductor инструментария безопасности и возможностей различных больших моделей.
Кроме того, эффективность использования токенов — еще одно большое преимущество Fugu. Традиционные большие модели при решении сложных проблем часто генерируют длинные цепочки рассуждений, потребляя много токенов. RL Conductor Fugu за счет точной маршрутизации избегает бессмысленного потребления длинных CoT. Официальные данные и раннее тестирование показывают, что он может значительно снизить потери на неэффективные токены. Для разработчиков, платящих за токены, это означает не только снижение затрат, но и повышение скорости отклика.
Уязвимость зависимостей: Цена оркестровки множественных агентов
Несмотря на впечатляющие результаты в архитектуре и тестах, Fugu как инструмент для реальной работы не лишена слабых мест. Архитектура оркестровки множественных агентов, приносящая прорыв в производительности, также создает неизбежные риски и ограничения.
Самая основная проблема — это риск зависимости от базовых моделей. Пул агентов Fugu в значительной степени зависит от базовых API американских гигантов, таких как GPT, Claude, Gemini. Хотя RL Conductor обладает способностью к динамической маршрутизации и может переключаться на другие модели в случае сбоя или ограничения одной модели, это лишь позволяет избежать риска отдельного поставщика, но не избавляет от и не может избавиться от всей экосистемы американской инфраструктуры ИИ. Если эти базовые модели коллективно поднимут цены, введут масштабные ограничения или изменят условия API, структура затрат и стабильность Fugu окажутся под прямым ударом. Эта модель "паразитирования" на чужой инфраструктуре по своей природе хрупка с точки зрения коммерциализации и долгосрочной стабильности.
Во-вторых, это компромисс между задержкой и структурой затрат. Хотя RL Conductor экономит потребление неэффективных токенов за счет точной маршрутизации, оркестровка множественных агентов неизбежно включает в себя множественные вызовы API и общение между моделями. Для сценариев интерактивного взаимодействия в реальном времени, требующих чрезвычайно низкой задержки, таких как голосовые диалоги в реальном времени или помощь в высокочастотной торговле, время "глубокого размышления и планирования" Fugu Ultra может быть больше, чем при прямом вызове монолитной модели. В тех сценариях, где скорость отклика критически важна, архитектурные преимущества Fugu могут, наоборот, стать тормозом для восприятия.
Кроме того, споры о справедливости сравнений продолжаются. Как уже упоминалось, Fugu заявляет о сопоставимости с Fable и Mythos, но последние не входят в её пул агентов. В сообществе разработчиков некоторые голоса подвергают сомнению практическую ценность таких сравнений, основанных на данных отчетов производителей. В конце концов, производительность разных моделей сильно различается в зависимости от распределения задач, и простое сравнение общих баллов может скрыть конкретные преимущества и недостатки. Для разработчиков, которым необходимо точно оценивать возможности модели, отсутствие данных реальных тестов в одном пуле означает, что при выборе модели все равно необходимо сохранять осторожность.
Не мощность, а оркестровка: Асимметричный прорыв Японии в области больших моделей
Выходя за рамки конкретного обзора продукта, появление Fugu имеет более глубокое значение для экосистемы больших моделей Японии. В глобальной гонке вооружений в области ИИ Япония находится в неловком положении. У неё нет ни такого непрерывного потока передовых вычислительных мощностей и накопления алгоритмов, как у США, ни такого огромного пула данных и острой рыночной конкуренции, как у Китая. Более того, Япония сталкивается с рисками экспортных ограничений на передовые американские модели (такие как Fable/Mythos). В этом контексте путь Sakana AI — "эволюционные алгоритмы" и "оркестровка множественных агентов" — демонстрирует логику "асимметричного прорыва" страны с ограниченными ресурсами.
На местном рынке Японии есть производители больших моделей. NTT выпустила tsuzumi, такие организации, как ELYZA, Rinna и LLM-jp, также стремятся обучать местные языковые модели. Но большинство этих производителей идут по традиционному пути "обучения с нуля" и по масштабу параметров и универсальным возможностям вряд ли могут конкурировать с ведущими китайскими и американскими моделями. Sakana AI — единственная лаборатория среди них, обладающая влиянием на мировом передовом уровне и делающая ставку на "асимметричную архитектуру".
Способность Fugu к динамической маршрутизации по сути помогает японским компаниям и учреждениям обрести "суверенитет в области ИИ". В условиях ограниченных вычислительных мощностей вместо того, чтобы тратить огромные средства на обучение модели с сотнями миллиардов параметров, которая во всех аспектах уступает GPT-5.5, лучше обучить умного 7B "прораба". Этот прораб может гибко подключаться к лучшим мировым моделям в зависимости от потребностей задачи. Если однажды какая-либо американская модель попадет под экспортные ограничения или будет отключена, RL Conductor сможет быстро перенаправить задачу другим доступным моделям или даже подключить местные специализированные японские модели. Такая архитектура дает Японии определенную степень автономии и устойчивости к рискам в использовании возможностей ИИ.
Наблюдая за глобальной экосистемой инструментов ИИ, OmniTools отмечает, что возможности больших моделей постепенно выравниваются, и главное поле битвы смещается от простого наращивания параметров к цепочкам инструментов и сценариям внедрения. Появление Fugu как раз подтверждает эту тенденцию. Она больше не стремится сделать одну модель идеальной, а стремится достичь оптимальности на системном уровне. Такой подход имеет важное значение для стран и регионов, которые не обладают преимуществами в вычислительных мощностях и данных.
Конечно, у этого "асимметричного прорыва" тоже есть свой потолок. Пока ключевые технологии базовых моделей остаются в руках нескольких гигантов, верхний предел возможностей системы оркестровки будет ограничен возможностями базовых моделей. Fugu доказала, что 7B-модель может быть отличным командиром, но она не может создать способности, которых нет у базовых моделей. Для реального прорыва японских больших моделей, помимо инноваций в архитектуре оркестровки, по-прежнему необходимы постоянные инвестиции в базовые вычислительные мощности, ключевые алгоритмы и качественные данные. Fugu — это изящное системное нововведение, но она не панацея. Для разработчиков и корпоративных пользователей Fugu предлагает новую, очень конкурентоспособную альтернативу в сложных инженерных сценариях, но при её использовании также необходимо четко осознавать хрупкость её базовых зависимостей и компромисс между задержкой и затратами.








