Автор: Пятница, TechFlow глубокого анализа
Anthropic только что представила бумажные результаты, которые выглядят безупречно.
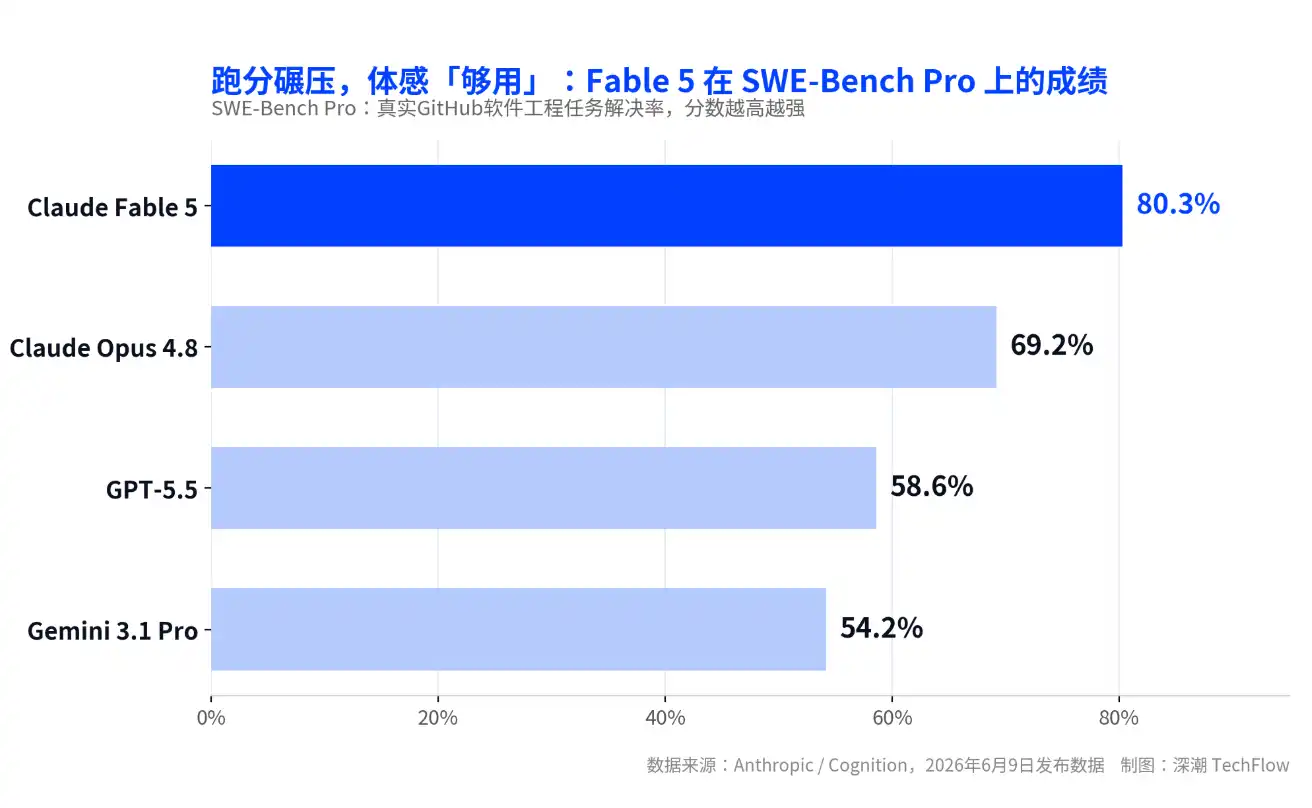
Выпущенная 9 июня Claude Fable 5 — это первая общедоступная модель компании уровня Mythos, которая набрала 80,3% в бенчмарке SWE-Bench Pro для задач реального программного инжиниринга, что примерно на 11 процентных пунктов опережает её предыдущий флагман Opus 4.8 и более чем на 20 пунктов — GPT-5.5.
Но реакция пользователей охладила энтузиазм.
Спустя три дня после анонса, в сабреддите r/artificial (еженедельный трафик 305 тыс.) появился горячий тред с заголовком: «Claude Fable дал мне понять, что мне не нужна лучшая модель». Автор, Axi0m-22, рассказал, что некоторое время использовал Fable для исследований по безопасности и рутинных задач, но затем почти сразу вернулся к Opus для написания кода и Haiku для рутины. Он провёл аналогию: Это как смотреть на анонс iPhone 17 с iPhone 14 в руках: «Ты знаешь, что новая модель лучше, но думаешь: да ладно, моя и так хороша».
Топ-комментарии захватили «довольные тем, что есть»: усталость от улучшений стала главным настроением
Комментарий, занявший первое место, набрал 42 лайка: «Помимо большего контекстного окна, я перестал чувствовать потребность в более мощной модели, начиная с Opus 4.5».
Заявление другого пользователя, hyprlab, получило 13 лайков: «Я не вижу пользы для своего рабочего процесса от перехода на модель, которая просто сжигает больше токенов. Высокопроизводительный режим Opus 4.8 уже достаточно удобен».
За такими высказываниями стоит общий расчёт стоимости.
API-цены на Fable 5 составляют $10 за миллион входных токенов, что почти вдвое дороже, чем у Opus 4.8. Пользователь siromega37 высказался прямо: «Расход токенов выше, но нет отдачи на вложения. Мне кажется, мы видим плато. Пузырь, в конечном итоге, лопнет».
Пользователь hobopwnzor дал более системное объяснение: «Мы находимся на вершине S-образной кривой уже некоторое время. Последние улучшения в основном связаны с вызовами инструментов и периферийной инженерией, а не с фундаментальными способностями самой модели».
Защитные ограничения — главная претензия: «90% запросов просто отклоняются»
Если «достаточность» — это лишь настроение, то жалобы на защитные ограничения — это конкретная проблема продукта.
Согласно официальному заявлению Anthropic, Fable 5 использует ту же базовую модель, что и Mythos 5, доступный лишь ограниченному кругу организаций, отличие заключается в установленных в Fable классификаторах безопасности: запросы, касающиеся таких областей высокого риска, как кибербезопасность, перехватываются и перенаправляются для ответа на Opus 4.8. Компания заявляет, что эта механизм настроен консервативно, срабатывая в среднем менее чем в 5% сессий, и может ложно блокировать безвредные запросы.
В этой ветке Reddit ощущаемая частота срабатываний явно намного выше 5%. Пользователь jradoff, чей комментарий набрал 17 лайков, сказал, что попросил Fable проверить безопасность своего кода, и «как только упоминается что-то, связанное с безопасностью, он почти всегда отказывается обрабатывать», после чего запрос переадресовывается Opus. Ещё один комментарий с 12 лайками был менее сдержан: «90% того, что вы хотите с ним сделать, будет отклонено, что делает его бесполезным».
Недовольство платящих пользователей было ещё сильнее. Пользователь kaitava с подпиской за $200 написал: «Я плачу вдвое больше за использование, хочу, чтобы он провёл проверку безопасности, а меня понижают до Opus. Теперь мне в нём не нравится всё. Жду, когда OpenAI догонит».
Для флагманского продукта, основное преимущество которого — скачок в возможностях, «плата за безопасность в виде удобства использования» становится ключевой переменной в решении пользователя о покупке.
Голоса оппонентов: для пользователей со сложными задачами разница — «как между ночью и днём»
Не все в треде были согласны с негативом, и портрет оппонентов довольно чёток: чем сложнее задачи, тем выше оценка.
Комментарий пользователя Phylaras набрал 15 лайков: «Fable для меня дал существенную разницу. В тех сложных задачах, которые требуют огромного контекстного окна, он нашёл ошибки, которые раньше не замечались». Пользователь, назвавшийся занимающимся моделированием в физике высоких энергий, сказал, что отдельные модели симуляции часто содержат от 8000 до 10 000 строк кода, с сотнями взаимодействующих моделей: «Модель, которая может самостоятельно и непрерывно работать, понимая детали среды, для меня — это то, чего очень ждёшь».
Самое резкое возражение было от пользователя Navetz: «Честно говоря, тот, кто использовал эту модель, сочтёт подобные посты безумием. Для меня она умнее настолько, что кажется другой личностью. Я пользуюсь ей постоянно. Я объяснил не-техническому другу: это как перейти прямо от студенческого игрока к стартовому составу НБА».
Кто-то предложил компромиссный подход. Пользователь ready-eddy посоветовал использовать Fable как «планировщика и исправителя», а не ежедневного «строителя», если только не жалко денег. Другой комментарий подвёл итог больше похоже на руководство: использовать Fable для вычислений в таблицах — значит выбрать неправильную модель; использовать Haiku для запуска 16 сложных агентов с ИИ — тоже выбрать неправильную модель. «Нет изначально плохих моделей, есть модели, используемые не по назначению».
После разрыва между бенчмарками и ощущениями, станут ли публичные ИИ сильнее?
Самый интересный комментарий в этой дискуссии сместил фокус с продукта на структуру индустрии.
Пользователь KedMcJenna выдвинул «тезис о заморозке публичного ИИ»: модели, доступные обычным людям, могут навсегда остаться примерно на текущем уровне, в то время как корпоративные и государственные элиты будут продолжать получать более мощные приватные модели. «Мы знаем как минимум о Mythos, и, вероятно, есть ещё более сильные модели, о которых мы никогда не услышим».
Этот комментарий указывает на факт: Mythos 5 действительно не является публично доступным и в настоящее время предлагается только организациям по киберзащите и предприятиям критической инфраструктуры через программу Project Glasswing.
Совместный взгляд на бенчмарки и общественное мнение приводит к непротиворечивому выводу.
Бенчмарки измеряют верхний предел возможностей, а топ-комментарии на Reddit отражают потолок повседневных потребностей. Когда задачи большинства пользователей уже удовлетворялись на уровне Opus 4.6, более сильные модели могут доказать своё превосходство только в экстремальных сценариях, таких как физическое моделирование или сверхдлинный контекст. Перед производителями моделей стоит уже не вопрос «можем ли мы это сделать», а вопросы «кому это нужно, сколько они готовы платить и какой компромисс в удобстве из-за безопасности они готовы терпеть».
Спустя три дня после выпуска Fable 5 получил два совершенно разных отчёта — в таблице бенчмарков и на поле общественного мнения. Какой из них ближе к истине, будет зависеть от того, как быстро Anthropic скорректирует классификаторы безопасности и как проголосуют кошельки пользователей со сложными задачами.








