В этом году американская "большая тройка" ИИ начала наклеивать на свои модели и продукты "футуристические" ярлыки.
OpenAI заявила, что ChatGPT научился "мечтать"; Anthropic хочет оснастить Claude встроенной "личной вики"; Google же заявляет, что Gemini "по умолчанию имеет десятилетнюю память".
Эти три заявления, кажущиеся несвязанными, на самом деле конкурируют за одну и ту же вещь — Контекст.
Раньше контекст был лишь незаметным техническим параметром, измеряющим, сколько символов модель может прочитать за раз. Сегодня значение контекста расширяется: это актив пользователя, права доступа к инструментам, текущее состояние выполнения задачи и, прежде всего, насколько хорошо ИИ понимает вас.
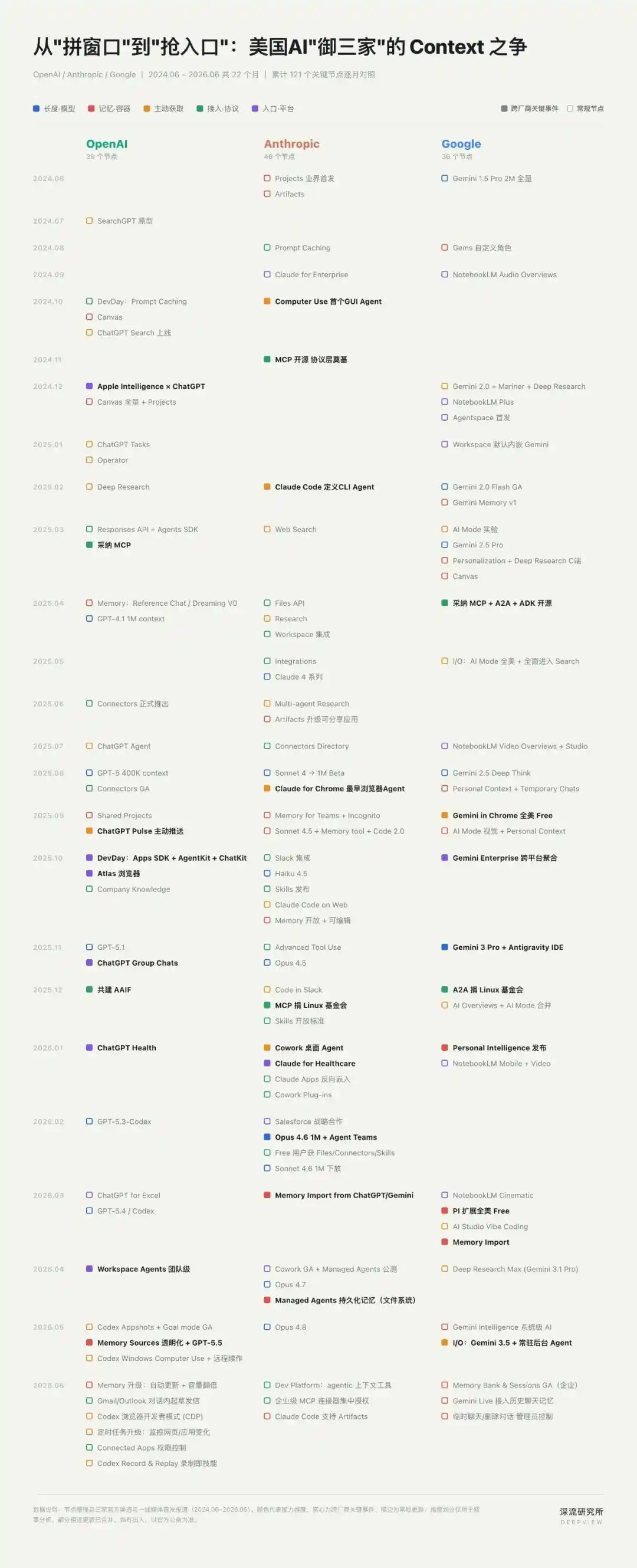
По данным "Института глубоких исследований" (深流研究所), с начала года OpenAI, Anthropic и Google выпустили более 40 важных обновлений продуктов и функций, связанных с контекстом — в среднем каждые три-четыре дня на рынок выходит новая возможность.
От длинных контекстных окон до памяти между сессиями и возможностей работы с браузером, рабочим столом и GUI — самые важные изменения в продуктах ИИ за последние два года почти все были связаны с контекстом.
Война за "контекст" уже началась, и она тихо перестраивает защитные барьеры в эпоху ИИ.
1. От длинных окон к реальной среде: три перехода в границах контекста
Первая конкуренция в области контекста началась с "длины текста".
В эпоху чат-ботов контекст в основном означал, сколько информации модель может обработать за один раз. Чем длиннее окно, тем лучше модель может работать с научными статьями, базами кода и даже полной документацией проекта. Так OpenAI, Anthropic и Google развязали гонку за контекстные окна.
В мае 2023 года Anthropic первой увеличила контекстное окно Claude с 9K до 100K токенов (примерно 75 000 слов), сделав возможной загрузку целой книги. В ноябре 2023 года OpenAI ответила GPT-4 Turbo с окном в 128K. Три месяца спустя Google с Gemini 1.5 Pro вывел окно на уровень в миллион токенов.
Менее чем за год контекст вырос с сотен тысяч до миллионов токенов.
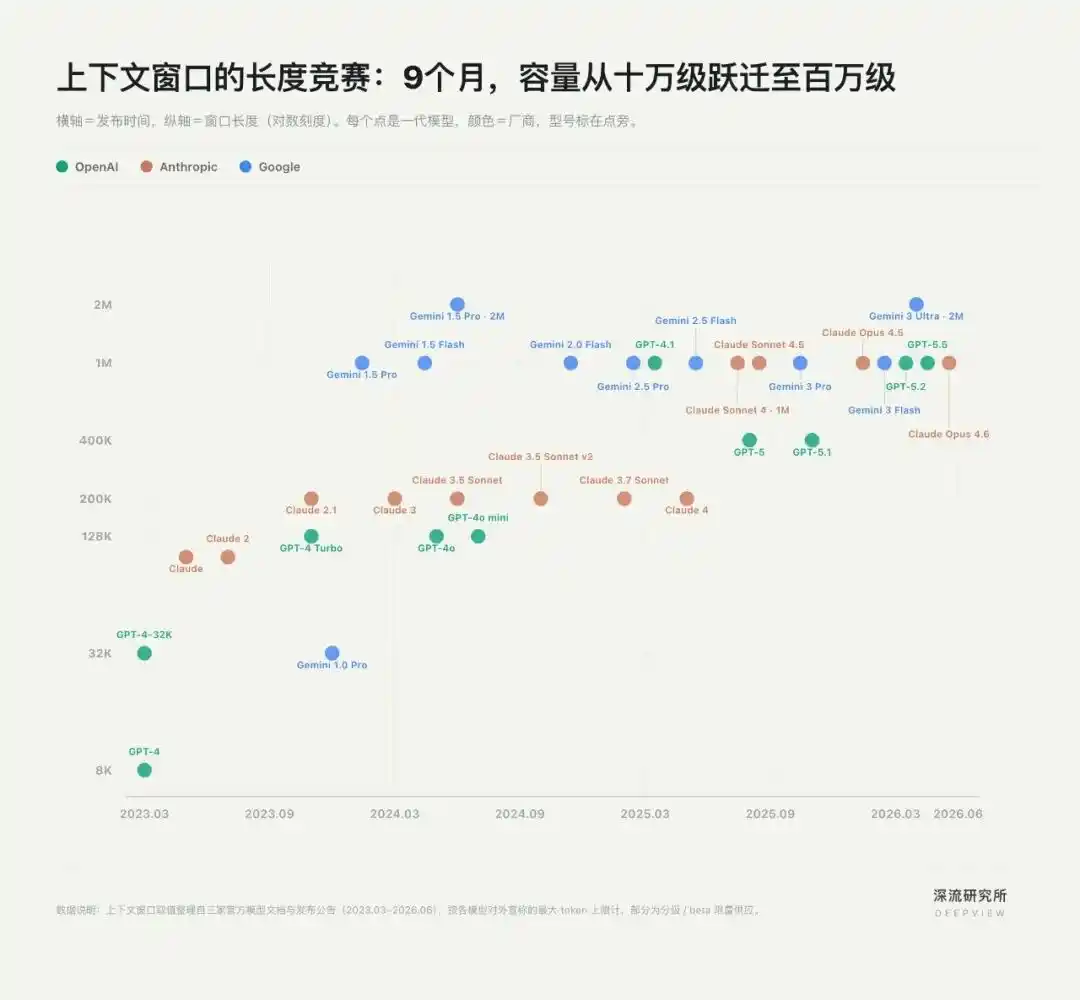
Длинные окна решили проблему "пропускной способности" ИИ, но эта гонка быстро выявила свои ограничения: то, что модель может видеть больше информации, не означает, что она будет лучше понимать задачу.
Особенно когда продукты ИИ перешли от чат-ботов к агентам, границы контекста начали меняться. Теперь это не просто входной текст одного диалога, а постоянно накапливаемый и динамически обновляемый поток состояния в цикле выполнения задачи.
Фокус конкуренции сместился: с вопроса "сколько модель может узнать за раз" к вопросу "что модель может запомнить в долгосрочной перспективе". Память стала типичной формой продукта на этом этапе.
В начале 2024 года OpenAI первой представила межсессионную память для ChatGPT, позволив модели запоминать предпочтения, контекст и долгосрочные потребности пользователя. Вскоре Anthropic и Google также добавили возможности памяти в Claude и Gemini.
Контекст обрел временное измерение. ИИ перестал просто обрабатывать текущий ввод и начал пытаться установить преемственность между взаимодействиями пользователя сегодня, на прошлой неделе и в прошлом месяце. Только ИИ с долгосрочным контекстом может соединить разрозненные взаимодействия в непрерывные отношения.
Однако память отвечает на вопрос "что произошло в прошлом", но не касается другого, более важного вопроса: что происходит сейчас?
Настоящий водораздел появился во второй половине 2025 года.
В августе этого года три компании почти одновременно перенесли фронт конкуренции в сфере контекста в браузер: Anthropic выпустила Claude для Chrome, Google встроила Gemini в Chrome, а OpenAI представила независимый ИИ-браузер ChatGPT Atlas.
Браузер — это естественная кладовая контекста. Содержимое веб-страниц, поисковые запросы, статус входа, формы, история, вкладки и задачи, которые выполняет пользователь, — все это оседает в браузере. Что еще важнее, здесь контекст более актуален, непрерывен и близок к реальной среде выполнения задачи.
Раньше способ, которым ИИ получал контекст, по сути, сводился к ожиданию, когда пользователь предоставит материалы: загрузка файлов, ввод команд, предоставление доступа к памяти, подключение источников данных.
После выхода в браузер логика изменилась. ИИ начал входить в рабочую среду пользователя, наблюдать за состоянием страницы, понимать прогресс задачи, улавливать намерения действий и выполнять следующие шаги в реальном интерфейсе.
Это третий переход в границах контекста: он превратился из статических данных, вводимых на стороне модели, в динамическое состояние, которое агент захватывает в GUI, веб-страницах и системной среде.
Длинные окна определяют, сколько информации модель может принять за раз; память определяет, может ли модель понимать пользователя во времени; а возможности работы с браузером, настольными продуктами и GUI определяют, может ли модель войти в реальную среду выполнения задачи.
Вместе эти три аспекта составляют основную линию конкуренции продуктов ИИ за последние два года: контекст больше не является просто вопросом возможностей модели, а постепенно превращается в вопрос входа в продукт, отношений с пользователем и накопления активов.
2. Контекст как новое поле битвы: три пути "большой тройки" американского ИИ
Когда контекст превращается из параметра модели в актив пользователя, ядро конкуренции становится вопрос: кто может стабильнее получать, организовывать и использовать контекст.
Исходя из этого, OpenAI, Anthropic и Google выбрали три разных пути.
ChatGPT — это основной источник контекста для OpenAI.
Память, предпочтения, история задач и записи использования инструментов, которые пользователь оставляет в ходе бесед, постепенно накапливаются в рамках одной учетной записи ChatGPT.
Эта учетная запись отличается от традиционных интернет-аккаунтов. Традиционные аккаунты фиксируют статус входа, подписки и платежную информацию; учетная запись ChatGPT фиксирует "историю, понятую ИИ".
Это актив пользователя, родственный ИИ. Его ценность проявляется не только в более персонализированных ответах, но и в снижении затрат на "холодный старт", продолжении состояния задачи и повторном использовании одного и того же понимания пользователя в разных сценариях продукта.
Для OpenAI, из-за отсутствия собственной экосистемы данных, как у Google, необходимо, чтобы пользователи постоянно генерировали новый контекст в рамках системы ChatGPT.
Поэтому действия OpenAI по разработке продуктов за последние два года были направлены на постоянное расширение радиуса задач, который может охватить учетная запись ChatGPT — Apps SDK позволил сторонним приложениям войти в ChatGPT, Atlas включил браузер в ChatGPT, а недавно интегрированный Codex добавил задачи программирования в единый рабочий процесс.
Особый путь OpenAI заключается в том, что она не сначала захватывает точку входа, а затем подключает ИИ; она использует ChatGPT как отправную точку и, наоборот, привлекает приложения, браузер, программирование и другие сценарии обратно в единую систему аккаунтов.
Таким образом, ChatGPT перестает быть просто точкой входа для диалога, а становится центром, который собирает, использует и обновляет контекст.
В отличие от нее, у Anthropic нет ни точки входа для конечных пользователей, ни больших объемов данных существующих пользователей.
Ее путь заключается во внедрении в такие высокоценные вертикальные сценарии, как программирование и агенты, и в усилении способности Claude активно получать контекст в этих сценариях.
Для Claude контекст — это не текст, введенный пользователем, а динамически меняющаяся среда в месте выполнения задачи: репозитории кода, файловая система, вывод терминала, страницы браузера, базы данных, документация проекта и обратная связь после каждого шага выполнения.
Поэтому Anthropic больше делает акцент на активном получении контекста. Модель не должна просто ждать ввода пользователя, она также должна активно входить в среду, считывать состояние и получать обратную связь в процессе выполнения задачи.
В октябре 2024 года Anthropic представила "Использование компьютера" (Computer Use), позволив Claude перемещать мышь, нажимать кнопки и вводить текст на основе снимков экрана.
Согласно официальному заявлению, Claude 3.5 Sonnet — это первая передовая модель ИИ, публично предоставившая возможность использования компьютера.
Это означает, что когда контекст находится в веб-страницах, формах, интерфейсах внутренних систем и локальных программ, а не в структурированных API, Claude также может войти в среду через GUI, наблюдать за состоянием и выполнять операции.
Месяц спустя Anthropic выпустила MCP (Model Context Protocol). Этот открытый протокол, соединяющий ИИ-помощников с внешними инструментами и источниками данных, официально определен как подключение ИИ-помощников к "системам, где находятся данные", включая библиотеки контента, бизнес-инструменты и среды разработки.
Его ценность в том, что он позволяет Claude больше не зависеть от копирования и вставки пользователем, а получать доступ к внешним инструментам и источникам данных стандартным способом.
Эти два типа возможностей соответствуют двум путям получения контекста Anthropic:
Computer Use входит в интерфейс через GUI, MCP подключается к системам через протокол. Один входит в место выполнения задачи, другой соединяется с внешними инструментами, вместе они позволяют Claude получать динамический контекст.
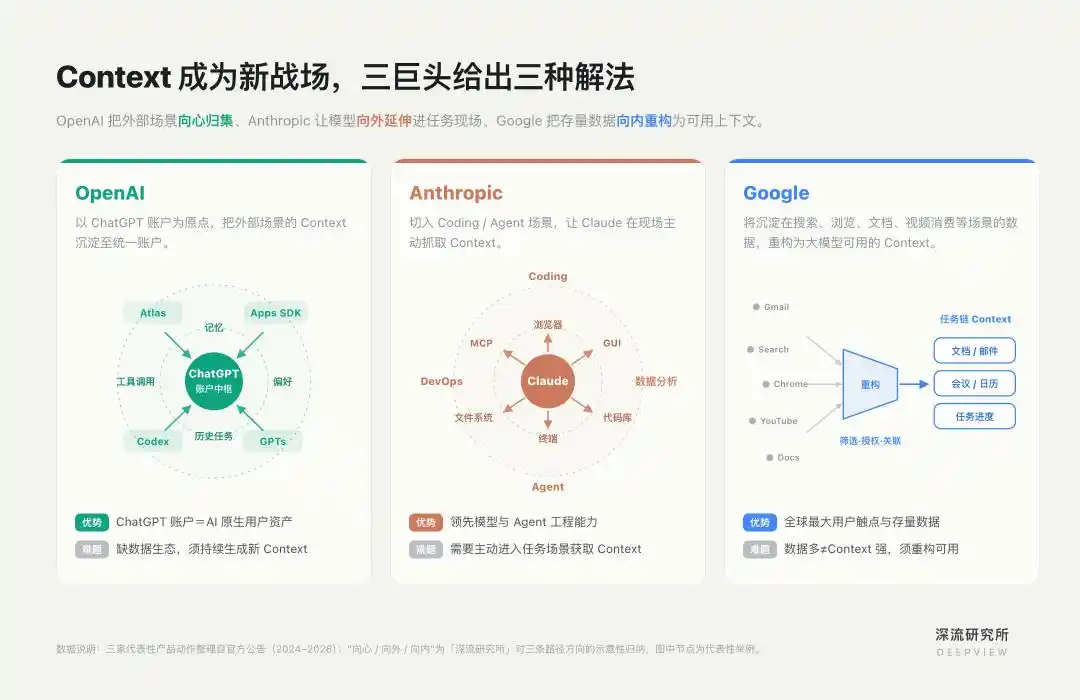
Теперь посмотрим на Google. Часто говорят, что Google — одна из компаний, обладающих наибольшим количеством контекста. Ей не не хватает точек входа и данных. Такие продукты, как Chrome, Gmail, YouTube и Search, составляют одну из крупнейших в мире точек контакта с пользователями.
Но с точки зрения ИИ, больше данных не означает сильнее контекст.
Google в прошлом накапливала данные о поиске, просмотре, почте, документах, местоположении, потреблении видео и т.д., в основном для ранжирования поиска, показа рекламы, рекомендации контента и совместной работы. По сути, это сигналы поведения, необходимые для работы системы.
Агентам же нужен контекст задачи, который может быть понят, осмыслен и использован моделью.
Только когда модель может определить, какая информация актуальна для текущей задачи, какая устарела, какую можно использовать и как эта информация связана между собой, данные действительно превращаются в контекст.
Google сталкивается не с простым "подключением данных", а с реконструкцией данных. Ей необходимо заново отфильтровать, связать, предоставить доступ и преобразовать разрозненные старые данные из разных продуктов, служившие разным системным целям, в личный контекст, пригодный для использования Gemini.
Сложность этой инженерной задачи не ниже, чем у OpenAI, которая заново накапливает контекст, или у Anthropic, которая входит в среду выполнения задачи.
За последние два года действия Google в области продуктов не были направлены на создание чего-то с нуля, а шли по пути преобразования существующих позиций. Суть этого пути — организация фрагментированных данных в цепочки задач.
В мае 2024 года Gemini 1.5 Pro вошла в боковую панель Workspace, позволив модели сначала использовать текущий контекст в рабочих сценариях, таких как Gmail, Docs, Drive.
В июле 2025 года приложение Gemini начало подключаться к таким инструментам, как Gmail, Drive, Calendar, расширив контекст от отдельных приложений до межприкладных задач.
В январе 2026 года была выпущена тестовая версия "Персонального интеллекта" (Personal Intelligence), которая еще больше включила личные данные из Gmail, Photos и других сервисов в персональный контекст Gemini.
Стратегия Google в области контекста — не "много данных, поэтому естественно лидирует".
Ей действительно необходимо завершить проект по повышению полезности данных: преобразовать накопленные в прошлом данные о поведении, служившие таким системным целям, как поиск, реклама и рекомендации, в контекст, который можно понять, разрешить и использовать в эпоху ИИ.
3. От "масштаба сети" к "индивидуальной глубине": барьеры в эпоху ИИ меняются
За последние два года OpenAI, Anthropic и Google ускорили накопление и изучение контекста, создавая вокруг него возможности получения, организации и использования, пытаясь сформировать новые конкурентные барьеры.
Но, казалось бы, противоречивое изменение также происходит параллельно: с начала года все три компании сделали память прозрачной, объяснимой и даже переносимой.
В марте 2026 года Anthropic и Google почти одновременно представили "Импорт памяти" (Memory Import), позволяя пользователям переносить воспоминания между ChatGPT, Gemini и Claude.
Затем OpenAI через "Источники памяти" (Memory Sources) позволила пользователям видеть, какие воспоминания, история чатов или внешние источники данных использовались для формирования персонализированного ответа.
Если контекст — самый важный актив в эпоху ИИ, почему платформы начинают открывать доступ к нему?
Ответ в том, что Memory Import действительно открывает доступ только к поверхностному контексту: предпочтения пользователя, резюме истории, сжатые версии истории диалогов.
Эта информация высоко структурирована и легко описывается естественным языком. Переносить ее технически не очень сложно.
Что действительно трудно перенести, так это другой тип контекста: состояние задачи, права доступа к инструментам, подключение к корпоративным системам, обратная связь в реальном времени из среды выполнения.
Этот контекст глубоко встроен в продукты и системную среду, и его невозможно полностью перенести с помощью одного промпта.
Это также показывает, что логика конкуренции в эпоху ИИ отличается от логики интернет-эпохи.
Основная форма интернета — это сеть. Она соединяет людей, контент, товары, услуги и информацию в узлы. Чем больше узлов и плотнее соединения, тем ценнее продукт. Поэтому самым сильным барьером в интернет-эпохе был сетевой эффект, ценность возникала от большего числа пользователей.
Основная форма ИИ больше похожа на новый тип компьютера или новую информационную систему.
Ее первичная ценность не в том, чтобы соединять больше людей, а в том, чтобы понимать информацию, обрабатывать задачи, использовать инструменты и выполнять действия. Даже ИИ, обслуживающий всего одного пользователя, может создавать огромную ценность.
Следовательно, барьеры в эпоху ИИ, на основе "сетевого масштаба", смещаются в сторону "индивидуальной глубины". Этот барьер "индивидуальной глубины" в основном формируется на трех уровнях:
Во-первых, сложный процент контекста. Каждый раз, когда ИИ выполняет задачу, он лучше понимает стиль общения, критерии суждения, источники информации и рабочие процессы пользователя. При следующем выполнении затраты на "холодный старт" будут ниже.
Во-вторых, интеграция прав доступа и цепочки инструментов. Когда пользователь предоставляет ИИ доступ к своей почте, документам, базам кода и т.д., ИИ перестает быть просто заменяемым инструментом для вопросов и ответов, а входит в реальную среду выполнения задач.
В-третьих, формирование доверительных отношений. Чем сложнее и ценнее задача, тем меньше вероятность, что пользователь просто доверит ее незнакомому ИИ. Только ИИ, который давно понимает пользователя, знает границы и может продолжать контекст, может быть допущен к выполнению следующего шага.
Если интернет-продукты боролись за точку входа внимания, то продукты ИИ борются за точку входа в задачи.
Как только ИИ постоянно входит в рабочий процесс пользователя, накапливает контекст и получает права на выполнение, стоимость перехода — это не просто смена приложения, а необходимость заново выстраивать отношения выполнения задач, основанные на понимании, предоставлении доступа и доверии.
Изменения в отечественных продуктах также можно понять в рамках этой логики.
Возьмем Tencent в качестве примера. В интернет-эпоху она накопила сеть контактов, контент, экосистему услуг и точки входа с высокой частотой использования; в эпоху ИИ ценность этих активов заключается в том, можно ли их реорганизовать в контекст, который агенты могут понимать, использовать и выполнять.
Будь то подключение WorkBuddy к рабочим сценариям, таким как документы, встречи, корпоративный WeChat, или попытки WeChat "Xiao Wei" использовать мини-программы и сервисы в экосистеме WeChat, по сути, все это превращает изначально предназначенные для людей контент, отношения и процессы в среду выполнения задач, в которую может войти ИИ.
Как верно заметил главный научный сотрудник Tencent по ИИ Яо Шуньюй: Контекст, кажущийся активом данных, по сути, является комплексным проявлением возможностей продукта, инженерных возможностей и способности к организационной координации.
В интернет-эпохе барьеры зависели от масштаба. В эпоху ИИ барьеры更应该 смотреть на эффективность преобразования:
Кто сможет быстрее превратить существующую экосистему в рабочую среду для ИИ, кто позволит ИИ накапливать более глубокое понимание пользователя с каждой задачей, у того больше шансов создать новые барьеры.
Вот что действительно заслуживает внимания в битве за контекст.
Эта статья взята из официального аккаунта WeChat "Институт глубоких исследований" (深流研究所), автор: Цзян Фэн (绛枫)








