Июнь 2026 года, индустрия больших моделей переживает беспрецедентное "открытое цунами": NVIDIA выпустила 550-миллиардную модель со смешанной архитектурой, Google подарил миру новую мультимодальную версию Gemma, Zhipu открыла исходный код своей флагманской модели с максимально либеральным лицензированием.
Почти все компании рассказывают одну и ту же историю: поместить больше параметров в архитектуру смешанных экспертов (MoE), снизить затраты за счет более разреженной активации, адаптировать ширину сети к различным сценариям развертывания.
Другими словами, вся отрасль отчаянно ищет способ "упаковать больше параметров в тот же вычислительный бюджет".
Однако новая статья исследователей из Mila, Корнелльского и Монреальского университетов задает вопрос, направленный почти в противоположную сторону: Что произойдет, если не добавлять ни одного параметра, а просто "переместить" уже существующие параметры внутри модели?

Название статьи: Tapered Language Models
Ссылка на статью: https://arxiv.org/abs/2606.23670
Контекст: упущенное из виду "равноправие"
С 2017 года и основополагающей статьи о Transformer «Attention Is All You Need», почти все языковые модели разделяют один и тот же каркас, будь то классический Transformer, последующие gated attention, рекуррентные сети с памятью или даже новые архитектуры со способностью к "памяти во время инференса": несколько абсолютно одинаковых "слоев" складываются друг на друга, и каждому слою выделяется абсолютно одинаковое количество параметров.

Это как сеть ресторанов, где в каждом заведении, независимо от локации в центре или пригороде, работает одинаковое количество поваров и одинаковое оборудование, без учета разницы в потоке клиентов. Такой подход "равноправия" прост в обслуживании и управлении, но не обязательно является оптимальным.
В последние годы все больше исследований с разных точек зрения указывают: слои модели не одинаково важны.
Эксперименты с "досрочным выходом" (Early Exit) показывают, что часто ответ модели уже в значительной степени сформирован, не дойдя до последнего слоя.
Исследования "обрезки слоев" (Layer Pruning) показывают, что удаление некоторых последних слоев почти не влияет на производительность модели.
Исследования интерпретируемости обнаруживают, что неглубокие слои фиксируют "базовую информацию", такую как синтаксис, в то время как более глубокие слои обрабатывают "высокоуровневую информацию", такую как семантика.
Другими словами, хотя слои сильно отличаются друг от друга, распределение параметров между ними остается равномерным.
Это и есть центральный вопрос статьи: если неравномерная важность слоев уже давно доказана, почему "емкость мозга" слоев все еще распределяется равномерно?
Смещаем "емкость мозга" вперед
Исследовательская группа начала с простого и наглядного эксперимента: они разделили слои модели Transformer с 440 миллионами параметров на три группы (ранние, средние, поздние) и, сохраняя общее количество параметров неизменным, сделали Feed-Forward Network (FFN — ключевой компонент, отвечающий за хранение и обработку информации в каждом слое, своего рода "рабочая память" слоя) шире в одной группе и уже в двух других.
Результат был очевиден: "неравномерное" распределение с концентрацией емкости в начальных слоях снизило perplexity модели на валидационном наборе (метрика, измеряющая точность предсказаний языковой модели, чем ниже значение, тем лучше) с 16.28 до 15.96. А наоборот, концентрация емкости в конечных слоях, наоборот, подняла perplexity до 17.29.

При одинаковом общем количестве параметров просто из-за разного их расположения разница в результатах составила более одного пункта, что является значительным отрывом в системе оценки языковых моделей.
Это открытие направило вопрос в более тонкое русло: можно ли вместо "грубого" деления на три группы использовать более плавную кривую, чтобы емкость постепенно уменьшалась от начала к концу?
Исследователи назвали этот подход "коническими языковыми моделями" (Tapered Language Models, TLMs): выберите любое измерение в модели, определяющее количество параметров (например, ширину FFN), и заставьте его монотонно уменьшаться по направлению глубины, при этом гарантируя, что средняя ширина всех слоев по-прежнему равна исходному фиксированному значению.
Таким образом, общее количество параметров и вычислительные затраты остаются полностью неизменными, только форма распределения меняется с "прямоугольной" на "клиновидную".
Команда попробовала три типа кривых уменьшения: линейное уменьшение, косинусное уменьшение, S-образное (сигмоидальное) уменьшение.
Разница между этими кривыми похожа на три разных способа "закрытия магазина":
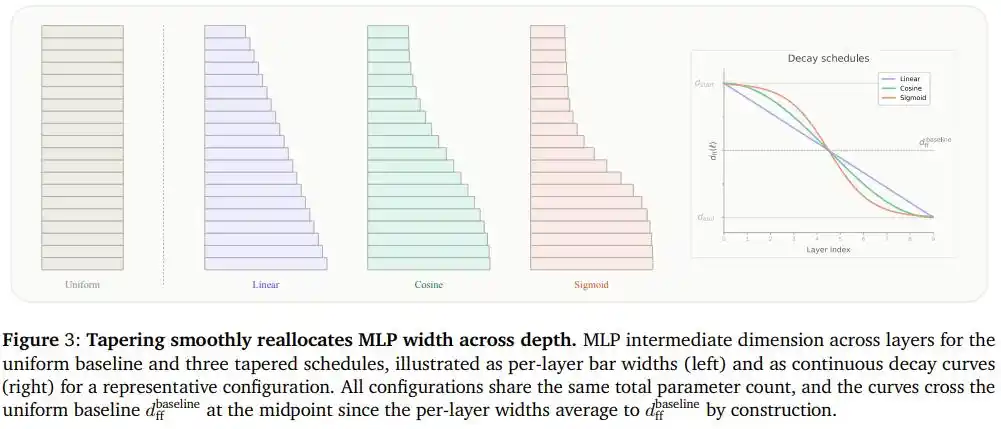
Линейное уменьшение — как равномерное закрытие магазина, где через равные промежутки времени закрывается примерно одинаковое количество стоек.
S-образное уменьшение — как внезапное объявление о закрытии, где большинство стоек остаются как есть, и лишь на коротком промежутке происходит резкое сужение.
Косинусное уменьшение — нечто среднее, с плавным переходом на концах и постепенным сужением в середине. Оно не "отсекает" резко гибкость на концах и не распределяет усилия равномерно, упуская место, где сужение наиболее необходимо.
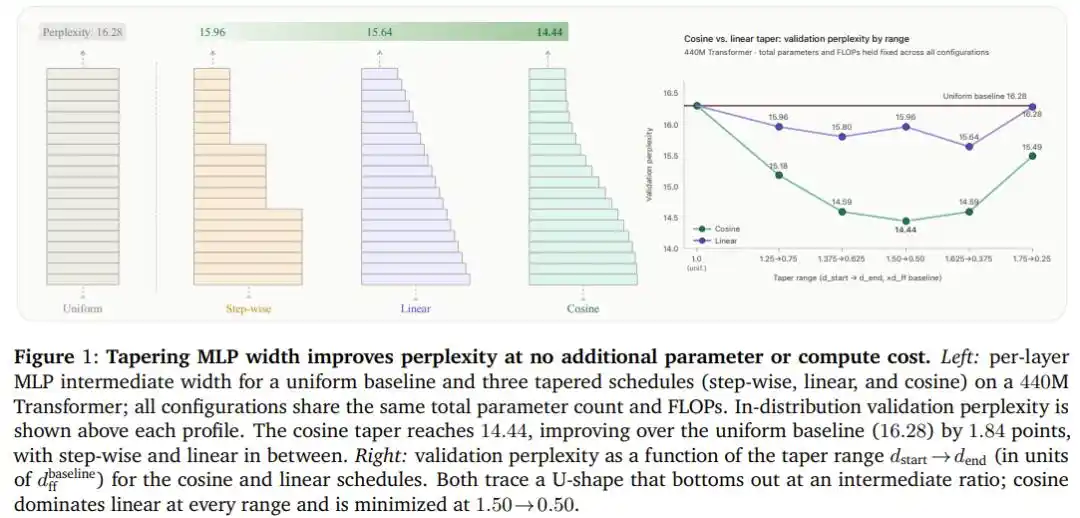
Результаты эксперимента: бесплатные 1.84 пункта
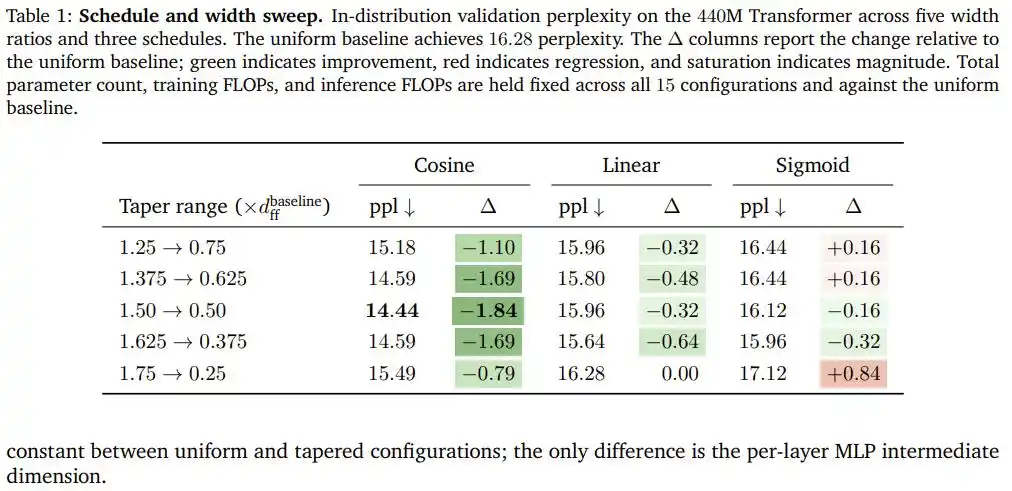
После сканирования всех комбинаций из пяти соотношений ширины и трех типов кривых на модели Transformer с 440M параметров, косинусное уменьшение одержало полную победу: при оптимальной конфигурации (ширина начальных слоев в 1.5 раза больше базовой, конечных — в 0.5 раза) perplexity снизилась с 16.28 (базовая равномерная модель) до 14.44, улучшившись на целых 1.84 пункта, и все это без добавления ни одного параметра или лишней операции с плавающей запятой.
Что еще важнее, этот вывод не является удачей для одной конкретной архитектуры.
Исследовательская группа применила ту же конфигурацию (косинусное уменьшение, соотношение ширины 1.5/0.5) без изменений к трем другим архитектурно различным моделям: модели с механизмом gated attention, модели Hope-attention, обладающей способностью к "самоизменяющейся памяти", и архитектуре Titans с модулями нейронной долгосрочной памяти, и провела повторную проверку на двух более крупных масштабах: 760M и 1.3B параметров.
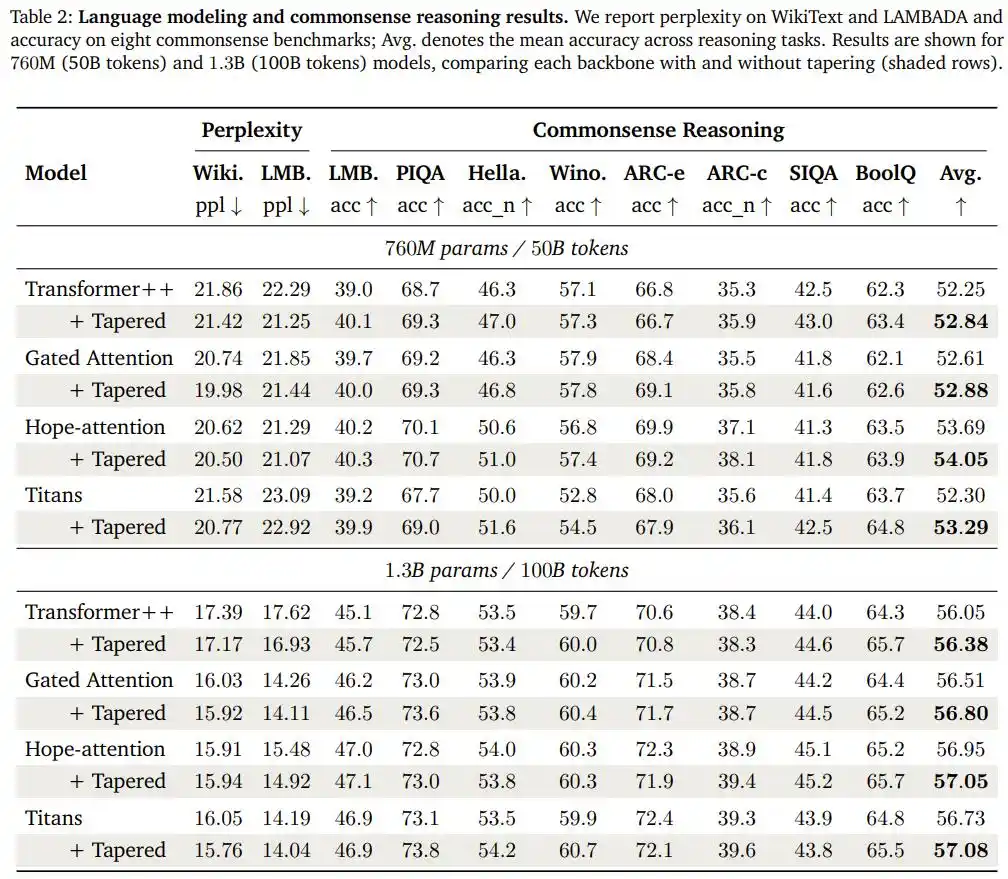
Результат: во всех восьми парах сравнений — четыре архитектуры, два масштаба — у моделей, прошедших "коническое" преобразование, средняя точность на тесте логического вывода (commonsense reasoning benchmark) повысилась, а perplexity на задаче языкового предсказания LAMBADA улучшилась.
Исследователи также дополнительно провели тест на поиск в длинном тексте (Needle-in-a-Haystack), подтвердив, что такое перераспределение не жертвует способностью модели обрабатывать длинный контекст.
Чтобы объяснить причину этого явления, команда также измерила степень сходства выхода "слоя FFN" с существующим потоком информации в серии моделей GPT-2 и обнаружила четкую закономерность: чем глубже в модели, тем больше новый контент, записываемый каждым слоем, похож на уже существующую информацию. Другими словами, более глубокие слои скорее "повторяют и подчеркивают" уже сделанные выводы, а не "создают" новое понимание.
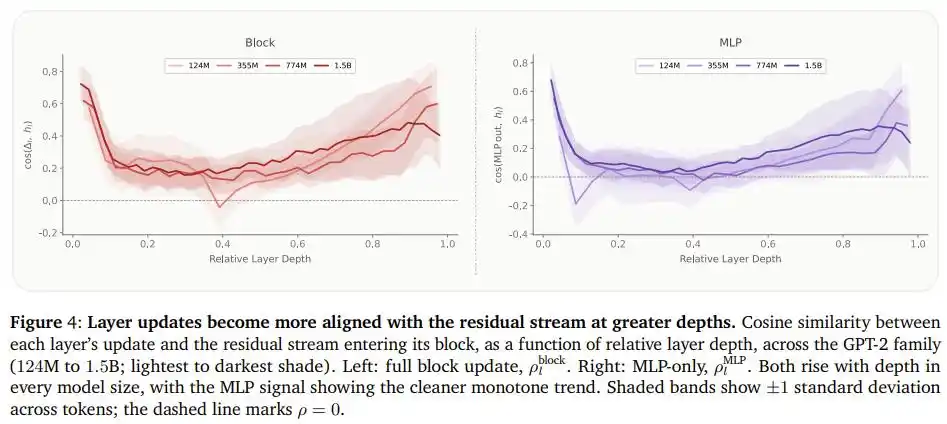
Это как раз подтверждает, почему перемещение емкости из конечных слоев в начальные логично: начальные слои действительно могут использовать эту дополнительную "емкость мозга", конечным же слоям она не так нужна.
Заключение
По своей сути это исследование предлагает простую, но долгое время игнорируемую идею: емкость модели не должна быть равномерно разбросанным ресурсом, она должна направляться туда, где она действительно необходима.
В 2026 году, когда вся индустрия соревнуется в том, "у кого больше параметров" и "у кого архитектура более разреженная", эта статья предлагает практически бесплатную альтернативу: не нужно менять архитектуру, не нужно добавлять параметры, достаточно просто изменить "форму" распределения.
Исследователи также признают, что текущая оптимальная конфигурация была найдена путем настройки на модели с 440M параметров. Остается открытым вопрос, существуют ли "специальные рецепты", более подходящие для моделей разного масштаба и архитектуры.
Но что еще более важно, в статье отмечается, что эта идея не ограничивается языковыми моделями — Vision Transformer, диффузионные модели, мультимодальные модели почти все унаследовали ту же настройку "равномерного распределения по слоям" по умолчанию. Если сама форма распределения емкости — это давно упущенный из виду параметр проектирования, то этот "бесплатный рычаг, скрытый на виду", возможно, только начал привлекать к себе внимание.
Информация о команде
Статья была написана совместно Резой Баятом (Mila — Институт алгоритмов обучения в Монреале), Али Бехрузом (Корнелльский университет) и сооснователем Mila, профессором Монреальского университета Аароном Курвилем.
Али Бехруз в настоящее время является исследователем Google Research и докторантом Корнелльского университета. За последние два года он участвовал в разработке нескольких новых архитектур, привлекших широкое внимание, включая архитектуру Titans, способную "обучаться и запоминать на этапе инференса", а также последующие Atlas и фреймворк "Nested Learning". Он долгое время фокусируется на том, как заставить модели более эффективно использовать и хранить долгосрочную контекстную информацию.
Аарон Курвиль — опытный ученый в области глубокого обучения, CIFAR AI Chair, долгое время совместно с Йошуа Бенджио продвигал фундаментальные исследования в области глубокого обучения, имеет глубокие знания в области обучения представлений и генеративных моделей. Он также является одним из авторов генеративно-состязательных сетей (GAN) и соавтором классической книги «Deep Learning» вместе с Яном Гудфеллоу и Бенджио.
Статья из WeChat Official Account "Машинный разум" (ID:almosthuman2014), автор: Следим за ИИ





