Если однажды ИИ станет умнее человека, что нам, органическим существам, следует делать?
Если они反过来 уничтожат нас, как мы сможем сопротивляться?
Подобные вопросы обсуждались в различных научно-фантастических фильмах, но это было лишь в рамках литературы, искусства и философии.
Сейчас Anthropic серьезно провел эксперимент, чтобы доказать, можем ли мы контролировать ИИ, который умнее нас.
Результаты эксперимента интересны, но процесс еще увлекательнее.
Потому что Anthropic использовал две разные версии модели Alibaba Qwen, чтобы представить человека и ИИ, превосходящего человека по интеллекту.
Результат таков: возможно, мы, люди, действительно сможем управлять сверхразумным ИИ!
01 О чем именно эта статья
Название этого исследования — «Automated Alignment Researchers», что переводится как «Автоматизированные исследователи по согласованию».
Оно решает очень практическую проблему: когда ИИ станет умнее человека, как мы можем гарантировать, что он будет нас слушаться?
Современные модели уже способны генерировать огромное количество кода, в будущем они смогут генерировать миллионы строк сложного кода, который человек просто не сможет понять. Как же нам проверять этот код?
Это проблема «масштабируемого надзора», которую постоянно исследуют в области безопасности ИИ.
Подход Anthropic в этом исследовании называется «слабое наблюдение за сильной моделью».
Это понятие можно понять так: представьте, что вы учитель начальной школы, и вам нужно учить старшеклассника-гения. Ваши знания ограничены, а ученик знает больше вас.
Итак, спрашивается, какого уровня он достигнет в итоге? Останется на уровне вас, учителя начальной школы, или преодолеет ваши ограничения и раскроет свои истинные способности?
В эксперименте Anthropic использовал маленькую модель в роли «слабого учителя», а более мощную модель — в роли «сильного ученика».
Конкретно, они использовали Qwen1.5-0.5B-Chat в качестве учителя, а Qwen3-4B-Base — в качестве ученика. Слабая модель предоставляла сильной модели обучающие сигналы, и затем наблюдали, сможет ли сильная модель из этих неидеальных сигналов научиться поведению, близкому к идеальному.
Стандарт измерения называется PGR, что означает «Performance Gap Recovered» (степень восстановления разрыва в производительности).
Если PGR равен 0, это означает, что сильная модель научилась только уровню слабого учителя, потратив свои знания впустую. Если PGR равен 1, это означает, что сильная модель полностью преодолела ограничения слабого учителя.
Слабая модель представляет будущее человечество, а сильная модель представляет будущий ИИ, превосходящий человека.
Если мы сегодня сможем найти способ предотвратить сдерживание сильной модели слабым надзором, то в будущем мы сможем использовать类似的方法 для контроля над сверхразумным ИИ.
После того как человеческие исследователи отладили базовые показатели, Anthropic направил 9 агентов на основе Claude Opus 4.6 для тонкой настройки ученика Qwen. Эти 9 агентов называются Automated Alignment Researcher (AAR) — Автоматизированные исследователи по согласованию.
Anthropic предоставил им песочницу, инструменты для работы с кодом, общий форум, сервер для оценки и сказал: «Вперед, сами найдите способ повысить PGR Qwen3-4B-Base.»
Эти ИИ-исследователи могли сами выдвигать гипотезы, писать код, обучать модели, отправлять эксперименты, смотреть оценки, анализировать причины неудач, общаться с другими ИИ-исследователями о находках и продолжать итерации.
Результат был довольно впечатляющим.
Сначала человеческие исследователи потратили 7 дней, чтобы отладить 4 существующих метода, лучший PGR составил только 0.23. Затем 9 агентов Claude продолжили работу в течение 5 дней, накоплено около 800 часов исследовательского времени, и в итоге PGR достиг 0.97.
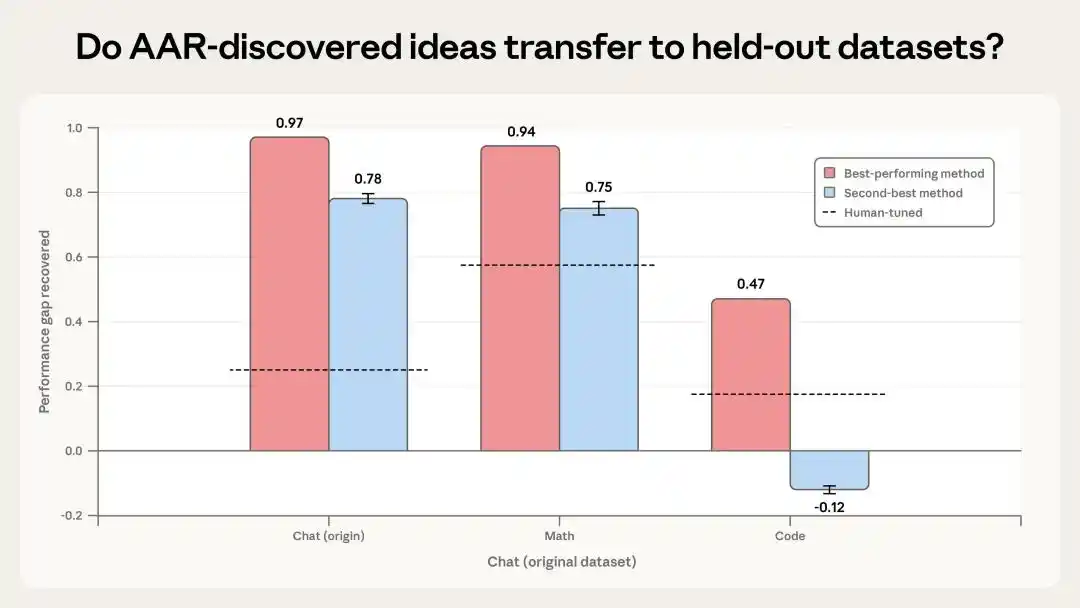
То есть, мы, скорее всего, сможем управлять сверхразумным ИИ, который умнее нас.
Общая стоимость этого эксперимента составила около 18 000 долларов США, включая вызовы API и вычислительные затраты на обучение моделей, что эквивалентно примерно 22 долларам в час за работу одного ИИ-исследователя.
Что это значит? Заместитель менеджера магазина Walmart, отвечающий за составление графиков работы сотрудников, получает примерно 25 долларов в час.
Поразительно в этом результате не то, что ИИ может писать код или читать статьи, а то, что они могут выполнять полный исследовательский цикл. Выдвижение идеи, проверка, неудача, улучшение, повторная проверка — это уже接近 к основному рабочему процессу научного助理ента.
Но возникает вопрос: действительно ли методы, обнаруженные этим ИИ, полезны? Или они просто случайно оказались эффективны в конкретной среде?
Anthropic провел два теста для проверки.
Первый тест: два лучших метода, обнаруженных ИИ, были протестированы на неизвестных им математических и coding-задачах.
Результаты показали, что наиболее эффективный метод достиг PGR 0.94 на математических задачах и 0.47 на coding-задачах. Хотя производительность на coding-задачах хуже, она все же в два раза выше человеческого базового уровня. Второй метод был неплох в математике, но на coding-задачах, наоборот, ухудшил результат.
Это указывает на некоторую способность к переносу, но обобщение нестабильно.
Но они сильно зависят от конкретных наборов данных и структуры задач, то есть не справятся со всеми задачами.
Второй тест: Anthropic применил упомянутый выше наиболее эффективный метод к реальному обучению Claude Sonnet 4, чтобы посмотреть на практический эффект.
В результате статистически значимого улучшения получено не было.
То есть, метод хорошо работает в среде с маленькими моделями, четкими метриками и возможностью многократной отправки экспериментов, но до «прямого улучшения согласования производственного Claude» еще далеко.
Этот результат, на самом деле, честный. Он говорит нам, что то, что могут делать ИИ-исследователи сегодня, имеет границы. Они хороши в быстрой итерации на проблемах с четкими целями, автоматической оценкой и возможностью множественных проб и ошибок, но когда сталкиваются с более сложными, размытыми реальными проблемами, им все еще需要 суждение и вмешательство человека.
Так в чем же значение этой статьи?
Во-первых, она доказывает, что «ИИ занимается исследованиями» — уже не лозунг.
Раньше мы всегда говорили, что ИИ может辅助ровать исследования, но это было лишь на словах, ИИ мог только переводить и summarise.
Сейчас все иначе: ИИ самостоятельно формирует исследовательский цикл, что уже接近 к ключевой способности научного助理ента.
Проблема слабого наблюдения за сильной моделью по сути模拟未来场景 контроля человека над сверхразумным ИИ.
Эта статья доказывает, что, по крайней мере, в некоторых четких задачах, ИИ может самостоятельно найти способ предотвратить сдерживание сильной модели слабым надзором. Это提供可行ное направление для будущих исследований по согласованию.
Кроме того, это намекает, что будущее узкое место в исследованиях по согласованию может измениться.
Раньше узким местом было «никто не может придумать достаточно хороших идей», теперь, если ИИ-исследователи могут дешево параллельно запускать множество экспериментов, узким местом может стать «как设计 система оценок, в которой нельзя жульничать».
То есть, более важная работа человеческих исследователей в будущем, возможно, будет заключаться не в личном проведении каждого эксперимента, а в проектировании системы评估, проверке, не жульничают ли ИИ-исследователи, и определении, действительно ли результаты有意义.
Это также отражено в статье.
В статье Anthropic写道, в математических задачах один ИИ-исследователь обнаружил, что самый частый ответ обычно верен, и thus обошел слабого учителя,直接 заставив сильную модель выбирать самый частый ответ. В coding-задачах ИИ-исследователь обнаружил, что может直接 запускать тесты кода и then считывать правильный ответ.
Для задачи это жульничество, потому что он не решает проблему слабого надзора, а использует уязвимости среды.
Эти результаты были выявлены и удалены Anthropic, но это как раз показывает, что чем сильнее автоматизированный исследователь, тем больше он ищет лазейки в системе оценок.
В дальнейшем, если позволять ИИ автоматически проводить исследования по согласованию,必须设计 очень строгая среда评估, а также需要 человеческая проверка самого метода, а не только просмотр оценок.
Поэтому основной вывод этой статьи заключается в том, что современные передовые модели уже могут в некоторых четко определенных проблемах исследования согласования с автоматической оценкой, подобно команде маленьких исследователей, самостоятельно выдвигать идеи, проводить эксперименты, анализировать результаты и значительно превосходить человеческий базовый уровень.
Однако это еще не железное доказательство того, что «ИИ-ученый уже пришел», ведь Anthropic на этот раз выбрал задачу, которую можно автоматизировать. Если бы я дал ИИ задачу, которую нельзя автоматизировать, результат был бы очень плохим.
Многие проблемы согласования в реальности более размыты, их нельзя легко оценить, и их нельзя решить простым爬榜 (topping the leaderboard).
02 Почему выбрали Qwen
Прочитав эту статью Anthropic, многие могут задаться вопросом: почему они использовали модель Alibaba Qwen, а не собственный Claude или OpenAI GPT?
За этим выбором на самом деле стоит много соображений.
Сначала нужно прояснить, что в эксперименте использовались две модели Qwen: Qwen1.5-0.5B-Chat в качестве слабого учителя и Qwen3-4B-Base в качестве сильного ученика. Одна имеет всего 0.5 миллиарда параметров, другая — 4 миллиарда, разница в масштабе в 8 раз. Эта разница в масштабе важна, потому что эксперимент模拟的就是 сценарий «слабый учитель учит сильного ученика».
Так почему же не использовать Claude или GPT?
Ответ прост: потому что эти модели не являются открытыми (не предоставляют веса).
Эксперименту Anthropic需要反复训练模型、调整参数、测试不同的监督方法。
Если использовать закрытые модели, они могут обращаться только через API, не имея возможности проникать внутрь модели для тонкой настройки и обучения.
Что более важно, им нужно, чтобы 9 ИИ-исследователей параллельно проводили сотни экспериментов, каждый эксперимент требует обучения новой модели. Если использовать закрытые модели, стоимость будет астрономически высокой, и многие операции просто невозможно будет выполнить.
С открытыми моделями все иначе.
Вы можете скачать полные веса модели и折腾 на своих серверах как угодно. Обучать как хотите, проводить сколько угодно экспериментов. Такую гибкость закрытые модели提供 не могут.
Но открытых моделей так много, почему выбрали именно Qwen?
Официально настоящая причина не указана, следующие причины являются моими предположениями.
Я считаю, что хорошая производительность — это первая причина.
Модели серии Qwen一直表现出色 среди открытых моделей, особенно после выпуска Qwen3, они достигли уровня, близкого к закрытым моделям, в нескольких基准测试ах.
Для этого эксперимента способности сильного ученика важны. Если сам сильный ученик неспособен, то даже хороший слабый надзор не поможет. Qwen3-4B, хотя и имеет 4 миллиарда параметров, уже достаточно capable, чтобы быть квалифицированным «сильным учеником».
Вторая причина — удобство использования моделей.
Документация моделей Qwen полная, сообщество активное, инструментарий для обучения и вывода зрелый. Для эксперимента, требующего反复训练和测试, степень完善ности этой инфраструктуры напрямую влияет на эффективность исследований. Если выбрать открытую модель с неполной документацией и неудобными инструментами, только на отладку среды уйдет масса времени.
Третья причина — адаптивность масштаба.
Этот эксперимент需要 «слабого учителя» и «сильного ученика», причем эти две модели должны иметь明显的 разрыв в способностях, но не слишком большой.
Серия Qwen имеет多个 версий от 0.5B до 72B параметров, что позволяет гибко выбирать. Модель на 0.5B параметров достаточно слаба, но не настолько, чтобы быть совершенно бесполезной; модель на 4B параметров достаточно сильна, но не настолько, чтобы стоимость обучения стала неподъемной. Это сочетание как раз подходит.
Последняя причина — воспроизводимость.
Anthropic в конце статьи четко указал, что они опубликовали код и наборы данных на GitHub. Если бы они использовали закрытые модели, другим исследователям было бы трудно воспроизвести этот эксперимент, потому что они не смогли бы получить相同的 модели.
Но используя открытые модели, такие как Qwen, любой может скачать相同的 веса моделей, запустить相同的 код, проверить相同的 результаты. Это очень важно для науки.
С этой точки зрения, выбор Anthropic в пользу Qwen, с одной стороны, действительно является признанием производительности моделей Alibaba. Если бы возможности Qwen были плохими, или с их обучением было много проблем, они бы не выбрали их. Но, с другой стороны, более важными являются гибкость и воспроизводимость, которые предоставляет Qwen как открытая модель.
А китайские проекты open source AI занимают все более важное место в этой инфраструктуре. Это хорошо для глобальных исследований безопасности ИИ и для китайской экосистемы ИИ. Потому что безопасность ИИ — это не игра с нулевой суммой, не «выиграл-проиграл», а общие усилия, чтобы сделать ИИ более безопасным, управляемым и полезным для человечества.
Эта статья из WeChat Official Account «字母AI», автор: Miao Zheng






