Автор|Нань Чжи (@Assassin_Malvo)

После того как большинство направлений были опровергнуты, рынки предсказаний стали одним из немногих сегментов в криптосообществе, которые продолжают показывать положительный рост. 20 ноября Нань Чжи начал экспериментировать с подходом поиска "умных денег" на рынках предсказаний, используя методологию, применявшуюся в прошлом году для поиска умных денег в мемах, и на начальном этапе достиг хороших результатов.
В начале декабря, как раз в момент запуска Gemini 3 Pro, в процессе тестирования соответствующих моделей возникла идея: можно ли использовать ИИ для анализа и прогнозирования рынков предсказаний, и устроить соревнование между человеком и ИИ, чтобы выяснить, чьи прогнозы точнее.
При описании рынков предсказаний обычно утверждается, что они, позволяя "людям с инсайдерской информацией делать ставки реальными деньгами",推动市场向“真相”靠拢推动市场向“真相”靠拢 (двигают рынок к "истине"). Однако некоторые считают, что Крипто + рынки предсказаний позволяют "инсайдерам" безопасно получать прибыль от информационного разрыва, тем самым направляя рынок к "инсайдерскому результату". По сути, это противостояние двух точек зрения: "мудрость толпы" против "истина в руках немногих". Прогнозирование с помощью ИИ больше склоняется к "мудрости толпы", поэтому требует большого количества доступных знаний и мнений.
Таким образом, при выборе модели ИИ изначально были выбраны Gemini и Grok, поскольку они, опираясь на Google и платформу X, могут наиболее непосредственно получать огромные объемы знаний и информации. Недавно Нань Чжи добавил комбинацию "Douban (Доубао) + знания из Douyin (ТикТок)", но из-за небольшого количества прогнозных вопросов, связанных с этим, в данной статье она не рассматривается.
Основные правила
- Версии ИИ: Gemini 2.5 pro (со встроенным поиском Google), Grok 4 Fast (через OpenRouter, с включенной функцией нативного поиска)
- Выбор вопросов: человек выбирает вопросы для ставок, ИИ следует за прогнозом, но исключается крипто-сектор
- Входные данные: официальный вопрос (title), официальное описание (Description), возможные ответы (фактически только Yes и No)
Примечание: Вопросы на Polymarket делятся на крупные категории Event и подкатегории Market. Крупная категория Event — это вопросы широкого охвата, такие как "Кто будет следующим председателем ФРС?" или "Когда Strategy продаст биткоин?". Под Event есть N подкатегорий рынков, например, "Станет ли Хассет следующим председателем ФРС?" или "Продаст ли Strategy биткоин до 31 марта 2026 года?" — конкретные варианты выбора. Чтобы согласовать с человеческим прогнозом, здесь был выбран Market как вопрос для оценки ИИ, без ввода других вариантов. Например, ИИ просят оценить "Станет ли Хассет следующим председателем ФРС?", а не выбрать наиболее вероятного из N кандидатов.
- Дизайн промптов (подсказок):
- Требовать от ИИ поиска последних новостей, официальных объявлений, аналитических отчетов экспертов
- Требовать исключить, запретить использование данных预测市场 (рынков предсказаний)
- Производить оценку на основе "доказательств", используя логические рассуждения
- Разрешить вывод только Yes или No, с кратким изложением логики рассуждений
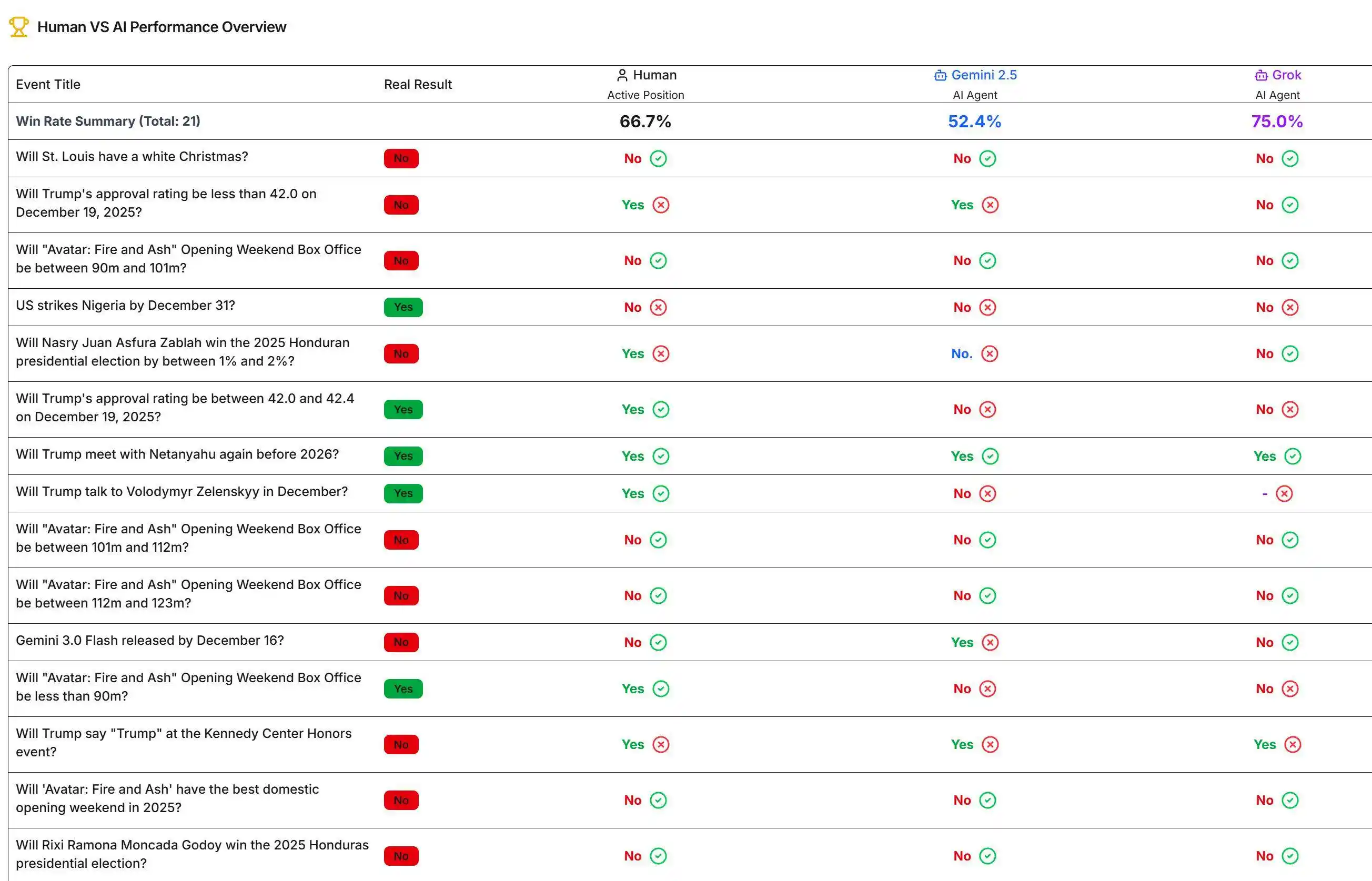
Текущие результаты
Среди прогнозных вопросов расчет проведен по 21. Наивысший процент побед у Grok — 75%, у человека — 66.7%, а у Gemini самый низкий — 52.4%. Текущие результаты можно посмотреть на соответствующем сайте.
Какие ошибки допустил ИИ?
Gemini иногда ошибается в определении текущего времени
В вопросе "Will Trump's approval rating hit 35% in 2025?" (Достигнет ли рейтинг одобрения Трампа 35% в 2025 году?) Gemini заявил, что сейчас первая половина 2025 года, поэтому всё возможно, и бездумно дал ответ.
Но когда автор с помощью программы прямо попросил Gemini вывести текущее время, Gemini смог дать правильный ответ. Пока неясно, почему возникает такая ошибочная оценка времени.
Недостаточная глубина мышления ИИ
В вопросе "Gemini 3.0 Flash released by December 16?" (Будет ли Gemini 3.0 Flash выпущен до 16 декабря?) Grok, основываясь на том, что "официальные источники最近只提及 (недавно упоминали) только Gemini 3 Pro и связанные версии 2.5,极少提及 (очень редко упоминали) 3 Flash, поэтому доказательств недостаточно для判断 (оценки)", учел только текущую информацию.
В то время как Gemini указал: "Gemini 1.0 был выпущен в декабре 2023 года, а экспериментальная версия Gemini 2.0 Flash — в декабре 2024 года. Продолжая эту модель, логично ожидать выпуск версии 3.0 в конце 2025 года", а также обнаружил "недавнюю (14 декабря 2025 года) утечку демонстрации 'Gemini 3.0 Flash', распространявшуюся в интернет-сообществах, что further enhanced (дополнительно усилило) вероятность его скорого публичного релиза".
Хотя с точки зрения结论 (заключения) ответ Gemini оказался ошибочным, в этом вопросе явно видна значительная разница в широте источников, на которые опираются две модели.
ИИ делает выводы на основе常识 (здравого смысла), а не доказательств + логики
В вопросе "Trump approval Up or Down this week?" (Рейтинг Трампа на этой неделе вырастет или упадет?) Gemini заявил: "预测 (Прогнозировать) рейтинг одобрения на одну конкретную неделю более чем через год highly uncertain (весьма неопределенно)", — здесь снова проявилась "ошибка времени". Затем Gemini сказал: "В любую обычную неделю вероятность событий, вызывающих轻微下降 (незначительное падение) рейтинга, может быть slightly higher (немного выше), чем вероятность позитивных событий, significantly提升 (значительно повышающих) рейтинг", поэтому вероятность падения поддержки больше. Сгенерированный вывод основан лишь на субъективных常识假设 (предположениях здравого смысла)).
В этом же вопросе Grok, основываясь на новостных reports (отчетах) и данных опросов о "приостановке работы правительства, экономических担忧 (опасениях), спорах вокруг иммиграционной политики и негативной реакции на комментарии по поводу смерти Роба Райнера", соответствовал ожиданиям дизайна.
Ошибка в判断 (оценке) условий расчета
В вопросе "Will Trump release the Epstein files by December 20?" (Опубликует ли Трамп файлы Эпштейна до 20 декабря?) и Gemini, и Grok уже знали, что "правительство опубликует 'сотни тысяч страниц' документов в пятницу (19 декабря)", а в условиях расчета четко указано: "Правительство публично выпускает любые документы, связанные с незаконной деятельностью Эпштейна, которые не были公开 (опубликованы) до указанной даты, считается как Yes".
Однако при этом условии Gemini заявил: "Завершить публикацию 'всех' документов до 20 декабря невозможно", явно misjudged (неверно оценил) условия, необходимые для расчета, и дал错误的答案 (неправильный ответ).
Краткий итог
В заключение, процент побед Grok в прогнозах уже превзошел показатели этих "умных денег", заработавших на рынках предсказаний сотни тысяч и миллионы долларов. Однако при глубоком изучении его прогнозной логики仍然有大量可以引导、改正的地方 (все еще есть много аспектов, которые можно направлять и исправлять).








