За год "съесть" SSD на 1 ТБ?
Флагманский инструмент программирования OpenAI Codex "прожигает" ваш твердотельный накопитель, записывая на него 640 ТБ данных в год.

Недавно разработчик создал issue на GitHub. Этот issue, помеченный как "Closed" с номером #28224, озаглавлен:
Журнал обратной связи SQLite в Codex записывает 640 ТБ в год, быстро исчерпывая ресурс SSD.
По измерениям автора, его основной SSD за 21 день непрерывной работы был перезаписан на 37 ТБ, что в пересчёте на год даёт около 640 ТБ — достаточно, чтобы "убить" потребительский накопитель с общим ресурсом записи (TBW) в 600 ТБ.
В подтверждение он привёл две таблицы.
В доказательстве 1 видно, что сама база логов всегда занимает около 1.2 ГБ, как будто ничего и не происходит; однако её автоинкрементный ID строки уже достиг 5.5 миллиардов, в то время как фактически сохранённых строк всего чуть более 500 тысяч — разница в десять тысяч раз.
Ключевой момент: износ диска зависит от общего объёма записанных данных, а не от того, сколько осталось сейчас. Все эти 5.5 миллиардов строк были записаны на диск, и их удаление не вернёт уже затраченный ресурс записи. Поэтому вы всегда видите только те 500 тысяч строк, но ваш диск уже выдержал запись 5.5 миллиардов строк.
Доказательство 2 раскрывает распределение этих 5.5 миллиардов строк: более 90% — это отладочный "шум", который даже сами разработчики не будут просматривать. Один только пункт "копирование каждого пакета данных WebSocket целиком" занимает половину.
Виновник — конфигурация по умолчанию Level::TRACE, которая использует ресурс записи вашего диска как бесплатную черновичную бумагу.
Высоко оценённый комментарий на Hacker News дал этой ситуации точное определение:
Это один из самых печально известных примеров "низкокачественного ПО" (slopware).

Этот пользователь также сокрушённо добавил:
Это настоящая трагедия. Этому миру нужна конкуренция для Anthropic.
Что ещё более неловко, эту проблему уже сообщали ранее.
Начиная с апреля этого года поступали единичные отзывы, и прошло более двух месяцев, прежде чем пользователи сами измерили, написали отчёт и вынесли это на первую страницу Hacker News, и только тогда к проблеме отнеслись серьёзно. Даже в этом случае, в текущем раунде исправлений удалось сократить лишь около 85% записи логов.
Некоторые хотели исправить это самостоятельно, но обнаружили, что это невозможно: настольные версии этих инструментов являются проприетарными.
В комментариях также появилась гениальная реплика: как процесс ревью пропустил такую очевидную ошибку? Ах да... @codex, просмотри это.
Как получаются эти 640 ТБ
Что такое 640 ТБ?
Ресурс записи (TBW) обычных потребительских SSD составляет примерно от 150 до 600 ТБ, чего обычному пользователю хватит на 10-20 лет.
А функция журналирования Codex, которая "записывает, что он делает", может исчерпать этот ресурс за один год.
Всё началось с того, что пользователь проверил состояние своего диска. Его машина работала непрерывно 21 день, и основной SSD был перезаписан на 37 ТБ.
При такой скорости за год набегает около 640 ТБ.
Но ещё более абсурден способ записи.
Codex локально поддерживает базу данных SQLite logs_2.sqlite, специально предназначенную для журналирования обратной связи. За 15 секунд наблюдений пользователь зафиксировал: в базу было вставлено 36211 строк, а общее количество сохранённых строк с начала до конца оставалось 681774, ни одной лишней.
Каждая вставленная строка сопровождалась удалением другой. Количество строк оставалось постоянным, но диск перезаписывался десятки тысяч раз.
У этого механизма есть прозвище — insert-and-prune: вставить, а затем сразу удалить.
И ещё более нелепо то, что записывается: куча событий inotify от файловой системы.
ld.so.cache был записан 128764 раз, locale.alias — 37982 раза, passwd — 23843 раза.
Один и тот же файл, одной и той же программой, записывался десятки тысяч раз.
Автоинкрементный ID в логах превысил 5.5 миллиардов, тогда как реально сохранённых строк всего около 500 тысяч.
Разница в десять тысяч раз.
Это не баг, это похоже на то, как инструмент ИИ-программирования безостановочно бормочет своё заклинание, обращаясь к собственному жёсткому диску.
Файл всего 1 ГБ, а запись — 640 ТБ
При постоянной записи и удалении, насколько большим остаётся файл logs_2.sqlite? Примерно 1 ГБ.
Это подводит нас к самому парадоксальному аспекту всей истории: ресурс SSD измеряется "объёмом записи", а не "размером файла". Если файл размером 1 ГБ перезаписывается 640 раз, для диска это равносильно записи 640 ТБ.
SQLite использует механизм WAL (Write-Ahead Logging): каждое изменение сначала записывается в -wal файл, накапливается, а затем checkpoint'ом переносится в основную базу. Codex каждые 15 секунд выполняет десятки тысяч операций вставки и удаления, каждая из которых проходит через WAL, обновление индексов, checkpoint. Одна и та же область хранения стирается и перезаписывается снова и снова.
Приведём аналогию: блокнот на 1 ГБ, в котором вы каждый день стираете и заново пишете 1750 раз, и так целый год. Блокнот остаётся тем же, но бумага уже протёрта насквозь.
Именно поэтому этот баг мог оставаться незамеченным так долго: он не занимает места, он лишь сжигает ресурс.
Проверка свободного места на диске не показывает аномалий, размер файла остаётся неизменным. Только считывание счётчика здоровья SMART самого диска может показать, как тихо накапливается объём записи.
Коренная причина: одна строка RUST_LOG, оставленная без внимания
Почему записывается так много логов?
Ответ кроется в одной строке конфигурации исходного кода Codex: sink для журнала обратной связи SQLite инициализируется с помощью Targets::new().with_default(Level::TRACE).
Одной фразой: уровень журналирования по умолчанию установлен на TRACE — самый высокий, самый подробный уровень, записывающий всё подряд.
Фреймворк журналирования Codex — это tracing из экосистемы Rust, стандартная практика — чтение переменной окружения RUST_LOG. Пользователи, конечно, пробовали изменить RUST_LOG на info, warn или даже полностью отключить.
Безрезультатно.
with_default(Level::TRACE) жёстко фиксирует глобальный уровень по умолчанию на TRACE, RUST_LOG на этом пути просто не действует. Вы думаете, что отключили логи, а они продолжают записываться.
Такой баг особенно коварен: это не "вы забыли настроить", а "вы настроили, но система делает вид, что не слышит".
Ещё более показательным является соотношение.
Если разбить сохранённые логи по категориям, TRACE занимает 70.7%, около 732.5 МБ. Плюс два потока зеркальных телеметрических логов codex_otel (log_only и trace_safe) занимают ещё 25.3%.
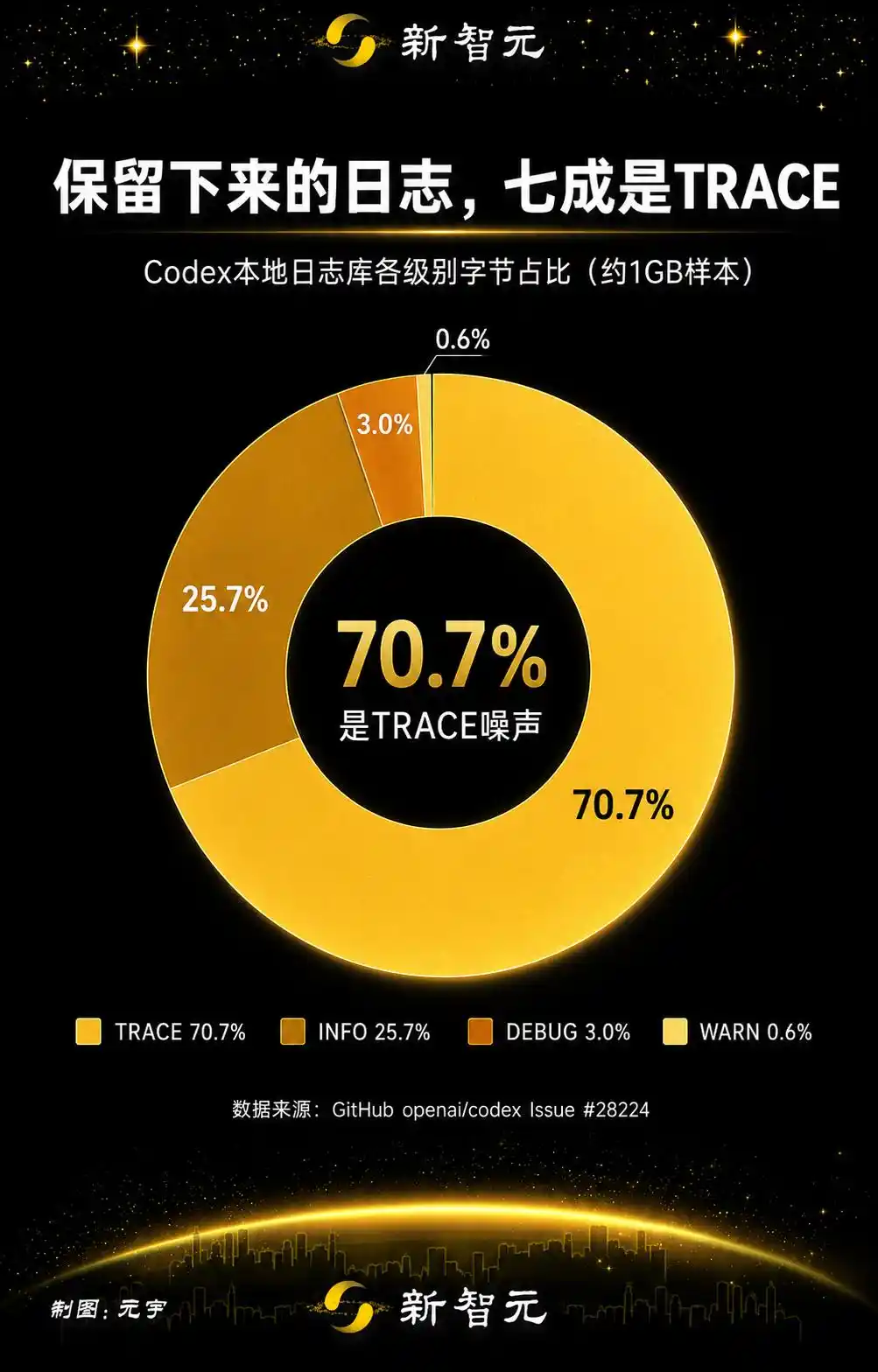
70% записи — это "шум" уровня TRACE, плюс зеркальная телеметрия — 96% всего это бесполезная информация, которую никто не будет читать.
Лишь 4% — это действительно значимый контент.
Это не первый случай, как минимум девятый
Автор отчёта изучил репозиторий Codex и обнаружил, что подобных Issues о "неограниченном росте логов" было как минимум 9.
#17320: бешеная запись в WAL во время потоковых ответов, коренная причина точно такая же — TRACE игнорирует RUST_LOG.
#24275: бесконтрольный рост logs_2.sqlite в десктопной версии.
#22444: бесконечный рост WAL без освобождения места.
#26374: запись 0.75 ГБ в день, без ротации.
#27911: база данных goals_1.sqlite размером 4 КБ записывалась со скоростью 11 МБ/с.
#20563: процесс бездействует, но активно пишет на диск.
#27020: 100% активность диска в Windows.
Самый ранний источник можно отследить до PR #12969, именно он подключил sink для журнала обратной связи SQLite на уровне TRACE.
Тот факт, что база данных размером 4 КБ записывалась со скоростью 11 МБ в секунду, сам по себе достоин отдельной статьи. И это симптом одной и той же проблемы, той же самой телеметрической системы в одном продукте.
Это говорит о том, что в системе журналирования и телеметрии Codex изначально отсутствовало понятие "бюджета ресурсов".
Вся отрасль соревнуется в бюджете токенов, длине контекста, возможностях моделей.
Но почти никто не задаётся вопросом: кто отвечает за бюджет диска, памяти, CPU для агента, который постоянно работает на машине пользователя 24/7?
Исправлено, но исправлено в стиле OpenAI
14 июня проблема была зарегистрирована на GitHub, 23 июня автор отчёта обновил информацию: три PR были объединены, и, по его собственным измерениям обратной связи Codex, запись логов сократилась примерно на 85%, после чего он объявил issue закрытым.
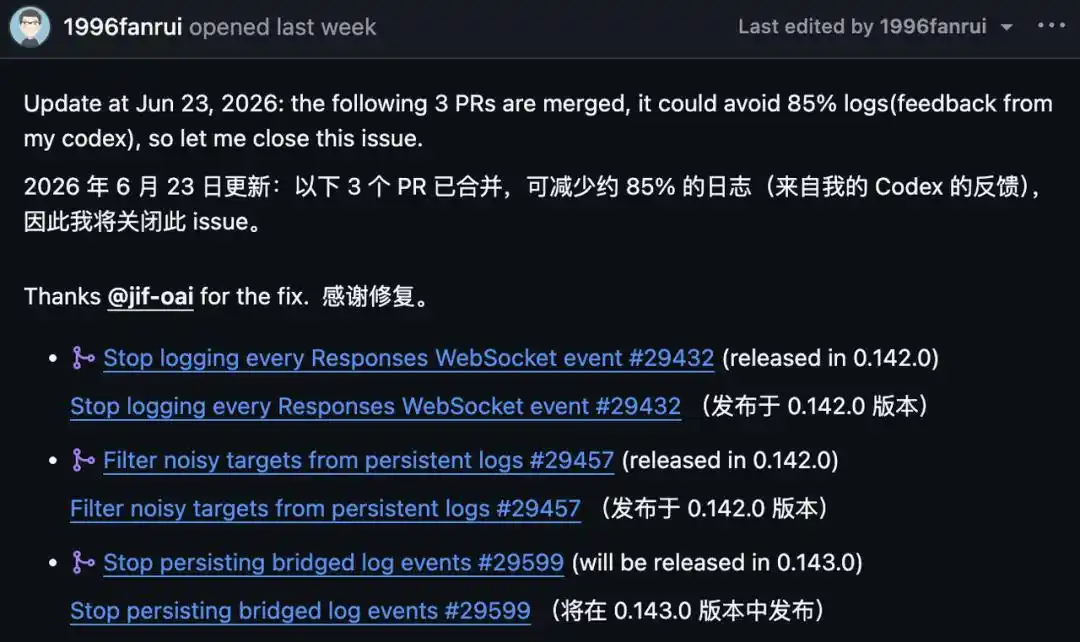
Сначала об этих 85% — это не 100%, и исправления ещё не полностью внедрены.
Из трёх исправлений, #29432 и #29457 уже выпущены с версией 0.142.0, они убрали построчную запись логов WebSocket и шумовые цели; третье исправление #29599, которое отключает другой тип избыточных логов, подключённых через мост, появится только в версии 0.143.0.
Даже если все три будут применены, оставшиеся примерно 15% будут по-прежнему составлять около 96 ТБ записи в год — ситуация меняется с "исчерпать ресурс диска за год" на "исчерпать ресурс диска за шесть лет".
Некоторые защищают Codex: логи уровня trace по дизайну сохраняются для отладки, это не баг, и для OpenAI это действительно удобно для отслеживания крайних случаев.
Но проблема как раз в этом: использование ресурса записи SSD платных пользователей в качестве бесплатного хранилища для отладки производителя — соглашались ли на это пользователи?
На поле программирования прожигается не только SSD
Любопытно, что под прицелом оказался не только Codex.
В комментариях сразу же добавили: Claude Code тоже активно пишет отладочные логи на локальный диск, некоторым пришлось привязывать каталог логов к RAM-диску (tmpfs), чтобы продлить жизнь SSD.
Два флагмана совершили одну и ту же ошибку.
Обсуждения в сообществе быстро переросли от одного бага к вопросу о качестве целого поколения инструментов ИИ-программирования.
Кто-то жаловался, что эти агенты постоянно загружают GPU на 100%, потребляя до 70 ГБ оперативной памяти, кто-то干脆 назвал это поколение программного обеспечения: "низкокачественное ПО".
Предложение того разработчика было предельно простым: установить для приложения лимит, не превышающий 3 ГБ. Просто эту одну черту Codex рисовал через 9 Issues на протяжении нескольких месяцев.
Вопрос в том, почему компания, которая постоянно говорит об "Искусственном Общем Интеллекте" (AGI), споткнулась о проблеме, которую мог бы заметить даже стажёр-инженер?
Почему этот дефект мог так долго оставаться незамеченным? Один комментарий попал в точку.
Десять лет назад, если бы логи были установлены на уровень TRACE, программа бы тут же зависла, и баг был бы исправлен в тот же день. Сегодня CPU достаточно быстрые, памяти много, диски мощные, и подобные недостатки тихо компенсируются производительностью железа. Программа работает, интерфейс в порядке, пользователь ничего не замечает, пока однажды SSD не выйдет из строя раньше времени.
За последние годы программное обеспечение заполнилось кодом, сгенерированным ИИ, функциональность множится, слои абстракции нарастают, потребление ресурсов стремительно растёт, и всё это держится только на том, что производители железа каждый год выпускают более быстрые чипы.
Так возникает абсурдный цикл: программное обеспечение пишется всё хуже, а железо становится всё мощнее. Пользователи, находясь под впечатлением, что "вроде не тормозит", платят за новую технику, хотя на самом деле новая техника лишь с трудом выдерживает более плохое программное обеспечение.
Один маленький баг, конечно, не может обрушить OpenAI. Но конкуренция между Codex и Claude Code уже распространилась с возможностей моделей на точку входа в рабочий процесс разработчика.
На этой линии фронта быстрое реагирование и удовлетворение потребностей разработчиков уже не является преимуществом, а лишь минимальным требованием для участия в игре.
Источники:
https://github.com/openai/codex/issues/28224
https://news.ycombinator.com/item?id=48626930
Эта статья из официального аккаунта WeChat "Новая Эра ИИ", автор: ASI Апокалипсис






