Over the past year, the research focus of world models has initially centered on representation learning and future prediction. Models first understand the world and then internally simulate future states. This approach has already produced a number of representative results. V-JEPA 2 (Video Joint Embedding Predictive Architecture 2—a video world model suite released by Meta in 2025) used over 1 million hours of internet video for pre-training, combined with a small amount of robot interaction data, demonstrating the potential of world models in understanding, prediction, and zero-shot robot planning.
However, a model's ability to predict does not equate to its ability to handle long-horizon tasks. When faced with multi-stage control, systems typically encounter two challenges. One is that prediction errors accumulate over long rollouts (multi-step simulations), causing the entire path to increasingly deviate from the goal. The other is that the action search space expands rapidly as the planning horizon increases, leading to continuously rising planning costs. HWM does not rewrite the underlying learning approach of world models but instead adds a hierarchical planning structure on top of existing action-conditioned world models, enabling the system to first organize stage paths and then handle local actions.
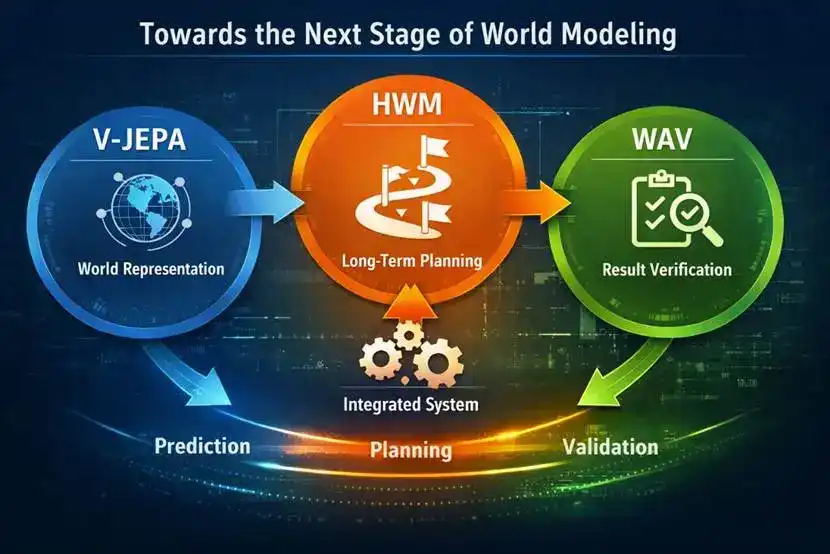
From a technical perspective, V-JEPA 2 (https://ai.meta.com/research/vjepa/) leans more toward world representation and basic prediction, HWM leans more toward long-horizon planning, and WAV (World Action Verifier: Self-Improving World Models via Forward-Inverse Asymmetry, https://arxiv.org/abs/2604.01985) leans more toward the model's ability to identify and correct its own prediction distortions. These three lines of research are gradually converging. The focus of world model research has shifted from merely predicting the future to transforming predictive capabilities into executable, correctable, and verifiable system capabilities.
I. Why Long-Horizon Control Remains a Bottleneck for World Models
The difficulties of long-horizon control become clearer when applied to robotic tasks. Take robotic arm manipulation as an example: picking up a cup and placing it in a drawer is not a single action but a sequence of continuous steps. The system must approach the object, adjust its posture, complete the grasp, move to the target location, and then handle the drawer and placement. As the chain lengthens, two problems arise simultaneously. One is that prediction errors accumulate along the rollout, and the other is that the action search space expands rapidly.
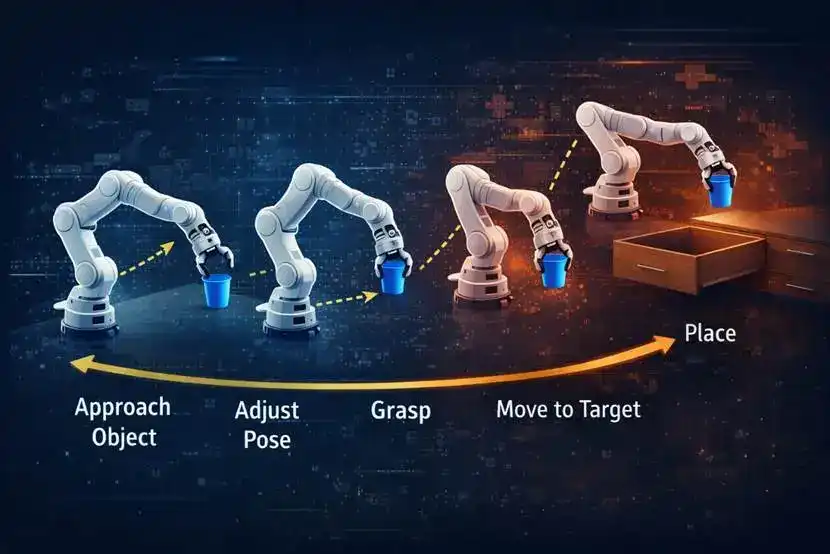
What the system often lacks is not local predictive ability but the capacity to organize distant goals into stage paths. Many actions may appear to deviate from the goal locally but are actually intermediate steps required to achieve it. For example, raising the arm before grasping or moving back slightly and adjusting the angle before opening a drawer.
In demonstration tasks, world models can already provide coherent predictions. However, when entering real control scenarios, performance begins to decline, and problems emerge. The pressure comes not only from the representation itself but also from the immaturity of the planning layer.
II. How HWM Restructures the Planning Process
HWM splits the originally single-layer planning process into two layers. The upper layer is responsible for stage direction at a longer time scale, while the lower layer handles local execution at a shorter time scale. The model plans at two different temporal rhythms simultaneously, rather than at a single pace.
When handling long tasks, single-layer methods typically need to search the entire action chain directly in the underlying action space. The longer the task, the higher the search cost, and the more likely prediction errors are to diffuse along multi-step rollouts. After HWM's decomposition, the high layer only handles route selection at a longer time scale, and the low layer only handles the execution of the current segment. The entire long task is broken into multiple shorter segments, reducing planning complexity.
Another key design is that high-level actions are not simply the difference between two states but use an encoder to compress a sequence of low-level actions into a higher-level action representation. For long tasks, the key is not just the difference between the start and end points but also how the intermediate steps are organized. If the high layer only looks at displacement differences, it may lose path information in the action chain.
HWM embodies a hierarchical task organization approach. Faced with a multi-stage task, the system no longer unfolds all actions at once but first forms a coarse stage path and then executes and corrects it segment by segment. Once this hierarchical relationship is incorporated into the world model, predictive capabilities begin to transform more stably into planning capabilities.
III. From 0% to 70%: What the Experimental Results Indicate
In the real-world grasp-and-place task set up in the paper, the system was given only the final goal condition without manually decomposed intermediate goals. Under these conditions, HWM achieved a success rate of 70%, while the single-layer world model had a 0% success rate. A long task that was nearly impossible to complete originally became highly achievable after introducing hierarchical planning.

The paper also tested simulation tasks such as object pushing and maze navigation. The results showed that hierarchical planning not only improved success rates but also reduced the computational cost of the planning phase. In some environments, the computational cost of the planning phase could be reduced to about a quarter of the original while maintaining higher or comparable success rates.
IV. From V-JEPA to HWM to WAV
V-JEPA 2 represents the world representation approach. V-JEPA 2 used over 1 million hours of internet video for pre-training, combined with less than 62 hours of robot video for post-training (targeted training after pre-training), resulting in a latent action-conditioned world model (a world model that predicts in an abstract representation space incorporating action information) usable for understanding, predicting, and planning in the physical world. It demonstrates that models can acquire world representations through large-scale observation and transfer these representations to robot planning.
HWM is the next step. The model already possesses world representation and basic predictive capabilities, but once multi-stage control is involved, the problems of error accumulation and search space expansion erupt. HWM does not change the underlying representation learning approach but adds a multi-timescale planning structure on top of existing action-conditioned world models. It addresses how the model organizes distant goals into a set of intermediate steps and then advances segment by segment.
WAV further focuses on verification capabilities. For world models to enter policy optimization and deployment scenarios, they cannot just predict; they must also identify areas where they are prone to distortion and make corrections accordingly. It focuses on how the model checks itself.
V-JEPA leans toward world representation, HWM toward task planning, and WAV toward result verification. Although their focuses differ, their overall direction is consistent. The next phase of world models is no longer just internal prediction but the gradual integration of prediction, planning, and verification into a system capability.
V. From Internal Prediction to Executable Systems
Many past world model efforts were closer to improving the continuity of future state predictions or the stability of internal world representations. However, the current research focus is beginning to change. Systems must not only form judgments about the environment but also translate those judgments into actions and continue to adjust the next steps after results are obtained. To get closer to real deployment, it is necessary to control error propagation in long-horizon tasks, compress the search space, and reduce inference costs.
Such changes will also affect AI agents. Many agent systems can already handle short-chain tasks, such as calling tools, reading files, and executing multi-step commands. However, once tasks become long-chain, multi-stage, and require mid-course re-planning, performance declines. This is not fundamentally different from the difficulties in robotic control; both stem from insufficient high-level path organization capabilities, leading to a disconnect between local execution and overall goals.
The hierarchical approach provided by HWM—where the high level is responsible for paths and stage goals, the low level handles local actions and feedback processing, and result verification is layered on top—will continue to appear in more systems in the future. The next phase of world models will focus not only on predicting the future but on organizing prediction, execution, and correction into a viable path.





