Imagine this scene:
An elderly person living alone slips and falls in the living room, and the pain prevents them from calling for help. At this moment, the smart device on their person or a home camera "sees" the abnormality. Without waiting for any voice command, the AI actively sends an alert and quickly contacts family or emergency services.
Or, you are watching an intense soccer match. At the moment a crucial goal is scored, before you can even think to rewind and ask a question, AI glasses automatically provide you with slow-motion analysis and tactical insights.
These scenarios are no longer fantasies of the future, but real-world propositions that JoyAI-VL-Interaction, the world's first full-stack open-source visual-language interaction model just launched by JD.com, is attempting to solve.

Over the past two years, the capability boundaries of large language models have been continuously expanded, but the mainstream mode of interaction remains stuck in the "turn-based" logic of "user questions, model answers." It is efficient, but not reasonable in many scenarios. Many important events happen too fast for users to ask a question; and in many scenes, there is no opportunity for voice command at all.
This year, a judgment is becoming an industry consensus: AI is moving from "predicting the next token" to "predicting the next physical state." This also means that AI must evolve from being a passive information processor to an active participant.
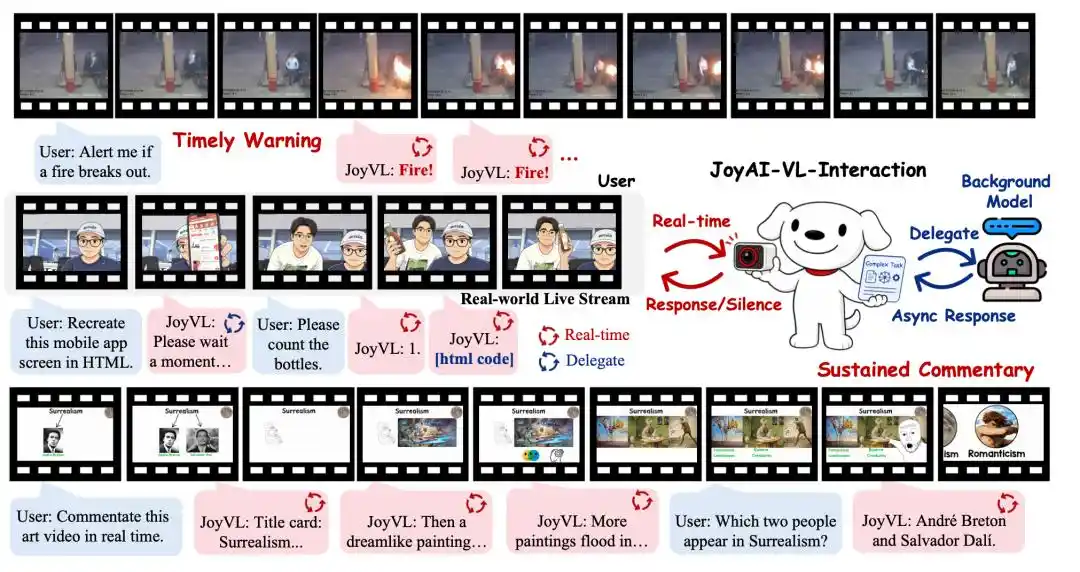
Right at this juncture, JD.com open-sourced JoyAI-VL-Interaction. This is the world's first full-stack open-source real-time visual-language interaction model, capable of autonomously judging when to respond, when to stay silent, and when to hand off complex tasks to backend models within continuous video streams.
What JoyAI-VL-Interaction aims to prove is: AI that truly enters the physical world should not always wait to be asked. It should learn to see, actively judge, and provide help at the right moment.
This is also the larger signal released by JD AI: from model capability to industrial application, AI competition is moving from on-screen Q&A to the real world.
Why Visual-Language Interaction?
In the real physical world, a vast amount of critical information occurs at moments when users don't have time to ask a question. This sense of "no time to react" is partly an experience issue, but more often, it's a capability boundary problem caused by the model paradigm.
The industry is not unaware of this limitation.
In the first half of 2026, real-time interaction became the hottest keyword in multimodal AI. The industry has broadly advanced along two paths: one is making turn-based dialogue faster, and the other is making voice calls more natural.
The former emphasizes low latency or arbitrary input/output, but its core remains "it answers only when you ask"; the latter allows the model to listen and speak simultaneously, be interrupted at any time, making the experience closer to a real human call, but the focus is still on voice scenarios.
The problem is that a large number of changes in the real world do not manifest as a sentence first. Fire, falls, approaching vehicles, changes in screen content, production line anomalies—these are all visuals that appear before language. If AI can only wait for someone to speak, it's hard to truly be "present."
The one who truly made the same judgment as JD.com at almost the same time is Thinking Machines Lab, founded by Mira Murati. On May 11, the company introduced the concept of "interaction models" and released some research preview demos, pointing out that the autonomous response paradigm of interaction models holds greater potential for Human-AI collaboration compared to the traditional Q&A paradigm.
The fact that two teams converged on the same line of thinking at nearly the same time is itself a signal: scaling interactivity as an inherent capability of the model is a direction the industry cannot avoid in the coming years.
The difference is that JD.com placed visual-language at a more central position, treating speech as a pluggable I/O, and making visual-language the "first-class driving modality" for the model's autonomous decision-making.
In other words, from the moment the camera turns on, JoyAI-VL-Interaction continuously "watches" the visual changes in the physical world and autonomously decides whether to speak up, what to say, and whether to hand off tasks.
This is also where the imagination for visual interaction lies: it can be used in scenarios like elderly and childcare, assistance for the blind, AI glasses, event commentary, store inspections, warehouse logistics, and robot collaboration. Users don't need to first formulate a problem into a sentence; AI can capture the need from environmental changes.
Therefore, vision is not just another input method; it is an indispensable perceptual channel for AI to move toward "predicting the next physical state."
JD.com's technical report on JoyAI-VL-Interaction also reinforces this point. The report shows that in six real-world streaming scenarios, JoyAI-VL-Interaction achieved a win rate of 77.6% against leading domestic models and 87.9% against foreign models. In the surveillance and warning scenario, which most tests event capture ability, the win rate reached 100%. The report suggests the gap is not merely in answer quality, but in the ability to act at the right moment.
However, achieving proactive visual interaction is indeed more difficult.
Data acquisition for voice interaction is relatively straightforward. A large amount of voice command datasets allows models to learn when humans speak, how to interrupt, and how to respond. The data needed for visual interaction is completely different. The model must learn, from a continuous stream of changing visuals, what signals merit a response and what signals should be met with silence.
A deeper barrier is the ability to define scenarios. In scenarios, voice interaction has a natural trigger boundary—the user opening their mouth to speak marks the start of interaction. Visual interaction has no clear start or end; the model must judge the boundaries within an unbounded stream of information.
This is also where JD.com's uniqueness lies: the company does not search for scenarios from an abstract laboratory; it naturally operates within real business networks spanning retail, logistics, health, industry, and more.
This means JD AI is not facing a single chat interface but a massive number of real-world tasks: how goods move, how equipment coordinates, how robots cooperate with humans, how anomalies are detected in advance. Models can learn from real needs and iterate based on real feedback.
Despite trade-offs in technical routes, the interactive form of future general AGI will inevitably be proactive intelligence. Intelligent agents must possess a complete loop of environmental perception, autonomous decision-making, and real-time response. Therefore, many companies are not unwilling to build visual interaction models; it's just that the soil to nurture visual interaction is currently lacking for them. This is also why capital and computing power first surged into the voice interaction track.
Thus, JD.com's choice to start from vision is not merely a technical route selection; it is also dictated by its strategic position. Compared to many LLM players, JD.com is closer to the operational front lines of the physical world and also has a greater need for AI that can actively perceive and respond in real-time.
To make this day come sooner, someone needs to set out earlier.
Lightweight, Open-Source, Deployable
What does being the world's first full-stack open-source model mean?
Redefining the interaction paradigm sounds grand, but when it comes to real-world applications, the first hurdle is quite simple: AI cannot always disturb people, nor can it remain silent when a reminder is needed.
People typically expect AI to be as talkative as possible, but in real-time visual interaction scenarios, a model that constantly interrupts is not smart. The truly valuable capability is actively appearing at critical moments and staying quiet during irrelevant times.
Therefore, JoyAI-VL-Interaction trains "silence" as an ability as well. The model needs to master three layers of judgment: in what scenarios it should proactively respond, in what scenarios it should remain silent, and in what scenarios it should delegate tasks out to other models.
This set of capabilities is of limited value if it stays only in research papers. JD.com's emphasis on "full-stack open-source" is key because it opens up the model, inference system, and application building path together, allowing developers to truly run, modify, and use it.
JD.com has chosen an engineering route that facilitates broader diffusion: an 8B parameter model, deployable on a single RTX 3090 graphics card. At this parameter scale, individual developers can run it, consumer-grade hardware can support it, and edge devices can implement it.
For real-time visual interaction, this lightweight approach does not mean reduced capability, but rather clearer division of labor.
JoyAI-VL-Interaction acts more like a front-end interaction layer, responsible for seeing the environment, judging timing, and completing brief communication. When encountering complex tasks requiring deep reasoning, it automatically delegates them to backend agents selected by the user, such as OpenClaw, Codex, or Claude Code. Therefore, an 8B model is sufficient.
For example, the model can first tell the user, "Let me think about that," then hand the difficult problem to the backend while itself remaining present; after the backend returns a result, it can synchronize the answer to the user. During this process, it can also continue helping the user with other immediate interactions.
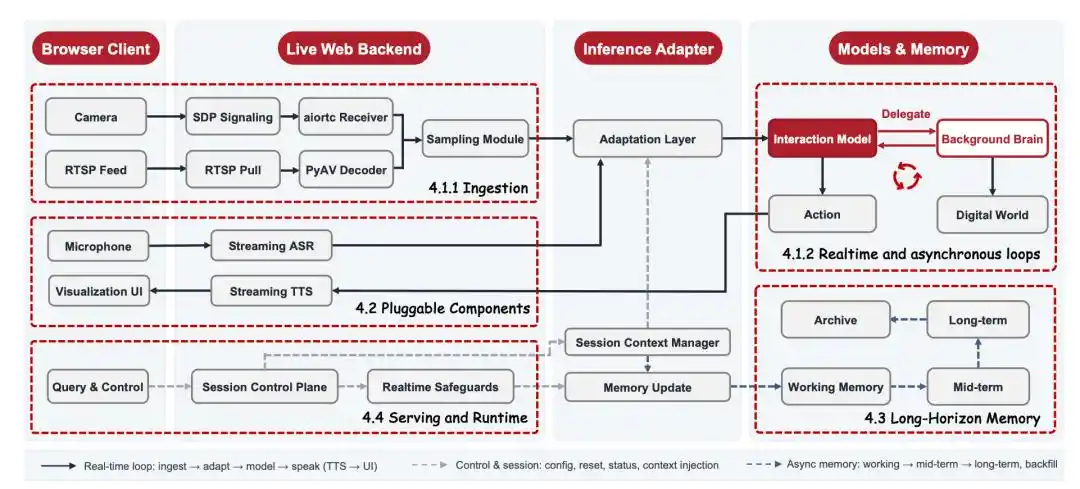
JD.com has also adopted a lightweight design in the underlying system: through video encoding, long-range memory, and context compression, the model can continuously watch long video streams at a lower cost and control end-to-end latency to sub-second levels. For the average reader, the focus is not on these technical terms, but the result: AI can stay in real-world scenarios for longer and with a lower barrier to entry.
A cost-effective, deployable choice also directly leads to JD.com's open-source strategy. Only when the model is sufficiently lightweight, the system sufficiently complete, and the deployment barrier sufficiently low can real-time visual interaction potentially evolve from experiments by a few teams to an application ecosystem explored by more developers and enterprises together.
JD.com has already open-sourced this inference system, with a clear goal: to enable anyone with an RTX 3090 or higher graphics card and a camera to quickly set up their own real-time visual interaction application.
JoyAI-VL-Interaction has received day-0 support from vLLM-Omni and has been natively merged into the vLLM-Omni mainline.
Bringing AI Back to the Physical World
The purpose of open-sourcing is to hand over the imaginative application possibilities to a larger market. Because the value of technological breakthroughs ultimately must be tested by the real world.
The first batch of application ideas for JoyAI-VL-Interaction is already quite intuitive: during live sports broadcasts, AI can automatically provide commentary at the moment of a key goal or last-minute play; in stock monitoring, it can continuously watch screen changes and alert to anomalies; in home care, it can actively warn when an elderly person falls or a child approaches a dangerous area; paired with AI glasses, it can help users recognize roads, products, screens, and surroundings; when assisting the blind, it can convert visual information into real-time assistance.
For JD.com, an even greater expectation is its application in robotics: a model that understands when to speak, when to be silent, and when to ask a backend system for help can make robots more efficient and closer to the "tactful" intelligent assistants people expect.
The fundamental reason JD.com dares to "stir" this field at this point is that it holds physical world data assets that other LLM players lack.
Placed within the industry coordinates of 2026, the weight of physical world data assets is particularly significant.
2026 has been dubbed the "Year One of Embodied Intelligence Data" by the industry. Within this grand backdrop, a sharp contradiction exists: high-quality physical interaction data is extremely scarce, far from meeting the needs of large-scale training. The bottleneck for algorithmic iteration is shifting comprehensively from the model side to the data side.
At this point in time, JD.com announced its plan to accumulate 10 million hours of high-quality real-world scene video data within two years, mobilizing 600,000 people to participate in collection.
JD.com has over 3,000 real business scenarios covering retail, logistics, health, industry, and more. This year, it also innovated a community grid collection model in Suqian, deploying its self-developed JoyEgoCam head-mounted terminals in batches and mobilizing surrounding small and medium-sized enterprises and residents to collect data in real work scenarios.
The deployment speed is rapid. In March, JD.com announced the completion of the world's first embodied intelligence data collection center in Suqian. In April, it released the industry's first embodied data infrastructure covering the entire chain of collection, storage, labeling, training, evaluation, simulation, and testing. In May, JoyEgoCam achieved mass production, enabling continuous first-person perspective data collection.
This data is the most scarce fuel for training embodied models and visual interaction models. As embodied data joins the training, the value of JoyAI-VL-Interaction will further evolve from "a model that can actively see" to more concrete physical spaces like robots, unmanned vehicles, warehouses, stores, and homes.
Between models and applications, JoyAI-Echo, also open-sourced by JD.com on June 3rd, plays a key role. Echo excels at real-time generation from long videos, while Interaction excels at real-time understanding and interaction. Releasing two models within a month signifies that JD.com has connected both the input and output ends of video multimodality and placed the advancement of AI into the physical world in a longer-term position.
At the 618 kickoff press conference this year, JD.com stated its ambition to become "the world's largest physical world operation center."
In the era of human-computer interaction, the industry is increasingly focusing on how AI understands the physical world. JD.com's problem-solving logic differs from that of most LLM players: this company already operates within the physical world.
Warehousing, delivery, retail, health, and industry—all are training grounds and proving grounds for AI and embodied intelligence. Within JD Logistics alone, there are plans to deploy 3 million robots, 1 million unmanned vehicles, and 100,000 drones over the next five years. These hardware will also become platforms for JoyAI-VL-Interaction to demonstrate its utility.
Whether voice or vision, interaction models are essentially about connecting the physical and digital worlds, understanding the physical world, and orchestrating the digital world.
Open-sourcing is the first window JD.com opens outward. In this track where demand drives technology, by releasing the model, training data, and complete system together, JD.com is betting on a longer-term vision: transforming proactive interaction from a judgment by a few teams into a main channel for AI's advancement into the physical world.
You are welcome to launch the service with one click in vLLM-Omni, or start it locally with one click from the repository:
Code Repository: https://github.com/jd-opensource/JoyAI-VL-Interaction
Model Hub: https://huggingface.co/jdopensource/JoyAI-VL-Interaction-Preview
Dataset Hub: https://huggingface.co/datasets/jdopensource/JoyAI-VL-Interaction
Technical Report: https://huggingface.co/papers/2606.14777








