【导读】GPT-5.5被扒出「假思考」,用两小时就被偷偷换成mini,200美元月费买了个「薛定谔的脑子」。Trace命令实锤,官方文档亲自认领。往后有纷纷吐槽:OpenAI,你糊弄谁呢?
ChatGPT又被爆「降智」了!
就在这两天,X上率先炸锅。
网友Lisan al Gaib发现,GPT-5.5用了一两个小时后突然变傻,每个请求都是秒回,质量断崖式下跌。
但界面上显示的,依然还是「GPT-5.5 Extended Thinking」。
也就是说,思考的标签还挂着,但思考本身已经消失了。

200美元/月,买了个「薛定谔的模型」
OpenAI开发者论坛上,一篇投诉帖同步爆了。
Agentify.sh表示,GPT-5.5用着用着会突然丧失遵循指令的能力。
眼瞧着它兴冲冲地宣布「修好了」,结果代码质量差到引发大面积回退。
之前5.5-med就能轻松搞定的UI任务,现在连最简单的改动都搞不定。
升到5.5-high,没用。再升到xhigh,还是不行。
而且xhigh以前能跑好几个小时,现在明显缩短了。
帖子一出,回复区瞬间炸了。
有人直接退回了5.4。
有人用的是xhigh最高档,但「跟上周比明显拉胯,长任务频繁出错,完全不遵循工作流」。
有人反映更离谱的情况,「简单查询也要转很久,你打断它纠正方向,它直接无视你,继续按之前错误的计划走」。
没错,所有人都在描述同一个现象——GPT的脑子,不知道什么时候被偷偷换掉了。
GPT-5.5目前的表现跟5.3差不多,毫不夸张。头几天还惊艳得不行,现在完全找不到当初那个模型的影子了。

不是错觉,OpenAI自己白纸黑字写着
为了验证,Lisan al Gaib专门做了一个对比测试。
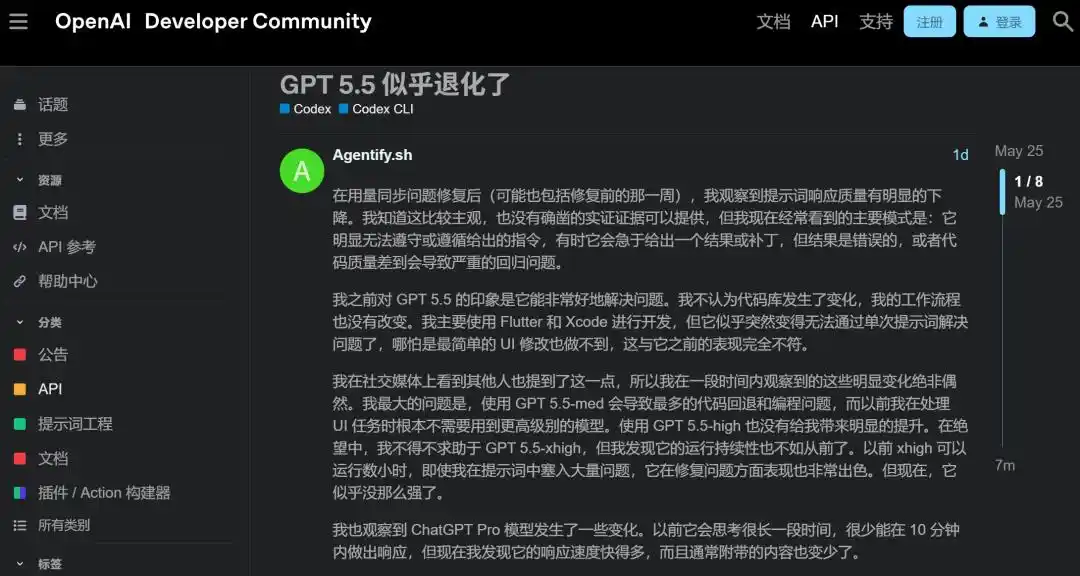
同一个账号,ChatGPT端用Extended Thinking跑出来的全是垃圾,转头到Codex端用xhigh,立刻恢复正常。
用他的原话说就是,Codex「简直比这玩意儿聪明40亿倍」。
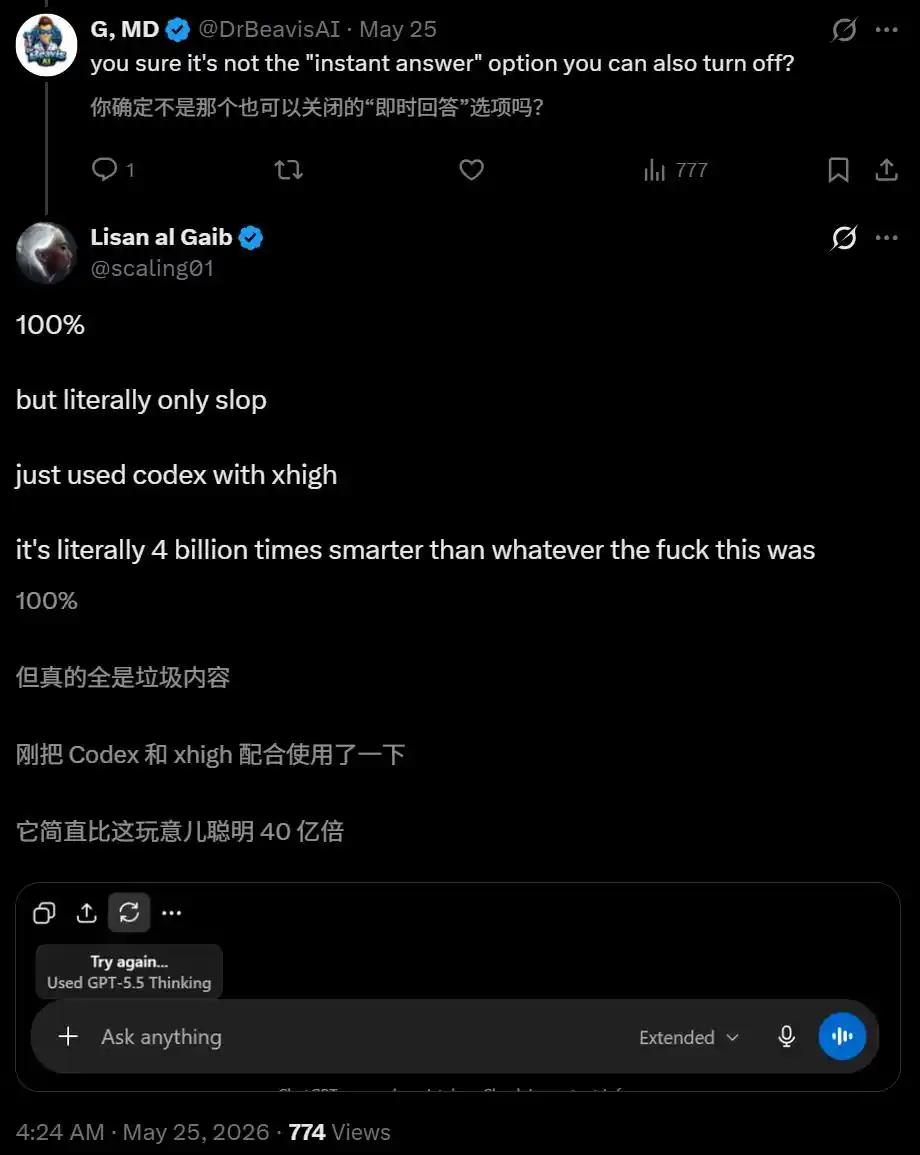
开发者Andrew Curran则想了个妙招——直接问模型「你的训练数据截止日期是什么?」
模型回答,August 2025。
问题是,GPT-5.5 Thinking的截止日期是12月。8月,是Instant版本的截止日期!
也就是说,他选的是Thinking,系统实际给他跑的是Instant。
界面上模型标签一个字都没变,但背后的模型已经被偷偷换掉了......
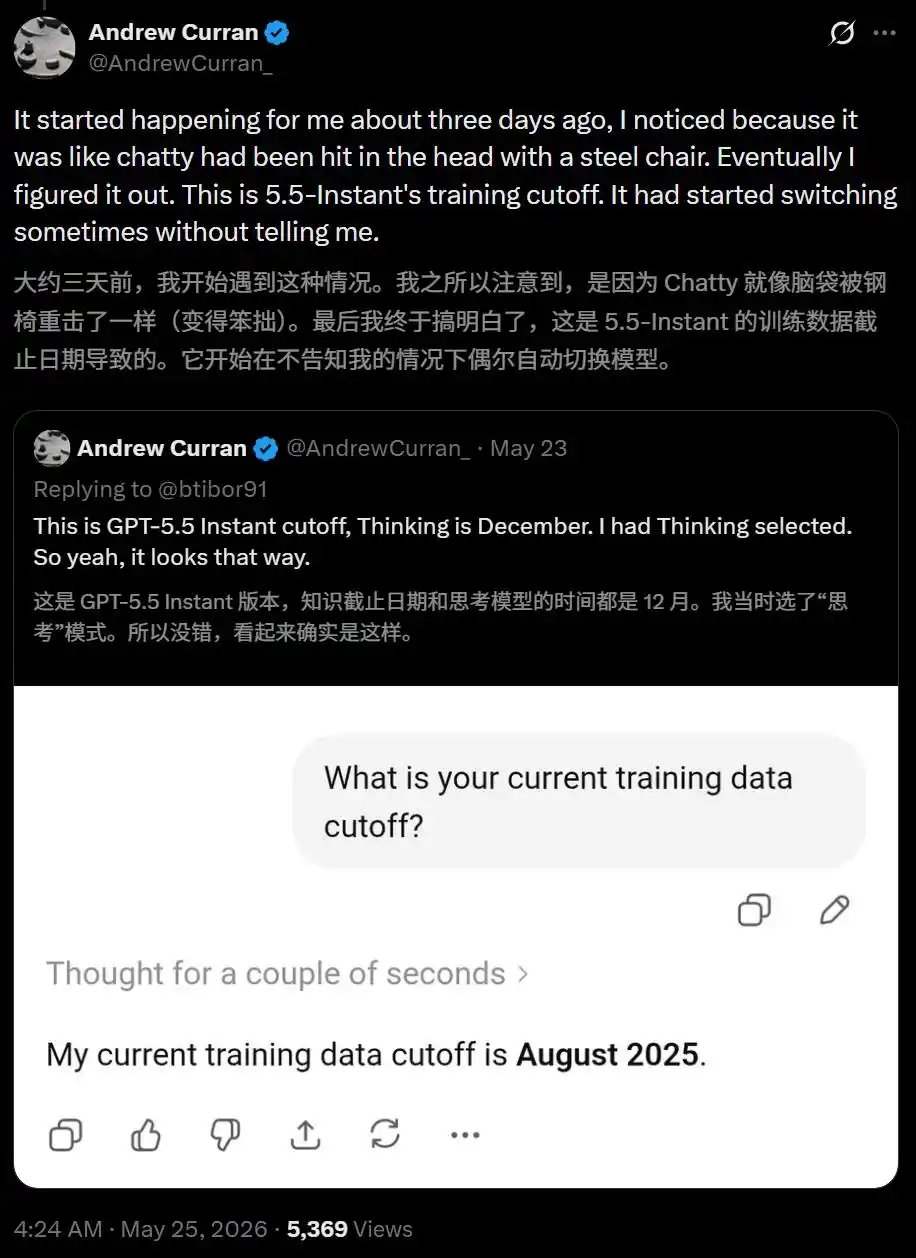
搞笑的是,这次OpenAI竟然在自己的帮助文档里替用户做了实锤。
根据OpenAI Help Center的官方说明,Plus用户每3小时最多发送160条GPT-5.5消息。
用完之后,系统会静默切换到mini模型,直到额度重置。
注意「静默」两个字。
没有弹窗提示,没有模型标签变化,没有任何视觉反馈。
你还以为自己在用旗舰模型,对面已经悄悄换成了mini。
Pro用户也别高兴太早。
Heavy思考模式,那个Pro独享的最高推理档位,在服务器负载高的时候,同样会被容量限流。同样没有预警。
换句话说,200美元/月的Pro订阅,买到的是一个随时可能被「偷梁换柱」的服务。

而这种「标签没变,脑子换了」的操作,在Codex端更早就被人抓包了。
今年2月,GitHub上出现了一个issue,一个Pro用户用trace命令抓到,自己请求的是GPT-5.3 Codex,实际返回的模型是GPT-5.2。
连5.2 Codex都不是,是更低的基础版5.2。
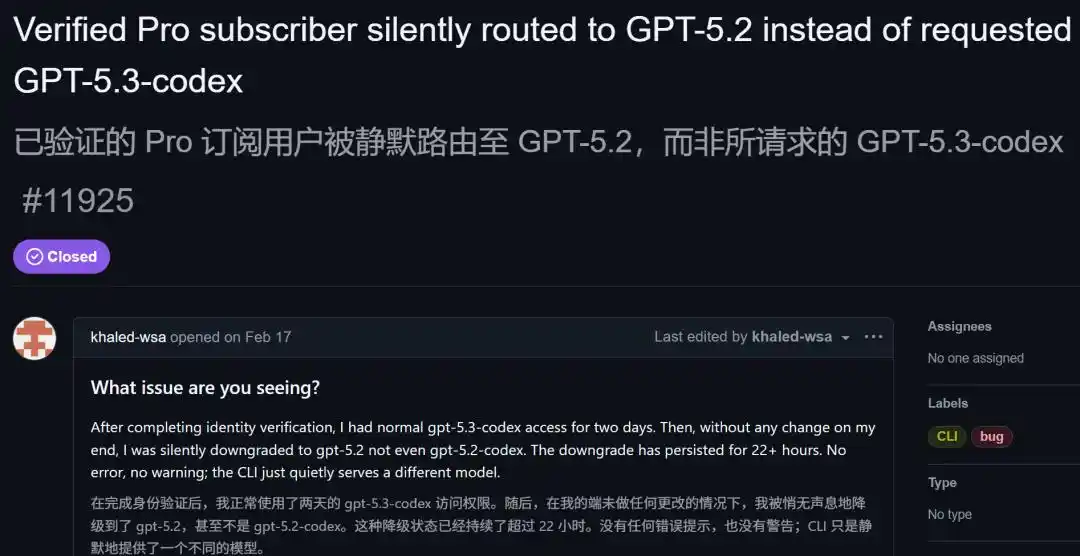
他贴出了复现命令:
- RUST_LOG='codex_api::sse::responses=trace' codex exec --skip-git-repo-check -s read-only -m 'gpt-5.3-codex' 'hi' 2>&1 >/dev/null | rg -o --replace '$1' '"model":"([^"]+)"' | head -n1
- 输出:gpt-5.2-2025-12-11
- 预期:gpt-5.3-codex
多个Pro用户在同一个issue下确认了同样的降级。
而且这种降级是「粘性的」,不会自己恢复,也没有任何解释。

甚至,在4月GPT-5.5发布当天,还有用户报告Fast模式的速度跟Standard差不多,但计费还是按Fast来的。
简单任务跑了7分49秒,正常应该5-6分钟。
OpenAI承认了,然后就没有然后了
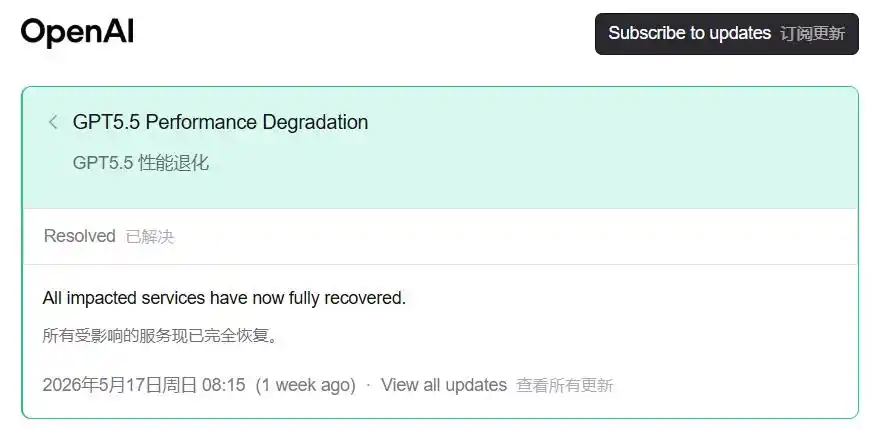
5月15日,OpenAI的status页面出现了一条记录。
GPT5.5 Performance Degradation,我们正在调查部分用户反映的GPT-5.5性能下降问题。
5月17日,状态更新为「已解决」。
但从论坛帖子的时间线来看,5月24-26日的降智投诉比5月15日那波更猛。
要么「解决」了的问题又回来了,要么压根就没真正解决。
每次升级都是一次「降智争议」
虽然各家都会遇到「模型变蠢」的吐槽,但OpenAI从GPT-5到GPT-5.5的每个更新,一次都没缺席。
每一次OpenAI都说在调查,每一次都说已解决,然后下一个版本继续。
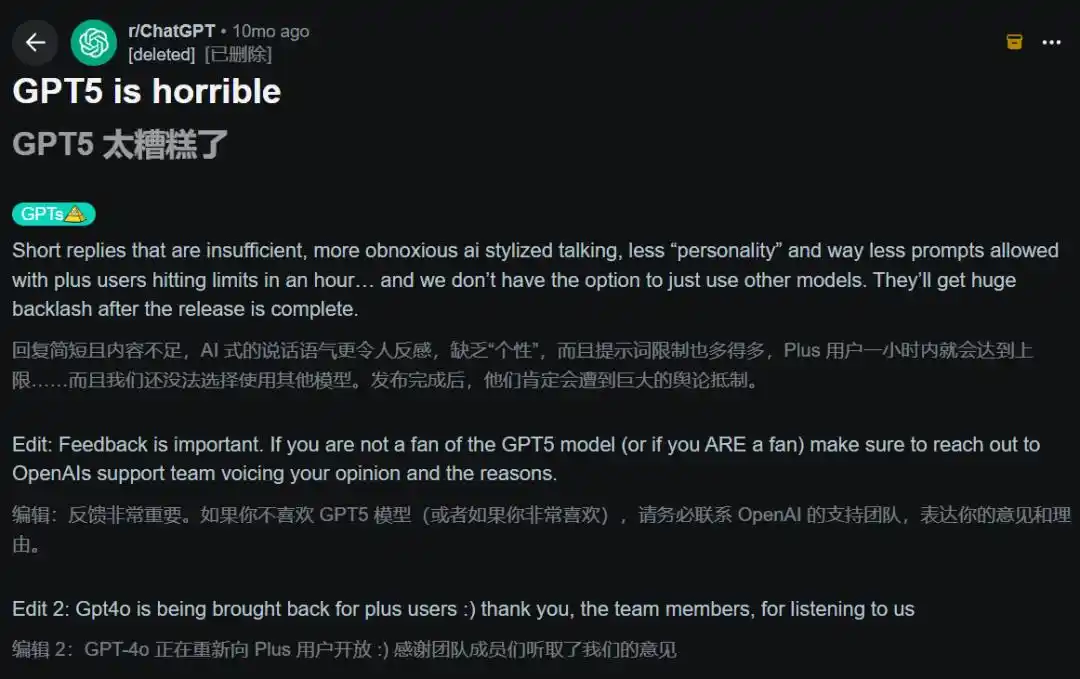
2025年8月,GPT-5首发。Reddit的热帖标题直接就是「GPT-5太烂了」。用户投诉短回复、更多拒绝、更少人格感。
OpenAI被迫紧急恢复GPT-4o选项。奥特曼在Reddit AMA上亲自承认「比我们预期的颠簸」。
2025年12月,GPT-5.2。翻译质量倒退,编造不存在的API,拒绝执行5.1能轻松完成的风格指令。
2026年2月,GPT-5.3-Codex。Pro用户被静默降级到5.2,trace命令实锤。
2026年3月,GPT-5.4。OpenAI社区论坛出现「GPT-5.4在Codex里明显退化了」帖子,网友回复全部确认。
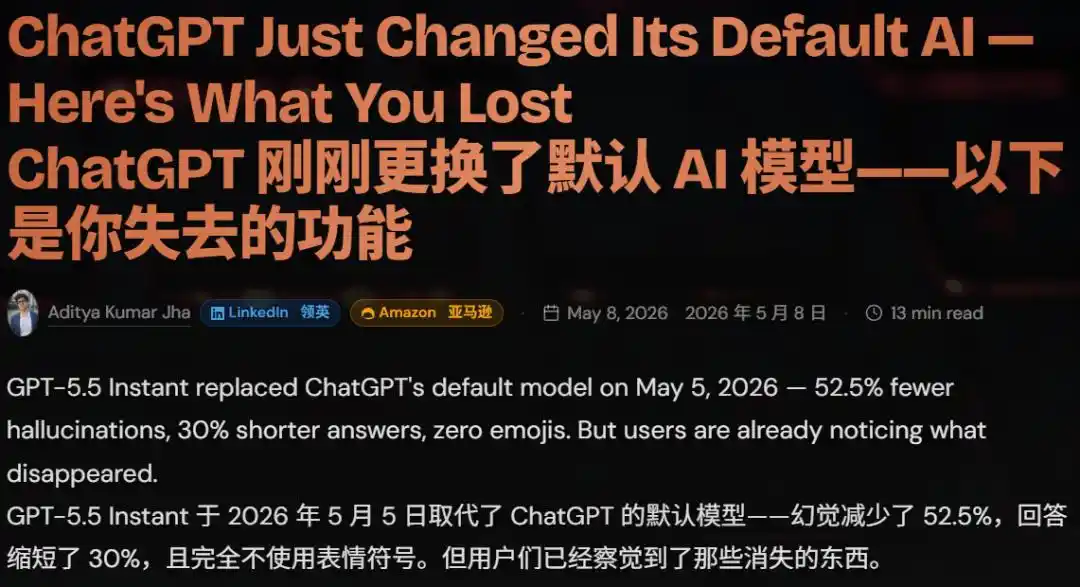
2026年5月初,GPT-5.5 Instant上线。回复长度缩短30%,emoji几乎消失。网友总结:精度提升了,但温度消失了。
2026年5月下旬,也就是现在。Thinking模式的降智投诉再次爆发。
Lisan al Gaib透露,自从GPT-5发布时他带头打了那场ChatGPT Plus额度争夺战之后,「每周都会收到这样的私信」。
最新一条是有人求他帮忙把xhigh/heavy thinking要回来。
跑分最强的那天,是发布日
chatgptdisaster.com整理了1087条经过验证的用户投诉,其中一类被反复提到的场景叫「路由层失灵」,UI显示GPT-5.5 Pro,输出完全是另一个档次的东西。
用户描述了一个可复现的模式,长会话后模型开始「完全无视你说的话」,但模型选择器上还挂着顶配标签。

最荒诞的注脚是,Plus用户160条/3小时用完后自动切换mini的机制,在OpenAI官方文档里被描述为一项「功能」。
为什么会这样?Lisan al Gaib分析认为,答案就两个字,省钱。
算力与盈利能力的紧缩正影响着每一个人。处处精打细算,不放过任何省钱的机会。
然而,就在GPT-5.5用户集体投诉的同一周,GPT-5.6的身影已经出现在了Codex后台日志里。
内部代号iris-alpha,150万Token上下文,Polymarket给出的6月发布概率超过85%。
一边是5.5用户连基础体验都保不住,一边是5.6已经在后台悄悄跑真实流量。
这就是2026年的ASI竞赛。
造新模型的速度越来越快,但让旧模型好好跑完一个会话却越来越难。
跑分最强的那一天永远是发布日,之后每一天都是薛定谔的GPT。

参考资料:https://x.com/scaling01/status/2058643470357590058?s=20
本文来自微信公众号“新智元”,作者:ASI启示录;编辑:摩西





