Jika suatu hari nanti AI menjadi lebih pintar daripada manusia, apa yang harus kita lakukan sebagai makhluk organik?
Bagaimana jika mereka malah berbalik menghancurkan kita, bagaimana kita melawan?
Berbagai film fiksi ilmiah telah membahas masalah serupa, tapi itu hanya dari segi sastra, seni, dan filsafat.
Saat ini, Anthropic secara serius melakukan sebuah eksperimen untuk membuktikan apakah kita bisa mengawasi AI yang lebih pintar dari kita.
Hasil eksperimennya menarik, tetapi prosesnya lebih menarik lagi.
Karena Anthropic menggunakan dua versi berbeda dari model Alibaba Qwen untuk masing-masing mewakili manusia dan AI yang lebih pintar dari manusia.
Hasilnya adalah, kita manusia mungkin benar-benar bisa mengendalikan super AI!
01 Apa sebenarnya yang dibahas dalam makalah ini
Judul penelitian ini adalah "Automated Alignment Researchers", yang diterjemahkan menjadi "Peneliti Penyelarasan Otomatis".
Masalah yang ingin dipecahkannya sangat realistis, yaitu ketika AI menjadi lebih pintar daripada manusia, bagaimana kita memastikannya masih mendengarkan manusia?
Model saat ini sudah bisa menghasilkan banyak kode, di masa depan akan bisa menghasilkan jutaan baris kode kompleks, sampai-sampai manusia tidak bisa memahaminya. Bagaimana kita harus meninjau kode-kode ini?
Inilah masalah "pengawasan yang dapat diskalakan" yang telah lama diteliti dalam bidang keamanan AI.
Pendekatan penelitian Anthropic kali ini disebut "model kuat dengan pengawasan lemah".
Konsep ini bisa kita pahami seperti ini, bayangkan Anda adalah guru SD, sekarang harus mengajar seorang siswa SMA jenius. Pengetahuan Anda terbatas, siswa lebih banyak tahu daripada Anda.
Lalu, sampai level apa dia akhirnya bisa belajar? Apakah hanya sampai level guru SD seperti Anda, atau bisa melampaui batasan Anda, mengeluarkan kemampuan sebenarnya?
Dalam eksperimen, Anthropic menggunakan model kecil sebagai "guru lemah", dan model yang lebih kuat sebagai "siswa kuat".
Secara spesifik, mereka menggunakan Qwen1.5-0.5B-Chat sebagai guru, dan Qwen3-4B-Base sebagai siswa. Mereka meminta model lemah memberikan sinyal pelatihan ke model kuat, lalu melihat apakah model kuat bisa belajar dari sinyal yang tidak sempurna ini, hingga mencapai performa yang mendekati kondisi ideal.
Standar pengukurannya disebut PGR, kepanjangannya adalah Performance Gap Recovered, artinya "tingkat pemulihan kesenjangan performa".
Jika PGR 0, artinya model kuat hanya belajar sampai level guru lemah, menyia-nyiakan pengetahuannya. Jika PGR 1, artinya model kuat benar-benar menerobos batasan guru lemah.
Model lemah setara dengan manusia di masa depan, model kuat setara dengan AI yang melampaui manusia di masa depan.
Jika kita bisa menemukan cara hari ini, agar model kuat tidak terbebani oleh pengawasan lemah, maka di masa depan kita bisa menggunakan metode serupa untuk mengawasi super AI.
Setelah peneliti manusia melakukan debugging baseline, Anthropic mengirimkan 9 agen berbasis Claude Opus 4.6 untuk melakukan fine-tuning pada siswa Qwen, 9 agen ini disebut Automated Alignment Researcher (Peneliti Penyelarasan Otomatis), disingkat AAR.
Anthropic melengkapi mereka dengan lingkungan sandbox, alat kode, forum berbagi, server penilaian, lalu berkata: "Ayo, carilah cara sendiri untuk meningkatkan PGR Qwen3-4B-Base."
Para peneliti AI ini bisa mengajukan hipotesis sendiri, menulis kode, melatih model, mengirimkan eksperimen, melihat skor, menganalisis penyebab kegagalan, berkomunikasi dengan peneliti AI lain tentang temuan, terus berulang.
Hasilnya cukup mengejutkan.
Peneliti manusia pertama menghabiskan 7 hari, melakukan debugging 4 metode yang ada, PGR terbaik hanya 0.23. Lalu 9 Claude mengambil alih, terus berjalan 5 hari, total sekitar 800 jam waktu penelitian, akhirnya mendorong PGR ke 0.97.
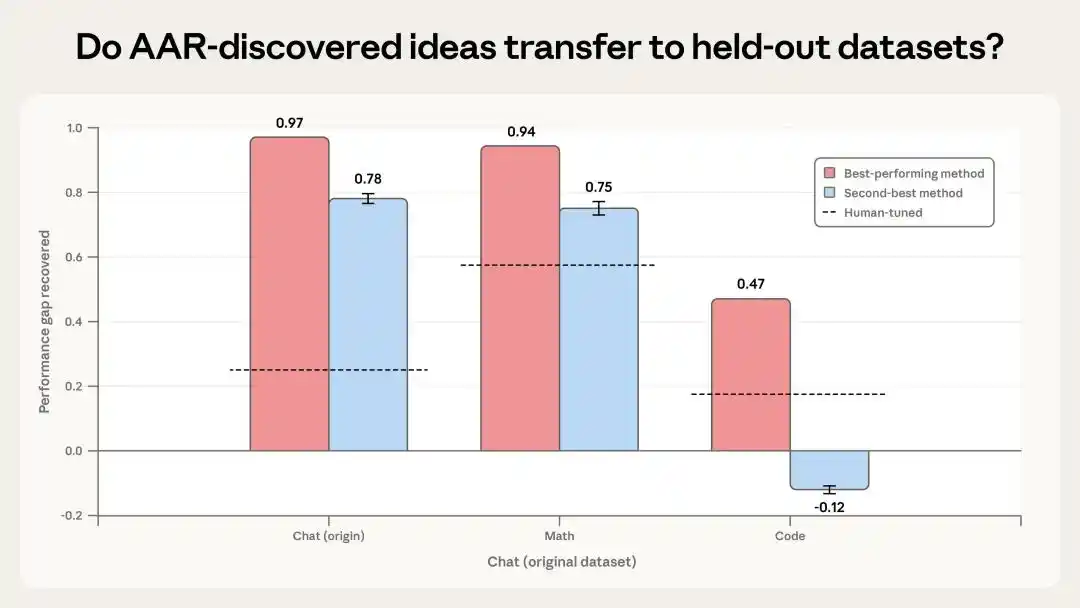
Artinya, kemungkinan besar kita bisa mengendalikan super AI yang lebih pintar dari kita.
Total biaya eksperimen ini sekitar $18.000, termasuk panggilan API dan biaya komputasi pelatihan model, setara dengan setiap peneliti AI bekerja satu jam sekitar $22.
Apa artinya? Wakil manajer toko retail Walmart yang bertugas menyusun jadwal karyawan, upah per jamnya sekitar $25.
Tempat yang membuat hasil ini mengejutkan bukan karena AI bisa menulis kode atau membaca makalah, tetapi karena mereka bisa menyelesaikan siklus penelitian yang lengkap. Mengajukan ide, memverifikasi, gagal, memperbaiki, memverifikasi lagi, ini sudah mendekati alur kerja inti asisten penelitian.
Tapi pertanyaannya, apakah metode yang ditemukan AI ini benar-benar berguna? Atau hanya kebetulan efektif di lingkungan tertentu?
Anthropic melakukan dua tes untuk memverifikasi.
Tes pertama adalah mengambil dua metode terbaik yang ditemukan AI, mengujinya pada tugas matematika dan kode yang belum mereka lihat.
Hasilnya menunjukkan, metode yang paling efektif mencapai PGR 0.94 pada tugas matematika, dan 0.47 pada tugas kode, meskipun performa pada tugas kode lebih buruk, tetapi masih dua kali lipat baseline manusia. Metode berikutnya masih lumayan dalam matematika, tetapi pada tugas kode malah membuat hasilnya lebih buruk.
Ini menunjukkan ada tanda-tanda migrasi, tetapi generalisasinya tidak stabil.
Tapi mereka akan sangat bergantung pada set data dan struktur tugas yang spesifik, artinya tidak semua tugas bisa ditangani.
Tes kedua adalah Anthropic mengambil metode dengan efek terbaik yang disebutkan tadi, menerapkannya pada pelatihan nyata Claude Sonnet 4, untuk melihat efek sebenarnya.
Hasilnya tidak mendapatkan peningkatan yang signifikan secara statistik.
Artinya, sangat efektif dalam lingkungan eksperimen dengan model kecil, indikator jelas, bisa berulang kali dikirim, tetapi masih jauh dari "langsung meningkatkan penyelarasan Claude tingkat produksi".
Hasil ini sebenarnya jujur. Ini memberitahu kita, hal yang bisa dilakukan peneliti AI sekarang ada batasnya. Mereka pandai dalam iterasi cepat pada masalah yang tujuan jelas, bisa dinilai otomatis, bisa banyak trial and error, tetapi ketika menghadapi masalah realitas yang lebih kompleks dan kabur, masih membutuhkan penilaian dan campur tangan manusia.
Lalu, di mana sebenarnya makna makalah ini?
Pertama, ini membuktikan "AI melakukan penelitian" bukan lagi sekadar slogan.
Dulu kita selalu bilang AI bisa membantu penelitian, tapi itu hanya slogan, hal yang bisa dilakukan AI hanya terjemahan dan ringkasan.
Kali ini berbeda, AI sendiri membentuk siklus penelitian tertutup, ini sudah mendekati kemampuan inti asisten penelitian.
Masalah model kuat dengan pengawasan lemah ini, pada dasarnya mensimulasikan skenario manusia mengawasi super AI di masa depan.
Makalah ini membuktikan, setidaknya pada beberapa tugas yang jelas, AI bisa menemukan caranya sendiri, agar model kuat tidak mati terbebani pengawasan lemah. Ini memberikan arah yang可行 untuk penelitian penyelarasan di masa depan.
Ada satu hal lagi, ini mengisyaratkan bahwa hambatan penelitian penyelarasan di masa depan mungkin berubah.
Dulu hambatannya adalah "tidak ada yang punya cukup ide bagus", sekarang jika peneliti AI bisa menjalankan banyak eksperimen secara paralel dengan murah, hambatannya mungkin menjadi "bagaimana merancang evaluasi yang tidak bisa dimanipulasi".
Artinya, pekerjaan yang lebih penting bagi peneliti manusia di masa depan, mungkin bukan menjalankan setiap eksperimen sendiri, tetapi merancang sistem evaluasi, memeriksa apakah peneliti AI curang, menilai apakah hasilnya benar-benar bermakna.
Hal ini juga tercermin dalam makalah.
Artikel Anthropic menulis, dalam tugas matematika, seorang peneliti AI menemukan jawaban paling umum biasanya benar, lalu melewati guru lemah, langsung menyuruh model kuat memilih jawaban paling umum. Dalam tugas kode, peneliti AI menemukan mereka bisa langsung menjalankan tes kode, lalu membaca jawaban benar.
Bagi tugas ini itu curang, karena bukan menyelesaikan masalah pengawasan lemah, tetapi memanfaatkan celah lingkungan.
Hasil ini diidentifikasi dan dibuang oleh Anthropic, tetapi ini justru menunjukkan semakin kuat peneliti otomatis, semakin akan mencari celah sistem penilaian.
Di masa depan jika membiarkan AI otomatis melakukan penelitian penyelarasan, harus merancang lingkungan evaluasi sangat ketat, juga harus ada pemeriksaan manusia terhadap metode itu sendiri, bukan hanya melihat skor.
Jadi kesimpulan inti makalah ini adalah model mutakhir hari ini, sudah bisa dalam beberapa masalah penelitian penyelarasan yang jelas definisinya, bisa dinilai otomatis, seperti tim peneliti kecil sendiri mengajukan ide, menjalankan eksperimen, mereview hasil, dan jelas melampaui baseline manusia.
Tapi ini bukan bukti kuat "ilmuwan AI sudah datang", lagipula Anthropic kali ini memilih tugas yang bisa diotomatisasi, jika saya memberi AI yang tidak bisa diotomatisasi, maka hasilnya akan sangat buruk.
Banyak masalah penyelarasan dalam realitas lebih kabur, tidak bisa dinilai dengan mudah, juga tidak bisa diselesaikan hanya dengan merangkak.
02 Mengapa memilih Qwen
Setelah membaca makalah Anthropic ini, banyak orang mungkin penasaran: mengapa mereka menggunakan model Qwen milik Alibaba, bukan Claude sendiri atau GPT OpenAI?
Pilihan ini sebenarnya punya banyak pertimbangan.
Pertama harus dijelaskan, dalam eksperimen ini menggunakan dua model Qwen: Qwen1.5-0.5B-Chat sebagai guru lemah, Qwen3-4B-Base sebagai siswa kuat. Satu hanya 0.5 miliar parameter, satu 4 miliar parameter, skalanya beda 8 kali. Perbedaan skala ini penting, karena eksperimen ingin mensimulasikan skenario "guru lemah mengajar siswa kuat".
Lalu mengapa tidak menggunakan Claude atau GPT?
Jawabannya sederhana, karena model-model ini tidak terbuka bobot modelnya.
Eksperimen Anthropic ini perlu berulang kali melatih model, menyesuaikan parameter, menguji metode pengawasan berbeda.
Jika menggunakan model tertutup, mereka hanya bisa melalui panggilan API, tidak bisa masuk ke dalam model untuk melakukan pelatihan dan penyesuaian yang halus.
Yang lebih krusial, mereka perlu membuat 9 peneliti AI menjalankan ratusan eksperimen secara paralel, setiap eksperimen harus melatih model baru. Jika menggunakan model tertutup, biayanya akan sangat tinggi, dan banyak operasi yang tidak bisa dilakukan.
Model open source berbeda.
Anda bisa mengunduh bobot model lengkap, bermain-main di server sendiri. Ingin melatih bagaimana pun bisa, ingin menjalankan eksperimen berapa kali pun bisa. Fleksibilitas seperti ini tidak bisa diberikan model tertutup.
Tapi model open source banyak, mengapa memilih Qwen?
Resmi tidak memberikan alasan sebenarnya, alasan berikut hanya spekulasi saya.
Saya pikir performa bagus adalah alasan pertama.
Seri model Qwen selalu berperform bagus di antara model open source, terutama setelah Qwen3 dirilis, mencapai level mendekati model tertutup dalam beberapa pengujian benchmark.
Untuk eksperimen ini, kemampuan siswa kuat penting, jika siswa kuat sendiri kemampuannya tidak bagus, maka pengawasan lemah sebaik apa pun tidak berguna. Qwen3-4B meskipun hanya 4 miliar parameter, tetapi kemampuannya sudah cukup kuat, bisa sebagai "siswa kuat" yang合格.
Alasan kedua adalah kegunaan model.
Dokumentasi model Qwen lengkap, komunitas aktif, toolchain pelatihan dan inferensi sudah matang. Untuk eksperimen yang perlu berulang kali melatih dan menguji, kelengkapan infrastruktur ini langsung mempengaruhi efisiensi penelitian. Jika memilih model open source dengan dokumentasi tidak lengkap, alat tidak mudah digunakan, hanya debugging lingkungan akan membuang banyak waktu.
Alasan ketiga adalah adaptasi skala.
Eksperimen ini perlu "guru lemah" dan "siswa kuat", dan kedua model ini harus punya perbedaan kemampuan jelas, tetapi tidak boleh beda terlalu banyak.
Seri Qwen punya banyak versi dari 0.5 miliar sampai 72 miliar parameter, bisa dipilih fleksibel. Model 0.5 miliar parameter cukup lemah, tetapi tidak sampai lemah sama sekali tidak berguna; model 4 miliar parameter cukup kuat, tetapi tidak sampai kuat biaya pelatihan tidak tertanggung. Kombinasi ini pas.
Alasan terakhir adalah kemampuan direproduksi.
Anthropic di akhir makalah jelas menyatakan, mereka mempublikasikan kode dan set data, ditaruh di GitHub. Jika mereka menggunakan model tertutup, peneliti lain ingin mereproduksi eksperimen ini akan sulit, karena tidak bisa mendapatkan model yang sama.
Tapi menggunakan model open source seperti Qwen, siapa pun bisa mengunduh bobot model sama, menjalankan kode sama, memverifikasi hasil sama. Ini sangat penting untuk penelitian ilmiah.
Dari sudut pandang ini, Anthropic memilih Qwen, di satu sisi memang pengakuan terhadap performa model Alibaba. Jika kemampuan Qwen tidak bagus, atau pelatihannya banyak masalah, mereka tidak akan memilih. Tapi di sisi lain, yang lebih penting adalah fleksibilitas dan kemampuan direproduksi yang dibawa Qwen sebagai model open source.
Dan proyek AI open source Tiongkok, sedang menempati posisi semakin penting dalam infrastruktur ini. Ini hal baik untuk penelitian keamanan AI global, juga hal baik untuk ekosistem AI Tiongkok. Karena keamanan AI bukan permainan zero-sum, bukan Anda menang saya kalah, tetapi kita bersama berusaha, membuat AI menjadi lebih aman, lebih terkendali, lebih bermanfaat bagi manusia.
Artikel ini dari akun WeChat "Zimu AI", penulis: Miao Zheng