【Pembuka】 Dalam WWDC yang baru berlalu, kelahiran kembali Siri Apple dengan AI menjadi kata kunci, 'model sisi perangkat' telah menjadi tren! Lebih awal lagi, Andrej Karpathy menyerukan untuk memisahkan pengetahuan dari model, hanya menyisakan 'inti kognitif'. Sebuah perusahaan China mengklaim telah mewujudkan arah ini—dengan 4B parameter, mencapai hasil yang setara dengan model besar triliunan dalam tugas kecerdasan kolektif. Apa yang bisa diubah oleh model kognitif sisi perangkat?
Tadi malam, Siri terlahir kembali dengan bantuan Gemini 1,2 triliun parameter dari Google.
Namun di sisi lain, Amazon menghentikan papan peringkat AI internalnya yang kontroversial—karyawan banyak menggunakan alat AI, menyebabkan biaya komputasi melonjak hingga manajemen tidak bisa duduk tenang.
Biaya Token menjadi hambatan terbesar untuk implementasi AI skala besar.
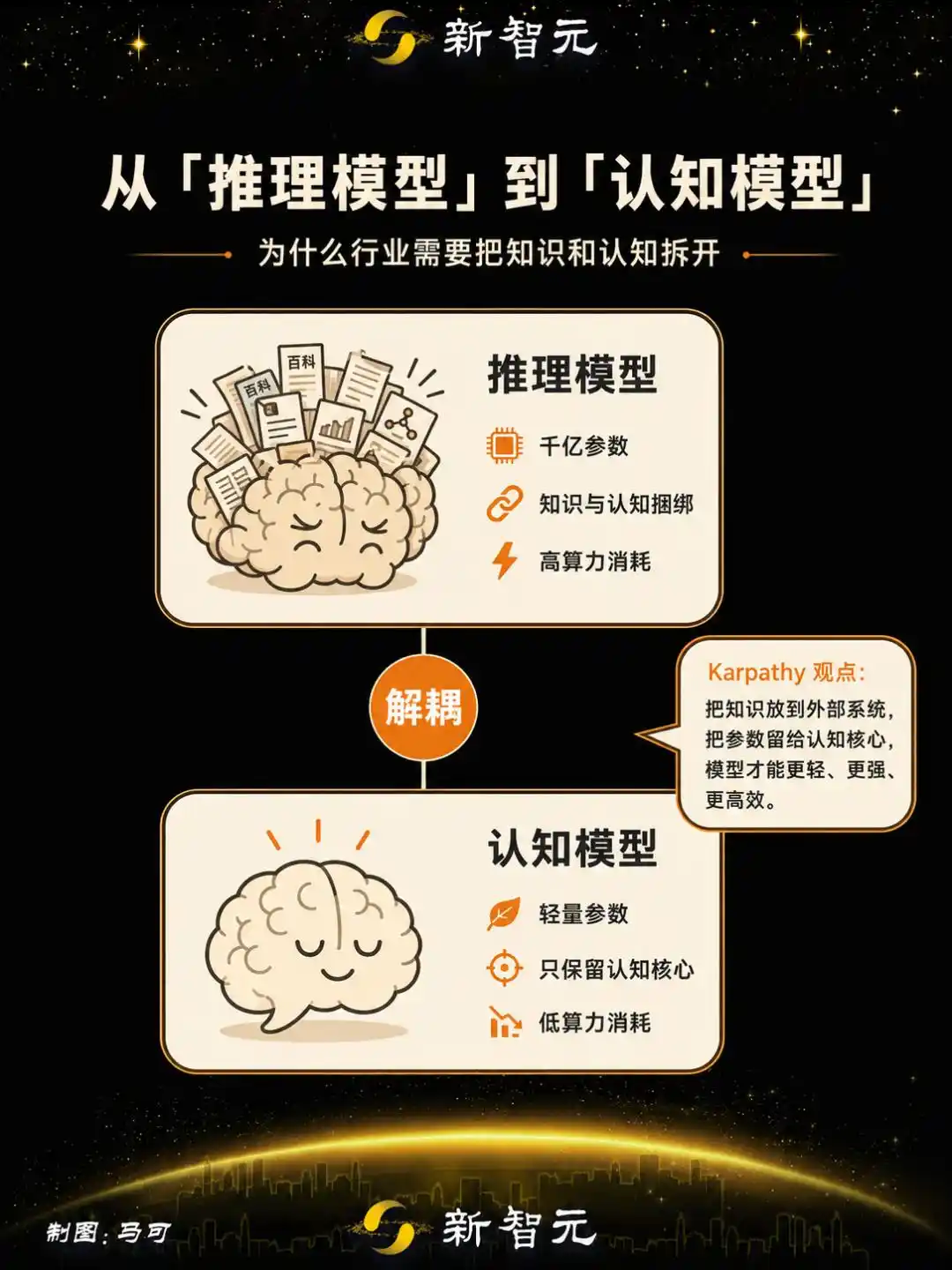
Andrej Karpathy sebelumnya memberikan sebuah arah dalam wawancara: pisahkan pengetahuan luas dari model, simpan hanya sebuah 'inti kognitif' yang bisa berpikir, merencanakan, dan tahu apa yang tidak diketahuinya, cukup dengan parameter level 1B.

https://www.youtube.com/watch?v=lXUZvyajciY
Arah ini sedang dibuktikan.
Sebuah model dengan 4B parameter, dalam tugas kecerdasan kolektif, menghasilkan hasil yang setara dengan model besar triliunan seperti GPT-5.4, dan mendukung penyebaran di sisi perangkat.
Ini berasal dari tim pendiri yang pernah mengalahkan Llama 65B dengan 3.6B parameter, menduduki peringkat pertama Hugging Face Jepang.
Kali ini, mereka membuatmodel kognitif sisi perangkat pertama di industri.
Ramalan Karpathy dan Tagihan Daya Komputasi
Tekanan biaya daya komputasi telah berubah dari isu teknis menjadi isu keuangan, kasus Amazon hanyalah puncak gunung es.
Karyawan Amazon sering menggunakan kemampuan inferensi model besar melalui alat AI internal, mendorong pengeluaran daya komputasi secara keseluruhan, manajemen terpaksa menghentikan mekanisme papan peringkat untuk menekan penggunaan.

https://www.ft.com/content/b1a62a7f-6df5-4c90-94ce-64ce9c9961b6?syn-25a6b1a6=1
Industri sedang mengalami 'penarikan besar-besaran Token' pertama, konsumsi daya komputasi harian beberapa perusahaan telah mencapai skala ratusan juta yuan.
Model bisnis model besar menabrak tembok struktural: semakin kuat kemampuannya, semakin dalam rantai inferensinya, semakin tinggi biaya panggilan tunggal.
Rasio Biaya GPU terhadap Pendapatan (GPU Cost / Revenue) adalah indikator kunci bagi semua perusahaan AI, tren ekspansi parameter model hanya akan membuat indikator ini lebih buruk.
Pemikiran Karpathy menunjuk ke jalur lain: dia mengusulkan perlunya memisahkan 'memori/pengetahuan' dari model, menyimpan apa yang dia sebut 'inti kognitif'—
entitas yang telah dilucuti dari fakta dan pengetahuan yang luas, tetapi mempertahankan algoritma berpikir, keajaiban kecerdasan, strategi pemecahan masalah.
Dia menilai, bahkan pada skala 1 miliar parameter, pemikiran seperti manusia yang efisien dapat diwujudkan:
Ia akan berpikir seperti manusia...... Jika Anda menanyakan pertanyaan faktual, mungkin perlu mencari—ia tahu bahwa ia tidak tahu, dan akan mencari.
Pernyataan ini memicu diskusi luas di komunitas teknologi.
Konsensus tentang arah sedang terbentuk, tetapi tim yang mampu mendorong 'inti kognitif' dari konsep ke produk yang dapat diterapkan, adalah variabel yang sesungguhnya.
4B Menyamai Triliunan, Apa yang Dilakukan Nextie Alpha
Yang mendorong 'inti kognitif' yang digambarkan Karpathy dari konsep ke produk, adalah Nextie (Ming Ri Xin Cheng).
Perusahaan ini melatih model inferensi sumber terbuka dengan pembelajaran penguatan, memisahkan pengetahuan dan kognisi—melucuti cadangan pengetahuan memori dari model, memperkuat kemampuan generalisasi dan berpikir abstrak.
Model yang dihasilkan dinamaiNextie Alpha, skala parameter 4B, telah menyelesaikan pelatihan dan diluncurkan,adalah produk pertama yang didefinisikan sebagai 'model kognitif' di industri.
Secara konkret tentang metode pelatihannya, sebenarnya adalah titik awal yang tidak biasa.
Tim Nextie mengumpulkan makalah akademik manusia dari tahun 1800 hingga 2020, melintasi 220 tahun, mencoba merunut evolusi kecerdasan kolektif, untuk memberikan referensi bagi rute teknis.
Berdasarkan penelitian ini, mereka melakukan pembelajaran penguatan pada model inferensi sumber terbuka, berfokus pada peningkatan kemampuan generalisasi dan abstraksi.
Berikan contoh intuitif: model yang telah dilatih dapat mentransfer pola keputusan pemain Go ke skenario kehidupan sehari-hari—apa yang disebut Karpathy 'mempertahankan algoritma berpikir', di sini memiliki implementasi teknis yang konkret.
Pada tingkat efektivitas, Nextie Alpha dalam tugas kecerdasan kolektif (debat, refleksi, tantangan, pemungutan suara, dll.), dengan 4B parameter mencapai kualitas keluaran yang setara dengan model besar seperti GPT-5.4, dengan keunggulan signifikan dalam konsumsi daya komputasi dan kecepatan inferensi.
Yang lebih perlu diperhatikan adalah ruang skenario yang dibuka oleh model ini, memiliki tiga lapisan makna yang progresif.
Lapisan pertama, peningkatan kualitas keputusan multi-agen.
Dalam kerangka keputusan Harness, menggunakan model kognitif menghasilkan efek keluaran yang lebih baik daripada model inferensi.
Peningkatan model dasar dari 'inferensi' menjadi 'kognitif', membawa lonjakan kualitas keseluruhan rantai keputusan dalam sistem kolaborasi multi-agen.
Lapisan kedua, pengurangan biaya daya komputasi secara signifikan.
4B dibandingkan dengan model triliunan parameter, biaya daya komputasi untuk penyebaran di cloud berkurang drastis.
Nextie Alpha juga mendukung penyebaran di sisi perangkat—MacBook, perangkat embodied intelligence dapat dijalankan langsung, biaya daya komputasi dengan demikian berubah menjadi biaya listrik.
Ini sangat berarti bagi bidang embodied intelligence: menggunakan model besar triliunan parameter untuk menggerakkan robot rumah tangga, setiap 'berpikir' mengkonsumsi banyak Token, biaya keseluruhannya mungkin lebih mahal daripada menyewa orang untuk membersihkan rumah.
Penyebaran 4B di sisi perangkat, secara fundamental mengubah perhitungan ini.
Lapisan ketiga, membuka kunci skenario proaktif (Proactive).
Sebagian besar produk AI saat ini berjalan dalam mode responsif (Reactive)—pengguna memberikan perintah, model merespons.
Mode Proactive berarti agen cerdas membuat keputusan dan menjalankan tugas secara mandiri, tanpa menunggu perintah, skala bisnis jauh melampaui Reactive, tetapi sebelumnya selalu terhalang oleh biaya daya komputasi.
Nextie Alpha mendukung operasi tanpa henti 24 jam, dengan biaya terkendali, membuat agen cerdas proaktif yang sebelumnya ditunda karena terlalu mahal menjadi mungkin.

Kartu As Tim dan Posisi di Jalur
Nextie didirikan oleh tim pendiri Microsoft Xiaoice.
Label tim ini adalah 'menang dengan parameter kecil melawan parameter besar'—sebelumnya, model sumber terbuka yang dilatih, rinna (Xiaoice Jepang), dengan 3.6B parameter menduduki peringkat pertama Hugging Face Jepang, mengalahkan Llama dengan 65B parameter.
Nextie Alpha dengan 4B mencapai efek yang setara dengan model besar triliunan, melanjutkan gen teknologi yang sama.
Jalur yang diandalkan oleh Nextie adalah—Harness, multi-agen kolektif.
Jalur ini sedang mendapatkan konfirmasi dari modal terkemuka—pada Maret 2026, OpenAI berinvestasi di perusahaan startup Isara, langsung mendorong valuasinya ke $6,5 miliar, arah penelitian Isara adalah kolaborasi multi-agen dan kecerdasan kolektif.

https://www.wsj.com/tech/ai/openai-backs-new-ai-startup-seeking-bot-army-breakthroughs-a0b1fedc
Dalam evaluasi mendalam kecerdasan (IDI) di bidang ini, kinerja keseluruhan Nextie secara signifikan lebih tinggi daripada model besar tunggal mana pun.
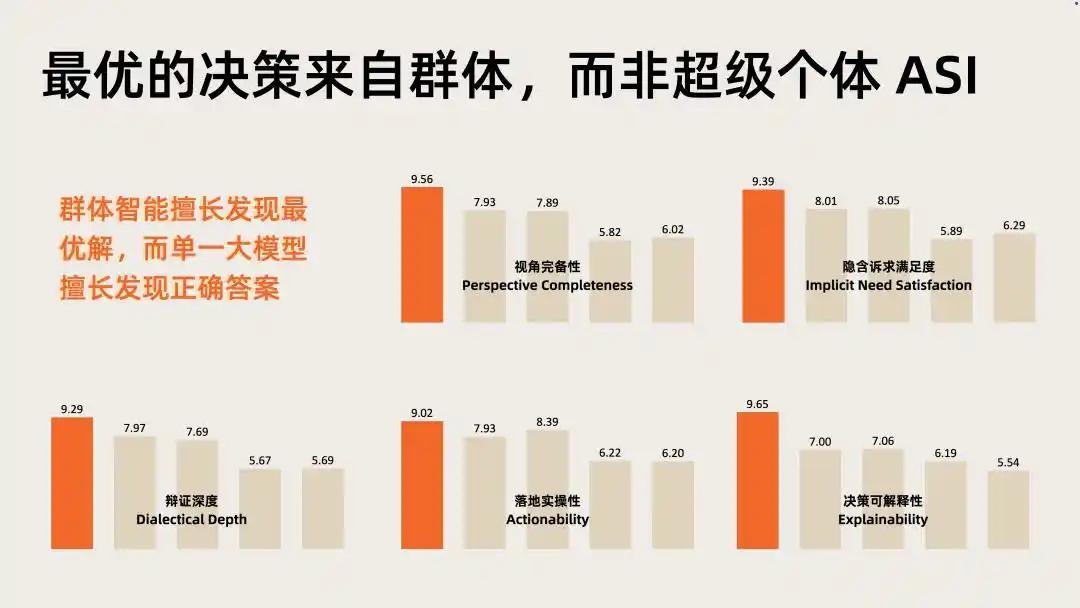
Modal memvalidasi nilai jalur, data evaluasi menandai posisi Nextie di dalam jalur.
Dua sinyal ini digabungkan, menunjuk pada penilaian yang sama: multi-agen kolektif adalah arah bernilai tinggi berikutnya di lapisan aplikasi AI, model kognitif adalah infrastruktur kunci untuk menggerakkannya.
Model Kognitif Mengubah Bukan Hanya Parameter, Tapi Juga Buku Besar
Rasio Biaya GPU terhadap Pendapatan (GPU Cost / Revenue) adalah pedang Damokles yang menggantung di atas semua perusahaan AI.
Solusi yang diberikan oleh model kognitif, intinya menunjuk pada rekonstruksi model ekonomi—dengan 4B mencapai efek yang biasanya membutuhkan triliunan parameter, berarti kualitas keluaran yang sama sesuai dengan struktur biaya yang sama sekali berbeda.
Nextie dalam wawancara mengungkapkan, tim sedang melatih model kognitif 8B dengan kemampuan generalisasi yang lebih kuat.
Jika 4B sudah bisa menyaingi GPT-5.4 dalam tugas kecerdasan kolektif, batas kemampuan 8B patut ditunggu.
Pertanyaan yang lebih mendalam ditinggalkan untuk seluruh industri:Ketika biaya menjalankan model kognitif di sisi perangkat secara terus-menerus turun ke tingkat yang dapat diabaikan, semua produk AI yang dirancang berdasarkan mode responsif (Reactive) 'pengguna memberikan perintah, model merespons' saat ini, mungkin perlu meninjau kembali bentuk produk mereka.
Ruang imajinasi bisnis dari agen cerdas proaktif (Proactive), jauh melampaui segala sesuatu di bawah agen cerdas responsif (Reactive) saat ini.
Artikel ini berasal dari akun WeChat publik "Xin Zhi Yuan", penulis: ASI启示录







