Kecerdasan Buatan Umum (AGI), akan segera tiba.
Baru saja, Kepala Ilmuwan Penelitian OpenAI, Mark Chen, menyatakan dengan percaya diri:
Dalam arti tertentu, seperti harapan Anda bisa merasakannya, AGI (Kecerdasan Buatan Umum) akan segera datang...
Kita semakin mendekati dunia di mana model mampu mengusulkan lebih banyak inovasi secara mandiri—mereka mampu melakukan penelitian yang berkelanjutan sendiri.
Ini bukan hanya peningkatan efisiensi, tetapi 'evolusi' itu sendiri juga dialihdayakan kepada kehidupan berbasis silikon.
Saat Mark Chen dengan mahir memotong jamur dan bawang di depan kamera, yang dia bicarakan bukan hanya semangkuk sup, tetapi benteng terakhir peradaban manusia.
Jika AI dapat meneliti dirinya sendiri, maka pada malam menjelang kedatangan AGI, peran apa sebenarnya yang harus dimainkan manusia?

Setiap Bidang Mengalami 'Langkah Dewa' Sendiri
Untuk memahami bobot pernyataan ini, kita harus kembali ke saat Mark memasuki bidang ini.
2016, AlphaGo melawan Lee Sedol.

Di permainan kedua, ada satu langkah bernama 'Langkah ke-37', pada saat itu, semua pemain catur manusia secara kolektif tidak memahaminya.
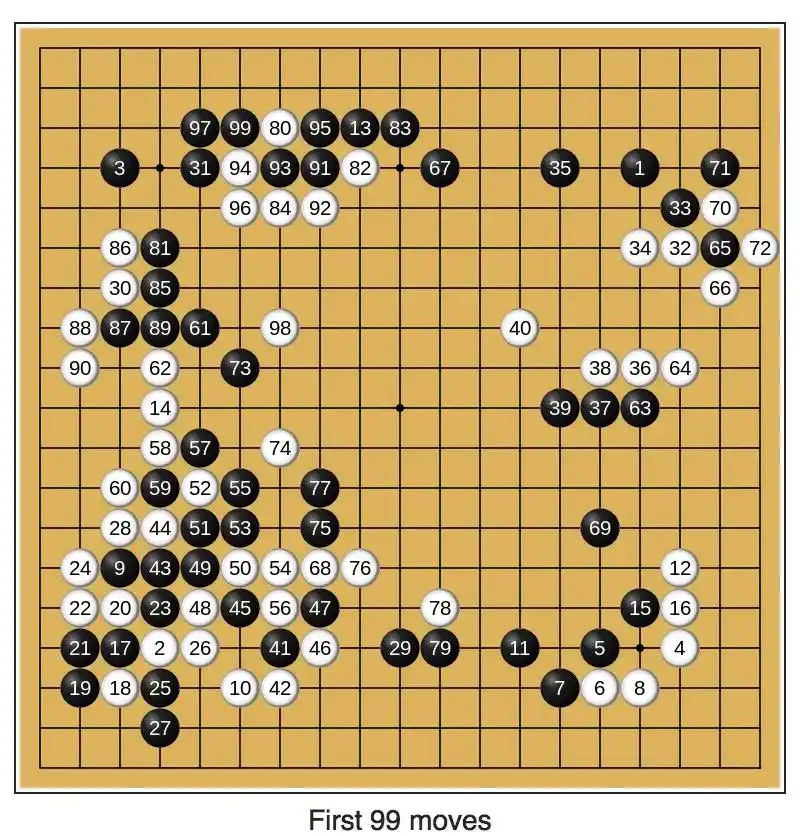
Kemudian baru disadari, itu adalah langkah yang diambil mesin, yang sama sekali tidak terpikirkan oleh manusia. Momen itu menyulut banyak orang, dan juga menarik Mark Chen ke bidang ini.
Dan sekarang?
"Yang paling gila adalah," kata Mark, "sekarang kamu hampir di setiap bidang, bisa melihat 'langkah dewa'."
Ada di matematika, ada di ilmu komputer, ada di pemrograman.
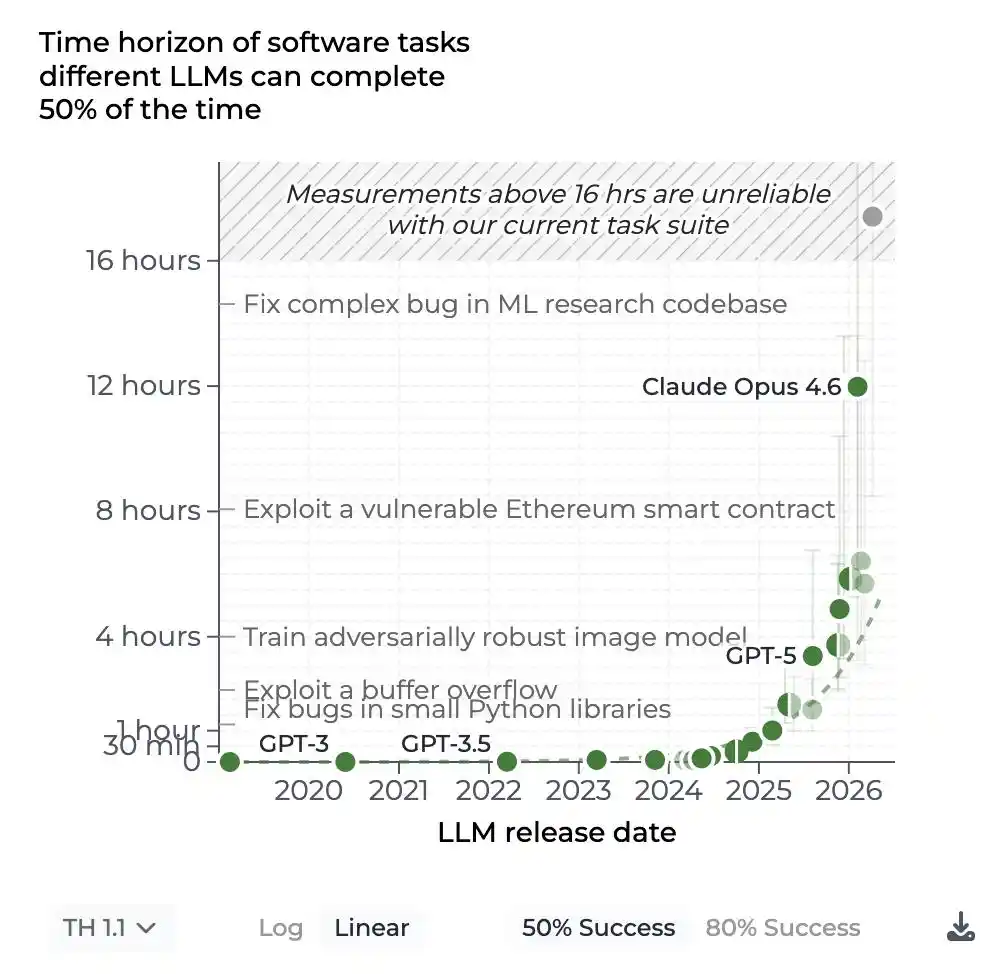
Dia menggambarkan momen yang sangat halus: banyak orang 'terbangun' di awal tahun ini, tiba-tiba menyadari: AI agent di bidang saya, benar-benar bisa bekerja.
Bukan mainan. Bukan demo. Tapi bisa menyelesaikan pekerjaan nyata yang bermakna, jangka panjang (long-horizon work) untukmu.
Ini berarti hal 'model melakukan penelitian sendiri' ini, bukan lagi adegan dari film fiksi ilmiah.
Itu adalah langkah berikutnya yang secara alami diekstrapolasi dari serangkaian 'langkah dewa' yang sudah terjadi.
Jika kamu mengikuti garis ini ke depan, di ujungnya berdiri model yang bisa melakukan penelitian sendiri.
Scaling Belum Berhenti, Pra-pelatihan Belum Mati
Tapi optimisme ini, sebenarnya ditopang oleh apa?
Ditopang oleh satu keyakinan: Kurva Scaling belum mencapai ujungnya.
Dua tahun terakhir, pendapat 'pra-pelatihan sudah mati' dan 'model bahasa tidak akan mencapai AGI' sering muncul.
Mark Chen 'sangat menentang' penilaian pesimis ini.
Dia menyingkap polanya.
'Pra-pelatihan sudah mati' terdengar segar, tapi sebenarnya itu adalah naskah usang yang telah diputar ulang berulang kali selama bertahun-tahun.

Setiap kali, ada yang menunjuk ke suatu hambatan dan berkata 'sudah puncak, tidak bisa lewat'; setiap kali, OpenAI selalu bisa mengeluarkan teknik rekayasa baru, atau wawasan penelitian baru, untuk menembus tembok itu.
Mark Chen yakin, "Kita berada di kurva eksponensial. Ini telah bertahan selama hampir 10 tingkat besaran, tidak ada alasan mengapa itu tidak akan terus bertahan."

Dan bukti yang paling meyakinkan, adalah OpenAI sendiri pernah berjudi dan menang satu kali.
Berjudi pada penalaran (reasoning).
Saat o1 baru dimulai, bahkan di dalam OpenAI sendiri ada yang tidak percaya.
Saat itu paradigma 'pra-pelatihan + pasca-pelatihan' terlalu kuat, orang secara alami bertanya: Mesin sudah berjalan dengan baik, mengapa repot-repot mengutak-atik yang lain?
Adalah Jakub Pachocki, Ilya Sutskever, dan beberapa orang lain yang memiliki keyakinan dan penilaian kuat, yang mendorong keras, perlahan-lahan mengubahnya menjadi taruhan fundamental perusahaan.

Setahun kemudian, o1 lahir, paradigma penalaran mengguncang seluruh industri.
Kurva belum berakhir, ditambah dengan fakta bahwa terobosan terbesar sering datang dari taruhan yang awalnya tidak dipercaya siapa pun. Kedua hal ini digabungkan, itulah dasar keberanian Mark Chen mengatakan 'penelitian mandiri model tidak jauh lagi'.
Saat model mulai berpikir pada tugas-tugas yang berlangsung selama berminggu-minggu, bahkan berbulan-bulan, inovasi yang dihasilkannya mungkin telah melampaui titik buta kognitif para ahli manusia.
Inilah dasar dari 'penelitian mandiri': jika ia dapat menyimpulkan rumus matematika yang belum pernah dilihat manusia, tentu ia juga dapat menulis arsitektur algoritma yang lebih baik daripada manusia.
Vibe Researcher: Saat Eksekusi Menjadi Murah
Kita sudah memiliki vibe coder — cukup berbicara, biarkan AI menulis kode.

Penelitian, juga sedang bergerak ke arah ini.
Dalam wawancara, sebuah konsep yang sangat kontroversial berulang kali disebut: Vibe Researcher (Peneliti Suasana/Aura).
Ini adalah prediksi profesi yang sedikit merendahkan diri tetapi direnungkan matang-matang.
Mark percaya, peneliti top di masa depan tidak akan lagi menjadi orang yang menulis setiap baris kode PyTorch, melainkan orang yang 'menguasai perasaan/perasaan'.

Baik di OpenAI maupun laboratorium lain, Anda mulai melihat, banyak pekerjaan berubah menjadi terutama 'pengaturan/orchestration'.
Diterjemahkan ke bahasa manusia: manusia bertanggung jawab memberi ide, model bertanggung jawab menyelesaikan semua pekerjaan.
Peneliti menggunakan pikiran untuk memikirkan ide, sisanya implementasi, eksekusi, penjadwalan, model yang mengurus sendiri.
Peta jalan tiga tahun OpenAI, tujuannya ditulis dengan jelas: membuat model melakukan penelitian end-to-end (ujung ke ujung), dari mengusulkan ide hingga menghasilkan hasil, semuanya dilakukan sendiri.
Tapi Di Jalan Ini, Penuh Dengan Lubang yang Belum Terisi
Seiring dengan AI mampu menjalankan dan mengatur (Orchestration) tugas secara mandiri, pekerjaan manusia akan dikompresi dengan ekstrem ke kedua ujung:
1. Mengajukan pertanyaan yang benar-benar penting.
2. Menilai apakah jawaban AI memiliki 'jiwa'.
Inilah yang disebut 'Selera (Taste)'.
Karena mesin tidak memiliki 'kehidupan', maka ia tidak memiliki 'akal sehat', sehingga tidak dapat menghasilkan 'selera'.
Tapi dengan tenang dipikir, Mark Chen sendiri lebih dari siapa pun menyadari, jalan ini jauh dari mulus.
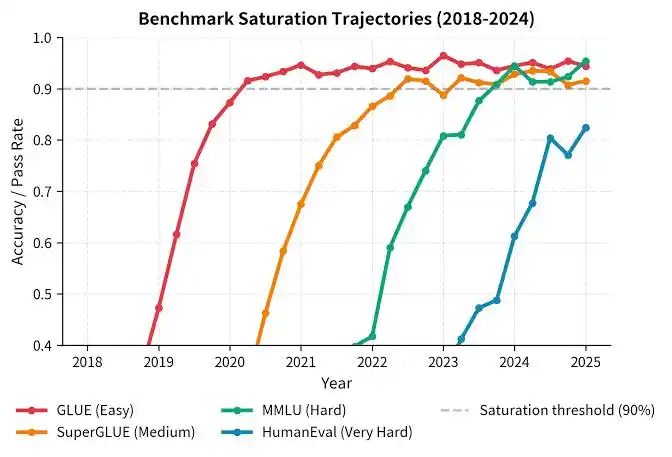
Lubang pertama: Evaluasi, kacau.
Dia menggunakan istilah internal, disebut 'Benchmaxxing' — mencari sekumpulan soal yang hampir identik dengan dataset uji, latih habis-habisan, skornya bagus luar biasa, kemampuan generalisasi tidak meningkat sedikit pun.
Lebih buruk lagi, benchmark standar emas yang diakui jumlahnya terlalu sedikit.
"Kita benar-benar berada dalam krisis evaluasi," katanya. Tes klasik seperti SAT, untuk model saat ini semuanya sudah jenuh.
Bahkan, begitu sebuah evaluasi dirilis ke dunia, itu bukan lagi evaluasi yang baik, seperti kertas ujian yang langsung tidak berlaku begitu dicetak.
Dua strategi untuk menghadapi masalah ini:
1. Memisahkan tim pembuat evaluasi dari tim pengoptimalan model, membentuk insentif yang bersifat adversarial (berlawanan).
2. Melakukan penyebaran model skala besar dan mengamati pola kegagalan dalam aplikasi nyata.
Dia juga mencatat, setiap kemampuan baru yang muncul akan diikuti dengan kebutuhan evaluasi yang sesuai, dan mengarahkan arah evaluasi adalah bagian yang cukup penting dari pekerjaannya.
Lubang kedua: Perbatasan yang tidak rata (jagged frontier).
Model bisa menyelesaikan soal sulit tingkat Olimpiade Matematika atau Olimpiade Informatika, tetapi mungkin tidak bisa menangani hal-hal sepele yang bisa dilakukan manusia dengan santai, seperti seorang jenius yang bisa menghitung kalkulus di kepala tetapi tidak bisa mengikat tali sepatunya sendiri.
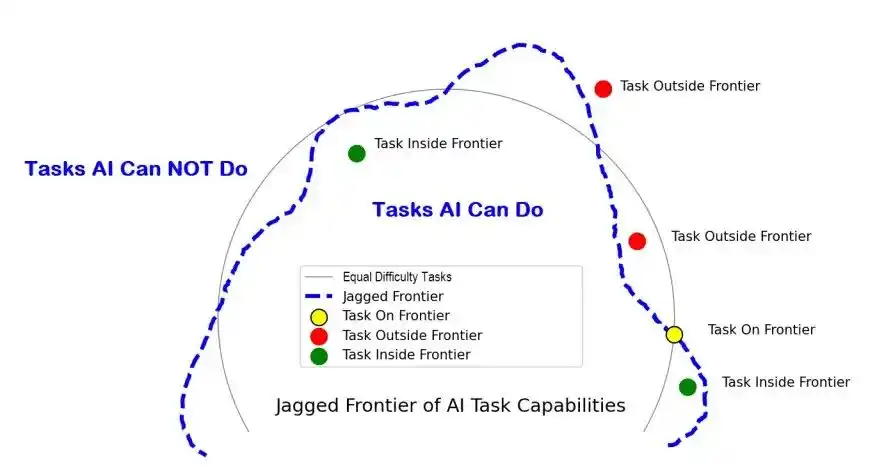
Beda di mana? Beda di 'konteks', beda di pembelajaran berkelanjutan (continual learning) — menggunakan pelajaran yang didapat dari satu tugas, untuk tugas berikutnya.
Ini terlalu alami bagi manusia, tetapi bagi model, itu adalah tulang keras yang sedang diperjuangkan mati-matian oleh seluruh industri.
Saat ditanya apakah menuju AGI masih membutuhkan dua atau tiga terobosan fundamental, Mark tidak menjawab langsung.
Dia berkata, pembelajaran berkelanjutan semacam itu adalah 'kemampuan dasar yang harus dibuka kuncinya', apakah itu dianggap 'terobosan' atau tidak dia tidak yakin, tetapi 'banyak tembakan sudah mengincar gawang, saya cukup yakin mereka akan masuk.'
Ini adalah sikapnya: lubang itu nyata, setiap lubang sudah ada yang mengisinya, dan dia bertaruh mereka bisa mengisinya.
Metafora Sup: Setelah AGI, Buka Warung Mie
Momen paling hangat dalam wawancara, adalah cerita tentang 'sup'.
Konon, Mark Zuckerberg pernah mencoba merekrut peneliti OpenAI dengan sup buatannya sendiri, dan tanggapan Mark Chen adalah: langsung membawa sup ke kantor dan membagikannya kepada semua orang.
Saat ditanya tentang keinginan terbesar setelah AGI terwujud, orang yang mengendalikan otak AI paling kuat di dunia ini menjawab:
"Saya ingin membuka warung mie. Ini mungkin hobi saya setelah AGI."
Jawaban ini menyimpan makna yang dalam.
Saat AI dapat menyelesaikan semua 'penelitian mandiri', ketika semua pengetahuan dan inovasi dapat dihasilkan dengan kecepatan cahaya, sumber daya paling langka bagi manusia bukan lagi kecerdasan, melainkan 'pengalaman'.
Mesin dapat menghitung kadar asin optimal semangkuk sup, tetapi tidak akan pernah dapat memberikan sup itu 'kehangatan' dan 'cerita'.
Referensi:
https://www.youtube.com/watch?v=fpAthTtha8c
https://finance.biggo.com/podcast/1241bc21164ccc75
Artikel ini berasal dari akun WeChat "Xin Zhi Yuan", penulis: ASI Revelation