Delapan tahun lalu, ZTE mengalami henti jantung.
Pada 16 April 2018, sebuah larangan dari Biro Industri dan Keamanan Departemen Perdagangan AS membuat ZTE, perusahaan peralatan komunikasi terbesar keempat di dunia dengan 80.000 karyawan dan pendapatan tahunan lebih dari 100 miliar yuan, berhenti beroperasi dalam semalam. Isi larangannya sederhana: selama tujuh tahun ke depan, dilarang bagi perusahaan AS mana pun untuk menjual komponen, barang, perangkat lunak, dan teknologi kepada ZTE.
Tanpa chip Qualcomm, produksi base station terhenti. Tanpa lisensi Android dari Google, ponsel juga tidak memiliki sistem yang dapat digunakan. 23 hari kemudian, ZTE mengumumkan bahwa operasi utama perusahaan tidak dapat dilanjutkan.
Namun, ZTE akhirnya bertahan hidup, dengan biaya 1,4 miliar dolar AS.
Denda 1 miliar dolar AS, dibayar sekaligus; jaminan 400 juta dolar AS, disimpan di rekana escrow bank AS. Selain itu, semua manajemen eksekutif diganti, menerima tim pengawasan kepatuhan dari AS. Sepanjang tahun 2018, ZTE mengalami kerugian bersih 7 miliar yuan, dengan pendapatan turun drastis 21,4%.
Ketua ZTE saat itu, Yin Yimin, menulis dalam surat internal: "Kami berada di industri yang kompleks dan sangat bergantung pada rantai pasokan global." Kalimat ini, pada saat itu, terdengar seperti refleksi, juga ketidakberdayaan.
Delapan tahun kemudian, pada 26 Februari 2026, unicorn AI China DeepSeek mengumumkan bahwa model multimodal V4 yang akan dirilis, akan memprioritaskan kerja sama mendalam dengan produsen chip domestik, untuk pertama kalinya mencapai alur lengkap dari pra-pelatihan hingga penyesuaian halus tanpa solusi NVIDIA.
Diterjemahkan: kami tidak menggunakan NVIDIA lagi.
Saat berita ini keluar, reaksi pertama pasar adalah keraguan. Pangsa pasar NVIDIA di pasar chip pelatihan AI global lebih dari 90%. Meninggalkannya, apakah masuk akal secara komersial?
Namun, di balik pilihan DeepSeek, tersembunyi masalah yang lebih besar dari logika komersial: AI China, sebenarnya membutuhkan kemandirian komputasi seperti apa?
Apa Sebenarnya yang Dijepit
Banyak orang mengira, larangan chip menjepit perangkat keras. Tetapi yang benar-benar membuat perusahaan AI China tercekik adalah sesuatu yang disebut CUDA.
CUDA, singkatan dari Compute Unified Device Architecture, adalah platform komputasi paralel dan model pemrograman yang diluncurkan NVIDIA pada tahun 2006. Ini memungkinkan pengembang untuk secara langsung memanggil daya komputasi GPU NVIDIA guna mempercepat berbagai tugas komputasi kompleks.
Sebelum era AI tiba, ini hanyalah alat untuk segelintir geek. Tetapi ketika gelombang pembelajaran mendalam datang, CUDA menjadi fondasi seluruh industri AI.
Pelatihan model AI besar, pada dasarnya adalah operasi matriks dalam jumlah besar. Dan ini persisnya adalah pekerjaan yang paling dikuasai GPU.
NVIDIA, dengan persiapan lebih dari sepuluh tahun sebelumnya, menggunakan CUDA untuk membangun satu set lengkap rantai alat dari perangkat keras dasar hingga aplikasi atas bagi pengembang AI global. Hari ini, semua kerangka kerja AI utama global, dari TensorFlow milik Google hingga PyTorch milik Meta, terikat dalam dengan CUDA.
Seorang doktor AI, dari hari pertama masuk, belajar, memprogram, dan bereksperimen di lingkungan CUDA. Setiap baris kode yang ditulisnya, memperkuat parit pertahanan NVIDIA.

Hingga 2025, ekosistem CUDA telah memiliki lebih dari 4,5 juta pengembang, mencakup lebih dari 3.000 aplikasi yang dipercepat GPU, dan lebih dari 40.000 perusahaan di seluruh dunia menggunakan CUDA. Angka ini berarti lebih dari 90% pengembang AI global terikat dalam ekosistem NVIDIA.
Hal yang menakutkan dari CUDA adalah, ia adalah sebuah flywheel. Semakin banyak pengembang yang menggunakan, akan menghasilkan semakin banyak alat, pustaka, dan kode, ekosistem semakin makmur; semakin makmur ekosistem, semakin menarik lebih banyak pengembang untuk bergabung. Flywheel ini, sekali berputar, hampir tidak dapat digoyahkan.
Hasilnya, NVIDIA menjual sekop termahal kepada Anda, dan juga mendefinisikan satu-satunya cara menambang. Ingin mengganti sekop? Bisa. Tetapi Anda harus menulis ulang semua pengalaman, alat, dan kode yang telah dikumpulkan oleh puluhan ribu otak paling cerdas di dunia dalam postur ini selama lebih dari sepuluh tahun.
Biayanya, siapa yang membayar?
Jadi, ketika pada 7 Oktober 2022, putaran pertama pengendalian BIS diterapkan, membatasi ekspor NVIDIA A100 dan H100 ke China, perusahaan-perusahaan AI China untuk pertama kalinya merasakan perasaan tercekik seperti ZTE. NVIDIA kemudian meluncurkan versi "khusus China" A800 dan H800, mengurangi bandwidth interkoneksi antar chip, mempertahankan pasokan dengan susah payah.
Tapi hanya setahun kemudian, pada 17 Oktober 2023, putaran kedua pengendalian kembali diperketat, A800 dan H800 juga dilarang, 13 perusahaan China dimasukkan dalam daftar entitas. NVIDIA terpaksa meluncurkan H20 yang lebih dikebiri. Pada Desember 2024, putaran terakhir pengendalian dalam masa jabatan pemerintahan Biden diterapkan, bahkan ekspor H20 dibatasi secara ketat.
Tiga putaran pengendalian, berlapis-lapis.
Tapi kali ini, arah cerita, sangat berbeda dengan ZTE dulu.
Sebuah Terobosan Asimetris
Di bawah larangan, semua orang mengira, mimpi model besar AI China akan berakhir.
Mereka salah. Menghadapi blokade, perusahaan China tidak memilih untuk berhadapan langsung, tetapi memulai sebuah terobosan. Medan pertempuran pertama terobosan ini, bukan pada chip, tetapi pada algoritma.
Pada akhir 2024 hingga 2025, perusahaan-perusahaan AI China secara kolektif beralih ke arah teknologi: model ahli campuran.
Sederhananya, memecah model besar menjadi banyak ahli kecil, saat menangani tugas hanya mengaktifkan beberapa yang paling relevan, bukan membuat seluruh model bergerak.
V3 DeepSeek adalah perwakilan tipikal dari pemikiran ini. Ia memiliki 671 miliar parameter, tetapi setiap inferensi hanya mengaktifkan 37 miliar di antaranya, hanya 5,5% dari total. Dalam hal biaya pelatihan, ia menggunakan 2048 GPU NVIDIA H800, dilatih selama 58 hari, total biaya 5,576 juta dolar AS. Sebagai perbandingan, perkiraan biaya pelatihan GPT-4 sekitar 78 juta dolar AS. Perbedaan satu tingkat.
Optimasi algoritma yang maksimal, langsung tercermin pada harga. Harga API DeepSeek, input per juta Token hanya 0,028 hingga 0,28 dolar AS, output 0,42 dolar AS. Sedangkan harga input GPT-4o adalah 5 dolar AS, output 15 dolar AS. Claude Opus lebih mahal, input 15 dolar AS, output 75 dolar AS. Dikonversi, DeepSeek 25 hingga 75 kali lebih murah daripada Claude.
Perbedaan harga ini, mendapat tanggapan besar di pasar pengembang global. Pada Februari 2026, di platform agregasi API model AI terbesar global OpenRouter, volume panggilan mingguan model AI China melonjak 127% dalam tiga minggu, untuk pertama kalinya melampaui AS. Setahun sebelumnya, pangsa model China di OpenRouter kurang dari 2%. Setahun kemudian, tumbuh 421%, mendekati 60%.
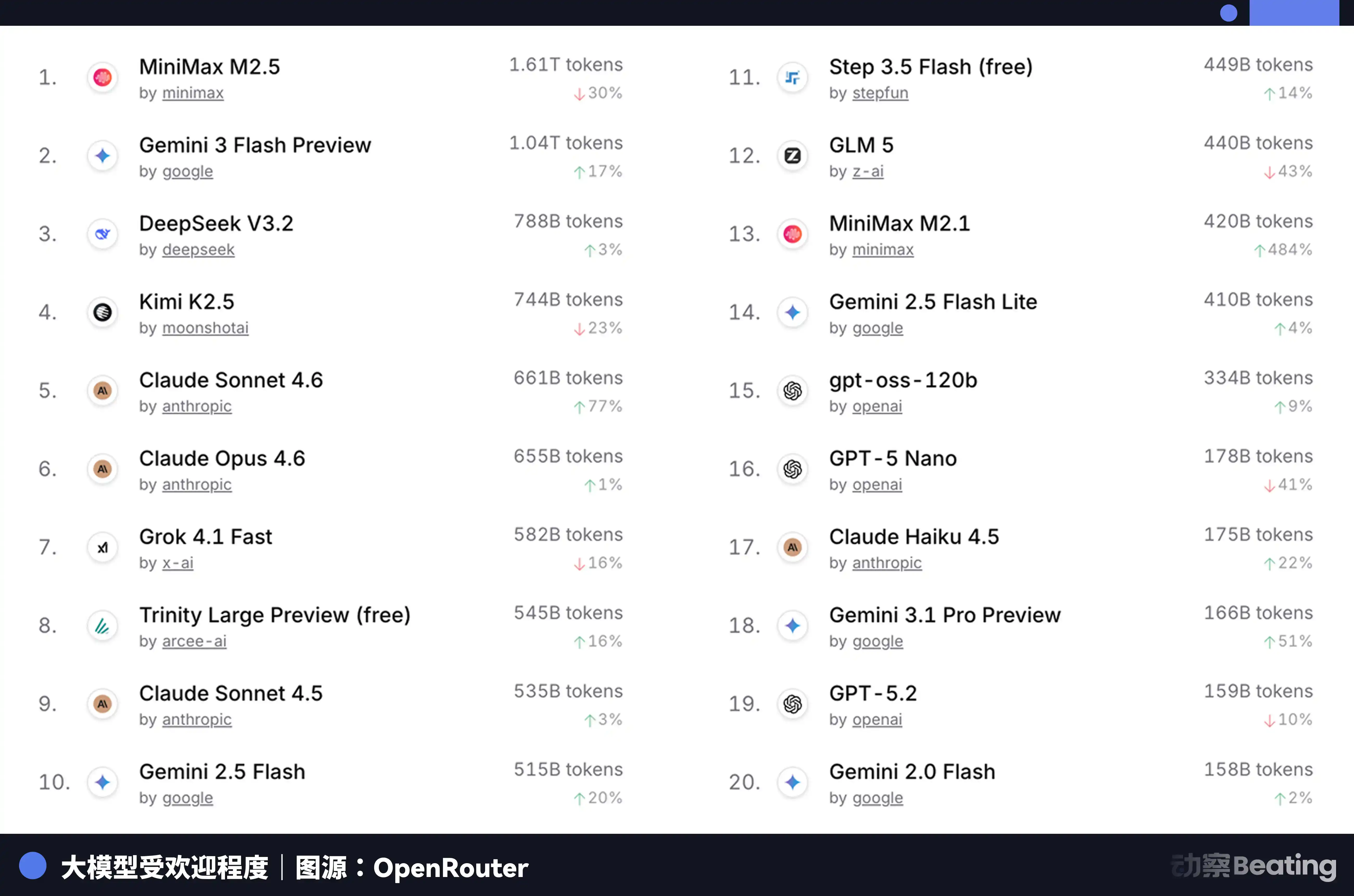
Di balik data ini, ada perubahan struktural yang mudah diabaikan. Pada paruh kedua 2025, skenario utama aplikasi AI beralih dari obrolan ke Agen. Dalam skenario Agen, konsumsi Token untuk satu tugas adalah 10 hingga 100 kali lipat dari obrolan sederhana. Ketika konsumsi Token tumbuh secara eksponensial, harga menjadi faktor penentu. Harga yang sangat terjangkau dari model China, tepat menginjak jendela ini.
Tapi masalahnya, penurunan biaya inferensi tidak menyelesaikan masalah mendasar pelatihan. Sebuah model besar jika tidak dapat terus dilatih dan diiterasi pada data terbaru, kemampuannya akan cepat menurun. Dan pelatihan, tetap merupakan lubang hitam komputasi yang tidak dapat dihindari.
Lalu, dari mana "sekop" untuk pelatihan datang?
Pengganti Menjadi Andalan
Xinghua, Jiangsu, kota kecil di tengah Jiangsu, terkenal dengan baja tahan karat dan makanan kesehatan, sebelumnya tidak ada hubungannya dengan AI. Tetapi pada tahun 2025, sebuah lini produksi server komputasi domestik sepanjang 148 meter dibangun dan mulai berproduksi di sini, dari penandatanganan hingga produksi, hanya butuh 180 hari.
Inti dari lini produksi ini adalah dua chip yang sepenuhnya domestik: prosesor Loongson 3C6000 dan kartu akselerator AI Taichu Yuanqi T100. Loongson 3C6000, dari set instruksi hingga arsitektur mikro semuanya dikembangkan secara mandiri. Tauch Yuanqi berasal dari Pusat Superkomputer Nasional Wuxi dan tim Universitas Tsinghua, mengadopsi arsitektur heterogen banyak inti.
Saat lini produksi ini berproduksi penuh, 5 menit menghasilkan satu server, lini produksi ini total investasi 1,1 miliar yuan, diperkirakan produksi tahunan 100.000 unit.
Yang lebih penting, berdasarkan kluster ribuan kartu yang terdiri dari chip domestik ini, telah mulai menangani tugas pelatihan model besar yang sebenarnya.
Pada Januari 2026, Zhipu AI bersama Huawei merilis GLM-Image, ini adalah model generasi gambar SOTA pertama yang mencapai pelatihan penuh sepenuhnya mengandalkan chip domestik. Pada Februari, model besar "Xingchen" milik China Telecom dengan skala miliaran, menyelesaikan pelatihan alur lengkap di kolam komputasi ribuan kartu domestik di Lingang, Shanghai.

Arti dari contoh-contoh ini adalah, mereka membuktikan satu hal: chip domestik, telah melompat dari "dapat digunakan untuk inferensi" ke "dapat digunakan untuk pelatihan". Ini adalah perubahan kualitatif. Inferensi hanya perlu menjalankan model yang sudah dilatih, persyaratan untuk chip relatif rendah; sedangkan pelatihan perlu memproses data dalam jumlah besar, melakukan perhitungan gradien kompleks dan pembaruan parameter, persyaratan untuk daya komputasi chip, bandwidth interkoneksi dan ekosistem perangkat lunak, lebih tinggi satu tingkat.
Kekuatan inti yang menangani tugas-tugas ini adalah seri chip Ascend Huawei. Hingga akhir 2025, jumlah pengembang ekosistem Ascend telah突破 4 juta, mitra lebih dari 3.000, 43 model besar utama industri menyelesaikan pra-pelatihan berdasarkan Ascend, lebih dari 200 model open source disesuaikan. Pada konferensi MWC 2 Maret 2026, Huawei juga meluncurkan dasar komputasi generasi baru SuperPoD untuk pasar luar negeri.
Daya komputasi FP16 Ascend 910B telah setara dengan NVIDIA A100. Meskipun kesenjangan masih ada, tetapi telah berubah dari tidak dapat digunakan menjadi dapat digunakan, dari dapat digunakan sedang menuju berguna. Pembangunan ekosistem, tidak bisa menunggu sampai chip sempurna baru mulai, harus dilakukan pada tahap yang cukup digunakan dengan skala besar, menggunakan kebutuhan bisnis nyata untuk memaksa iterasi chip dan perangkat lunak. Target impor server komputasi domestik oleh ByteDance, Tencent, Baidu, pada tahun 2026 umumnya meningkat dua kali lipat dibandingkan tahun sebelumnya. Data Kementerian Perindustrian dan Teknologi Informasi menunjukkan, skala komputasi cerdas China telah mencapai 1590 EFLOPS. Tahun 2026, sedang menjadi tahun pertama penyebaran skala komputasi domestik.
Kelangkaan Listrik AS dan Ekspor China
Awal 2026, negara bagian Virginia, yang menanggung lalu lintas pusat data global dalam jumlah besar, menunda persetujuan proyek pusat data baru. Negara bagian Georgia mengikuti, menunda persetujuan hingga 2027. Negara bagian Illinois, Michigan juga相继 memberlakukan langkah-langkah pembatasan.
Menurut data Badan Energi Internasional, pada tahun 2024 konsumsi listrik pusat data AS telah mencapai 183 TWh,约占 total konsumsi listrik nasional 4%. Pada tahun 2030, angka ini diperkirakan berlipat ganda menjadi 426 TWh, proporsi mungkin突破 12%. CEO perusahaan Arm bahkan memprediksi, pada tahun 2030, pusat data AI akan mengonsumsi 20% hingga 25% listrik AS.
Jaringan listrik AS sudah tidak mampu menanggung beban. Jaringan PJM yang mencakup 13 negara bagian timur AS menghadapi kekurangan kapasitas 6GW. Pada tahun 2033, AS secara keseluruhan menghadapi kekurangan kapasitas listrik 175GW, setara dengan konsumsi listrik 130 juta rumah tangga. Biaya listrik grosir di area konsentrasi pusat data, 267% lebih tinggi daripada lima tahun lalu.
Ujung dari komputasi adalah energi. Dan pada dimensi energi ini, kesenjangan antara China dan AS, bahkan lebih besar daripada chip, hanya saja arahnya terbalik.
Konsumsi listrik tahunan China adalah 10,4 triliun kWh, AS adalah 4,2 triliun kWh, China adalah 2,5 kali lipat AS. Yang lebih krusial adalah, konsumsi listrik kehidupan penduduk China hanya 15% dari total konsumsi listrik, sedangkan AS proporsinya adalah 36%. Ini berarti China memiliki sisa kapasitas listrik industri yang jauh lebih besar daripada AS yang dapat diinvestasikan dalam pembangunan komputasi.
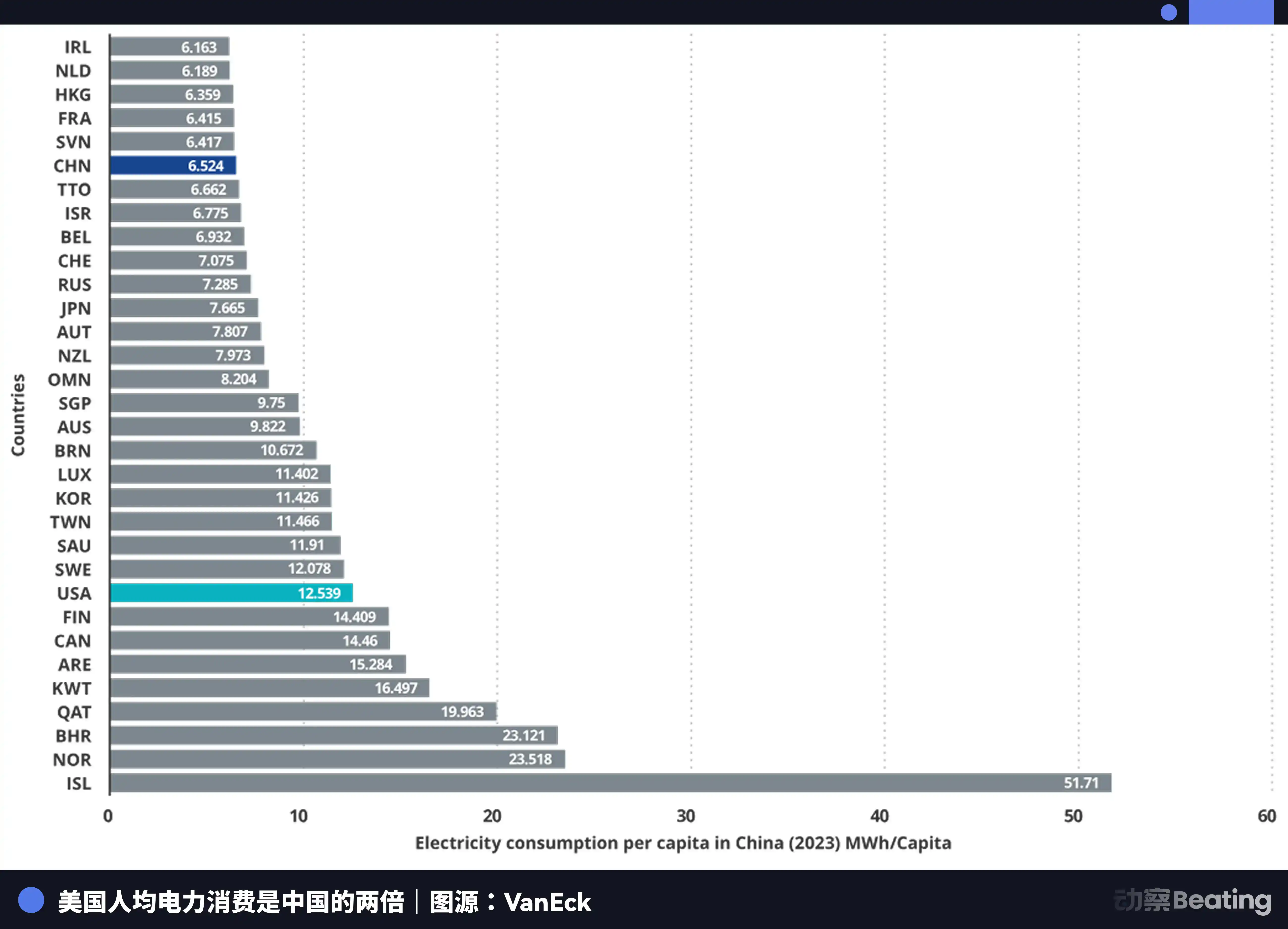
Dalam hal harga listrik, harga listrik di area berkumpulnya perusahaan AI adalah 0,12 hingga 0,15 dolar AS per kWh, sedangkan harga listrik industri di barat China sekitar 0,03 dolar AS, hanya seperempat hingga seperlima dari AS.
Peningkatan pembangkit listrik China, telah mencapai 7 kali lipat AS.
Ketika AS khawatir tentang listrik, AI China diam-diam melakukan ekspor. Tapi kali ini yang diekspor, bukan produk, bukan pabrik, tetapi Token.
Token, unit terkecil informasi yang diproses model AI, sedang menjadi komoditas digital baru. Itu diproduksi dari pabrik komputasi China, dikirim ke seluruh dunia melalui kabel laut.
Data distribusi pengguna DeepSeek sangat menjelaskan: China daratan 30,7%, India 13,6%, Indonesia 6,9%, AS 4,3%, Prancis 3,2%. Ini mendukung 37 bahasa, sangat populer di pasar berkembang seperti Brasil. Secara global, 26.000 perusahaan membuka akun, 3.200 lembaga menyebarkan versi perusahaan.
Pada tahun 2025, 58% perusahaan rintisan AI baru memasukkan DeepSeek ke dalam tumpukan teknologi. Di China, DeepSeek merebut 89% pangsa pasar. Dan di negara-negara lain yang terkena sanksi, pangsa pasar antara 40%~60%.
Pemandangan ini, sangat mirip dengan perang lain tentang hak otonomi industri empat puluh tahun yang lalu.
Pada tahun 1986 di Tokyo, di bawah tekanan kuat AS, pemerintah Jepang menandatangani Perjanjian Semikonduktor AS-Jepang. Klausul inti perjanjian ada tiga: meminta Jepang membuka pasar semikonduktor, pangsa pasar chip AS di Jepang harus mencapai lebih dari 20%; melarang semikonduktor Jepang diekspor dengan harga di bawah biaya; mengenakan tarif hukuman 100% untuk chip ekspor Jepang senilai 3 miliar dolar AS. Pada saat yang sama, AS memveto akuisisi Fairchild Semiconductor oleh Fujitsu.
Tahun itu, industri semikonduktor Jepang sedang berada di puncak. Pada tahun 1988, Jepang mengontrol 51% pangsa pasar semikonduktor global, AS hanya 36,8%. Sepuluh perusahaan semikonduktor terbesar global, Jepang menduduki enam: NEC peringkat kedua, Toshiba ketiga, Hitachi kelima, Fujitsu ketujuh, Mitsubishi kedelapan, Panasonic kesembilan. Pada tahun 1985, Intel dalam perebutan semikonduktor AS-Jepang rugi 173 juta dolar AS, hampir bangkrut.
Tapi setelah perjanjian ditandatangani, semuanya berubah.
AS melalui penyelidikan 301 dan cara lainnya, melancarkan penindasan menyeluruh terhadap perusahaan semikonduktor Jepang. Pada saat yang sama mendukung Samsung Korea, Hynix, dengan harga lebih rendah untuk menyerang pasar Jepang. Pangsa DRAM Jepang turun dari 80% menjadi 10%. Hingga tahun 2017, pangsa pasar IC Jepang hanya tersisa 7%. Raksasa yang pernah sangat perkasa, dipecah, diakuisisi, atau meninggalkan panggung dengan suram dalam kerugian tanpa henti.
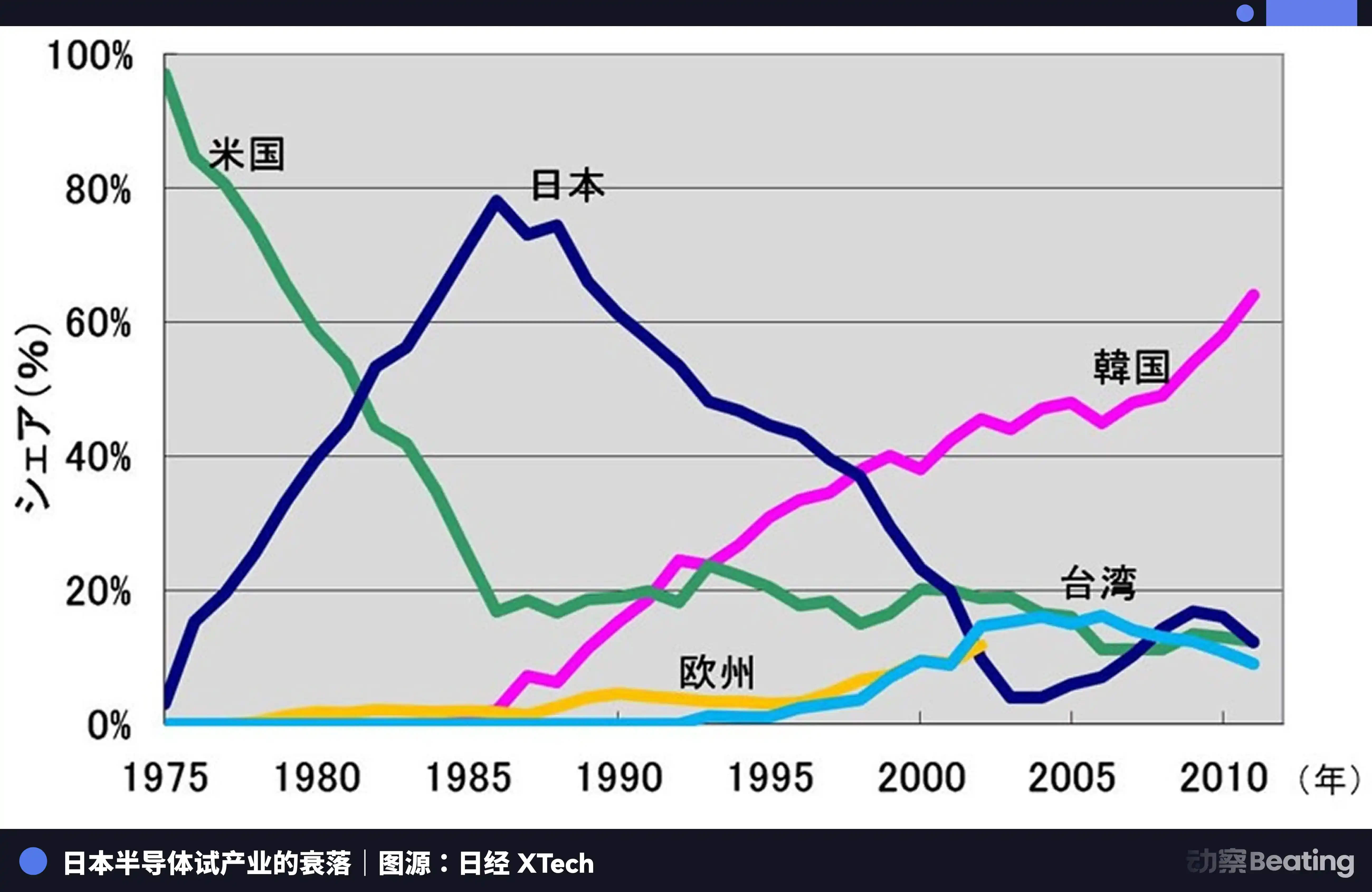
Tragedi semikonduktor Jepang adalah, mereka puas menjadi produsen terbaik dalam sistem pembagian kerja global yang dipimpin oleh kekuatan eksternal tunggal, tetapi tidak pernah berpikir untuk membangun ekosistem mandiri milik mereka sendiri. Ketika air surut, mereka baru menyadari, selain produksi itu sendiri, mereka tidak memiliki apa-apa.
Industri AI China hari ini, berdiri di persimpangan yang mirip tetapi sangat berbeda.
Yang mirip adalah, kita juga menghadapi tekanan besar dari luar. Tiga putaran pengendalian chip, berlapis-lapis, hambatan ekosistem CUDA masih tinggi.
Yang berbeda adalah, kali ini, kita memilih jalan yang lebih sulit. Dari optimasi algoritma yang maksimal, hingga lompatan chip domestik dari inferensi ke pelatihan, hingga akumulasi 4 juta pengembang Ascend, hingga penetrasi Token ke pasar global. Setiap langkah di jalan ini, membangun ekosistem industri mandiri yang tidak pernah dimiliki Jepang saat itu.
Penutup
Pada 27 Februari 2026, tiga laporan kinerja dari perusahaan chip AI domestik, dirilis pada hari yang sama.
Cambricon, pendapatan melonjak 453%, untuk pertama kalinya mencapai laba tahunan. Moore Thread, pendapatan tumbuh 243%, tetapi rugi bersih 1 miliar yuan. MetaX, pendapatan tumbuh 121%, rugi bersih hampir 800 juta yuan.
Setengah adalah api, setengah adalah air.
Api, adalah kelaparan pasar yang sangat. 95% kekosongan yang ditinggalkan Jensen Huang, sedang diisi oleh angka pendapatan perusahaan-perusahaan lokal ini, seinci demi seinci. Tidak peduli kinerjanya如何, tidak peduli ekosistemnya怎样, pasar membutuhkan pilihan kedua selain NVIDIA. Ini adalah peluang struktural langka yang dibuka oleh geopolitik.
Air, adalah biaya besar pembangunan ekosistem. Setiap kerugian, adalah uang sungguhan yang dibayar untuk mengejar ekosistem CUDA. Adalah investasi penelitian dan pengembangan, adalah subsidi perangkat lunak, adalah biaya tenaga kerja insinyur yang ditempatkan di lokasi pelanggan, menyelesaikan masalah kompilasi satu per satu. Kerugian ini, bukan operasi yang buruk, tetapi pajak perang yang harus dibayar untuk membangun ekosistem mandiri.
Tiga laporan keuangan ini, lebih jujur mencatat wajah sebenarnya perang komputasi ini daripada laporan industri mana pun. Ini bukan kemenangan yang maju dengan sorak-sorai, tetapi pertempuran posisi yang sengit, menyerang sambil berdarah.
Tapi bentuk perang, memang telah berubah. Delapan tahun lalu, kita membahas masalah "apakah bisa bertahan hidup". Hari ini, kita membahas masalah "berapa besar biaya untuk bertahan hidup".
Biaya itu sendiri, adalah kemajuan.







