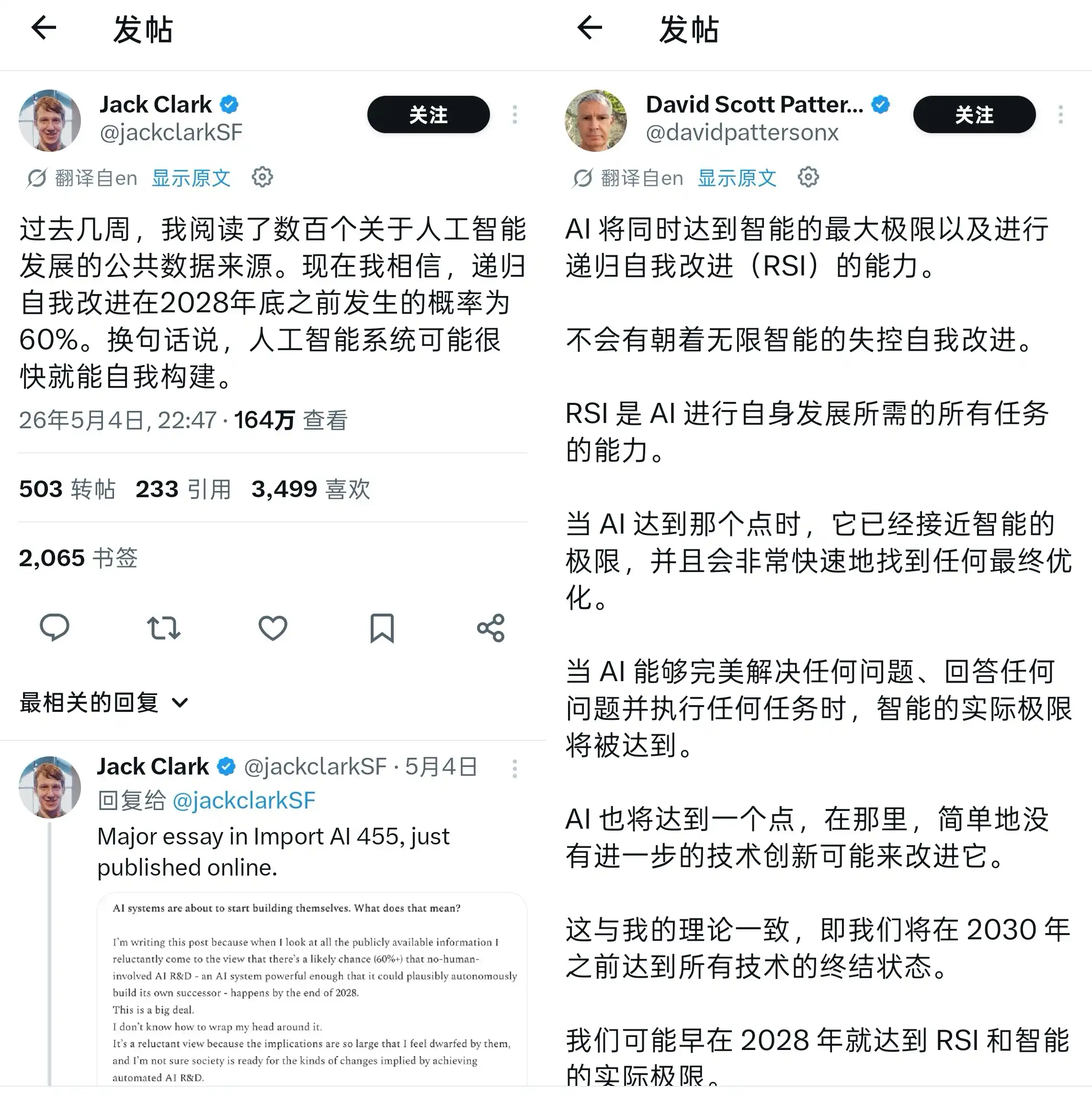
"Recursion" has recently become a hot topic in the AI community.
Two startups have directly used this term as their company names, and many labs have started inserting the three-letter acronym RSI—which stands for Recursive Self-Improvement—into their roadmaps. Much like AGI, RSI is becoming an exciting yet unsettling industry buzzword, even though a unified definition hasn't been fully established.
(Image source: X)
What is RSI? Simply put, it's about enabling AI to train itself. In the tech world, RSI has long been regarded as a major indicator of artificial intelligence progress, alongside memory, reasoning, and multimodality. The only limitation is computing power; humans are no longer a necessary condition, not even as assistants.
Sounds like science fiction, or perhaps, sounds dangerous? But upon calm reflection, this isn't the first wave of fervor in the AI industry. From AlphaGo in 2016 to ChatGPT in 2023, and now the parameter arms race among major models, the industry's nature is to chase the next "game-changer." In the view of Leike Technology AGI, RSI might be the next carnival.
RSI Gains Traction: When AI Can "Recursively" Construct Itself
In May of this year, renowned AI researcher Richard Socher high-profile founded a new company called Recursive Superintelligence, its name directly referencing RSI.
He stated: "Our core goal is to build a truly recursive self-improving superintelligence. The entire process of research conception, implementation, and validation will be automated."
Another case that has garnered more buzz within the circle is a project called Auto-Research advanced by Andrej Karpathy: using agent clusters to train language models, enabling models to perform simple research tasks and improve themselves autonomously.
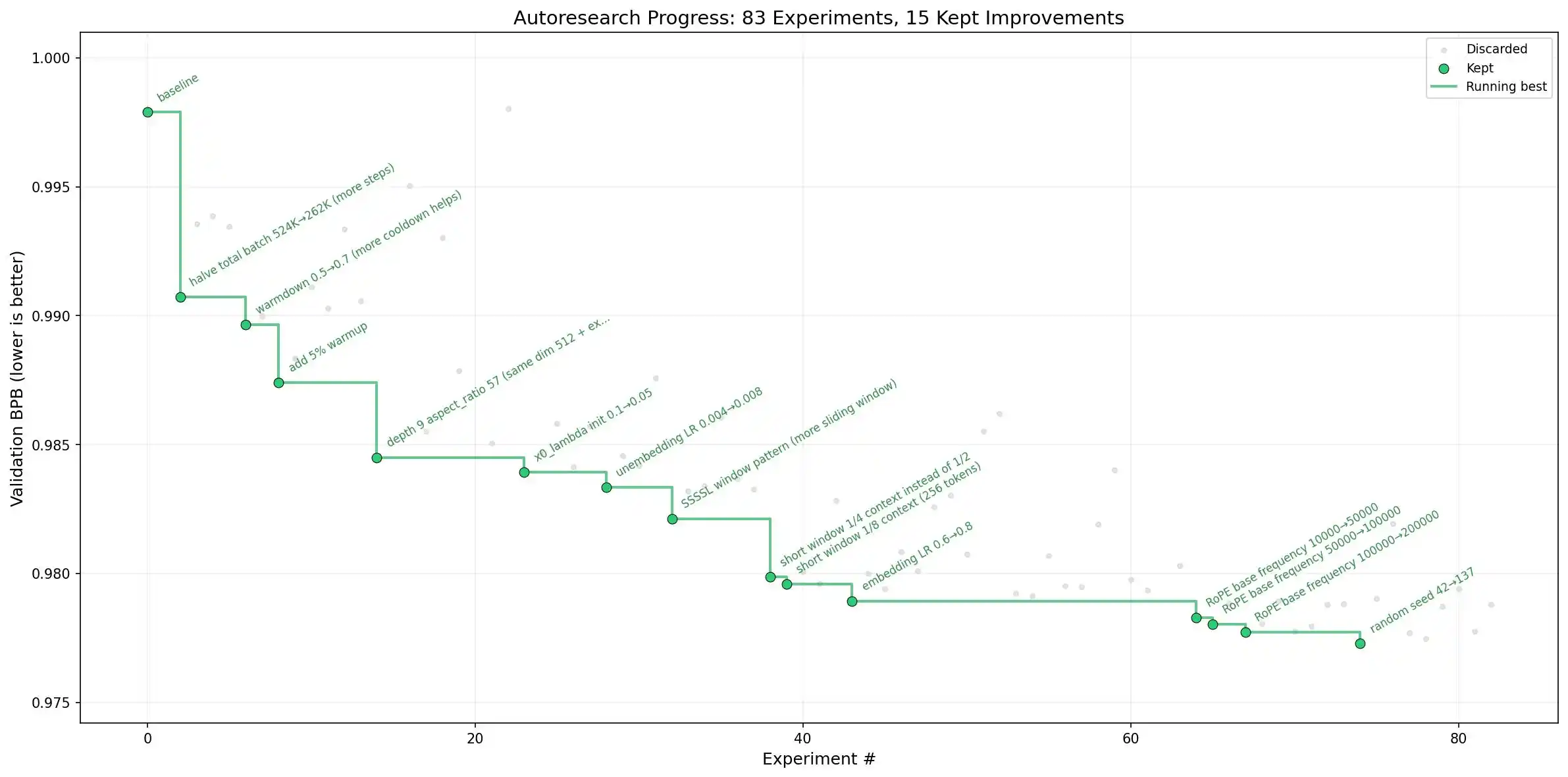
Image source: github
Andrej Karpathy is also a legendary figure, having left significant contributions at Tesla in autonomous driving and at OpenAI on GPT. Now he's all-in on RSI as his next stop, and he's advancing it with remarkable transparency, indicating he genuinely believes it's achievable.
Interestingly, he has been unusually candid about this project, regularly updating progress on Twitter and maintaining a public GitHub repository for the code. Of course, Andrej Karpathy himself has noted that current work is still iterating on small models at the GPT-2 level, "not yet breakthrough research (for now)," but this is enough to drive a large number of researchers to follow suit.
More importantly, Andrej Karpathy recently joined Anthropic's pretraining team. Anthropic has Claude, Karpathy has the auto-research methodology; combining the two, large model + self-training loop, if proven successful, would move beyond the small-scale experiments of GPT-2.

Image source: haimagazine
Another company called Adaption launched a tool called AutoScientist, aiming to automate the training process of frontier models. The logic aligns with Andrej Karpathy's auto-researchers: training agents for incremental improvement. However, Adaption's ambition is greater, seeking to directly establish a complete training loop for a full-scale frontier model.
These two represent two different approaches: Andrej Karpathy is verifying from the ground up piece by piece, building momentum within the community while open-sourcing; Adaption is directly targeting commercial large-model training scenarios with a stronger drive for practical application. Whichever path succeeds first will have distinctly different impacts on the entire industry.
Google CEO Pours Cold Water: We're Not There Yet
Regarding RSI, opinions among AI industry leaders vary widely.
Last month, in a podcast, Google CEO Sundar Pichai acknowledged reality with quite cautious wording: "(RSI) is a continuum. We are indeed all making progress. But if we talk about RSI in the way people describe it, that represents the next level of acceleration, with many implications, but we're not at that stage yet."
Even so, the term "continuum" here contains much food for thought.
In January this year, a programmer leading Claude Code development at Anthropic admitted that nearly 100% of the team's code was written by Claude Code, which is AI literally writing itself. It's not AI assisting engineers in writing code; it's an AI tool, to some extent, already replacing engineers in writing its own code.
Image source: Anthropic
Anthropic conducted an internal survey about the Mythos preview version: among 18 engineers, five believed that if the supporting systems were improved, this version of Mythos could replace an L4 engineer—a mid-level programmer capable of independently handling complex projects without real-time supervision.
However, the weaknesses were also clearly stated: "The main weaknesses reported by Claude include: fuzzy tasks beyond one management cycle, understanding organizational priorities, taste, verification, instruction following, and epistemology." In other words, its weaknesses lie precisely in the aspects of self-motivation, which is the foundation of RSI.
Interestingly, the Georgetown Center for Security and Emerging Technology (CSET) last year assembled a group of experts specifically to study RSI. These experts exhibited a clear split in their assessments. Some anticipated an imminent "superintelligence explosion," while others expected slower progress that would eventually reach a plateau.
But they shared one consensus: recursion makes the future exceptionally difficult to predict.
To this end, an article by METR researcher Ajeya Cotra breaks down the RSI process into several milestones. I find this to be the most useful analytical framework currently available.
The first level is called "Adequacy": After completely removing humans, the system can still conduct research—even if inferior to humans, it can function.
The second level is called "Parity": Research conducted independently by AI matches the quality of research conducted independently by humans.
The third is called "Supremacy": The performance of an independent AI system surpasses that of a human-AI collaborative system.
It's somewhat akin to L2, 3, 4, 5 in autonomous driving. Ajeya Cotra's assessment is: we are already very close to the first level. But when the second level will arrive, she didn't provide a timeline. However, she offered a clear deduction: once the second level arrives, subsequent acceleration will far exceed past rates, "potentially reaching the third level within a year."
Why so fast? Because at the moment the second level is achieved, AI becomes a research team that doesn't need sleep, meetings, or KPI alignment. It can experiment, modify, and re-experiment 24/7. Humans conducting research, no matter how efficient, only have a few hours of effective deep work per day, interspersed with countless interruptions and communication overhead. Once this bottleneck disappears, the acceleration is cliff-like.
No One in China is Shouting RSI, But DeepSeek and Others Have Already Touched the Edges
After discussing overseas progress, you might wonder: what about China?
Frankly, domestic companies rarely publicly shout about RSI. Overseas AI companies can write "recursive superintelligence" into their mission statements; such a thing is almost unimaginable in China. But when it comes to having AI improve itself, domestic players have already quietly approached the edges on different paths.
The most typical example is DeepSeek. They spend an order of magnitude less money than OpenAI, yet can compete head-on in many reasoning tasks. This is achieved through extreme optimization of algorithmic efficiency—MoE architecture, extreme compression of activation parameters, and engineering refinement of training strategies.
Although this isn't directly related to RSI, it represents a path of using smarter methods to replace brute-force computational power. And this path is precisely one of the core logics of RSI: enabling models to find smarter paths through iteration.
On the Baidu Wenxin side, reinforcement learning-driven model self-optimization has become routine. Although they don't use the RSI label, they are doing the same thing: allowing models to continuously improve through self-feedback loops on specific tasks. From this perspective, domestic companies are not ignoring RSI; they have already incorporated certain aspects of RSI into daily engineering practice, just without the label.

(Image source: gemini generation)
Of course, objective gaps exist. The talent density at OpenAI and Anthropic is still unmatched by any domestic company, meaning that in the exploration of RSI, the current status is still one of following.
But historical experience shows that domestic companies often exhibit astonishing speed in catching up once "the path is clearly defined." The RSI framework is being increasingly dissected by overseas experts, and Karpathy's code is publicly available on GitHub. Once a reproducible path is established, the cost control capabilities and application scenario density of domestic players will become a variable severely underestimated by the market.
Simultaneously, we must also pour some appropriate cold water. In reality, data generated by AI used to train the next version of AI tends to degrade in quality. The logic of RSI is that AI generates good data, which is then used to train the next generation of AI, making it stronger.
But the actual situation might be reversed. AI-generated data often mixes in its own hallucinations, biases, and quality degradation. These second-hand data are fed to the next version, which then produces even worse third-hand output. After a few cycles, the entire system collapses, akin to a photocopier repeatedly copying copies; by the tenth copy, the image is blurred beyond recognition.
Academia refers to this as model collapse, and papers have already verified this phenomenon's existence.
Furthermore, the ideal environment required for RSI doesn't exist in the real world. For this system to function, two prerequisites are indispensable: infinite computing power and a globally open, collaborative research ecosystem.
The reality is that the cost of training a frontier model has reached the billion-dollar scale. Chip capacity is limited, energy is limited, high-quality data is diminishing, and export controls and technological decoupling are fragmenting AI research into several non-interconnected circles. When people and goods can't flow freely, and these basic conditions can't be met, talking about RSI is premature.
RSI is no longer just a technical problem; it requires a sufficiently open world. Whether this prerequisite can be established is beyond the control of the tech community.
In Conclusion
Finally, here's an interesting observation I've made: Over the past five years, the industry first lured people into "parameter worship" through large-scale pretraining, then convinced them that "values can be fine-tuned" with RLHF, and now RSI tells a story of "machines completing the entire R&D chain autonomously." Each step pushes humans one step back—not out of the industry, but out of the decision-making chain.
Although this retreat isn't necessarily a bad thing, it is irreversible. Once a certain link is automated, human intuition, experience, and judgment in that link gradually deteriorate, much like how navigation ability declines when you stop using GPS.
By then, we might not even truly understand how the tools we use are made.






