Un import d'une ligne, le fine-tuning de grands modèles MoE est accéléré de 3,7 fois.
Les derniers travaux de recherche de NVIDIA sont désormais open source : NeMo AutoModel, conçu spécifiquement pour la construction et le fine-tuning à grande échelle de modèles d'IA générative.
Construit sur la base de Hugging Face Transformers v5, NeMo AutoModel permet, sans modifier le code API, simplement en ajoutant une ligne d'import, de réaliser un fine-tuning plus rapide pour les modèles MoE.

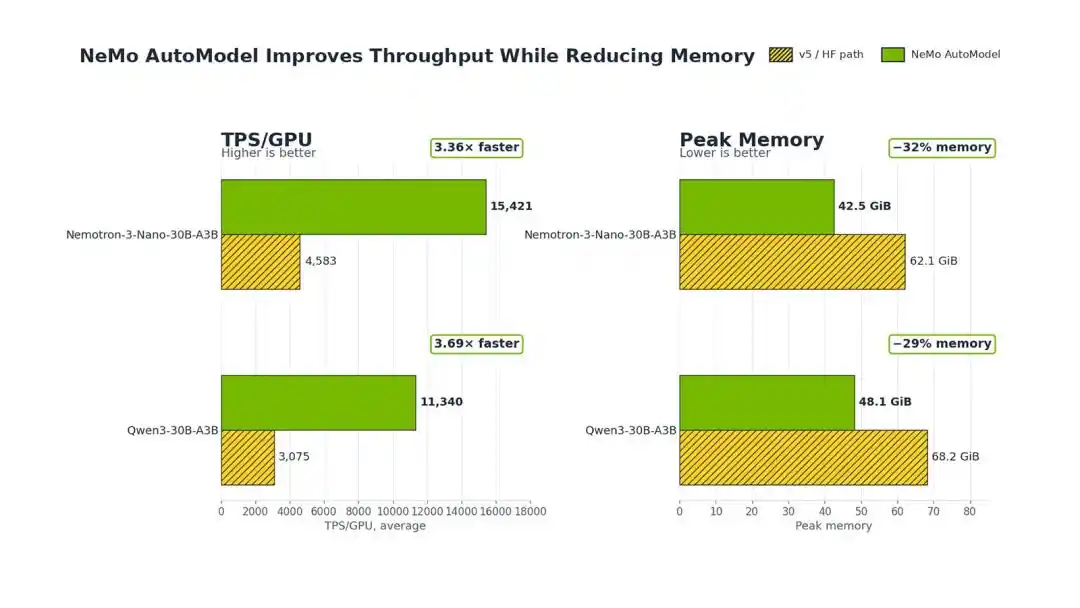
Les expériences montrent que, par rapport à la version originale de Transformers v5 de Hugging Face, NeMo AutoModel de NVIDIA permet de réaliser un gain de débit de formation de 3,4 à 3,7 fois lors du fine-tuning MoE, et réduit de 29% à 32% l'utilisation de mémoire GPU.
Sur un seul nœud avec 8 GPU H100 80GB, prenant l'exemple de Qwen3-30B-A3B, NeMo AutoModel augmente directement le TPS/GPU (débit par seconde par GPU) de 3075 à 11340, soit une amélioration de 3,69 fois.
Analyse de la technologie clé
MoE est devenu l'architecture dominante des modèles de pointe actuels, mais MoE apporte également de nouveaux défis pour un entraînement efficace :
Parallélisme d'experts, fusion des communications, optimisation des kernels... Ces travaux d'ingénierie complexes nécessitent des infrastructures de support adaptées.
Transformers v5 de HuggingFace est actuellement la "base générique" de formation MoE la plus utilisée. La v5 améliore la prise en charge native de MoE, introduisant des capacités fondamentales comme les *expert backends*, le *dynamic weight loading* et l'exécution distribuée pour MoE.

Cette fois, l'approche de NVIDIA est de se placer sur les épaules de ses prédécesseurs, en restant compatible avec l'API de HuggingFace Transformers, permettant aux utilisateurs d'obtenir un débit de formation plus élevé et une consommation mémoire plus faible lors du fine-tuning MoE sans modifier largement leur code.
Plus précisément, NeMo AutoModel ajoute à Transformers v5 : Expert Parallelism (EP), DeepEP et TransformerEngine.
Expert Parallelism (Parallélisme d'Experts)
La technologie de parallélisme d'experts sert principalement à réduire la pression mémoire.
EP répartit les poids des experts sur plusieurs GPU, chaque GPU ne détenant plus la totalité des paramètres de tous les experts, mais seulement une partie.
Par exemple, sur 8 GPU avec ep_size=8, les poids des experts sont répartis sur les 8 GPU, l'empreinte mémoire MoE par GPU peut être réduite à 1/8 de l'original.
D'après les résultats expérimentaux, pour Qwen3, cette technologie peut réduire la mémoire maximale de 68,2 GiB à 48,1 GiB, soit une baisse de 29%.
Pour le modèle Nemotron Nanomo, l'utilisation mémoire passe de 62,1 GiB à 42,5 GiB, une baisse de 32%.
L'espace libéré peut être utilisé pour supporter des lots plus grands ou des séquences plus longues.
DeepEP
DeepEP réalise la fusion des calculs et des communications.
Dans l'approche traditionnelle, il y a un coût de communication significatif entre la distribution des tokens et le calcul des experts. DeepEP intègre les opérations de distribution et de combinaison des tokens dans des kernels GPU optimisés, permettant le chevauchement du processus de communication et du calcul des experts.
TransformerEngine
Le kernel TransformerEngine fournit une accélération pour divers calculs de base.
Cette technologie offre des implémentations fusionnées pour les mécanismes d'attention, les couches linéaires et RMSNorm, etc., accélérant non seulement la couche MoE mais aussi les couches Transformer ordinaires.
Un import d'une ligne, une amélioration de vitesse par 3
En résumé, pour ceux qui utilisent déjà Transformers v5, NeMo AutoModel de NVIDIA propose une solution de mise à niveau sans douleur :
Il suffit d'ajouter une ligne de code d'import pour obtenir une amélioration de vitesse de fine-tuning MoE par un facteur de 3.

Sur Qwen3-30B-A3B et Nemotron 3 Nano 30B-A3B, comparé à Transformers v5, cette solution permet d'atteindre une amélioration du débit de formation de 3,4 à 3,7 fois, tout en réduisant la consommation mémoire de 29% à 32%.
NVIDIA a également présenté les résultats du fine-tuning complet des paramètres pour Nemotron 3 Ultra 550B A55B sur 16 nœuds H100, soit 128 GPU.
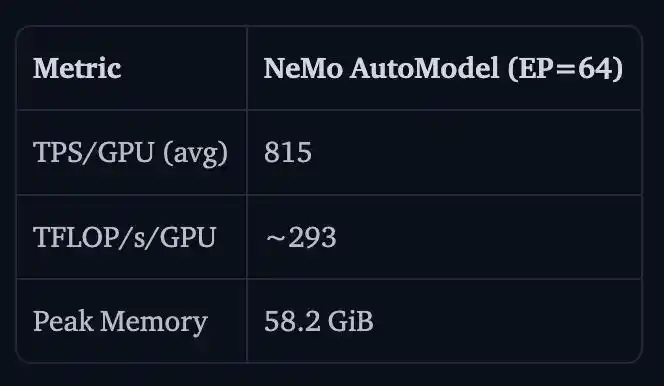
Le TPS/GPU était de 815, le TFLOP/s/GPU environ 293, et la mémoire maximale de 58,2 GiB.
La raison pour laquelle il n'y a pas de comparaison avec la v5 ici est que Transformers v5 saturerait directement la mémoire à cette échelle ̄_(ツ)_/ ̄
Si vous êtes intéressés, NVIDIA a mis le code, les configurations et les scripts de benchmark sur GitHub : https://github.com/NVIDIA-NeMo/Automodel/tree/blog/transformers-v5-automodel/blog_experiments
Le guide d'utilisation détaillé se trouve ici : https://docs.nvidia.com/nemo/automodel/latest/get-started/hf-compatibility
Cet article provient du compte WeChat officiel "Quantum Bit", auteur : Yu Yang






