Ces deux dernières années, les modèles de génération vidéo ont évolué à une vitesse fulgurante. De l'effet saisissant de Sora fin 2024 aux lancements multiples de modèles comme Google Veo, Sora 2, les modèles de la série Kling et, début cette année, Seedance 2.0, la qualité des vidéos générées par IA a fait un bond qualitatif, permettant de produire des séquences de plusieurs minutes, avec plusieurs personnages et des scènes complexes, d'un réalisme cinématographique.
Face à cette évolution rapide du côté génération, l'intérêt du monde de la recherche pour la détection de vidéos IA reste pourtant modéré.
Pourtant, dans la réalité, nous pouvons facilement observer l'impact sociétal majeur dû au pouvoir trompeur accru de la vidéo, lié à sa nature multimodale :
Sur les diverses plateformes sociales, les vidéos fausses générées par IA se multiplient, augmentant en nombre, en qualité et en portée. Lorsque des utilisateurs interrogent des modèles de base comme Grok ou Doubao pour savoir si une « vidéo est générée par IA », les réponses sont souvent de simples jugements binaires, manquant d'explicabilité et de crédibilité. Sur des plateformes comme Xiaohongshu, des vidéos filmées en conditions réelles sont fréquemment étiquetées comme « suspectées d'être générées par IA ».
Un fossé immense se creuse entre les progrès rapides de la génération et le manque d'attention portée à la détection. Il est urgent de se demander : à l'ère de l'évolution rapide de la génération vidéo IA, où en est la recherche sur la détection, quel changement de paradigme est en cours, et vers quelles directions doit-elle se tourner à l'avenir.
C'est dans ce contexte que des chercheurs du MBZUAI, de l'Université Renmin de Chine et de l'Université Harvard ont co-écrit et publié une revue de cinquante pages. Pour la première fois, ils organisent les approches techniques selon deux axes, visuel et linguistique, allant de la perception visuelle de bas niveau au raisonnement de haut niveau sur le monde. Sur cette base, ils analysent le besoin pressant d'un système de détection fiable, dynamique, traçable et explicable, couplant des preuves à plusieurs niveaux. Cette revue a été acceptée à ACL 2026.

Lien de l'article : https://www.researchgate.net/doi/10.13140/RG.2.2.31713.88168
Lien GitHub : https://github.com/dxhou/AI-Generated-Video-Detection
Lien de la page d'accueil : https://AIgcvdetection.github.io
Redéfinir l'objectif de la détection de vidéos générées par IA
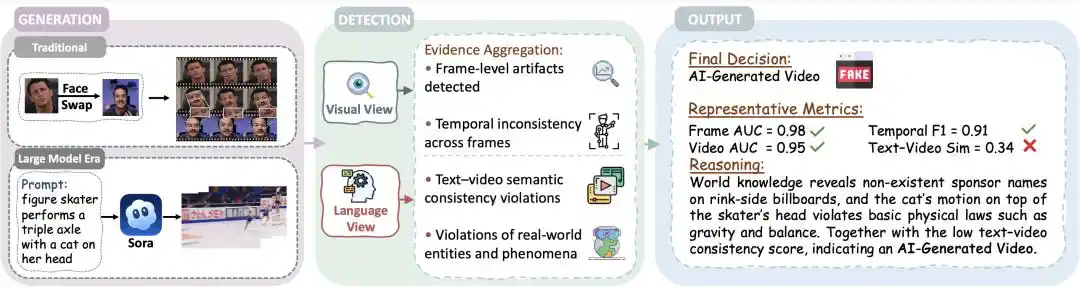
Figure 1 | Processus complet de détection de vidéos générées par IA : du côté génération, détection à double perspective, jusqu'à l'ensemble de preuves
Avant l'essor de l'IA générative, les vidéos générées par IA laissaient des artefacts visuels relativement évidents. Sur cette base, dans les premiers scénarios de Deepfake comme le remplacement de visage, une vérification visuelle au niveau de l'image était suffisamment efficace.
Ces deux dernières années, la qualité vidéo de l'ère de l'IA générative en rapide évolution a dépassé cette « base ». Il est de plus en plus difficile pour l'œil humain de juger de l'authenticité d'une vidéo complète et réaliste. Dans ce contexte, une détection qui ne fournit qu'un jugement binaire ne suffit plus. Il est urgent de répondre à la question : sur quelles preuves un détecteur s'appuie-t-il pour justifier un jugement crédible.
Cette revue repousse d'abord les limites du problème de détection : elle souligne que la sortie de la détection doit passer d'une « classification binaire vrai/faux » à un jugement structuré, explicable et crédible, faisant ainsi évoluer l'objet de la détection vers la vérification de l'écart entre le « monde virtuel » et le « monde réel » dans la vidéo.
Par conséquent, la revue redéfinit d'abord l'objectif de détection, le reformulant comme une « vérification de la fidélité aux faits », c'est-à-dire vérifier si le contenu de la vidéo concernant des propositions comme « qui, quand, où, que s'est-il passé » est à la fois cohérent sur le plan perceptif et cognitif avec le monde réel. Au-delà de la vérification visuelle et intermodale, il faut aller plus loin pour juger si le contenu de la vidéo est en conflit avec des éléments externes comme « les faits, les lois physiques, les connaissances du monde, etc. ».
L'objet de détection : les trois paradigmes des vidéos générées par IA

Figure 2 | Les trois paradigmes de vidéos générées par IA définis dans cette revue
De 2020 à aujourd'hui, la génération vidéo IA a connu une migration de paradigme : des premières modifications locales via GAN à l'époque du Deepfake, au réassemblage audio-visuel comme le changement de synchronisation labiale ou de voix, jusqu'à la synthèse complète de vidéos IA rendue possible par les modèles de diffusion dans l'espace latent, de type « simulateurs de monde » comme Sora. La revue classe les vidéos générées par IA selon les trois paradigmes suivants :
Vidéos à manipulation locale conservant un support réel (Local Manipulation Video, LMV)
Le LMV a longtemps été le paradigme le plus typique et le plus mature de la détection traditionnelle du Deepfake. La vidéo elle-même modifie une région locale d'une vidéo filmée en conditions réelles, comme un changement de visage ou d'arrière-plan ; la plupart des structures de la vidéo originale, comme la scène, les actions des personnages, les mouvements de caméra, les relations d'éclairage, sont généralement conservées. Ainsi, la grande majorité des premières méthodes se concentraient justement sur les artefacts locaux, les caractéristiques fréquentielles, les anomalies géométriques et la cohérence régionale. Mais les modèles de génération deviennent de plus en plus performants dans la fusion locale, l'adaptation à l'éclairage et la migration d'identité ; le traitement par les plateformes et la diffusion secondaire effacent de nombreuses petites traces. L'accent de la détection du paradigme LMV se déplace progressivement vers la robustesse des méthodes dans différents scénarios.
Édition audio-visuelle sous contraintes de couplage intermodal (Audio-Visual Editing, AVE)
Le paradigme AVE a principalement émergé en 2024. Dans ces vidéos générées par IA, ce sont les relations établies entre la vidéo elle-même et le son, la synchronisation labiale, l'identité du locuteur, le rythme de parole, le contenu des sous-titres, etc., qui sont modifiées. Cela inclut la synthèse de visages pilotée par la voix, le re-doublage d'une vidéo originale, le changement de synchronisation labiale, le remplacement de locuteur. Cela oblige la détection à passer de la recherche d'artefacts visuels à l'examen de la validité des relations entre les différents modes à l'intérieur de la vidéo, en considérant ensemble le son, les lèvres, l'identité et le contenu pour trouver des indices réellement discriminants.
Synthèse vidéo générative de bout en bout (Generative Video Synthesis, GVS)
Le paradigme GVS, qui a explosé en 2025, voit le modèle générer directement la séquence vidéo entière à partir d'informations conditionnelles comme le texte, l'image, le bruit, etc., sans s'appuyer sur une vidéo réelle comme base. Cela apporte un tout nouveau défi à la détection.
Ces vidéos paraissent souvent très réalistes sur une image unique ou sur une courte durée, mais peuvent présenter des failles sur de longues séquences spatio-temporelles : par exemple, les actions d'un personnage ou sa position dans la scène ne s'enchaînent pas logiquement, la forme ou le mouvement d'un objet change de manière non conforme aux lois physiques, ou l'événement lui-même présenté dans la vidéo ne pourrait pas exister dans le monde réel.
En conséquence, l'approche de détection du paradigme GVS ne peut se limiter à la cohérence locale ou intermodale. Elle doit s'élever vers des niveaux supérieurs, en partant de la cohérence à long terme, du bon sens, des lois physiques, de la narration, de la causalité, de la véracité au niveau des propositions et de la traçabilité, pour vérifier, sur de longues séquences, si le contenu lui-même est crédible, et si le contenu de la vidéo peut être considéré comme valide à tous les niveaux dans le monde réel.
La généalogie des méthodes de détection en quatre couches selon la double perspective visuelle-linguistique
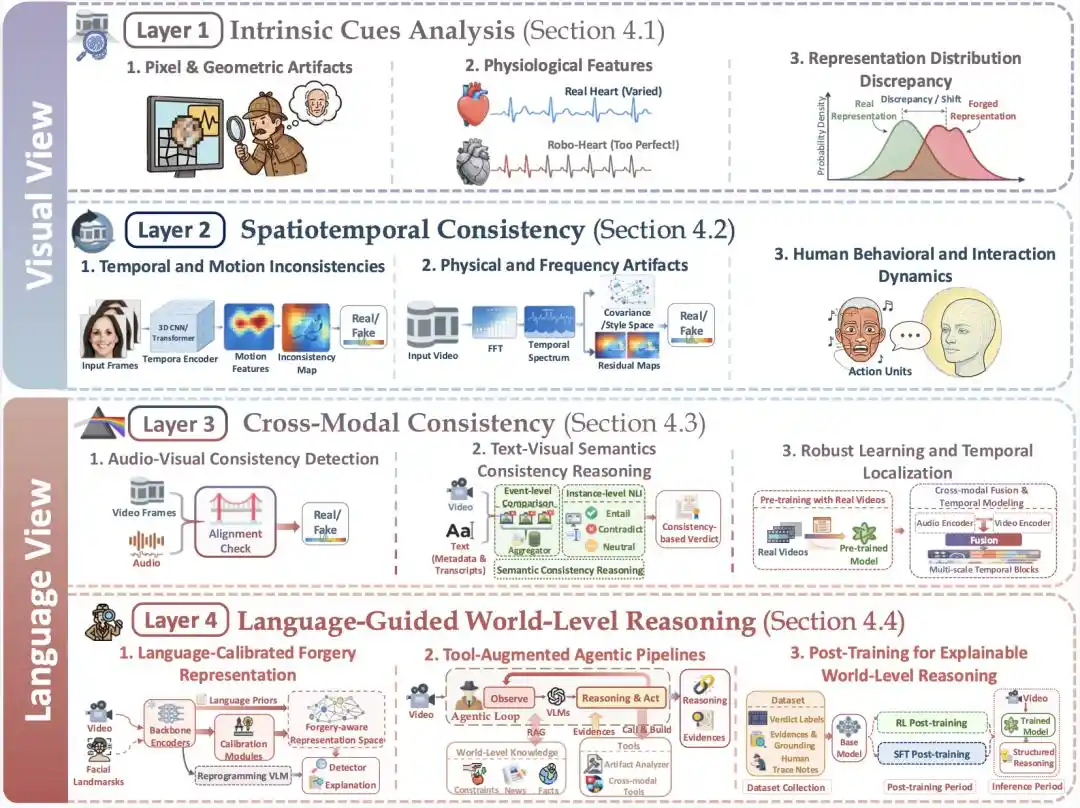
Figure 3 | Cadre à quatre couches Vision-Langue Double Perspective : les deux premières couches sont plutôt du point de vue visuel, les deux dernières évoluent vers le point de vue linguistique
Actuellement, les perspectives modales pour la détection de vidéos générées par IA se sont différenciées en deux grandes questions scientifiques fondamentales. La première part de la modalité visuelle, en se concentrant sur l'analyse des signaux de bas niveau et la cohérence spatio-temporelle de l'image.
L'autre part de la modalité linguistique, s'intéressant notamment aux informations linguistiques intermodales de la vidéo elle-même, pour juger si « la vidéo raconte bien une histoire avec un bon alignement intermodal » ; et en utilisant la modalité linguistique pour introduire des raisonnements liés aux connaissances et aux faits sur le monde, pour juger si « le contenu de la vidéo peut résister à l'épreuve des connaissances, des faits, des lois, etc., du monde réel externe ».
La revue saisit cette tendance de transformation et propose d'organiser les méthodes de recherche et les paradigmes d'évaluation de la détection de vidéos générées par IA à partir d'une double perspective visuelle-linguistique. Sur cette base, elle propose ensuite le panorama suivant de méthodes en quatre couches, allant de la perception de bas niveau à la cognition de haut niveau.
Cela comprend les quatre couches suivantes :
Couche 1, indices visuels de bas niveau (Intrinsic Cues Analysis) : le premier tamis
Les méthodes de la couche 1 s'intéressent à la question de recherche : au niveau des signaux visuels de bas niveau, la vidéo respecte-t-elle les lois statistiques que doivent suivre les vidéos réelles, et présente-t-elle des indices de bas niveau introduits par le modèle d'IA génératif ou par les opérations d'édition.
Au niveau des signaux de bas niveau, les vidéos réelles présentent des propriétés statistiques correspondantes, et les vidéos résultant d'une acquisition et d'un traitement réels correspondent naturellement aux processus d'acquisition, de codage et de post-traitement ; tandis que le processus de génération par IA laisse souvent des traces s'écartant de la distribution des vidéos réelles, comme un style uniforme, des filigranes ou artefacts spécifiques au modèle, des signaux physiologiques artificiels détectables, etc. Les méthodes de cette première couche, du point de vue visuel, effectuent une analyse médico-légale en modélisant, en extrayant et en amplifiant ces signaux de bas niveau. Cela inclut la détection :
des anomalies de pixels et géométriques (fréquences, textures, contours, motifs de bruit, etc.) ;
des signaux physiologiques sur le visage (couplage du pouls, micro-mouvements musculaires, rythme des clignements, etc.) ;
de l'existence d'un décalage systématique dans l'espace des caractéristiques entre les vidéos réelles et les vidéos falsifiées.
Couche 2, cohérence spatio-temporelle (Spatiotemporal Consistency) : vérifier si « une vidéo est fluide »
Les méthodes de la couche 2 ciblent le concept de « séquence de combinaisons d'images dans le temps et l'espace ». Elles s'intéressent à la question de recherche : dans les dimensions spatiale et temporelle, le flux d'images de la vidéo présente-t-il les caractéristiques que doivent respecter les processus de mouvement des objets dans une vidéo réelle ? Les vidéos filmées en conditions réelles sont contraintes par une trajectoire continue de la caméra et un environnement scénique réel ; les changements spatio-temporels entre images adjacentes, pour le sujet principal et l'arrière-plan, suivent un mode continu et prévisible conforme à la faisabilité physique et au mouvement de la caméra. Les vidéos générées par IA peuvent présenter, sur de longues séquences temporelles, des discontinuités spatio-temporelles comme des distorsions d'objets locaux, des dérives d'arrière-plan, des flous soudains localisés, des anomalies de résidus de mouvement. Cela inclut la détection :
d'incohérences temporelles et de mouvement (déformation locale d'objets, dérive d'arrière-plan, flou soudain, anomalies de résidus de mouvement, etc.) ;
de la dynamique des comportements et interactions humaines (changements d'expression, dynamique d'identité, rythme d'interaction entre les personnages principaux de l'image, etc.) ;
d'anomalies physiques et fréquentielles liées à la fréquence temporelle et à la continuité de l'image.
Couche 3, cohérence intermodale (Cross-Modal Consistency) : vérification multimodale à l'intérieur de la vidéo
La couche 3 est un point de basculement crucial dans tout le cadre : la détection commence à entrer dans la vérification multimodale à l'intérieur de la vidéo. Elle s'intéresse à la question de recherche : les différents modes de la vidéo (image, son, sous-titres, etc.) « racontent-ils bien le même contenu, alignés à tous les niveaux » ?
Les vidéos réelles présentent généralement un alignement élevé entre les modes qui les accompagnent : audio, texte, image. Les vidéos générées par IA peuvent présenter des décalages systématiques entre la synchronisation labiale et la voix, l'identité et l'empreinte vocale, l'image et le texte. Les méthodes de la troisième couche effectuent une analyse de cohérence fine et multi-angle de la cohérence entre les modes. Cela comprend trois types :
détection de la cohérence entre le son et l'image ;
introduction des sous-titres, titres, transcriptions, textes descriptifs pour un raisonnement sur la cohérence sémantique texte-vidéo ;
apprentissage robuste pour la localisation temporelle des incohérences intermodales.
Couche 4, raisonnement au niveau du monde guidé par le langage (Language-Guided World-Level Reasoning) : se pencher sur l'écart entre la vidéo et le monde réel
La perspective de détection de la couche 4 passe de la « cohérence interne de la vidéo » à la « cohérence avec les règles, connaissances du monde réel externe, sans conflit ». La question de recherche devient : le contenu de la vidéo, sur les dimensions sémantique et factuelle, pourrait-il vraiment exister dans le monde réel, est-il plausible ?
Tout le contenu d'une vidéo réelle doit être cohérent avec les faits, les lois physiques, les connaissances du domaine, le bon sens de base, etc., du monde réel. Le contenu des vidéos générées par IA a souvent du mal à s'aligner complètement sur le monde réel, et c'est précisément cet espace que la quatrième couche exploite pour la détection. Cela inclut :
l'utilisation de mots-clés, de connaissances préalables textuelles, de prototypes textuels ou de modules légers pour recalibrer l'espace de représentation du modèle, afin qu'il associe plus facilement les anomalies perçues à des catégories sémantiques plus précises ;
considérer la détection comme un processus d'enquête, construisant un agent intelligent enquêteur qui sait consulter des sources, utiliser des outils, revenir sur son jugement, en liant le jugement aux preuves, aux sorties d'outils, au processus de vérification, etc. ;
via du fine-tuning, de l'apprentissage par préférence, de la modélisation de récompense et de l'apprentissage par renforcement, intégrer « comment choisir les preuves, comment organiser l'explication, comment tirer une conclusion » dans le modèle lui-même, en veillant à produire une sortie de détection claire, à la structure stable, avec une chaîne de preuves complète.
Carte d'évolution du côté génération et du côté détection
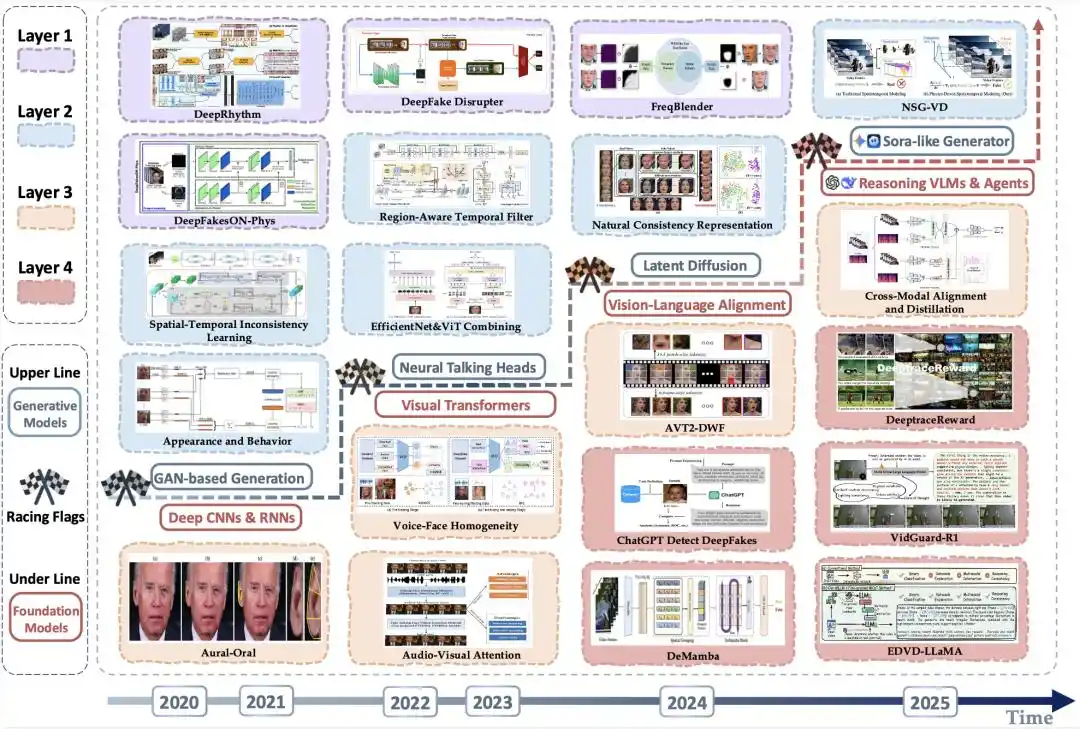
Figure 4 | Carte d'évolution des méthodes de détection représentatives : élévation des menaces du côté génération et progrès synchrones du côté détection
Le graphique ci-dessus présente, le long d'une chronologie, comment les menaces du côté génération relèvent continuellement le plafond de réalisme atteignable par les « fausses vidéos », tandis que dans le même temps, les modèles de base sur lesquels s'appuient les techniques de détection évoluent des réseaux convolutifs profonds et récurrents, aux Transformers visuels, puis aux grands modèles linguistiques et aux systèmes d'agents dotés de capacités de raisonnement. Il montre l'évolution du côté détection, passant progressivement de l'analyse médico-légale visuelle à la vérification multimodale et à la détection par raisonnement de haut niveau.
La revue établit en outre une statistique temporelle de la distribution des méthodes de détection par couche. La part des méthodes de perspective linguistique (couches 3 et 4) n'était que de 7,7 % en 2020, elle est passée à 40,0 % en 2023, et dépasse les 50 % en 2025.
Globalement, le centre de gravité des méthodes de détection monte continuellement : initialement concentré principalement sur les couches 1 et 2, avec les vidéos générées de plus en plus fluides et réalistes, la détection s'oriente de plus en plus vers les couches 3 et 4.
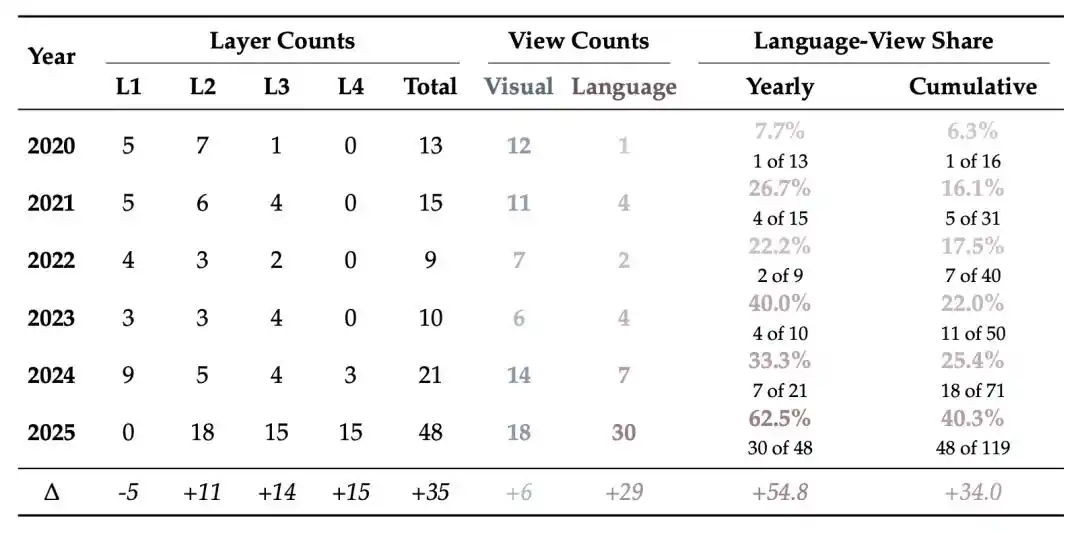
Figure 5 | Statistiques sur l'évolution de la distribution des méthodes de détection : la part de la perspective linguistique augmente progressivement
Évaluation des méthodes de détection
Face à l'objectif de détection de la fidélité aux faits, l'évaluation des méthodes de détection doit répondre à la question : le modèle a-t-il maîtrisé des indices visuels transférables, peut-il identifier les incohérences spatio-temporelles et intermodales, peut-il porter un jugement efficace sur les faits, les connaissances et les contraintes du monde. La revue organise systématiquement l'évolution des métriques d'évaluation et des jeux de données, de l'époque traditionnelle du Deepfake à aujourd'hui.
Métriques d'évaluation selon la double perspective visuelle-linguistique
Métriques partagées : Acc / AUC toujours nécessaires, mais loin d'être suffisantes
La précision (Acc), l'AUC, la précision (Precision), le rappel (Recall), le F1, l'EER, la PR-AUC, ainsi que les méthodes d'agrégation au niveau de l'image (frame-level) et de la vidéo (video-level), restent le langage commun le plus basique entre différentes méthodes, permettant des comparaisons transversales entre méthodes de différentes couches. Cependant, ces métriques d'évaluation de base, bien que nécessaires, ne peuvent pas répondre aux exigences d'évaluation explicables et crédibles dans l'objectif de vérification de la fidélité aux faits.
Métriques du point de vue visuel : évaluer si les indices restent valables face aux perturbations du monde réel
L'accent de l'évaluation porte sur la capacité du détecteur, lorsqu'il rencontre des changements de distribution, de la compression, de la diffusion et des perturbations propres aux environnements réels, à maintenir la validité de ses indices initiaux. Cela se divise en deux catégories :
- Robustesse des indices de bas niveau : inclut le TPR@FPR=α à seuil fixe, les tests sur jeux de données croisés, les tests de résistance aux perturbations, etc.
- Cohérence spatio-temporelle et physique : s'intéresse au reporting au niveau vidéo (video-level), à la baisse de performance face aux perturbations temporelles (temporal perturbation drop), aux tests d'ablation de mouvement, et vérifie si le modèle se dégrade significativement une fois les informations temporelles supprimées, afin d'évaluer si le détecteur regarde réellement la continuité de toute la séquence vidéo, et ne s'appuie pas sur des raccourcis dans des images individuelles.
Métriques du point de vue linguistique : évaluation de la localisation multimodale et du raisonnement
Le champ couvert par les approches de détection du point de vue linguistique est plus large, et les métriques d'évaluation ne peuvent plus être résumées par un simple ensemble d'indicateurs de classification. La revue propose la stratification suivante :
- Alignement intermodal et localisation temporelle : ces métriques d'évaluation visent la précision de la détection dans l'alignement intermodal, et la capacité du détecteur à localiser les indices à des périodes spécifiques. Outre les Acc et AUC de base, les indicateurs courants incluent souvent l'AP, l'AR, le Recall@K, le mAP@IoU, etc.
- Connaissances du monde et raisonnement : face à la question de plus haut niveau « l'événement raconté par la vidéo peut-il être étayé par le bon sens, les lois physiques, les connaissances externes et des preuves concrètes ? », les métriques d'évaluation de la détection doivent introduire des jugements humains (human judgments), des préférences par paires (pairwise preferences), des réponses à des questions (question answering), ainsi que des indicateurs comme BLEU, ROUGE-L, METEOR, CIDEr, ou des similarités basées sur les embeddings, servant à évaluer la qualité des explications.
Jeux de données : réorganisés selon les trois paradigmes des objets de détection
La grande majorité des jeux de données utilisés pour l'évaluation et l'entraînement des méthodes de détection se différencient naturellement selon les paradigmes de vidéos générées par IA mentionnés précédemment. La revue les organise comme suit :
- Jeux de données pour le paradigme LMV : l'évaluation se concentre sur la stabilité des indices visuels des méthodes de détection, et sur la capacité de ces indices à rester valables face à la distorsion, la compression et la diffusion inter-domaines. Ces jeux de données évoluent constamment en intégrant des évaluations de raisonnement temporel et d'explicabilité pour se rapprocher des environnements réels.
- Jeux de données pour le paradigme AVE : ces jeux de données mettent souvent davantage l'accent sur des annotations temporelles fines, des relations intermodales correspondantes plus explicites, et une modélisation plus forte des décalages locaux et des incohérences sémantiques. Ils examinent la capacité du modèle à détecter que l'audio et la vidéo ne racontent pas la même chose, à localiser la période où le décalage se produit, à distinguer les problèmes de synchronisation, d'identité et de sémantique.
- Jeux de données pour le paradigme GVS : d'un côté, les vidéos entièrement synthétiques atténuent continuellement les traces d'édition explicites, de l'autre, elles apportent sans cesse de nouveaux défis à la détection comme la diversité des générateurs, le désalignement sémantique et les risques de transfert. L'évaluation correspondante évolue le plus rapidement : des premières collections massives de vidéos entièrement synthétiques pour évaluer la précision de la détection, on est passé à des travaux comme LOKI, GenWorld, DAVID-X, DeeptraceReward qui intègrent dans le système d'évaluation la simulation du monde, l'annotation au niveau des défauts, et les indices de falsification perçus par les humains.
Évaluations liées au diagnostic des modèles de génération vidéo
Les ressources liées à l'évaluation pour la détection ne se limitent pas aux jeux de données orientés spécifiquement vers la détection. En effet, dans la recherche en vision par ordinateur (CV) et sur les modèles du monde, de nombreuses évaluations diagnostiques de la qualité de génération des modèles de génération vidéo et des évaluations des capacités de détection d'erreurs des modèles de compréhension vidéo peuvent également servir de références importantes pour la détection. La revue organise ces travaux d'évaluation diagnostique pouvant servir de ressources complémentaires selon une chaîne d'évaluation progressant par étapes :
- Examiner d'abord si les objets, attributs, interactions et changements d'état dans la vidéo respectent les lois physiques de base ;
- Ensuite, examiner la dynamique du monde et la causalité, c'est-à-dire si les lois locales peuvent s'étendre sur toute la vidéo pour former un processus événementiel continu, cohérent, conforme aux connaissances du monde ;
- Enfin, voir si des systèmes comme les modèles de compréhension vidéo peuvent transformer les erreurs à différents niveaux dans ces vidéos générées en jugements clairs, compréhensibles et vérifiables.
De « pouvoir distinguer » à « pouvoir prouver »
Les vidéos générées par IA de haute fidélité continuent de relever le plafond de réalisme des contenus falsifiés. Le problème auquel est confrontée la tâche de détection devient de plus en plus difficile à résumer par un simple score vrai/faux ; une détection de la fidélité aux faits est nécessaire. En conséquence, les phases d'évaluation et les systèmes de détection doivent également s'étendre parallèlement à l'élargissement des limites de la tâche :
Système d'évaluation dynamique priorisant les preuves
Face aux nouvelles vidéos complexes de longue durée générées par IA, l'évaluation ne doit plus seulement répondre à la question « le modèle sait-il classer », mais aussi à « sur quels indices le modèle s'est-il précisément appuyé pour produire un jugement correct ou erroné ». Des étiquettes d'évaluation grossières masquent de nombreuses informations réellement cruciales. L'annotation des données, l'entraînement des modèles et le rapport des résultats dans l'évaluation doivent également avancer de pair, nécessitant de décomposer la vidéo en unités de propositions vérifiables, de transformer la « narration sur de longues séquences » en objets structurés exploitables comme des chaînes d'événements, des trajectoires d'état d'entités ou des graphes d'événements, afin de permettre une vérification causale et des contraintes sur de longues échelles temporelles, et ainsi interroger plus avant la détection sur « quelle proposition précise elle a identifiée » et « si la preuve et le jugement correspondent bien un à un ».
De plus, la plupart des détecteurs sont encore évalués dans un cadre « en monde fermé » : dans les scénarios de déploiement réels, de nouveaux modèles de génération vidéo, outils d'édition et styles de contenu émergent continuellement, et différentes plateformes introduisent leurs propres processus de sous-échantillonnage, de transcodage et de filtrage. Pour combler ce déficit de robustesse à long terme, il faut s'inspirer des mécanismes de mise à jour continue de type arena/leaderboard, en intégrant de manière fluide les nouveaux générateurs publiés et les nouvelles chaînes de transcodage des plateformes dans l'ensemble d'évaluation.
Système de détection fiable et explicable, intégrant les deux perspectives
Pour réaliser une détection explicable de la fidélité aux faits mentionnée précédemment, il faut combiner les deux chaînes de perception et de cognition, en associant la capacité de la perspective visuelle à révéler les artefacts visuels et les incohérences spatio-temporelles, avec la capacité de la perspective linguistique de haut niveau à effectuer un raisonnement structuré, afin d'unifier les quatre couches de méthodes à travers cette double perspective. D'une part, les modèles linguistiques visuels et les modèles de compréhension vidéo actuels sont relativement faibles dans la discrimination liée à la « fidélité perceptive », nécessitant des moyens de la perspective visuelle pour les compléter. D'autre part, pour les vidéos générées par des modèles plus puissants et des techniques anti-détection, hautement fidèles sur le plan perceptif, une détection au niveau factuel et sémantique dans l'espace des faits est nécessaire, du point de vue linguistique.
En outre, il faut établir un chemin de raisonnement explicite « identification – localisation – explication ». Cela signifie que, dans le système à double chaîne mentionné ci-dessus, chaque appel d'outil ou référence à une connaissance doit être strictement lié à une étape spécifique de l'argumentation.
De plus, le système de détection constitué du côté « contenu » doit être croisé avec des signaux d'authentification possibles du côté « source », etc., pour connecter l'analyse du contenu et la traçabilité à la source. Au final, cela forme un système de détection multiniveaux et multimodal, ainsi qu'un espace de preuves fiable et explicable.
Conclusion
La détection de vidéos IA est une tâche qui ne fera que devenir de plus en plus difficile.
Pour la future recherche et les applications pratiques de détection AIGC-V, cette revue fournit une carte plus proche des besoins opérationnels. Elle redéfinit la tâche de détection de vidéos générées par IA, propose un cadre à quatre couches selon une « double perspective visuelle-linguistique », et organise systématiquement sur cette base les méthodes existantes, les références et les indicateurs d'évaluation associés, tout en reliant ces couches aux défis du déploiement réel, aux lacunes des évaluations actuelles et aux orientations de développement émergentes.
En suivant ce cadre, elle souligne plusieurs exigences clés que doit posséder une détection crédible, notamment la priorité aux preuves, la traçabilité des conclusions, et le maintien d'une robustesse face aux différents générateurs et aux conditions de scénarios réels.
À l'avenir, une détection crédible des vidéos IA ne pourra difficilement plus être accomplie par un seul domaine de manière indépendante. Elle devient un sujet croisé que doivent affronter conjointement la recherche en CV, en NLP, en compréhension multimodale et sur les modèles du monde : la CV fournit la modélisation des preuves spatio-temporelles et la robustesse de l'analyse médico-légale, le NLP fournit les capacités de décomposition en propositions, de raisonnement, de concrétisation des preuves et d'explication, tandis que la recherche multimodale et sur les modèles du monde fournit des capacités d'alignement intermodal plus fortes et des connaissances a priori plus riches sur la physique, la causalité et la cohérence temporelle.
Ce n'est qu'en combinant véritablement ces capacités que la détection vidéo pourra progressivement dépasser la recherche d'artefacts locaux, pour évoluer vers une « vision de la réalité » plus rigoureuse : la question ne sera plus seulement de savoir si la vidéo paraît crédible, mais si les entités, événements et processus dynamiques qu'elle contient sont toujours fidèles aux contraintes du monde réel, en cherchant à définir la frontière de plus en plus floue entre le monde virtuel et le monde réel.
Références : https://www.researchgate.net/doi/10.13140/RG.2.2.31713.88168
Cet article provient du compte WeChat public « Xin Zhi Yuan », édité par LRST





