La conférence Google I/O 2026 pour les développeurs n'a laissé qu'une seule impression : l'audace.
Non seulement ils ont intégré de force des agents intelligents basés sur l'IA dans tous les principaux points d'accès aux flux : recherche, navigateur, téléphone, lunettes intelligentes, mais ils ont aussi dévoilé coup sur coup trois cartes maîtresses : Gemini 3.5 Flash, le modèle vidéo Omni et le nouvel assistant Spark.
Après avoir montré ses muscles, Sundar Pichai a même annoncé de manière ostentatoire que les utilisateurs actifs mensuels de Gemini avaient atteint 9 milliards, tout en officialisant une réduction significative des prix.
Le message ne pouvait être plus clair : Je suis meilleur, et moins cher.
Qu'est-ce que c'est, sinon une déclaration de guerre ?
01
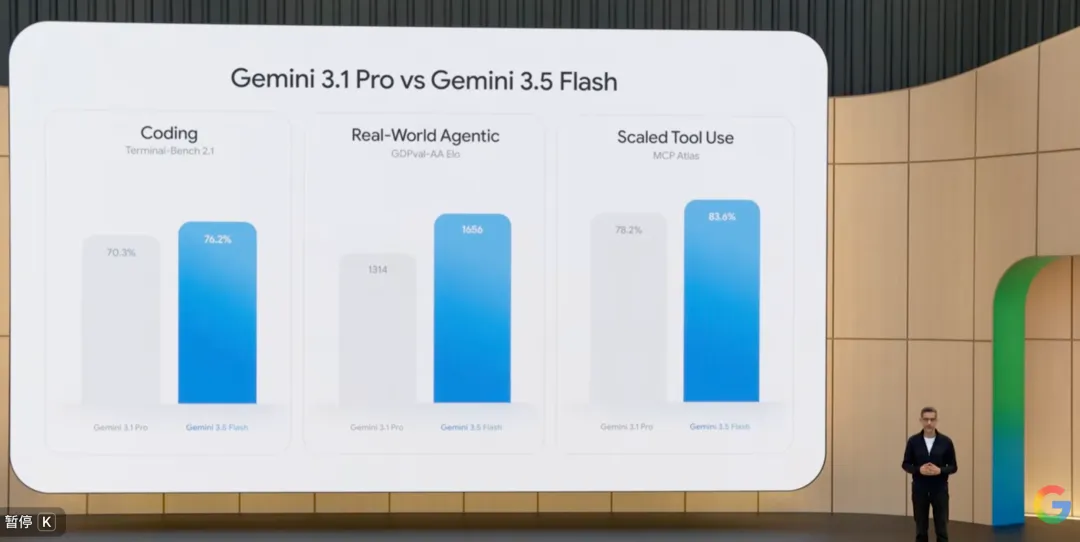
La révélation la plus impressionnante de la conférence était sans aucun doute Gemini 3.5 Flash.
Normalement, "Pro" représente la puissance de base, "Flash" signifie léger et rapide.
En termes de paramètres du modèle, 3.5 Flash est effectivement plus petit que 3.1 Pro, mais ses performances sont en réalité supérieures dans presque tous les tests de référence en raisonnement et en codage :
Sur le test GSM8K de raisonnement mathématique complexe, 3.5 Flash a obtenu un score de 95,8 %, surpassant les 93,2 % de 3.1 Pro ; dans le test de génération de code SWE-bench (version complète), le taux de résolution de 3.5 Flash était de 38,4 %, dépassant largement les 32,1 % de 3.1 Pro...
Pourquoi ?
Selon le Gemini 3.5 Technical Report publié par DeepMind, deux technologies clés sont les plus importantes.
Distillation de connaissances extrême : Google n'a pas simplement entraîné Flash en augmentant la puissance de calcul, mais a utilisé "Gemini 3.5 Ultra", jamais divulgué auparavant, comme modèle enseignant pour une distillation de dimension réduite vers Flash.
Selon l'analyse du tweet du scientifique en chef de DeepMind, Jeff Dean, la proportion de fine-tuning de 3.5 Flash sur des ensembles de données de chaînes de raisonnement de haute qualité a augmenté de 400 % par rapport à la génération précédente.
Cela signifie qu'il a hérité du "cerveau logique" des très grands modèles, et non d'une "base de connaissances" apprise par cœur.
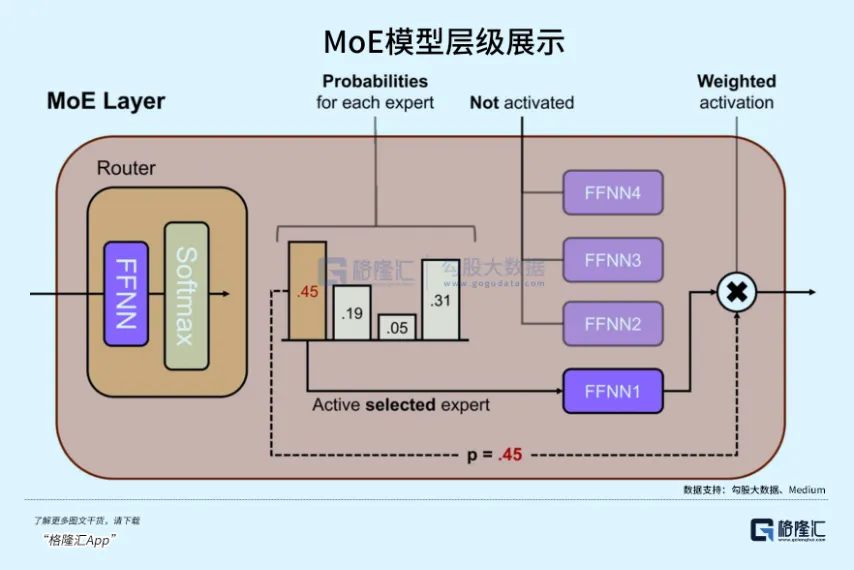
Nouvelle architecture MoE (Modèle de Mélange d'Experts) : Dans 3.5 Flash, Google a adopté des réseaux d'experts à granularité plus fine.
Les MoE traditionnels peuvent n'avoir que 8 ou 16 experts, n'en activant que 1-2 à la fois, ce qui suffit pour supporter des modèles à l'échelle de milliers de milliards de paramètres.
Selon l'analyse du mémorandum d'investissement dans l'infrastructure IA 2026 de a16z, 3.5 Flash utilise 256 micro-experts, activant les 4 plus efficaces à chaque inférence.
C'est pourquoi, tout en maintenant un très faible nombre de paramètres activés, il peut couvrir un espace de caractéristiques multimodales extrêmement vaste.
Sur l'indicateur TTFT (Time to First Token), 3.5 Flash a atteint moins de 65 millisecondes.
Un clignement d'œil humain prend 100-150 millisecondes.
En termes simples, lorsqu'il fonctionne en tant qu'agent intelligent, du point de vue physiologique humain, il est impossible de percevoir une quelconque pause.
Pour les développeurs ayant besoin d'invoquer fréquemment des outils, de réflexion multi-tours et d'une latence extrêmement faible, c'est la base parfaite pour un super agent.
Ce n'est qu'en s'appuyant sur une optimisation technique aussi poussée qu'il est possible d'établir une domination dans le "déploiement côté terminal" dans un environnement hautement concurrentiel.
Premièrement, le modèle multimodale natif Gemini Omni Flash.
Omni signifie omniscient, en référence à l'ancien GPT-4o. Rien qu'au nom, on ressent l'intensité de la compétition.
Au moins en termes de performances, Gemini Omni Flash a beaucoup plus le droit d'utiliser le caractère "o" que GPT-4o.
Les premiers Sora ou Gemini 1.5 étaient essentiellement des assemblages hétéroclites, convertissant la parole en texte, puis le texte en vision.
Mais le Omni publié cette fois est un véritable alignement multimodal natif de bout en bout. Il peut non seulement comprendre de manière native la cohérence temporelle et les lois physiques dans une vidéo, mais sa latence est également passée de la moyenne du secteur de 400-600 millisecondes à 120 millisecondes.
Un exemple de la conférence : un utilisateur portant une caméra remplit un verre d'eau. Omni peut dire "Stop, stop, stop !" 0,5 seconde avant que le verre ne déborde.
Ce type d'inférence en temps réel sur l'état physique du monde réel semble simple, mais il est très significatif : L'IA passe d'un chatbot à l'écran à un outil d'assistance dans le monde réel.
Même s'il n'en est qu'à ses débuts.
Deuxièmement, l'assistant intelligent Spark.
Selon des informations divulguées dans une interview de The Verge avec le vice-président de l'ingénierie Android, Spark se voit attribuer un contrôle natif des API au niveau du système d'exploitation Android 17.
En termes simples, les processus complexes qui nécessitaient auparavant d'ouvrir de nombreuses applications peuvent désormais être entièrement gérés simplement en donnant un ordre à Spark. Il peut même envoyer des messages, organiser des e-mails, résumer des agendas, suivre des pages web, identifier des frais cachés sur les factures, traiter des documents par lots, etc., en fonction de votre ton et de vos préférences...
En d'autres termes, avec un assistant IA, nous n'aurons plus vraiment besoin d'applications. Toute opération complexe sera simplifiée en une seule commande.
Troisièmement, les lunettes intelligentes.
Pourquoi encore des lunettes ?
Du moins aux yeux de Google, l'accès transparent à la vue et à l'ouïe est l'hôte ultime des grands modèles multimodaux.
Ces lunettes n'ont aucun design tape-à-l'œil et se concentrent entièrement sur les capacités pratiques :
Des lentilles à guide d'ondes Micro-OLED couleur pesant seulement 4 grammes, avec un taux de transparence atteignant 85 % ;
Équipées d'une puce Gemini allégée développée en interne, avec une latence d'inférence locale ≤12 ms, permettant une traduction en temps réel, une reconnaissance d'images, une analyse de scène sans connexion internet ;
Intégration native avec l'agent intelligent Spark, synchronisant les données du téléphone et du cloud, offrant des services personnalisés comme des rappels d'agenda, des traductions en temps réel, des alertes environnementales.
En un mot, il s'agit de franchir l'écran du téléphone et intégrer l'agent intelligent dans la perspective de première personne de l'humain grâce aux lunettes.

Le contenu est tellement dense que Google semble avoir utilisé toutes ses cartes maîtresses d'un coup, annonçant au marché une vérité :
Sans point d'entrée, un algorithme n'est rien.
L'ère de l'augmentation des paramètres des grands modèles et des comparaisons de performances est révolue. Les fournisseurs de modèles purs n'ont plus de barrières. L'avenir est une guerre quadridimensionnelle "terminal + cloud + écosystème + matériel".
Intégrer l'IA dans la suite complète de services, c'est en fait remodeler toute la logique de distribution du trafic internet : passer de "l'utilisateur recherche/clique activement" à "l'agent intelligent IA distribue activement des services".
Pour la grande majorité des développeurs et des PME, c'est une excellente nouvelle, car la puissance de calcul et les modèles sous-jacents deviennent extrêmement bon marché, permettant de se concentrer sur l'innovation au niveau applicatif.
Mais les autres concurrents, eux, doivent probablement vouloir jurer à haute voix en ce moment.
02
Lorsque Sundar Pichai a annoncé avec désinvolture sur scène que "les utilisateurs actifs mensuels de Gemini ont officiellement dépassé les 9 milliards", cela a créé un certain émoi dans l'audience.
9 milliards, plus que la somme de tous les MAU des concurrents américains.
Comment est-ce possible ?
La réponse est simple et brutale : Intégration de force.
Google n'a pas besoin de dépenser en publicité pour attirer des utilisateurs comme le feraient des sociétés d'IA indépendantes. Il suffit d'ajouter une icône à côté de la barre d'adresse du navigateur Chrome, d'intégrer un raccourci d'appel dans la barre de navigation inférieure des 3 milliards de téléphones Android, de diffuser une mise à jour complète dans Google Workspace...
Le coût d'acquisition est essentiellement nul.
Plus crucial encore, dans les mois à venir, les regards que les 9 milliards d'utilisateurs actifs porteront sur les produits avec leurs lunettes intelligentes, les logiques qu'ils corrigeront en traitant des tâches avec Spark, et les interactions avec le modèle visuel Omni généreront d'énormes quantités de données de rétroaction de haute qualité, multimodales et du monde réel, qui deviendront toutes des nutriments pour nourrir Gemini 4.
C'est une barrière extrêmement solide : Plus le modèle est performant -> plus il y a d'utilisateurs -> plus il génère de données -> le modèle devient encore plus performant.
Pour renforcer rapidement cette boucle, Google déclare directement la guerre des prix à tous ses concurrents : le forfait AI Ultra passe de 249,99 $/mois à 99,9 $/mois.
3.5 Flash voit son prix pour 1 million de tokens en entrée baisser à 0,02 $, et pour 1 million de tokens en sortie à 0,08 $.
Quel prix miraculeux !
À titre de comparaison, le prix moyen des modèles de niveau équivalent dans le secteur est respectivement de 0,15-0,2 $ et 0,6-1 $.
Sundar Pichai a fait le calcul : les principaux clients traitent environ 1 billion de tokens par jour. En transférant 80 % de la charge de travail vers Gemini 3.5 Flash pendant un an, cela peut économiser plus de 10 milliards de dollars.
Pourquoi peut-il se permettre de vendre l'IA à un prix dérisoire ?
Le plus grand atout est : l'infrastructure de puissance de calcul intégrée verticalement.
Des géants comme OpenAI, Anthropic, bien qu'impressionnants, sont essentiellement des "locataires de puissance de calcul", devant l'acheter auprès de Microsoft, Amazon, qui eux-mêmes paient Nvidia.
Google possède ses propres TPU, et avec l'efficacité d'activation sparse extrême de MoE de 3.5 Flash, il a compressé les coûts de calcul à l'extrême.
Il peut parfaitement utiliser son avantage d'actifs lourds pour mener une guerre de prix à bas coût contre les simples entreprises d'algorithmes.
La logique est claire.
Les grands modèles de base se banalisent rapidement. Comme l'eau et l'électricité, avez-vous déjà vu une entreprise d'eau générer des profits faramineux ?
Google ne craint pas que le modèle de base en lui-même ne soit pas rentable, car il peut récupérer l'argent via la publicité sur les recherches, les services cloud et les commissions de l'écosystème Android.
Mais pour ceux dont la survie dépend de la vente d'API de grands modèles, comme OpenAI, Anthropic, Cohere, Mistral, c'est impossible.
Les investisseurs doivent probablement vouloir demander à Sam Altman : "Le prix de l'API de Google n'est qu'un dixième du vôtre, et ses performances sont meilleures. Expliquez-moi comment votre modèle économique peut être viable ?"
La structure concurrentielle de plusieurs secteurs entrera donc dans une phase d'évolution accélérée.
Les fournisseurs d'IA doivent rapidement trouver des sources de calcul moins chères ou se lancer dans la fabrication de puces.
Ensuite, Apple, qui travaille encore à huis clos.
La combinaison lunettes intelligentes + modèle vidéo Omni + intégration native au niveau système Spark menace sans aucun doute l'iPhone.
Selon le rapport de prévision de tendances des produits électroniques grand public de Macquarie : Dans les trois prochaines années, la part du temps d'interaction sans écran basé sur la vision/la parole devrait passer de 8 % actuellement à 35 %.
Si les utilisateurs s'habituent à effectuer leurs tâches quotidiennes et divertissements avec des lunettes et la voix, le temps d'utilisation des écrans sera nécessairement fortement réduit.
Si Apple ne parvient pas à proposer des dispositifs portables suffisamment impressionnants pour contre-attaquer (Vision Pro est trop lourd et cher, destiné à rester un jouet pour une minorité), son monopole sur les points d'entrée de l'ère mobile sera mis à rude épreuve comme jamais auparavant.
Ce n'est pas une évolution, c'est une révolution.
Google a lancé un défi à tous ses concurrents avec trois armes : la technologie, le flux et le prix.
À ce stade, y a-t-il encore quelqu'un pour se moquer de sa soi-disant maladie de grande entreprise ?






