Auteur : Fei-Fei Li
Traduction : Jiayang
Le "modèle du monde" est probablement le concept le plus chaud et le plus confus dans le domaine de l'IA depuis 2025. Lorsque Sora est sorti, OpenAI l'a appelé simulateur du monde ; Genie, qui vous permet de vous déplacer dans des images générées, s'appelle également modèle du monde ; les entreprises de robotique disent qu'elles travaillent sur des modèles du monde, NVIDIA dit qu'Omniverse est l'infrastructure des modèles du monde, et même les moteurs de jeu ont été intégrés dans ce récit. Tout le monde utilise le même terme, mais chacun parle de choses totalement différentes.
Aujourd'hui, Fei-Fei Li a publié un nouvel article sur son Substack pour clarifier ce concept. Elle revient d'abord au diagramme classique des manuels d'apprentissage par renforcement (la boucle POMDP : agent → action → état → observation → agent), puis souligne : les choses actuellement appelées "modèles du monde" sont en fait trois projections différentes de cette boucle fermée. Ce qui produit des pixels (observations) est un rendu ; ce qui produit des états est un simulateur ; ce qui produit des actions est un planificateur. Le critère de classification est très simple : il suffit de regarder quelle partie de la boucle est produite en sortie.

(Source : MIT Technology Review)
Elle juge que parmi les trois, le rendu est le plus mature commercialement mais a un plafond (une belle apparence ne signifie pas une exactitude physique), le planificateur est le plus excitant mais le plus éloigné du déploiement réel (l'écart entre les démonstrations en laboratoire et la disponibilité pratique reste énorme), tandis que le simulateur est le pivot clé gravement sous-estimé. Parce que le simulateur travaille au niveau de la géométrie, de la physique et de la dynamique, il peut à la fois se projeter vers le haut en pixels pour la consommation humaine et déduire les conséquences des actions pour l'utilisation des robots. Maîtriser la simulation signifie avoir simultanément les bases du rendu et de la planification ; l'inverse n'est pas vrai.
Cet article est bien sûr aussi une déclaration produit de World Labs. Leur modèle Marble produit déjà simultanément des "Gaussian splats" et des maillages de collision, essayant d'unifier le rendu et le simulateur dans un seul modèle. La fin de l'article décrit un aboutissement ultime : un modèle de base du monde unifié capable de basculer librement entre rendu, simulation et planification en fonction des besoins en aval. La question de savoir si cette vision peut être réalisée est une autre histoire, mais en tant que cadre d'analyse, la tripartition rendu/simulateur/planificateur aide peut-être vraiment à percer une partie du bruit actuel autour du concept de "modèle du monde".
La traduction complète est la suivante.
"Le monde est tout ce qui arrive." — Wittgenstein, Tractatus logico-philosophicus, 1921
Le monde n'est pas fait de mots.
Dans un article précédent, nous avons proposé que l'intelligence spatiale soit la prochaine frontière de l'IA, et que les modèles du monde en soient la voie. Ici, l'équipe de World Labs et moi-même souhaitons aller plus loin : parmi la multitude de choses appelées aujourd'hui "modèles du monde", quels modules fonctionnels constituent véritablement cette capacité ? Et à quoi servent-ils ?
Les modèles de langage ont donné aux machines une puissante maîtrise des concepts, du vocabulaire et du raisonnement, mais le monde physique, qu'il soit virtuel ou réel, fonctionne sur un substrat totalement différent. Les modèles de langage apprennent la structure statistique du texte, les modèles du monde apprennent la structure statistique de l'espace et du temps : comment la lumière tombe sur une surface, comment un jardin apparaît sous un angle jamais capturé par une caméra, comment les objets répondent aux forces et suivent les lois de la physique.
Cela fait du "modèle du monde" l'un des termes les plus importants et les plus galvaudés dans le domaine de l'IA aujourd'hui. La vision par ordinateur, la robotique, l'apprentissage par renforcement et l'IA générative affirment tous construire des modèles du monde, mais chacun parle de choses radicalement différentes. Un modèle vidéo générant des flammes magnifiques mais physiquement impossibles, un modèle de langage improvisant un jeu jouable, un moteur physique simulant fidèlement le processus de combustion, ils sont tous appelés du même nom.
Les Grecs anciens ne sont jamais parvenus à un accord sur ce qui constitue le monde, que ce soit le feu, l'eau ou des atomes indivisibles, car le "monde" n'a jamais été une chose unique. Il a toujours été un substitut utilisé par un penseur pour raisonner sur une certaine totalité. L'IA a hérité du même problème, et cela arrive précisément au moment où le domaine a le plus besoin de précision.
La boucle fermée derrière la taxonomie
Pour démêler cette confusion, on peut partir d'un diagramme plus ancien que toutes ces technologies. Tous les manuels d'apprentissage par renforcement, y compris le classique Sutton et Barto, utilisent depuis des décennies des variantes d'un même diagramme pour décrire comment un agent interagit avec le monde. Son nom formel est le Processus de décision markovien partiellement observable (POMDP), et la définition originale du terme "modèle du monde" appartient à cette tradition.
Un agent (qui peut être un humain, un robot ou un système logiciel) exécute une action. Cette action modifie l'état du monde. Mais l'agent ne voit jamais directement l'état lui-même ; ce qu'il reçoit, c'est une observation : les photons tombant sur la rétine, les lectures des capteurs, les pixels d'une trame vidéo. Une nouvelle observation guide une nouvelle action, et ainsi de suite.
Le terme "état" mérite d'être décomposé, car son sens varie selon les domaines. Il ne s'agit pas ici de l'état du chimiste, de la distinction entre solide, liquide et gazeux. C'est l'état du physicien et du roboticien : une description complète de tout ce qui se passe dans le monde à un instant donné, incluant chaque objet, chaque position, chaque vitesse, chaque attribut. L'état est la réalité sous-jacente du monde, en principe complète, mais jamais directement observable pour aucun agent qui y évolue. L'observation est la perspective locale que l'agent a de cette réalité. L'action est la réponse que l'agent fait en conséquence.
Cette boucle fermée (agent → action → état → observation → agent) est précisément la structure qui donne au terme "modèle du monde" sa signification technique. L'expression elle-même est plus ancienne, remontant à la proposition de Kenneth Craik en 1943 selon laquelle l'esprit raisonne en exécutant des "modèles à petite échelle" de la réalité, et à la fin des années 1980 et au début des années 1990, ce concept a été introduit dans le domaine des réseaux neuronaux. Cette boucle fermée explique également ce que les gens entendent aujourd'hui lorsqu'ils utilisent ce terme. Les différentes choses maintenant appelées modèles du monde sont en fait des projections différentes de cette même boucle fermée, chacune produisant en sortie une partie différente de la boucle.
Les trois fonctions d'un modèle du monde
Le premier type de modèle du monde est le moteur de rendu. Le moteur de rendu produit des observations, spécifiquement des pixels destinés à l'œil humain, et la métrique de qualité la plus importante est la fidélité visuelle. Un modèle vidéo qui transforme une invite textuelle en séquences cinématographiques de type drone est un moteur de rendu ; des systèmes interactifs comme Genie 3 de Google ou RTFM de World Labs lui-même, qui génèrent des images en temps réel en fonction des entrées utilisateur, sont également des moteurs de rendu. Ces modèles n'ont pas de compréhension explicite de la structure tridimensionnelle. Ils génèrent ce que le spectateur verra, et non à quoi les choses ressemblent réellement. Les bâtiments dans une séquence de drone peuvent être parfaits vus du ciel, mais essayez de naviguer dans la ville en dessous, et ils s'effondreront.
Le second type est le simulateur. Le simulateur produit des états : une représentation du monde fidèle sur les plans géométrique, physique ou dynamique, sur laquelle les humains et les programmes informatiques peuvent calculer et interagir. Le contrat du moteur de rendu est purement visuel, tandis que le contrat du simulateur est structurel ; il exige que la géométrie soit robuste, que la physique suive les lois de Newton, et que les comportements dynamiques se conforment aux attentes des lois physiques. Le simulateur sert deux types d'utilisateurs. Les professionnels comme les architectes, designers, cinéastes, développeurs de jeux ont besoin d'une exactitude allant au-delà de la crédibilité visuelle. Les programmes informatiques comme les agents d'apprentissage par renforcement, les contrôleurs robotiques, les véhicules autonomes utilisent le simulateur comme terrain d'entraînement, interagissant à grande échelle avec le monde, testant des scénarios qui seraient dangereux, coûteux ou tout simplement impossibles à exécuter dans la réalité.
Le troisième type est le planificateur. Le planificateur produit des actions. Étant donné une observation et un objectif, le planificateur répond à la question : que doit faire l'agent ensuite ? En un sens, le planificateur est le processus inverse du moteur de rendu. Le moteur de rendu prend une action en entrée et produit une observation, le planificateur prend une observation en entrée et produit une action, fermant ainsi la boucle perception-action. Les modèles vision-langage-action (VLA), les systèmes à base de modèles, ainsi que la nouvelle vague de modèles d'action du monde (World Action Models) sont toutes des tentatives de planificateurs : permettre au système de décider ce qu'un robot doit faire dans un monde non structuré.
Ces trois catégories couvrent la majorité des travaux actuellement mis en œuvre, et leur distinction est utile en pratique. Mais ces trois catégories ne sont pas fondamentalement séparées. Elles partagent la même connaissance sous-jacente du fonctionnement du monde : la géométrie, la physique, la dynamique. Un modèle capable de rendre une tasse sous n'importe quel angle devrait en principe être capable de simuler ce qui se passe si la tasse est poussée, et de planifier le mouvement d'une main pour la saisir. De plus en plus des recherches les plus intéressantes brouillent délibérément les frontières entre ces trois aspects.
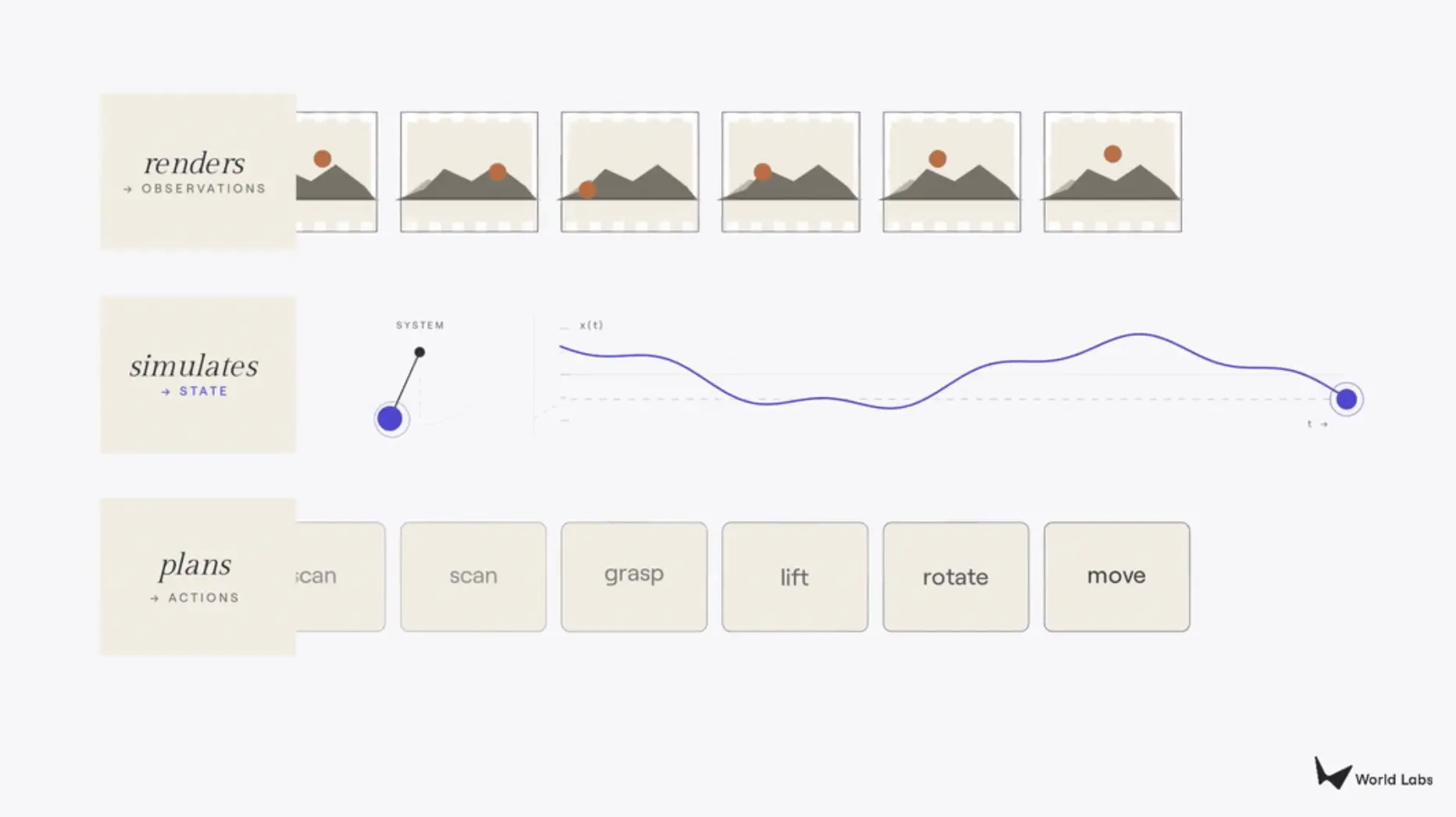
Diagramme | Les trois types de modèles du monde (Source : Substack)
Pourquoi la simulation est le pivot clé
Parmi les trois catégories, le simulateur reçoit le moins d'attention publique, mais c'est le plus important des trois. Cet article vise à corriger cette asymétrie.
Le moteur de rendu est actuellement le plus avancé commercialement. De nombreux produits d'image ou de texte-à-vidéo se déploient rapidement sur les marchés grand public et d'entreprise. Le modèle Nano Banana de Google a apporté des capacités de génération d'images de niveau moteur de rendu à potentiellement des centaines de millions d'utilisateurs. La technologie est réelle, le marché aussi. Cependant, le moteur de rendu optimise pour la crédibilité visuelle plutôt que pour l'exactitude physique, et ce plafond est important. Leurs productions sont belles, mais on ne peut pas les utiliser pour concevoir un bâtiment ou entraîner un robot.
Le planificateur est le plus excitant et le moins mature, étroitement lié au domaine de l'apprentissage robotique en rapide évolution. Ces deux dernières années, ce domaine a produit de nombreuses démonstrations robotiques impressionnantes en vidéo, mais nous devons être francs sur ce que ces démonstrations montrent réellement. Presque toutes se limitent à des environnements de laboratoire hautement contraints, avec un nombre limité d'objets et des tâches de courte durée. Aucune n'a été soumise à la complexité, à la diversité et à la durée continue requises pour un déploiement réel. L'écart entre une vidéo de démonstration impressionnante et un robot capable de fonctionner de manière fiable dans une cuisine, un entrepôt ou une salle d'opération reste immense.
Malgré cela, les paris commerciaux restent substantiels. Une vague de nouveaux entrants bien financés se précipitent pour lancer des systèmes de planification généraux, tandis que les grands acteurs d'infrastructure construisent des capacités de planification sur des piles de simulation plus larges.
La simulation est le pont entre les deux. Si le langage est une abstraction du monde, les pixels sont une projection du monde, alors la géométrie, la physique et la dynamique sont le monde lui-même. Le simulateur doit opérer à ce niveau : c'est le squelette structurel à partir duquel peuvent être dérivées à la fois la représentation visuelle (pour le moteur de rendu) et les conséquences des actions (pour le planificateur).
Un modèle qui maîtrise la simulation peut projeter sa compréhension en pixels pour la consommation humaine, et également en prédictions d'actions pour les agents incarnés. Un modèle qui ne maîtrise que le rendu ou la planification ne peut faire ni l'un ni l'autre. L'espace commercial ici est extrêmement vaste. Rien que pour l'Omniverse de NVIDIA, le marché cible est estimé par la société à plus de mille milliards de dollars, couvrant les usines, les entrepôts, les chaînes d'approvisionnement et les jumeaux numériques. L'entraînement des robots, les tests de conduite autonome, la visualisation architecturale, l'ingénierie, la découverte de médicaments dépendent tous d'une forme de simulation.
Les questions ouvertes les plus difficiles de ce domaine se concentrent également ici. Les données tridimensionnelles avec une géométrie explicite, des attributs de matériaux et des annotations physiques sont de plusieurs ordres de grandeur plus rares que les vidéos Internet utilisées pour l'entraînement des moteurs de rendu. L'écart "sim-to-real" (différence entre le comportement des objets en simulation et dans le monde réel) persiste. Les simulateurs génératifs introduisent de nouveaux risques supplémentaires : la géométrie générée par l'IA peut sembler correcte mais contenir des problèmes d'auto-intersection ou de mauvaise échelle, conduisant à des résultats physiques absurdes. Le coût computationnel de la simulation multi-physique à grande échelle (corps rigides, objets déformables, fluides, tissus interagissant simultanément) reste de plusieurs ordres de grandeur supérieur à celui de la simulation dans un domaine unique.
Chez World Labs, Marble est notre premier pas dans cette direction. Il accepte des entrées multimodales (texte, image, vidéo ou croquis spatial), génère des environnements 3D explorables, et produit simultanément des "Gaussian splats" pour l'exploration visuelle et des maillages de collision pour les moteurs physiques. Mais Marble n'est que le premier chapitre d'un long arc. Alors que les frontières entre rendu, simulation et planification commencent à s'estomper, tout le domaine écrit cette histoire.
Les frontières s'estompent, et ce qui va suivre
La tendance la plus importante dans ce domaine actuellement est la fusion des trois catégories. Le consensus sous-jacent est : les connaissances nécessaires pour rendre un monde, le simuler et y agir sont en grande partie les mêmes. Reprenant l'exemple précédent, un modèle qui comprend réellement comment une tasse repose sur une table (sa forme géométrique, ses attributs matériels, sa réponse aux forces, etc.) devrait être capable de rendre cette tasse sous n'importe quel angle, de simuler ce qui se passe si la tasse est poussée, et de planifier le mouvement d'une main pour la saisir. Les trois catégories sont trois projections d'une même compréhension sous-jacente.
Par exemple, il y a eu récemment un petit nombre croissant de travaux émanant de différents laboratoires de robotique, montrant une possibilité au moins conceptuellement viable : un moteur de rendu vidéo pré-entraîné peut servir de réseau de base pour la prédiction conjointe du monde et des actions, permettant à un modèle unique d'imaginer à la fois "ce qui va se passer" et "ce qu'il faut faire", établissant ainsi un pont entre le moteur de rendu et le planificateur. Marble de World Labs peut déjà produire simultanément des "Gaussian splats" et des maillages de collision à partir d'un seul modèle, effaçant la frontière entre moteur de rendu et simulateur. À chaque niveau, on passe d'une sortie passive à des systèmes interactifs : les moteurs de rendu deviennent conditionnés par des actions, les mondes générés par les simulateurs deviennent plus contrôlables et modifiables, les planificateurs commencent à raisonner de manière délibérée plutôt que de simplement réagir.
Le point d'arrivée logique est un modèle du monde unifié : un modèle de base capable de rendre des vues photoréalistes, de générer des structures physiquement exactes, de planifier des séquences d'actions, et de basculer entre ces modalités de sortie en fonction des besoins de l'utilisateur final. Nous ferons face à une série de défis redoutables. Le paysage des données est extrêmement déséquilibré, les moteurs de rendu disposant d'une abondance de vidéos Internet, tandis que les simulateurs et planificateurs souffrent d'une grave pénurie de données d'actifs 3D et de démonstrations robotiques. L'optimisation pour l'esthétique visuelle peut sacrifier la précision nécessaire à la robotique ou à la simulation haute fidélité. Réconcilier ces tensions au sein d'une architecture unique est le problème ouvert central de la recherche actuelle sur les modèles du monde, et celui que World Labs s'efforce de résoudre en faisant évoluer continuellement Marble.
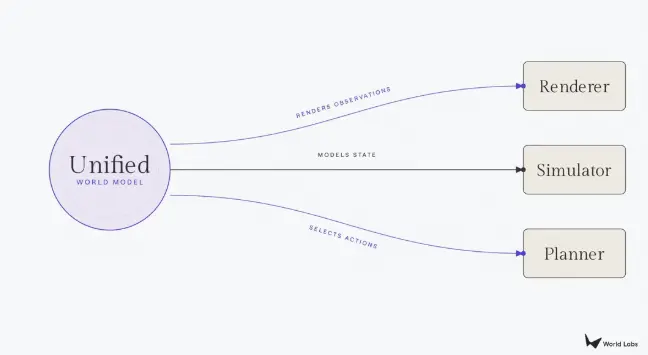
(Source : Substack)
Mais la grande direction est déjà claire. Depuis la fin des années 1980 jusqu'à aujourd'hui, le pari du domaine a toujours été le même : si le modèle du monde est suffisamment riche, alors tout ce dont un agent a besoin pour voir le monde, le construire et y agir s'y trouve. Ce pari guide désormais une génération entière de recherche. Et ce qui lui donne véritablement de la substance, c'est la fusion déjà en cours : les trois lignes de rendu, simulation et planification, chacune soutenant déjà des industries de plusieurs milliards de dollars, étaient à l'origine des axes de recherche indépendants, et commencent maintenant à converger. Lorsque les frontières disparaissent, la confluence des trois redéfinira quelque chose de plus grand : la relation entre l'intelligence des machines et le monde physique qu'elles habitent, c'est-à-dire la trajectoire à long terme de l'intelligence spatiale.
Le langage a donné aux machines un moyen de parler de ce monde. Les modèles du monde sont le chemin par lequel les machines pourront finalement comprendre, imaginer, raisonner et interagir avec lui.
Références : 1.https://drfeifei.substack.com/p/a-functional-taxonomy-of-world-models







