Autor: Wang Jianshuo
El 6 de marzo de 2023, poco después del lanzamiento de ChatGPT y antes del lanzamiento de GPT-4, Sarah y yo realizamos una entrevista sobre ChatGPT: el tercer episodio de la serie 'Plain Talk' de Traders' Talk (El podcast 'Plain Talk sobre ChatGPT' ya está publicado, ¡bienvenidos a escuchar!).
En ese entonces, ChatGPT acababa de salir, y muy poca gente lo había usado realmente. Esa entrevista de tres horas se mantuvo en el primer lugar de la categoría ChatGPT en XiaoYuZhou. En ella, lancé una veintena de juicios y predicciones, basados puramente en la intuición y en información limitada, sin muchos datos. La transcripción completa de esa entrevista aún permanece en la cuenta pública.
Ahora estamos a finales de mayo de 2026, han pasado tres años, y la IA ha crecido hasta alcanzar una forma que antes era inimaginable.
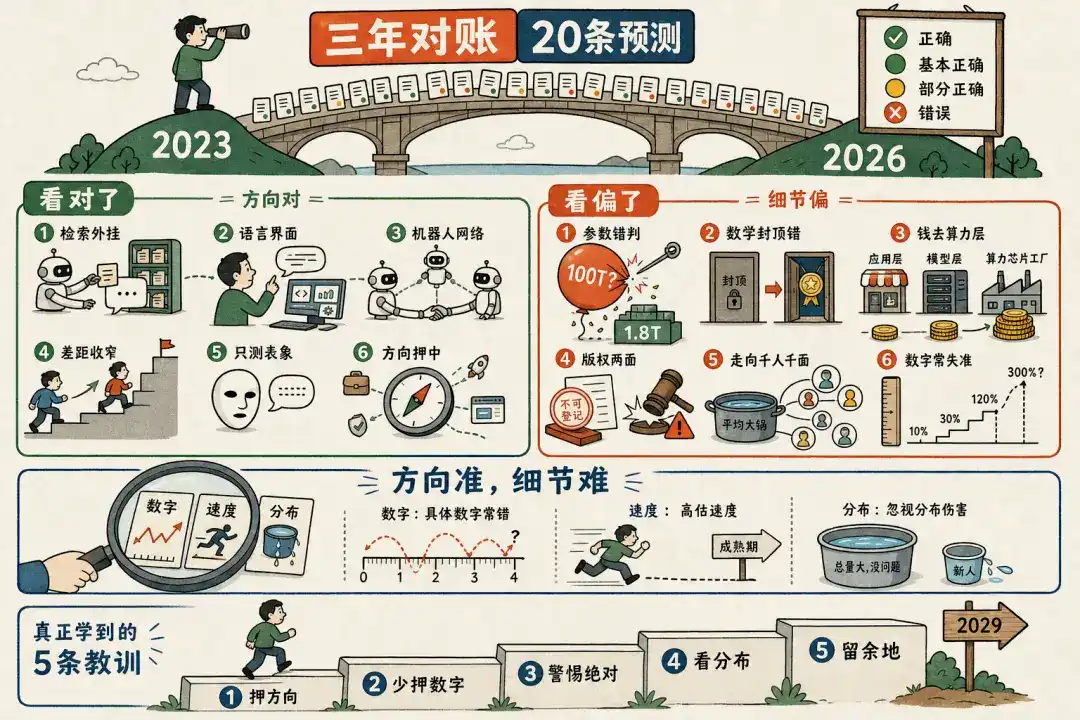
Quiero hacer algo: sacar esas veinte afirmaciones una por una, y utilizando los datos más recientes disponibles hoy, hacer una verificación objetiva de cada una. Para ver claramente en qué se ha convertido el mundo en estos tres años, y también para ver claramente en qué acertó y en qué se equivocó aquel 'yo' de hace tres años.
Para tratar de ser lo más imparcial posible, esta vez decidí dejar que la IA hiciera la verificación: introduje la transcripción de la entrevista original en un flujo de trabajo, el cual dirigió a 41 agentes Opus 4.8 para que primero desglosaran las veinte afirmaciones, luego investigaran en línea para obtener los datos más recientes y verificaran cada una de forma cruzada, y finalmente calificaran a Wang Jianshuo de hace tres años. Estos agentes gastaron unos 20 minutos, consumiendo 1.4 millones de tokens (aproximadamente 35 dólares), y generaron el siguiente informe. Los juicios provienen de ellos, no de mí. La fecha de referencia se establece en mayo de 2026.
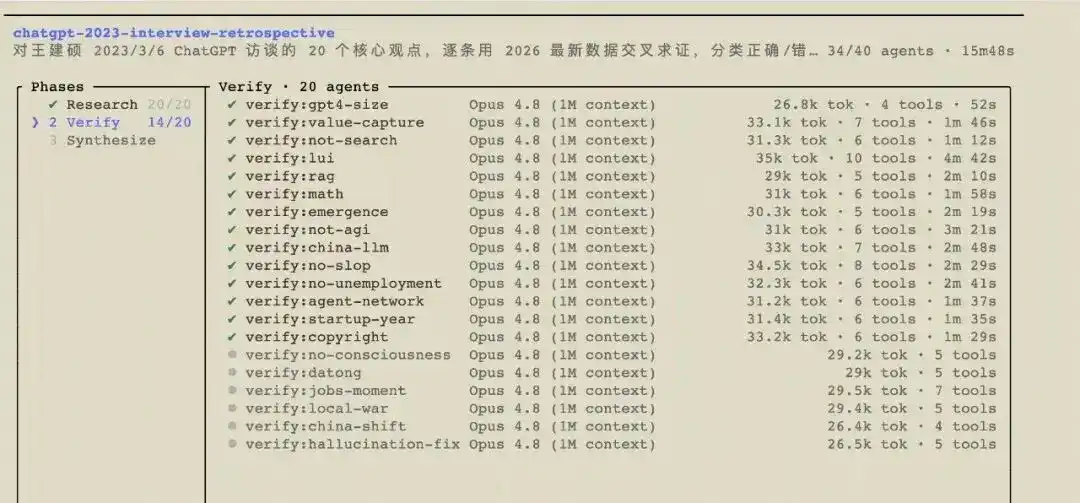
一、El marcador
Símbolos de veredicto: ✅ Correcto · 🟢 Básicamente correcto · 🟡 Parcialmente correcto · ❌ Incorrecto
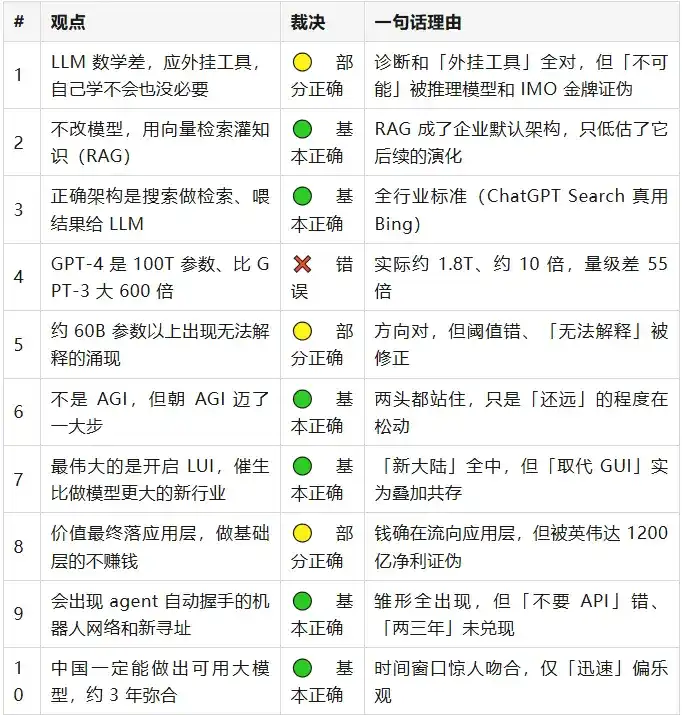
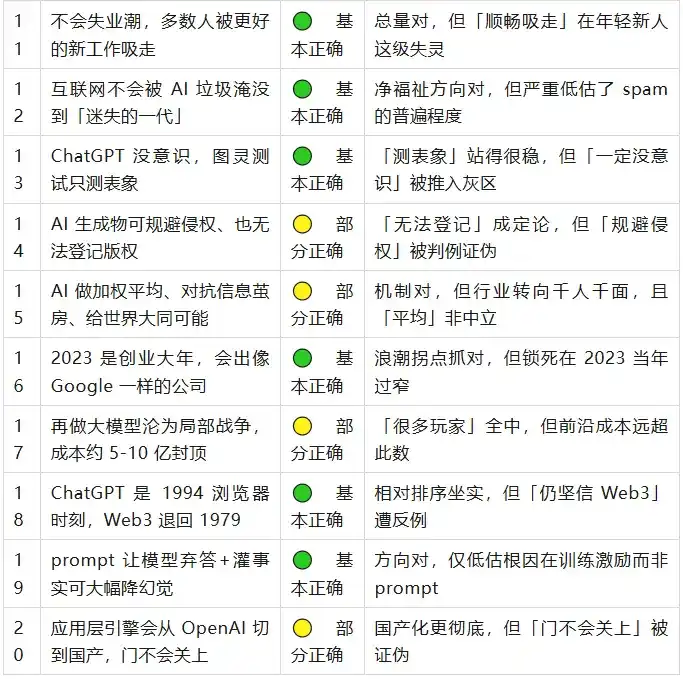
En una vista general, las grandes direcciones que Wang Jianshuo señaló en su mayoría se sostuvieron. Realmente solo hubo un error contundente: difundir que GPT-4 tenía 100T de parámetros. Pero el diablo está en los detalles: detrás de casi cada acierto, hay una cola de algo que no se dijo con precisión. Ninguna de las veinte afirmaciones es puramente "aún incierta"; tres años es tiempo suficiente para que la mayoría de las cosas tengan una respuesta tendenciosa. Hablemos en detalle por grupos a continuación.
二、Los que acertó
Lo común en este grupo es que Wang Jianshuo acertó en la dirección, el mecanismo e incluso el ritmo temporal de sus juicios de entonces; sus errores solo están en el "grado" y en las "expresiones absolutas".
RAG y arquitectura de recuperación (Puntos 2 y 3)
> En 2023, Wang Jianshuo dijo: El método principal para resolver el conocimiento y las alucinaciones no es modificar el modelo, sino inyectar conocimiento a través de recuperación vectorial como "chuleta"; la arquitectura correcta es que el motor de búsqueda haga la recuperación y alimente los resultados al LLM.
Este es el estándar de facto actual para todos los productos de IA. RAG se ha convertido en la arquitectura predeterminada para la IA empresarial; OpenAI, Google, Anthropic la han convertido en una capacidad a nivel de plataforma; ChatGPT Search es literalmente "primero indexar y recuperar con Bing, alimentar los resultados a GPT, y luego generar respuestas con citas". Google AI Overviews utiliza 'grounding' y alcanza unos 2 mil millones de usuarios activos mensuales; Perplexity, una empresa basada puramente en esta arquitectura, tiene una valoración que ha superado los 20 mil millones de dólares.
En una época en que GPT-4 aún no se había lanzado y la industria asumía por defecto "inyectar conocimiento mediante fine-tuning", él apostó por "no tocar los parámetros del modelo, recuperación externa", acertando en el mecanismo y el momento.
Para ser honesto: él imaginaba una "recuperación estática de una sola vez", pero la realidad es más compleja: contexto largo, GraphRAG, recuperación agentic han venido a fortalecerla. El debate de 2026 sobre "RAG está muerto" prueba precisamente que la dirección principal no ha muerto; lo que se negaba era la "recuperación simple de una sola vez", y la conclusión fue mejorarla con recuperación híbrida, no retroceder a modificar parámetros del modelo. Otro punto: el término RAG ya se propuso en un artículo de Meta en 2020, no fue su creación original; simplemente acertó en que se volvería dominante durante la ventana de oportunidad.
LUI es un nuevo continente (Punto 7)
> En 2023, Wang Jianshuo dijo: Lo más grandioso de ChatGPT no es la AIGC, sino haber iniciado la LUI (Interfaz de Usuario de Lenguaje Natural), que reconstruirá la interacción persona-computadora como lo hizo la GUI en su día, y dará lugar a una nueva industria mucho mayor que la de "hacer grandes modelos".
La parte del "nuevo continente" es casi un acierto completo. El lenguaje natural se ha convertido en la capa de interacción dominante para el público (ChatGPT tiene 900 millones de usuarios activos semanales), y ha dado lugar a una nueva industria independiente: agentes, agentes de codificación, la capa de protocolo, todo se ha cumplido. La afirmación más concreta "mucho más grande que hacer modelos" se ha confirmado con fuerza: el protocolo MCP se ha convertido en el "estándar del sistema operativo" de la era LUI, fue adoptado ampliamente por OpenAI, Google y Microsoft en 2025, y a finales de año pasó a la Linux Foundation; Claude Code, un solo producto, alcanzó unos 2.5 mil millones de dólares en ingresos anualizados.
Pero usó expresiones fuertes como "reconstruir, reemplazar la GUI", y tres años después vemos que es una superposición y coexistencia, no un reemplazo. Hay tres tipos de contraejemplos sólidos: un informe del MIT muestra que el 95% de las pruebas piloto de GenAI empresarial no tienen un ROI medible; los agentes de 'computer-use' que operan interfaces directamente solo alcanzan alrededor del 78% en conjuntos de prueba con los mejores modelos, apenas rozando la línea base humana; el hardware de lenguaje puro sin pantalla ha fracasado casi por completo (Humane Pin cesó su servicio permanentemente en 2025). Una formulación más precisa sería: LUI es una nueva capa de interacción superpuesta a la GUI.
Red de robots y nueva dirección (Punto 9)
> En 2023, Wang Jianshuo dijo: En aproximadamente una década, aparecerá una "red de robots": agentes que se comuniquen automáticamente en lenguaje natural y se invoquen mutuamente, sin necesidad de APIs tradicionales; surgirá un sistema de direccionamiento de dominios completamente nuevo. Esta cosa "podría completarse en dos o tres años".
La dirección acertó de manera sorprendente. MCP, A2A (donada a Linux Foundation, con apoyo de más de 150 organizaciones) resuelven la invocación mutua entre agentes; el Agent Network Protocol se basa directamente en DID del W3C para el "direccionamiento de agentes sin autoridad central", con el objetivo de una "red colaborativa de miles de millones de agentes". Esto es altamente isomorfo a su "nuevo sistema de dominios".
Dos puntos a corregir: primero, "sin necesidad de API" no es cierto, los protocolos principales subyacentes tienen esquemas estructurados, esencialmente una capa estándar sobre las APIs; segundo, "completarse en dos o tres años" no se cumplió, datos de Gartner muestran que hasta 2026 solo alrededor del 17% de las organizaciones han desplegado agentes realmente. Es interesante que en realidad él estratificó su predicción en su momento: el prototipo en "dos o tres años", la madurez en "aproximadamente diez años". Acertó muy bien el ritmo del prototipo, y el ciclo de madurez sí es de nivel de década. Viéndolo por separado, la calidad de esta afirmación es más alta de lo que parece.
China definitivamente podrá crear grandes modelos utilizables (Puntos 10 y 20)
> En 2023, Wang Jianshuo dijo: China definitivamente podrá crear grandes modelos utilizables, y la brecha con los mejores se cerrará rápidamente en unos tres años (similar a cómo el navegador Red Flag persiguió a Netscape).
La línea de tiempo de esta afirmación coincide de manera inesperada. El AI Index de Stanford 2026 mide que la brecha de referencia entre los mejores modelos de China y EE.UU. se redujo desde un 17.5–31.6 por ciento en mayo de 2023 hasta 2.7%; mientras que la inversión privada en IA en EE.UU. es aproximadamente 23 veces mayor que en China: se logró la convergencia con una inversión mucho menor. DeepSeek, Qwen, Kimi, GLM se han vuelto parte de la corriente principal global, y el ecosistema de código abierto incluso lidera.
Pero la palabra "rápidamente" fue optimista: la verdadera madurez ocurrió alrededor de 14 meses después, no en "unos meses". Y esto es igualar la usabilidad, no definir la frontera: a principios de 2026, aún ningún modelo chino superaba al OpenAI o3. En el punto 20, se equivocó claramente: su juicio de que "una vez abierta la puerta, no se cerrará" fue directamente refutado cuando OpenAI cortó activamente su API para China en julio de 2024; la puerta fue cerrada por el proveedor. Además, Ernie Bot, que él nombró como líder, se quedó atrás, y quienes realmente tomaron el relevo fueron DeepSeek, Doubao, Qianwen, que en ese entonces eran poco conocidos.
Sin conciencia, la prueba de Turing solo mide la apariencia (Punto 13)
> En 2023, Wang Jianshuo dijo: ChatGPT no tiene conciencia, es una "autoconmiseración donde el hablante no tiene intención y el oyente tiene demasiado corazón"; la prueba de Turing solo prueba "si te hace pensar que la tiene", no si realmente la tiene.
El juicio central de "probar la apariencia" se sostiene firmemente, y fue corroborado irónicamente por un experimento: en una prueba de Turing de UC San Diego en 2025, GPT-4.5, bajo instrucciones para "interpretar un personaje", fue juzgado como humano en un 73%, más alto que personas reales, pero solo mediante habilidades interpretativas: la mejor anotación para "solo prueba si te hace pensar que la tiene".
Lo que hay que añadir: la afirmación fuerte y absoluta de que "la máquina definitivamente no tiene conciencia" se ha convertido en una zona gris en estos tres años. Anthropic estableció un puesto de investigación en "bienestar del modelo", asignando una probabilidad de conciencia de aproximadamente 15-20%, y añadió a Claude la función de "terminar activamente conversaciones abusivas". Todo esto ha cambiado el "absolutamente no" a "baja probabilidad pero no se puede excluir". Sin embargo, se basa en "posible, debería asumirse" y no en "confirmado". El núcleo no fue refutado, solo que su tono fue demasiado rotundo en su momento.
Los demás aciertos (Puntos 6, 11, 12, 16, 18, 19)
- No es AGI pero es un gran paso
: Ambas partes se sostienen. El propio Altman en la era GPT-5 aún dice "no es AGI, carece de aprendizaje continuo"; al mismo tiempo, las medallas de oro en la IMO y ARC-AGI pasaron de casi cero al 85%, "un gran paso adelante" es indiscutible. - No habrá una ola de desempleo
: En abril de 2026, la tasa de desempleo en EE.UU. fue solo del 4.3%. El punto ciego está en la "distribución": un estudio de Stanford muestra que los afectados son precisamente los jóvenes de 22-25 años en el primer peldaño de la escalera profesional; el mecanismo de "absorción fluida" falla para ellos. - No nos ahogaremos en basura de IA
: La dirección del beneficio neto es correcta, pero subestimó gravemente la magnitud: el contenido de IA ya representa aproximadamente el 52% de las nuevas páginas web, "AI slop" se convirtió en la palabra del año. - Un gran año para emprender
: Acertó el punto de inflexión de la ola, xAI (fundada en marzo de 2023) alcanzó una valoración de 230 mil millones. Pero confinó "empresas grandiosas" a 2023, demasiado estrecho: OpenAI y Anthropic, verdaderamente del orden del billón de dólares, se fundaron antes. - El momento del navegador de 1994
: Se confirmó el orden relativo. OpenAI realmente lanzó Atlas Browser en 2025, convirtiendo la metáfora en realidad literal. Solo que ChatGPT se difundió más rápido que los navegadores, la metáfora fue conservadora. - El prompt más la inyección de hechos reduce las alucinaciones
: La dirección se confirmó. GPT-5 sin conexión y sin recuperación tiene una tasa de alucinación del 47%, confirmando inversamente que los "hechos" son una variable clave. Solo subestimó que la causa raíz está en los incentivos de entrenamiento, no en el prompt.
三、Los que se equivocó o desvió
GPT-4 tiene 100T parámetros (Punto 4) — Completamente incorrecto
> En 2023, Wang Jianshuo dijo: (Rumor) GPT-4 tiene 100T parámetros, aproximadamente 600 veces más que los 175B de GPT-3.
Ambos números están equivocados. GPT-3 tiene 175B, la mejor estimación filtrada en julio de 2023 es que GPT-4 tiene aproximadamente 1.8T, MoE con 16 expertos, solo unas 10 veces más. 100T difiere de la realidad en aproximadamente 55 órdenes de magnitud. La única fuente de "100T" fue una cita de segunda mano aproximadamente del CEO de Cerebras en 2021; Sam Altman ya desmintió esa gráfica de comparación como "complete bullshit" en enero de 2023.
En su momento, calificó su declaración como "rumor", conservando incertidumbre. A un nivel más profundo, el marco de "usar múltiplos de parámetros para medir generaciones" está desactualizado: OpenAI posteriormente con GPT-4.5, GPT-5 simplemente dejó de publicar el número de parámetros. Este es el único error duro: número equivocado y perspectiva desfasada.
Matemáticas en LLM (Punto 1) — Diagnóstico correcto, conclusión categórica incorrecta
> En 2023, Wang Jianshuo dijo: Las matemáticas deficientes de los LLM son inherentes; que aprendan matemáticas por sí mismos es tanto imposible como innecesario; la forma correcta es usar herramientas externas.
"Diagnóstico más enfoque con herramientas" es completamente correcto: la causa raíz es que la generación token por token conlleva una falta de fiabilidad en el acarreo (un documento de mecanismo de 2025 confirmó precisamente la intuición de "últimos dígitos a menudo correctos, dígitos intermedios erróneos"); la mejora con herramientas externas también es enorme (o4-mini, cuando se permite usar Python, alcanza 99.5% en AIME 2025).
El error está en las expresiones categóricas "imposible, innecesario". "Imposible" fue refutado: en julio de 2025, Gemini Deep Think y modelos de OpenAI ganaron medallas de oro en la IMO usando solo lenguaje natural, sin herramientas. El punto de inflexión clave fue la aparición de los "modelos de razonamiento" en 2024-2025, algo impredecible en marzo de 2023. Por lo tanto, esta predicción debe juzgarse con indulgencia por su dirección, no con severidad por el momento.
Captura de valor (Punto 8) — Acertó la mitad, la afirmación central es la contraria
> En 2023, Wang Jianshuo dijo: El valor finalmente recaerá en la capa de aplicación; las empresas que crean la capa base (los que hacen modelos) no necesariamente terminarán ganando dinero.
El dinero realmente ha comenzado a fluir hacia la capa de aplicación (Cursor alcanzó 2 mil millones de ingresos anualizados en tres años): eso está medio acertado. Pero "los que hacen la capa base no ganan dinero" fue refutado directamente por NVIDIA: beneficio neto FY2026 ~120 mil millones de dólares, capitalización de mercado 5 billones+, es el único actor del mercado con beneficios claramente grandes. Y la capa de modelos, que él insinuó que ganaría (OpenAI proyectaba pérdidas de ~14 mil millones en 2026) es la que más se parece a su "capa base que quema dinero sin ganar".
No distinguió entre "capa base de potencia de cómputo" y "capa base de modelos", ni entre "ingresos" y "beneficios". El valor en 2026 está capturado de manera más extrema por la capa de potencia de cómputo que en 2023, no trasladándose a la capa de aplicación. Hay que añadir: quienes pierden dinero son los proveedores de nube que compran chips, no NVIDIA que los vende: precisamente el desajuste de su analogía de "sobreconstrucción ferroviaria".
Derechos de autor (Punto 14) — Acertó el registro, se equivocó en eludir la infracción
> En 2023, Wang Jianshuo dijo: El contenido generado por IA podría eludir los derechos de autor (protegen la expresión, no la idea); el producto generado podría no infringir derechos, pero tampoco poder registrarse.
"No poder registrarse" se convirtió en un hecho legal establecido (en 2025, la Oficina de Derechos de Autor de EE.UU. aclaró que "solo ingresar palabras clave (prompt) no es suficiente para reclamar autoría"). Pero "eludir la infracción" está claramente equivocado: los tribunales han determinado repetidamente que si la salida de IA es sustancialmente similar a la obra original, constituye infracción; Anthropic llegó a un acuerdo de 1.5 mil millones de dólares por corpus de capacitación pirata, la mayor compensación por derechos de autor en la historia de EE.UU. La IA no "eludió" los derechos de autor, sino que pagó el precio más alto de la historia.
Armonía mundial (Punto 15) — Mecanismo correcto, tendencia opuesta
> En 2023, Wang Jianshuo dijo: ChatGPT hace un "promedio ponderado" de los puntos de vista humanos, puede combatir las cámaras de eco tipo TikTok, y da la posibilidad de una "armonía mundial".
En el nivel de mecanismo acertó: múltiples estudios en 2025 confirmaron que los LLM comprimen los puntos de vista hacia la moda, subestimando sistemáticamente a las minorías. Pero la predicción social fue opuesta: él mismo añadió "al menos por ahora no es personalizado", lo cual fue refutado en tres años: OpenAI desde abril de 2025 hizo la memoria entre conversaciones y la personalización capacidades predeterminadas; la IA está avanzando rápidamente hacia la personalización. Más crucialmente, imaginó el "promedio ponderado" como un consenso mundial neutral, pero las pruebas muestran que es un sesgo direccional, además de sumisión, y puede usarse para manipular activamente posturas: esto apunta a "crear nuevas cámaras de eco", no a "disolver la polarización".
Guerras locales y costos (Punto 17) — Cualitativo completamente correcto, cuantitativo refutado
> En 2023, Wang Jianshuo dijo: Hacer grandes modelos se convertirá rápidamente en "guerras locales", el costo es conocido (eliminando desvíos, un máximo de 5-10 mil millones de dólares), muchos actores entrarán.
La dirección cualitativa acertó sorprendentemente: muchos actores entraron, rápida comercialización, código abierto igualando al cerrado, todo se cumplió. Pero la cifra dura "5-10 mil millones máximo" está equivocada en ambos extremos: el extremo de vanguardia fue subestimado gravemente (nivel GPT-5 en 2026 alcanza 2-5 mil millones de dólares de entrenamiento, más centros de datos de cientos de miles de millones y el Stargate de 500 mil millones); el extremo de réplica fue sobreestimado (DeepSeek redujo el costo marginal de entrenamiento al nivel del millón de dólares). El "costo" del mismo modelo puede diferir 200 veces dependiendo de la definición, pero no en el intervalo que él dio.
Capacidades emergentes (Punto 5) — Dirección correcta, números y delimitación incorrectos
> En 2023, Wang Jianshuo dijo: Por encima de ~60B de parámetros aparecen nuevas capacidades que no estaban en el corpus original y que los investigadores tampoco pueden explicar.
La intuición direccional es válida, pero dos formulaciones no se sostienen: primero, no existe un "umbral de 60B" unificado: el umbral real para la cadena de pensamiento es ~100B, diferentes capacidades emergen en escalas que van desde 13B hasta 540B; segundo, "inexplicable" fue desafiado a finales de 2023 por un documento NeurIPS destacado: muchas "mutaciones" son ilusiones causadas por la elección de métricas de evaluación, las curvas se suavizan y son predecibles con métricas continuas. Para ser justos, en su momento estaba repitiendo la narrativa absolutamente dominante; lo que realmente se puede corregir es tomar "60B" como un umbral duro y "inexplicable" como una conclusión cualitativa.
四、Mirando atrás tres años, algunos patrones
Después de verificar cada afirmación, alejándonos un paso, estos veinte juicios de Wang Jianshuo esconden algunos patrones que vale más recordar que cualquier afirmación individual.
一、La dirección es mucho más confiable que los números y el grado. De las veinte afirmaciones, todas las que juzgaban mecanismos y direcciones (RAG, LUI, red de robots, prueba de Turing) acertaron casi por completo; todas las que dieron números específicos o expresiones categóricas (100T parámetros, umbral de 60B, costo de 5-10 mil millones, matemáticas "imposible") fallaron casi por completo. Para campos que cambian rápidamente, apuesta por la dirección, por el mecanismo, menos por números precisos, y ten cuidado con palabras como "imposible, definitivamente, máximo, absolutamente no": son zonas de alto riesgo para recibir una bofetada del tiempo.
二、En cuanto al tiempo, tiende a sobreestimar la velocidad y subestimar el grado. Todas las que decían "rápidamente, completarse en dos o tres años" tuvieron un periodo de maduración más lento; pero subestimó el techo del salto de capacidades: las matemáticas pasaron de "imposibles" a medallas de oro en la IMO, los costos de vanguardia pueden aumentar a magnitudes inimaginables entonces. En una frase: demasiado optimista a corto plazo, demasiado conservador a largo plazo.
三、El error más oculto aparece repetidamente en la "distribución". No es un error de dirección, sino ver solo el total, ignorando la distribución. "No habrá una ola de desempleo" es correcto, pero el daño se concentra altamente en jóvenes principiantes; "el valor cae en la capa de aplicación" acertó a medias, pero no distinguió entre la capa de potencia de cómputo y la capa de modelos. Total correcto, encubre una catástrofe de distribución: esta es la lección más importante que aprender.
四、Donde dejó margen, tres años después resiste la prueba. "Rumor", "al menos por ahora", "reduce significativamente en lugar de eliminar", "prototipo en dos o tres años, madurez en aproximadamente diez años": todos los juicios que tenían calificativos o estaban estratificados en su momento, hoy se sostienen mejor. Por el contrario, las frases absolutas lanzadas sin pensar son las que más fácilmente se dan un vuelco. La honestidad de una predicción está mitad en atreverse a decir, mitad en atreverse a marcar la propia incertidumbre.
五、Algunos problemas, tres años no son suficientes. ¿A quién pertenece finalmente el valor? ¿La emergencia es un cambio de verdad? ¿Tiene la máquina aunque sea un ápice de conciencia? ¿El contexto largo se comerá a RAG? Estos debates de entonces, para 2026 siguen siendo debates. Poder distinguir entre "lo que ya tiene respuesta" y "lo que aún hay que esperar" es más importante que apresurarse a sacar conclusiones sobre todo.
El Wang Jianshuo de hace tres años, basándose en la intuición, señaló veinte direcciones en la niebla antes de que saliera GPT-4. Hoy, después de la verificación, quizás la frase más importante para recordar es: acertar la dirección general en realidad no es tan difícil, lo difícil es admitir que una y otra vez se dio por sentado en números, velocidad y distribución. Estas veinte cuentas, más que calificar el pasado, son establecer algunas reglas para los próximos tres años. En otros tres años, volvamos a verificarlo en 2029.