La restricción de la potencia de cálculo
Desde finales del año pasado, empresas chinas de GPU como Moore Thread, MetaX, Biren Technology y Enflame Technology han desatado una ola de entusiasmo en el capital. Sin embargo, bajo este festín de riqueza en el mercado secundario, una línea oscura que no se puede ignorar se está volviendo cada vez más clara, y los problemas que plantea también se vuelven más apremiantes.
En los últimos años, los chips de IA chinos se han concentrado principalmente en el lado de la "inferencia", que es relativamente seguro y periférico. Por ejemplo, recientemente Doubao planea comprar 50.000 chips de Enflame Technology para tareas de inferencia, satisfaciendo así las frecuentes llamadas de esta aplicación de IA más grande de China.
En cuanto al entrenamiento de IA, que representa la cúspide de la pirámide de la potencia de cálculo, los chips chinos actualmente solo pueden participar en tareas "secundarias" en los bordes.
Los chips de entrenamiento de IA se utilizan principalmente para entrenar modelos de inteligencia artificial, realizando una gran cantidad de operaciones matriciales y ajustes de parámetros durante el proceso. Por lo tanto, requieren una gran capacidad de cálculo y una alta eficiencia energética. Son más potentes y también más caros, como las series A100, H100, H200 de Nvidia y la serie MI300 de AMD.
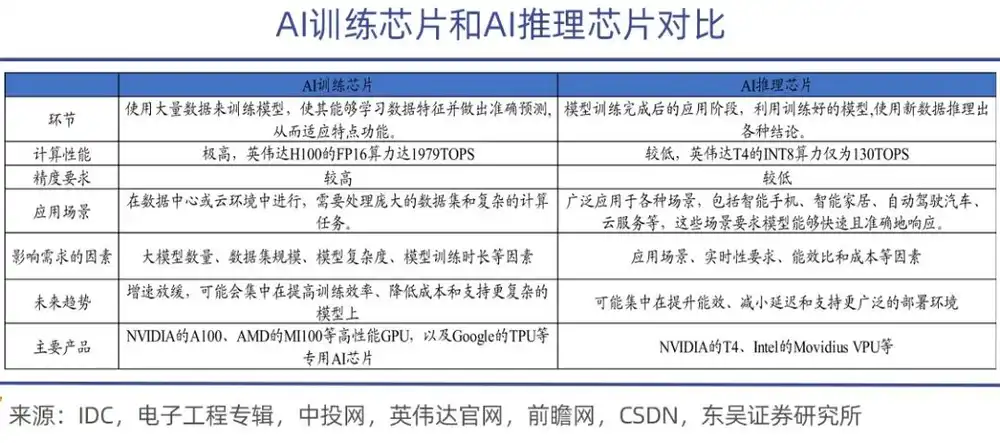
En comparación, la tarea de los chips de inferencia es mucho más ligera. Se utilizan en la fase de despliegue una vez completado el entrenamiento del modelo, principalmente para ejecutar tareas de inferencia del modelo. Tienen altos requisitos de tiempo real, por lo que deben garantizar precisión, respuesta rápida y bajo consumo energético.
Una metáfora apropiada es que el entrenamiento es "enseñar conocimientos" al modelo de IA, mientras que la inferencia es "aplicar conocimientos" por parte del modelo grande. En la fase de aprendizaje, el chip de entrenamiento debe utilizar datos masivos para "alimentar" actualizaciones dinámicas de parámetros de miles de millones, billones o incluso diez billones. No solo requiere una potencia de cálculo formidable, sino también un ancho de banda y capacidad de comunicación eficientes, además de garantizar la estabilidad en clústeres de decenas de miles de tarjetas.
La raíz de la brecha entre los modelos chinos y estadounidenses reside precisamente en estos "aspectos invisibles", especialmente en la ausencia de chips de entrenamiento de alta gama.
Bajo la ley de escalamiento (Scaling Law) de los modelos grandes, cuanto mayores son los parámetros del modelo, mayor es la demanda de potencia de cálculo, creciendo linealmente. La expansión exponencial de la potencia de cálculo y los costos de hardware hacen del entrenamiento de modelos grandes un "juego exclusivo" de unas pocas gigantes tecnológicas.
Entre las empresas tecnológicas estadounidenses, solo Meta planea desplegar más de 1.2 millones de GPU de alta gama para finales de 2026, con una inversión anual superior a 145 mil millones de dólares. Según cálculos, la potencia total de IA de Google equivale a 5 millones de Nvidia H100, representando una cuarta parte de la capacidad global total de una sola empresa.
Amazon, Microsoft, Alphabet y Meta tienen previsto un gasto de capital este año de 725 mil millones de dólares, un aumento del 77% interanual. Esta magnitud equivale al 13% de la inversión privada interna total anual de Estados Unidos. Morgan Stanley predice que para 2027, el gasto de capital de las empresas tecnológicas estadounidenses podría alcanzar el récord histórico de 1.1 billones de dólares.
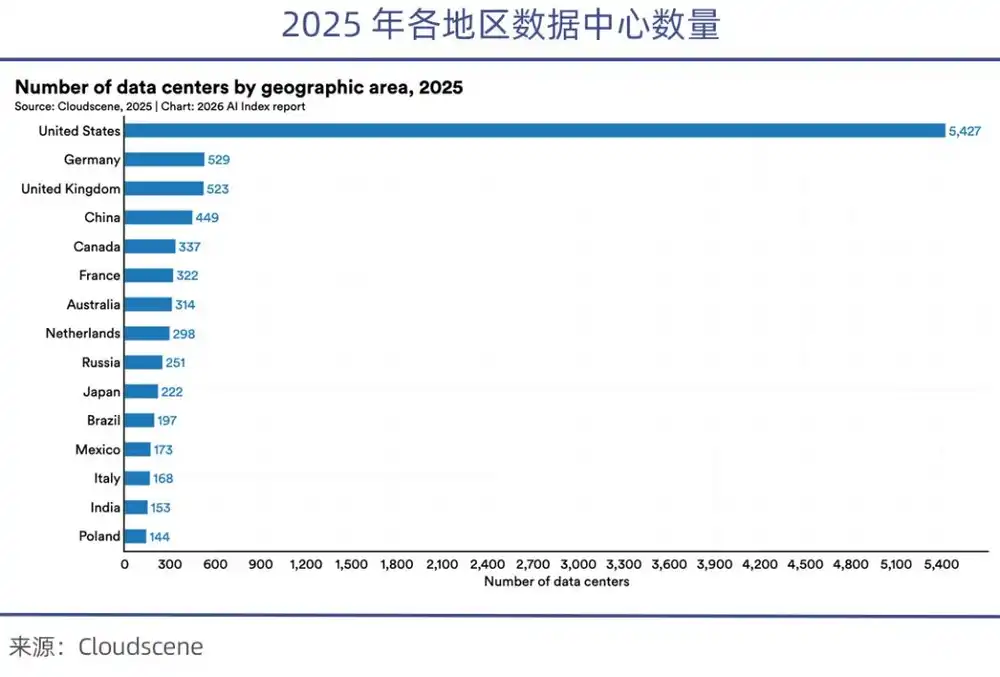
Actualmente, Estados Unidos controla más del 70% de las GPU de alta gama a nivel mundial. Después de la prohibición de chips, China solo tiene acceso a una octava parte de los chips de alta gama disponibles en EE.UU. El Informe de Índice de IA de Stanford 2026 señala que el número de centros de datos en Estados Unidos (5,427) es más de 10 veces mayor que el de China.
Según cálculos del Instituto de Investigación de la Industria de la Información y las Comunicaciones de China (CAICT), a principios de 2025, la escala de potencia de cálculo de Estados Unidos era de 2400 EFLOPS, mientras que la de China era de 1053 EFLOPS. Estados Unidos tiene más del doble que China.
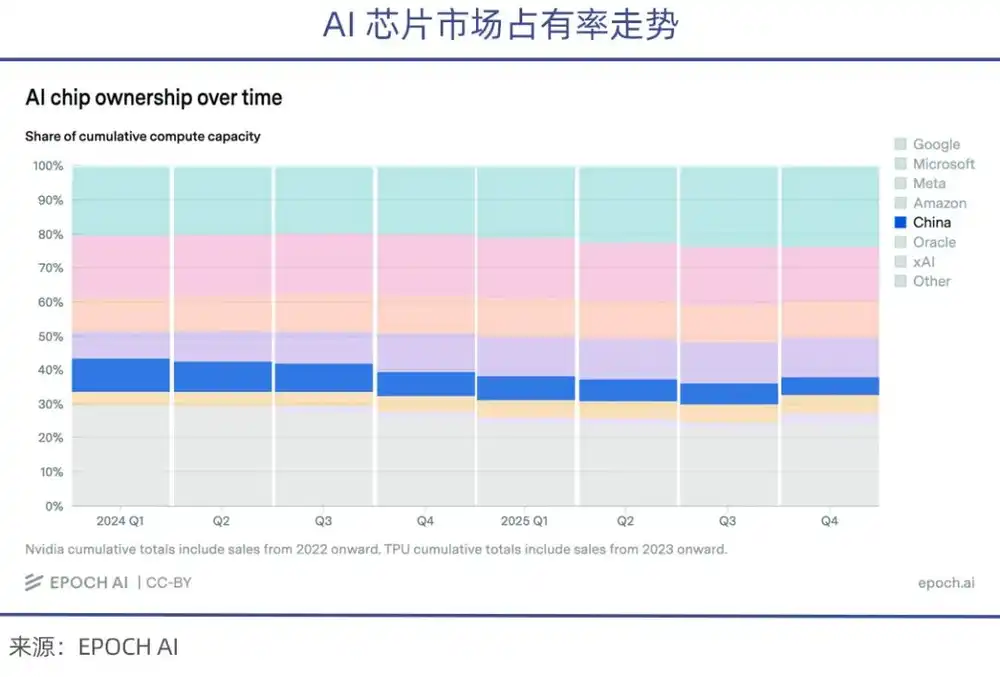
La escala de potencia de cálculo de las cuatro gigantes tecnológicas mencionadas, cada una por separado, ya supera la suma de todas las empresas de IA de China.
Esta ventaja aplastante en potencia de cálculo permite a las empresas estadounidenses completar más de una docena de iteraciones de experimentos con modelos grandes en un año.
Musk es aún más extravagante. Su xAI posee Colossus 2, proclamado como el "primer clúster de IA de nivel GW" del mundo. Por ello, tiene la confianza de afirmar que está entrenando simultáneamente 7 modelos: dos de 1 billón, dos de 1.5 billones, uno de 6 billones y uno de 10 billones de parámetros. Esta "estética de la fuerza bruta" solo es posible cuando la potencia de cálculo es extremadamente abundante.

Al mismo tiempo, debido a las restricciones estadounidenses a la exportación de chips, la participación de las empresas chinas en los chips de IA de alta gama enviados en los últimos años ha seguido disminuyendo (según estadísticas de epoch.AI).
Puede decirse sin exageración que la enorme brecha en la base de potencia de cálculo mantendrá a la IA china en una fase de seguimiento a largo plazo y dificultará aún más el proceso de que los modelos grandes chinos alcancen a sus homólogos estadounidenses.
La diferencia generacional
"El ritmo de la innovación china es imparable", "quien piense que China no puede hacer (chips), realmente se equivoca. La brecha entre China y EE.UU. es solo de nanosegundos".
Jensen Huang, fundador de Nvidia, ha elogiado en más de una ocasión en público el progreso de los semiconductores chinos.

Musk también suele expresar opiniones similares en X: "China definitivamente resolverá el problema de la restricción de chips", "en el campo de la potencia de cálculo de IA, superará con creces a todos los demás países del mundo", "China ganará la carrera de IA en la Tierra".
Los elogios excesivos de figuras prominentes de la tecnología hacia el desarrollo de la IA china son fácilmente creíbles. Estas declaraciones claramente tienen un matiz de adulación. Algunos medios estadounidenses han estado difundiendo la idea de que la brecha entre los modelos chinos y estadounidenses es muy pequeña, intentando confundir los hechos y ocultar algunas verdades objetivas.
Ante esto, todas las áreas relacionadas con la IA en China deben mantener la calma y la claridad.
Si los modelos grandes avanzados de China hoy difieren poco de sus competidores estadounidenses al resolver problemas estandarizados, la brecha se hace más evidente en entornos industriales complejos y empresariales.
En comparación con modelos de vanguardia estadounidenses como Anthropic, China sigue siendo un perseguidor. La evaluación de CAISI de EE.UU. considera que el DeepSeek V4 Pro más potente de China está unos 8 meses por detrás de la vanguardia estadounidense.
Kai-Fu Lee señaló recientemente en una entrevista con The Wall Street Journal que, tomando como referencia modelos estadounidenses de punta como Claude Fable 5 de Anthropic, EE.UU. lidera actualmente a China por aproximadamente 15 meses.

Los modelos grandes siguen la ley de escalamiento (Scaling Law). Cuantos más parámetros tenga el modelo, más datos de entrenamiento y mayor potencia de cálculo se inviertan, mejor será el rendimiento del modelo. Actualmente, los modelos grandes más avanzados de EE.UU. han entrado en la era de los diez billones de parámetros, y la velocidad de iteración sigue acelerándose.
El Mythos más potente de Anthropic ya alcanza los 10 billones de parámetros, y entrenarlo cuesta 10 mil millones de dólares. Colossus 2 de xAI está entrenando simultáneamente 7 modelos, incluidos modelos de 6 y 10 billones de parámetros. OpenAI itera un modelo de 4 billones de parámetros en solo un mes.
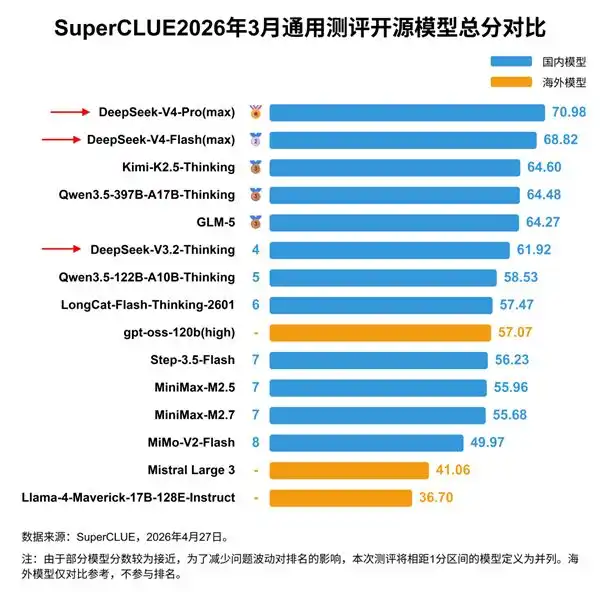
El modelo más potente de China, DeepSeek V4 Pro, tiene un total de 1.6 billones de parámetros, aproximadamente 6 veces menos que los modelos de vanguardia estadounidenses de diez billones.
La serie Claude de Anthropic ya ha sido reconocida como el modelo de IA de programación más fuerte de los últimos dos años, y Mythos ha vuelto a renovar la percepción pública, siendo aún más poderoso que su anterior buque insignia Oups 4.6.
OpenBSD es famoso en la industria por ser el sistema más seguro, pero Mythos encontró una vulnerabilidad que había pasado desapercibida durante 27 años. También encontró vulnerabilidades en FFmpeg y en el kernel de Linux que no se habían descubierto durante años o incluso más de una década, y lo hizo de forma completamente autónoma, sin depender de humanos.
Hay que tener en cuenta que el "pre-entrenamiento" del modelo grande determina el límite superior de su capacidad. No es posible ajustar un modelo de billones de parámetros mediante "post-entrenamiento" para alcanzar el nivel de un modelo de 10 billones de parámetros. El factor determinante del pre-entrenamiento son los chips de potencia de cálculo de alta gama, que determinan la escala de parámetros y la velocidad de iteración del entrenamiento.
Liu Qingfeng, presidente de iFlytek, admitió que actualmente todos los principales fabricantes de modelos grandes, especialmente los gigantes estadounidenses, están construyendo plataformas de potencia de cálculo a gran escala. La potencia de cálculo nacional china realmente enfrenta un período de dificultades, lo que ha llevado a limitaciones en el entrenamiento de contextos de texto muy largos.
Así, la brecha en la potencia de cálculo es la raíz de la diferencia entre los modelos chinos y estadounidenses.
El auge nacional
Una empresa monopoliza el 90% de la cuota de mercado mundial de chips de entrenamiento de IA de alta gama: esto ayuda a Nvidia a mantener su trono como la empresa más valiosa del mundo. Su capitalización de mercado total llegó a superar el PIB de Alemania en 2025, la tercera economía más grande del mundo.
Según datos de TrendForce, en el primer trimestre de 2026, en el mercado mundial de servidores GPU, Nvidia se llevó el 68%, AMD ocupó del 5% al 6%, y los fabricantes chinos de GPU en conjunto representaron menos del 4%.
Con ventajas de ser los primeros, fuertes barreras tecnológicas, interconexión de alta velocidad, ecosistema de software y la vinculación con los procesos avanzados de TSMC, Nvidia domina el mundo. En escenarios de entrenamiento de alta gama, el GB300 de Nvidia supera en rendimiento al MI325 de AMD y también al Siyuan 690 de Cambricon y al MTT40 de Moore Thread. Especialmente en el entrenamiento de modelos grandes de billones de parámetros, su rendimiento supera al de sus competidores en más del 30%.
Bajo las restricciones a la exportación, Jensen Huang ya había indicado que la cuota de mercado de Nvidia en China (nuevas adquisiciones) básicamente se ha reducido a cero, quedando solo el mercado existente. Con el apoyo de políticas de sustitución nacional, han surgido empresas como el Ascend 910 de Huawei, el DCU ShenSuan 2 de Hygon, el Siyuan 370/590 de Cambricon, así como Moore Thread, MetaX, entre otras.
Entre estos, el Ascend 910 es el chip de mayor potencia de cálculo de Huawei, con el Ascend 910B alcanzando 640 TOPS (INT8), comparable al chip A100 de Nvidia.
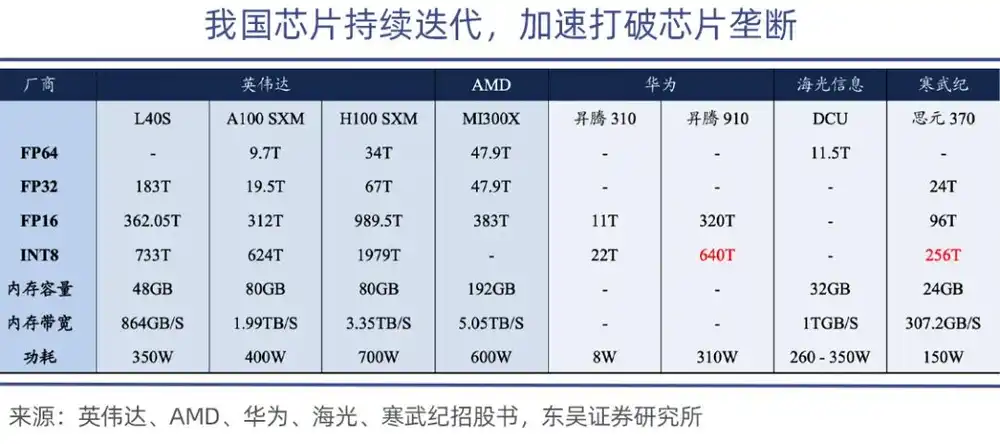
En términos de rendimiento absoluto, aunque las GPU chinas todavía tienen una brecha, pueden comenzar desde escenarios de inferencia y de borde. Actualmente, las GPU chinas básicamente satisfacen las necesidades de inferencia general de empresas e instituciones gubernamentales, reduciendo la brecha con los productos de gama media de Nvidia al 15%-20%, y son factibles para sustitución.
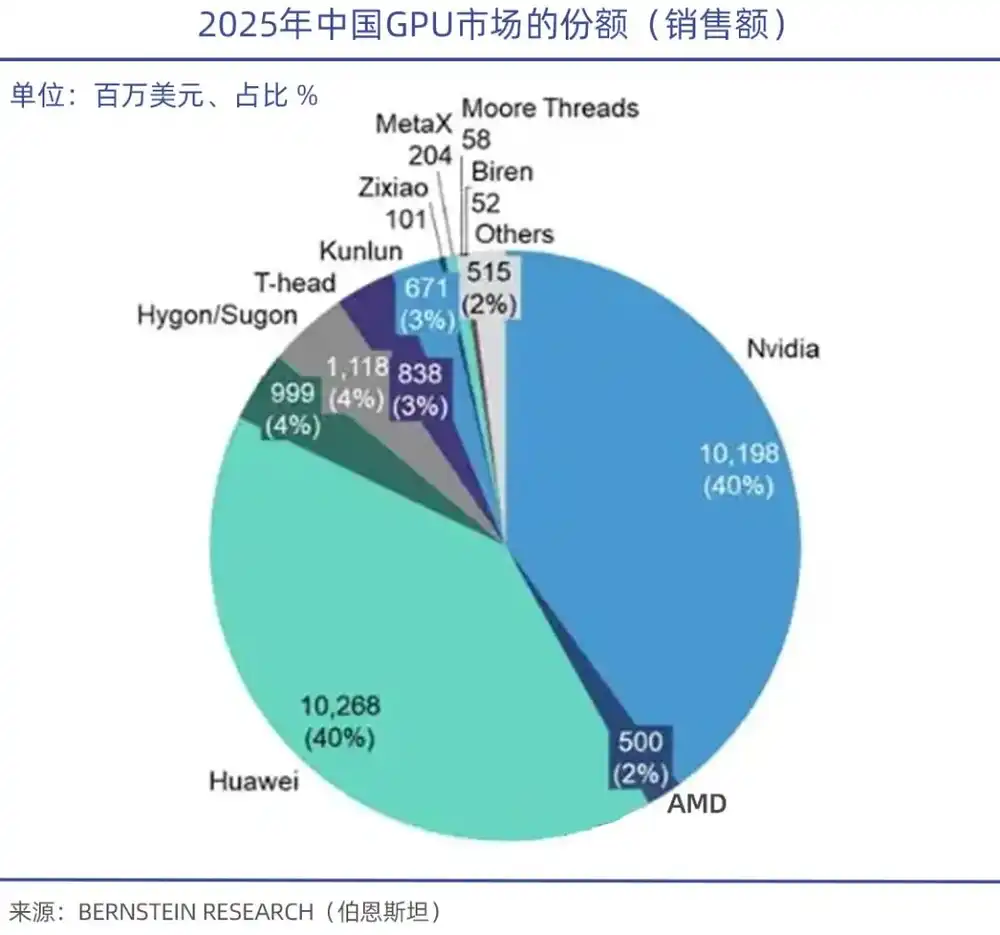
Es importante señalar que, aunque el rendimiento de la potencia de cálculo es importante, el ecosistema tecnológico y de software subyacente es el punto débil de las GPU chinas. Así como CUDA es la base que forjó el imperio de GPU de Nvidia, el académico Zheng Weimin de la Academia de Ingeniería de China señaló que el problema central de los chips de IA chinos es que el ecosistema no es lo suficientemente bueno. Si el ecosistema fuera bueno, incluso con un rendimiento del 60% habría usuarios.
Puede decirse que el ecosistema de software es la barrera más dura en el campo de las GPU, y la capacidad de Nvidia en este aspecto también es difícil de reemplazar.
El ecosistema CUDA, desarrollado durante más de una década, ya cuenta con más de 4 millones de desarrolladores, cientos de miles de modelos de código abierto, cadenas de herramientas de terceros completas y cubre entrenamiento de IA, inferencia, renderizado gráfico y computación científica. Sus barreras ecológicas son extremadamente fuertes y únicas.
Datos de IDC muestran que actualmente más del 95% de los modelos de IA a nivel mundial se desarrollan basados en el ecosistema CUDA. Las GPU chinas, con el apoyo de políticas, necesitan colaborar a largo plazo con la cadena industrial y requieren suficiente paciencia de los medios de comunicación y del mercado de capitales.
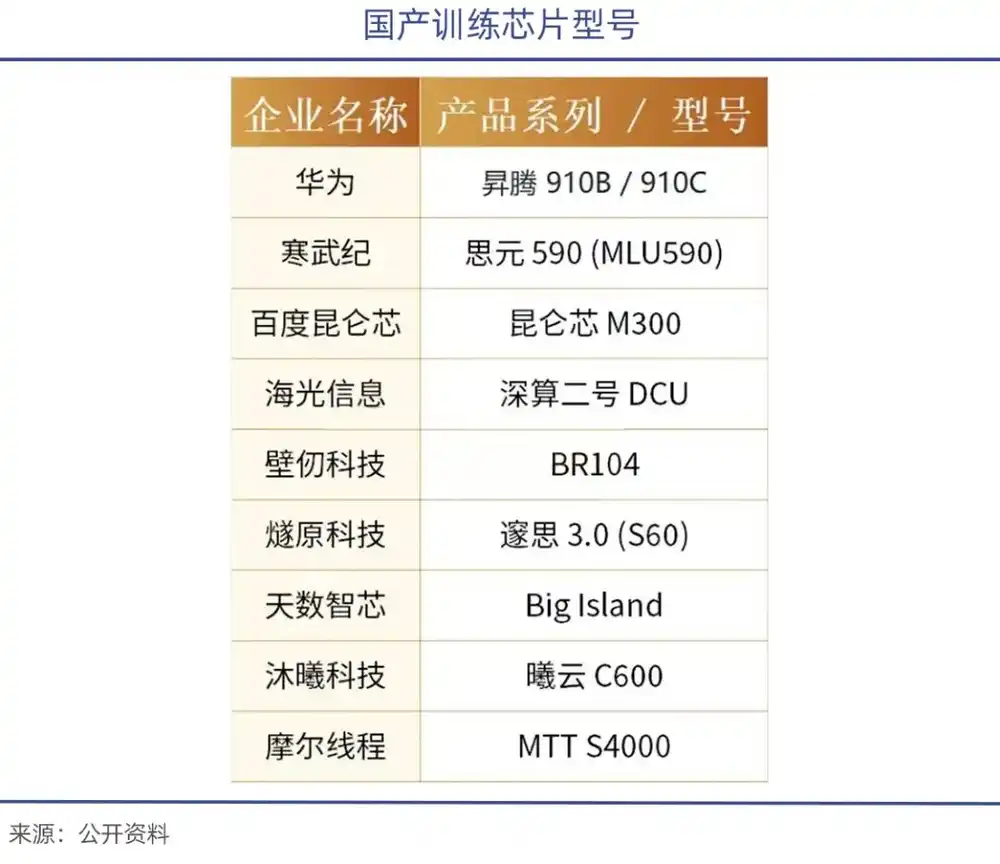
En enero de este año, Zhipu colaboró con Huawei para lanzar el nuevo modelo de generación de imágenes de código abierto GLM-Image. Este modelo se basa en el equipo Huawei Ascend Atlas 800T A2 y el marco de IA Ascend MindSpore, completando un ciclo completo desde el procesamiento de datos hasta el entrenamiento del modelo. Es el primer modelo multimodal SOTA entrenado completamente con chips nacionales.
Moore Thread y el Instituto de Investigación de Inteligencia Artificial de Pekín (BAAI) también completaron el entrenamiento completo del modelo RoboBrain 2.5, un cerebro corpóreo autodesarrollado por BAAI, basado en el clúster de supercomputación MTT S5000 y el marco FlagOS-Robo. Este logro valida por primera vez la viabilidad de los clústeres de potencia de cálculo nacionales en el entrenamiento de modelos grandes de inteligencia corpórea.
Se puede observar que las GPU chinas ya han logrado avances en adaptabilidad y construcción de ecosistema, pasando de "avances puntuales" en el lado de la inferencia a una "adaptación gradual" hacia el lado del entrenamiento. Esto ya es un progreso significativo.
Resumen
En general, en el contexto de dificultades para importar chips avanzados del extranjero, es aconsejable "combinar oriente y occidente" y avanzar con ambas piernas, al mismo tiempo que se apoya especialmente a los chips nacionales de potencia de cálculo para satisfacer las necesidades urgentes del mercado.
La autenticidad de la demanda es indudable. Aunque persiste la "teoría de la burbuja", las voces no son cada vez mayores. El entusiasmo del mercado mundial por la construcción de IA ya ha superado el de cualquier otro sector en sus primeras etapas de desarrollo.
Este año, el mercado de capitales mundial ha vuelto a desencadenar un superciclo de IA, con acciones de Samsung, SK Hynix, Broadcom y TSMC alcanzando repetidamente nuevos máximos. En el mercado nacional, la tecnología dura representada por Cambricon también ha experimentado un fuerte aumento, y el gigante de los módulos ópticos, Zhongji Innolight, llegó a superar en capitalización de mercado a Kweichow Moutai.
Repasando la historia del desarrollo de los semiconductores en Corea del Sur, este país apoyó con toda su fuerza la industria de chips de memoria, soportando los momentos más oscuros y finalmente derrotó a Japón, convirtiéndose en el absoluto rey mundial de la industria de memoria.
Ya sean chips de memoria, chips para móviles o incluso los actuales chips de IA, China todavía se encuentra en una fase de seguimiento, lo que definitivamente no es una tarea de un día. Sin embargo, con su enorme mercado, el continuo surgimiento de talento en IA y su gran fortaleza de capital, las GPU nacionales ya comienzan a mostrar cierta adaptabilidad y pueden resolver muchas necesidades reales de las empresas de IA.
En este juego de ajedrez de IA relacionado con el destino nacional, China y Estados Unidos son tanto rivales como necesitados mutuamente de la tecnología, el mercado y los recursos del otro.
Este artículo proviene de la cuenta oficial de WeChat: Juchao WAVE , editado por Yang Xuran, autor: Xie Zefeng, título original: "El desafío de la potencia de cálculo en el ajedrez de la IA entre China y Estados Unidos | Juchao"





