Autor: Claude, Deep Tide TechFlow
Resumen de Deep Tide: Las últimas pruebas de The New York Times en colaboración con la startup de IA Oumi muestran que la función de resúmenes de IA (AI Overviews) de Google tiene una precisión de aproximadamente el 91%, pero considerando el volumen de Google que procesa 5 billones de búsquedas anuales, esto significa que genera decenas de millones de respuestas erróneas por hora. Más problemático aún, incluso cuando la respuesta es correcta, más de la mitad de los enlaces de referencia no respaldan su conclusión.
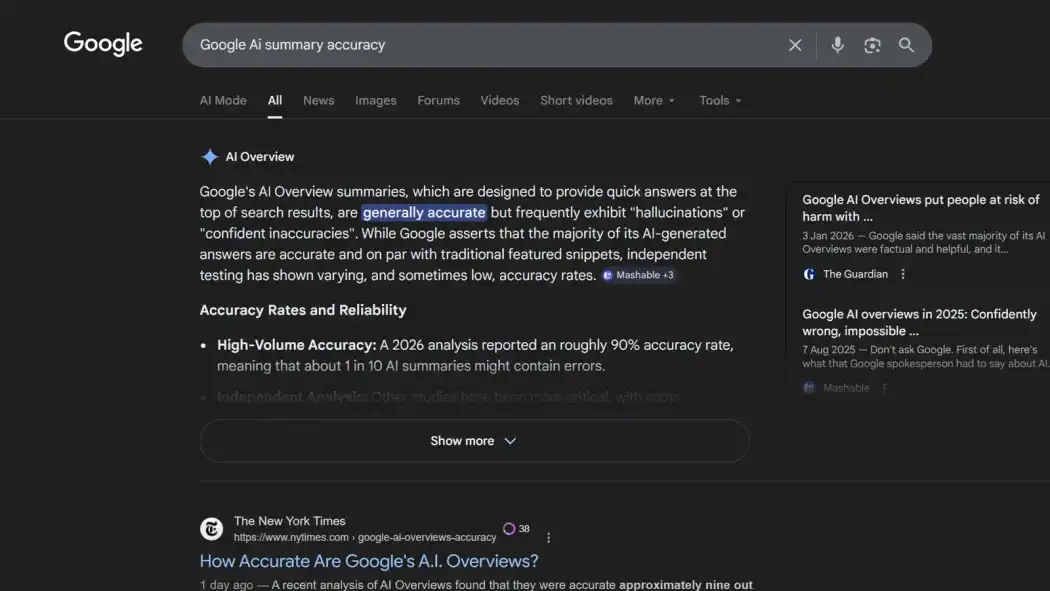
Google está distribuyendo información errónea a los usuarios a una escala sin precedentes, y la mayoría de las personas no lo saben.
Según informa The New York Times, la startup de IA Oumi, por encargo del periódico, evaluó la precisión de la función AI Overviews de Google utilizando la prueba estándar de la industria SimpleQA desarrollada por OpenAI. La prueba cubrió 4326 consultas de búsqueda, realizando una ronda en octubre del año pasado (impulsada por Gemini 2) y otra en febrero de este año (actualizada a Gemini 3). Los resultados mostraron que la precisión de Gemini 2 era de aproximadamente el 85%, y Gemini 3 mejoró al 91%.
91% suena bien, pero en la escala de Google es otra cosa. Google procesa alrededor de 5 billones de consultas de búsqueda al año; calculando con una tasa de error del 9%, AI Overviews genera más de 57 millones de respuestas inexactas por hora, casi 1 millón por minuto.
La respuesta es correcta, pero la fuente está equivocada
Más preocupante que la precisión es el problema de la "desvinculación" de las fuentes de referencia.
Los datos de Oumi muestran que en la era de Gemini 2, el 37% de las respuestas correctas tenían un problema de "referencia infundada", es decir, los enlaces adjuntos en el resumen de IA no respaldaban la información proporcionada. Después de actualizar a Gemini 3, esta proporción no disminuyó sino que aumentó, saltando al 56%. En otras palabras, mientras el modelo da respuestas correctas, cada vez es menos capaz de "mostrar su trabajo".
La pregunta del CEO de Oumi, Manos Koukoumidis, apunta directo al meollo: "Incluso si la respuesta es correcta, ¿cómo sabes que lo es? ¿Cómo lo verificas?"
El hecho de que AI Overviews cite abundantemente fuentes de baja calidad agrava este problema. Oumi descubrió que Facebook y Reddit son la segunda y cuarta fuente de referencia más citadas por AI Overviews, respectivamente. En las respuestas inexactas, Facebook se citaba con una frecuencia del 7%, superior al 5% en las respuestas precisas.
Un artículo falso de un periodista de la BBC "envenenó" los resultados en 24 horas
Otra grave deficiencia de AI Overviews es que es extremadamente manipulable.
Un periodista de la BBC probó con un artículo deliberadamente fabricado y falso; en menos de 24 horas, el resumen de IA de Google presentaba la información falsa como un hecho a los usuarios.
Esto significa que cualquier persona que entienda el mecanismo de funcionamiento del sistema podría potencialmente "envenenar" los resultados de búsqueda de IA publicando contenido falso e incrementando su tráfico. La respuesta del portavoz de Google, Ned Adriance, fue que la función de búsqueda de IA se basa en los mismos mecanismos de clasificación y seguridad que bloquean el spam, y afirmó que "la mayoría de los ejemplos en la prueba son consultas poco realistas que las personas realmente no buscarían".
Google refuta: la prueba en sí tiene problemas
Google planteó varias objeciones al estudio de Oumi. Un portavoz de Google calificó la investigación de "gravemente defectuosa", citando como razones: que el benchmark SimpleQA en sí contiene información inexacta; que Oumi utilizó su propio modelo de IA, HallOumi, para juzgar el rendimiento de otra IA, lo que podría introducir errores adicionales; y que el contenido de la prueba no refleja el comportamiento real de búsqueda de los usuarios.
Las pruebas internas de Google también mostraron que Gemini 3, cuando funciona de forma independiente fuera del marco de búsqueda de Google, produce resultados falsos (alucinaciones) a una tasa de hasta el 28%. Pero Google enfatizó que AI Overviews, al aprovechar el sistema de ranking de búsqueda, mejora la precisión y tiene un rendimiento superior al del modelo por sí solo.
Sin embargo, como señala la paradoja lógica destacada por PCMag: si tu argumento de defensa es "señalar que el informe que afirma que nuestra IA es inexacta también utiliza una IA que podría ser inexacta", esto probablemente no aumente la confianza de los usuarios en la precisión de tu producto.