ByteDance Volcano Engine Ark Coding Plan lanzó oficialmente recientemente GLM-5.1, indicando oficialmente que "se alinea con las capacidades completas del fabricante original, sin límites de compra". Antes de esto, el Coding Plan de Volcano durante mucho tiempo solo tenía modelos más antiguos como GLM-4.7. Esta actualización no solo introdujo GLM-5.1, sino que también integró múltiples modelos de inteligencia artificial nacionales de última generación como Minimax M2.7, Kimi k2.6 y DeepSeek-V3.2.
Esto significa que los desarrolladores, con una sola suscripción, pueden acceder simultáneamente a múltiples modelos líderes. Según la retroalimentación del mercado, este "modelo de paquete" reduce enormemente los costos de prueba y error para los desarrolladores. Actualmente, el precio del paquete Lite es de 40 yuanes mensuales y el paquete Pro de 200 yuanes mensuales, lo que hace que muchos desarrolladores estén dispuestos a "comprar uno para asegurar su lugar".
El propio GLM-5.1 de Zhipu AI, en una actualización a principios de abril de 2026, ya mostró capacidades de ingeniería impresionantes. En dos videos oficiales publicados por Zhipu, "construir un escritorio de Linux desde cero en 8 horas" y "655 iteraciones, aumentando el rendimiento de consulta de la base de datos vectorial a 6.9 veces la versión inicial", renovaron la imaginación del público sobre la "ejecución efectiva en 8 horas" de los grandes modelos.
Periodista explora comunidad de desarrolladores: la mayoría de los usuarios indican que "no es duradero"
Al entrar en un grupo de comunicación de desarrolladores de Ark Coding, el periodista descubrió que, además de publicaciones compartiendo experiencias, muchos usuarios reportaron una brecha en la experiencia real. Al revisar unas páginas de la comunidad de intercambio, se encuentran numerosas publicaciones de quejas y solicitudes de reembolso, con muchos netizens exclamando directamente "me siento estafado".
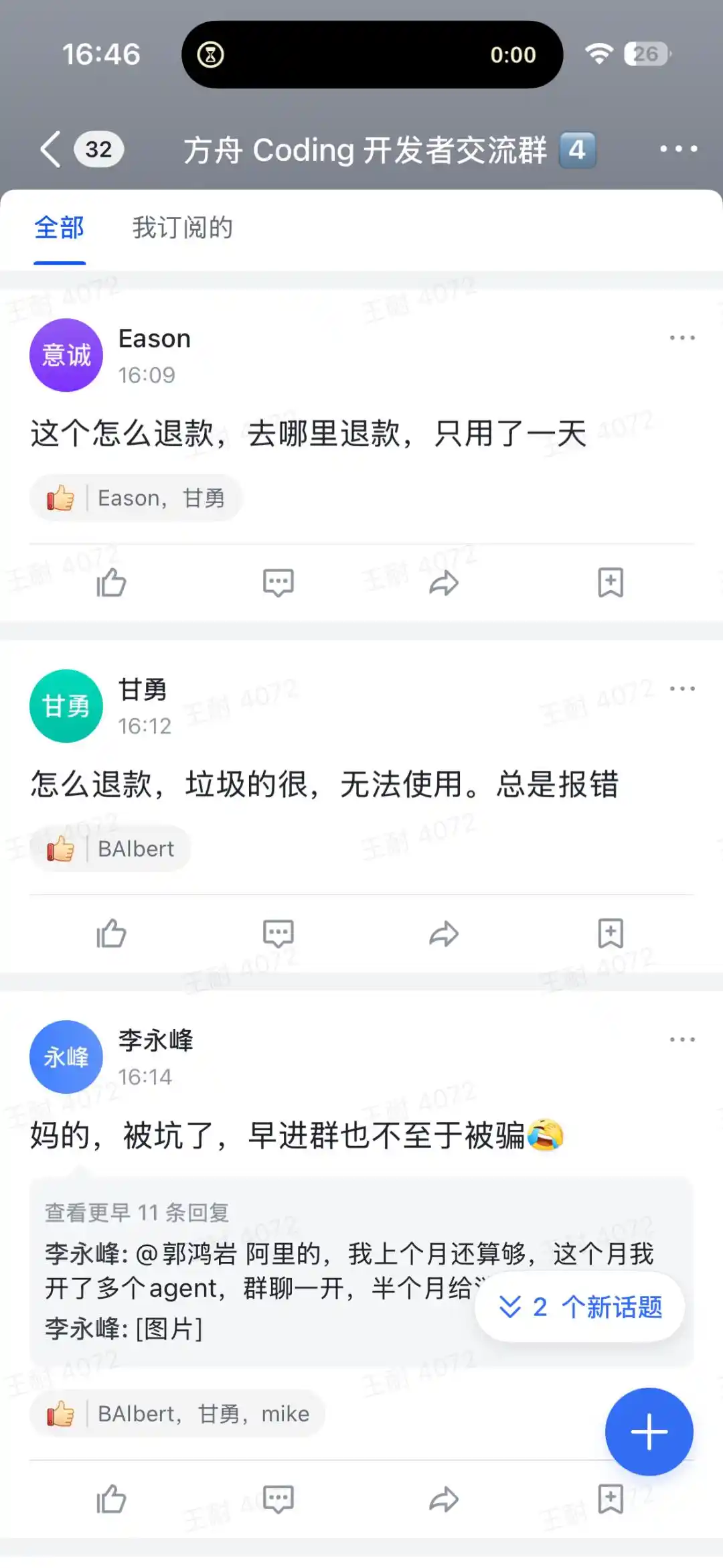
Las controversias son principalmente dos:
Una es sobre el agotamiento rápido de la cuota. Un usuario llamado "Hakimi" publicó: "unas pocas rondas de diálogo en una tarea y la limitación de 5 horas casi se agota". Otro netizen publicó que la "razón para activar la limitación de 5 horas" fue porque la cuenta tuvo una ventana deslizante continua durante 5 horas, con un número real de solicitudes que excedió las 6004, superando el límite del sistema.

La segunda es la degradación de la experiencia debido a la presión en la programación de la capacidad de cálculo. Muchos usuarios informaron encontrar el error 429 (demasiadas solicitudes) y, en horas pico, "un retraso del primer carácter de más de un minuto es normal". Un usuario直言: "La activación de la limitación de 5 horas es demasiado frecuente, no se puede usar para un desarrollo serio."
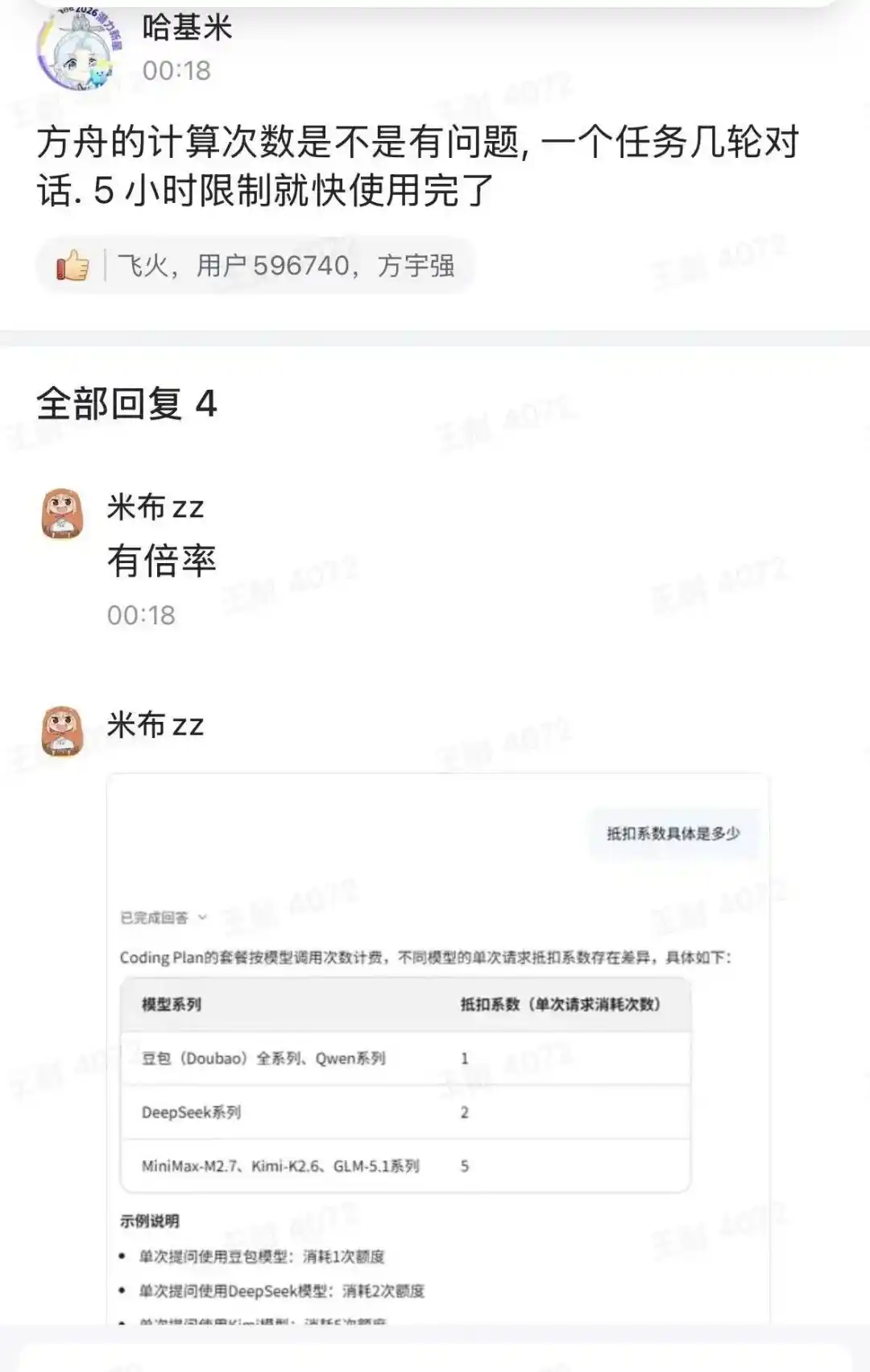
Al mismo tiempo, detrás del bajo precio mensual de 40 yuanes del Coding Plan, también se esconde una "corriente oculta" sobre "una solicitud de llamada" que conduce a diferentes coeficientes de deducción en el paquete. Por ejemplo, un usuario publicó en el grupo de intercambio de desarrolladores una imagen de las "diferencias en los coeficientes de deducción al llamar a diferentes modelos". Por ejemplo, la serie completa de Doubao y la serie Qwen tienen un coeficiente de deducción de 1 vez, la serie DeepSeek de 2 veces, y las series MiniMax-M2.7, Kimi-K2.6 y GLM-5.1 de 5 veces.
Esto también refleja que la construcción de un "supermercado de modelos" no es tan fácil como se imaginaba. Los desarrolladores son atraídos por la "relación costo-beneficio", pero las deficiencias expuestas inicialmente en áreas como la programación de capacidad de cálculo hacen que muchos desarrolladores, después de probarlo, opten por detenerse. Esto también expone los dolores de crecimiento iniciales del "modelo de paquete". Con la afluencia de usuarios, la capacidad de carga de la plataforma de computación enfrenta desafíos. Cómo encontrar un punto de equilibrio sostenible entre la atracción de precios bajos y la calidad del servicio será una propuesta a largo plazo que Volcano Engine y sus seguidores necesitarán resolver.
Proveedores de nube se vuelven colectivamente hacia "supermercados de modelos": comienza a aparecer una estratificación sólida
Esta actualización "integrativa" del Coding Plan de Volcano Engine tampoco es un evento aislado.
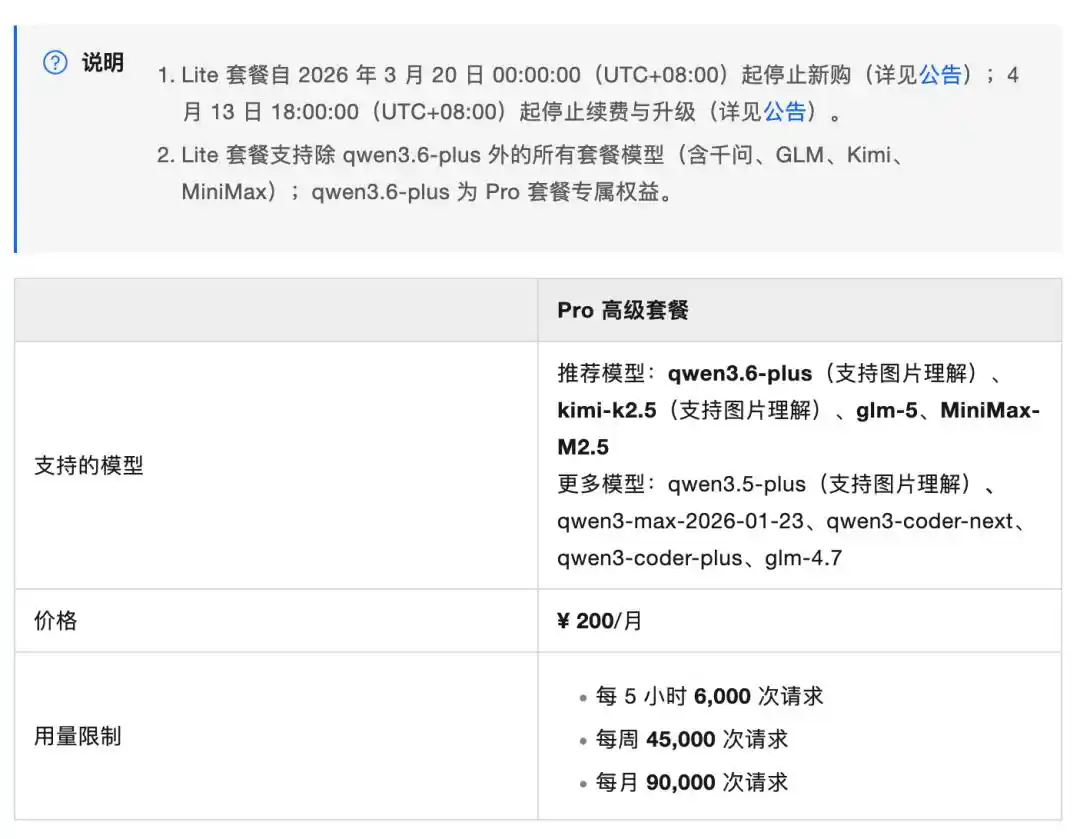
Desde principios de 2026, los principales proveedores de nube como Alibaba Cloud, Baidu Intelligent Cloud y Tencent Cloud han estado avanzando en layouts de integración de múltiples modelos. Por ejemplo, Alibaba Cloud, como pionero en la industria, lanzó antes el paquete de suscripción multi-modelo "Bailian Coding Plan". Actualmente admite series como Qianwen, kimi-k2.5, glm-5, MiniMax-M2.5, etc. Actualmente, el precio Pro es de 200 yuanes mensuales, y el paquete Lite dejó de estar disponible para nuevas compras a partir del 20 de marzo, y dejará de renovarse y actualizarse a partir del 13 de abril.
El servicio de suscripción Tencent Cloud Large Model Coding Plan se lanzó completamente en marzo de 2026, admitiendo múltiples modelos最新 como Tencent HY 2.0 Instruct, GLM-5, Kimi-K2.5, MiniMax-M2.5. Baidu Qianfan lanzó oficialmente el servicio de suscripción de codificación AI Coding Plan en febrero de 2026, siendo también uno de los primeros proveedores de nube en lanzar este tipo de servicio en China.
El modelo de "supermercado de modelos" no es una elección de una sola empresa, sino que se está convirtiendo en una pista en la que compiten los proveedores de nube. Pero al desgarrar la estrategia de agregación de los proveedores de nube, quién puede proporcionar un servicio más estable, reglas de cuota más transparentes, mecanismos de tolerancia a fallos más flexibles, quién puede extender más capacidades de servicio a nivel empresarial más allá de la programación, y si la tasa de renovación puede seguir el ritmo, se convierten en nuevos núcleos de competencia.
A nivel internacional, las plataformas de servicio de agregación de modelos Amazon Bedrock y Microsoft Azure, aunque difieren en escenarios del modo de suscripción Coding nacional, pertenecen a la misma tendencia de integración.

En general, la competencia de la industria también está pasando de la "comparación de capacidades de un solo modelo" a la "capacidad de integración de plataformas + capacidad de servicio ecológico", y la concentración de la industria aumentará rápidamente.
Wang Kai, analista jefe de asignación de activos de Guoxin Securities, dijo al periodista que, aunque la diferenciación de la industria se está acelerando, puede ser un poco pronto juzgar el período de integración. "Más precisamente, esto es una refinación e iteración de la división laboral de la cadena industrial. Los fabricantes de modelos se enfocan en algoritmos, los proveedores de nube se enfocan en la entrega de ingeniería, cada uno aprovechando sus ventajas principales". Considera que, independientemente de si otros proveedores de nube siguen el ejemplo, el panorama competitivo evolucionará de luchas individuales a una diferenciación de nicho ecológico.
¿Se intensifica la presión de "canalización" para las empresas de grandes modelos?
La llamada "canalización" no se refiere a la desaparición de las empresas de modelos, sino a la pérdida de su prima de producto, derecho de conexión con el usuario y poder de discourse, transfiriéndose las ganancias a la parte de la plataforma de computación, convirtiéndose en un papel "dominado".
Bajo la ola de agregación de los proveedores de nube, la "canalización" también se está convirtiendo en la espada de Damocles que pende sobre la cabeza de las empresas independientes de grandes modelos. En este juego silencioso, jugadores líderes como Zhipu AI, Moonlight (Kimi), MiniMax, etc., no han optado por comprometerse pasivamente, sino que han crecido desde sus genes, dando diferentes caminos de突围.
Zhang Peng, CEO de Zhipu AI, en un diálogo público el 8 de abril, dejó claro que el objetivo final de Zhipu nunca es convertirse en una "herramienta de llamada reemplazable a voluntad", sino construir un agente inteligente totalmente autónomo (Autonomous Agent). Este posicionamiento intenta hacer que Zhipu actualice de "proveedor de modelos" a "ejecutor de tareas", evitando así la trampa de precios bajos de la API pura.
Moonlight (Kimi) adopta una estrategia de "disposición dispersa + profundización en texto largo". Se conecta simultáneamente a múltiples plataformas principales en la nube como Volcano Engine y Alibaba Cloud, logrando un suministro de capacidad de cálculo multi-fuente, sin estar vinculado a un solo canal, garantizando la estabilidad del servicio y el control de costos. Kimi K2.6, lanzado en abril de 2026, adopta una arquitectura Mixture of Experts (MoE), con una ventana de contexto estándar de 256K tokens.
MiniMax concentra sus recursos centrales en campos verticales como la creación de contenido, servicio al cliente inteligente, educación, servicios empresariales, entretenimiento social, etc., especialmente en escenarios como IA para juegos, humanos digitales, interacción multimodal, etc., creando "capacidades personalizadas difíciles de reemplazar por la plataforma en la nube".

¿La integración de plataformas de los grandes fabricantes acelerará la "canalización" de las empresas de modelos? Wang Kai, analista jefe de asignación de activos de Guoxin Securities, cree que es necesario distinguir entre perspectivas a corto y largo plazo.
"A corto plazo, es una ley comercial que los canales de distribución estén controlados por la plataforma, se ceda parcialmente el poder de fijación de precios y las ganancias de los fabricantes de modelos se transfieran a la parte de entrada. Pero a largo plazo, los modelos generales son fáciles de homogeneizar, y los modelos de aprendizaje profundo en escenarios verticales como finanzas, atención médica, derecho, etc., tienen barreras profesionales que la agregación centralizada no puede eliminar." Considera.
Para hacer frente al riesgo de ser platformizado, también se puede hacer referencia a las estrategias de OpenAI y Anthropic. Por un lado, fortalecer los canales que se enfrentan directamente a los usuarios finales, por ejemplo, la operación independiente de ChatGPT y Claude esencialmente establece una conexión de usuario que evita la plataforma. Por otro lado, la velocidad de iteración tecnológica y el reconocimiento de la marca del usuario son dos barreras efectivas, por lo que las empresas de modelos necesitan equilibrar la inversión en I+D y el layout de productización.
El final del juego de esta "canalización versus platformización" podría no ser quién se come a quién, sino una mayor clarificación de la división laboral. Los proveedores de nube hacen la canalización, las empresas de modelos hacen la tecnología, y ambas partes encuentran gradualmente sus límites de supervivencia en el juego.
En cuanto a quién se come a quién, en esta etapa, aún está lejos del final de la historia.
Este artículo proviene del WeChat public account "科创板日报", autor: Wang Nai