Imagina una escena:
Una persona mayor que vive sola se resbala en la sala de estar, y el dolor le impide pedir ayuda. En ese momento, el dispositivo inteligente que lleva puesto o la cámara de su casa "ve" la anomalía, y la IA, sin esperar ninguna orden de voz, emite activamente una alerta y contacta rápidamente con familiares o servicios de emergencia.
O estás viendo un partido de fútbol intenso, en el instante en que se produce el gol clave, antes de que puedas retroceder y preguntar, las gafas de IA te proporcionan automáticamente un análisis a cámara lenta y una explicación táctica.
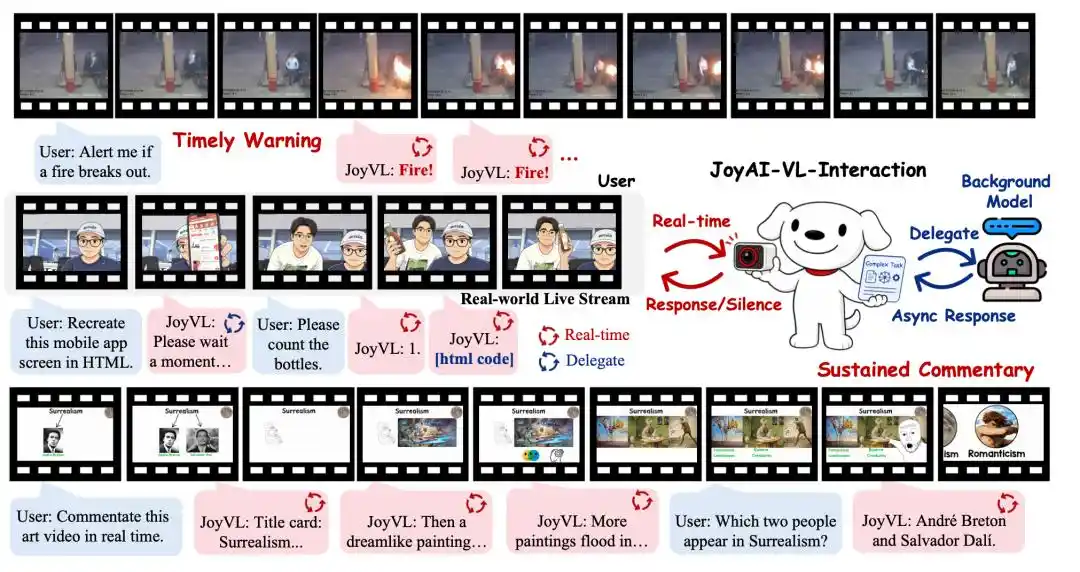
Estas escenas ya no son fantasías del futuro, sino los problemas reales que el primer modelo de interacción visual-lingüística de pila completa de código abierto a nivel mundial de JD.com, JoyAI-VL-Interaction, intenta resolver.

En los últimos dos años, los límites de capacidad de los modelos grandes se han ido ampliando constantemente, pero la forma de interacción principal sigue siendo la lógica de "turnos": "el usuario pregunta, el modelo responde". Es eficiente, pero en muchos escenarios no es razonable. Muchos eventos importantes ocurren demasiado rápido para que el usuario formule una pregunta; en muchos casos, ni siquiera hay instrucciones de voz.
Este año, un juicio se está convirtiendo en consenso de la industria: la IA está pasando de "predecir el siguiente token" a "predecir el siguiente estado físico". Esto también significa que la IA debe evolucionar de ser un procesador de información pasivo a un participante activo.
Precisamente en este momento, JD.com ha publicado como código abierto JoyAI-VL-Interaction, el primer modelo de interacción visual-lingüística en tiempo real de pila completa de código abierto a nivel mundial, capaz de juzgar de forma autónoma cuándo responder, cuándo guardar silencio y cuándo delegar tareas complejas en modelos de back-end dentro de un flujo de vídeo continuo.
Lo que JoyAI-VL-Interaction quiere demostrar es: una IA que realmente entra en el mundo físico no debería esperar siempre a que le pregunten, debería aprender a ver, juzgar de forma proactiva y ofrecer ayuda en el momento adecuado.
Esta es también la señal más amplia que JD.com AI está enviando: desde la capacidad del modelo hasta los escenarios industriales, la competencia en IA está pasando del interrogatorio dentro de la pantalla al mundo real.
¿Por qué la interacción visual-lingüística?
En el mundo físico real, una gran cantidad de información crítica ocurre en momentos en los que el usuario no tiene tiempo de plantear una pregunta. Lo que hace sentir que "no hay tiempo" es a veces un problema de experiencia, pero más a menudo es un límite de capacidad causado por el paradigma del modelo.
La industria no es ajena a esta limitación.
En la primera mitad de 2026, la interacción en tiempo real se convirtió en la palabra clave más candente de la IA multimodal. La industria avanzó principalmente por dos vías: una fue hacer la conversación por turnos más rápida, la otra fue hacer las conversaciones de voz más naturales.
La primera enfatiza la baja latencia o la entrada/salida arbitraria, pero su núcleo sigue siendo "responde solo si preguntas"; la segunda permite al modelo escuchar y hablar simultáneamente, ser interrumpido en cualquier momento, acercando la experiencia a una llamada telefónica real, pero el foco sigue estando en los escenarios de voz.
El problema es que muchos cambios en el mundo real no se convierten primero en una frase. Incendios, caídas, aproximación de vehículos, cambios en el contenido de la pantalla, anomalías en la línea de producción: todos son imágenes que aparecen antes que el lenguaje. Si la IA solo puede esperar a que la gente hable, le costará estar realmente "presente".
Quien realmente llegó a la misma conclusión que JD.com al mismo tiempo fue Thinking Machines Lab, fundada por Mira Murati. El 11 de mayo, esta empresa propuso el concepto de "modelos de interacción" (interaction models) y publicó algunas vistas previas de investigación, señalando que el paradigma de respuesta autónoma de los modelos de interacción, en comparación con el paradigma tradicional de pregunta-respuesta, presenta un espacio de imaginación mayor para la colaboración Humano-IA.
Que dos equipos convergieran en la misma idea casi al mismo tiempo es en sí misma una señal: hacer de la interactividad una capacidad del propio modelo y escalarla es una dirección inevitable para la industria en los próximos años.
La diferencia radica en que JD.com coloca el lenguaje visual en una posición más central, desacoplando el lenguaje oral como una E/S desmontable, haciendo del lenguaje visual la "modalidad de conducción principal" para la toma de decisiones autónomas del modelo.
Es decir, desde el momento en que se enciende la cámara, JoyAI-VL-Interaction "observará" continuamente los cambios visuales en el mundo físico y juzgará de forma autónoma si debe hablar, qué decir y si debe delegar la tarea.
Aquí reside también la imaginación de la interacción visual: se puede utilizar en escenarios como el cuidado de ancianos y niños, asistencia para invidentes, gafas de IA, comentarios deportivos, inspección de tiendas, logística de almacenes, colaboración con robots, etc. El usuario no necesita primero formular la pregunta en una frase; la IA puede captar la necesidad a partir de los cambios en el entorno.
Por lo tanto, la visión no es solo otra forma de entrada, sino un canal de percepción insustituible para que la IA avance hacia "predecir el siguiente estado físico".
El informe técnico de JoyAI-VL-Interaction de JD.com también refuerza este punto, mostrando que en seis escenarios de flujo real, JoyAI-VL-Interaction alcanzó una tasa de victoria del 77.6% frente a los principales modelos nacionales y del 87.9% frente a modelos internacionales; en el escenario de alerta por monitorización, que más pone a prueba la capacidad de captura de eventos, la tasa de victoria alcanzó el 100%. El informe considera que la diferencia no es solo la calidad de la respuesta, sino la capacidad de actuar en el momento correcto.
Sin embargo, lograr una interacción visual proactiva es ciertamente más difícil.
La adquisición de datos para la interacción por voz es relativamente directa; grandes conjuntos de datos de comandos de voz permiten al modelo aprender cuándo hablan los humanos, cómo interrumpir, cómo continuar. Los datos necesarios para la interacción visual son completamente diferentes. El modelo debe aprender, en un flujo continuo de imágenes cambiantes, qué señal merece una respuesta y qué señal debe ser silenciada.
Una barrera más profunda es la capacidad de definición del escenario. En la interacción por voz existe un límite de activación natural: que el usuario hable marca el inicio de la interacción. La interacción visual no tiene un inicio y un final claros; el modelo debe juzgar los límites por sí mismo dentro de un flujo de información sin fronteras.
La singularidad de JD.com reside precisamente aquí: esta empresa no busca escenarios desde un laboratorio abstracto, sino que opera naturalmente dentro de redes empresariales reales como comercio minorista, logística, salud e industria.
Esto significa que la IA de JD.com no se enfrenta a una única entrada de chat, sino a una multitud de tareas reales: cómo fluyen las mercancías, cómo colaboran los dispositivos, cómo cooperan los robots con las personas, cómo se detectan las anomalías con antelación. El modelo puede aprender de las necesidades reales e iterar a partir de los comentarios reales.
Aunque hay compensaciones en la ruta tecnológica, la forma de interacción futura para la AGI general debe ser la inteligencia activa. Los agentes inteligentes deben poseer el ciclo completo de percepción del entorno, toma de decisiones autónoma y respuesta en tiempo real. Por lo tanto, muchas empresas no es que no quieran hacer modelos grandes de interacción visual, sino que actualmente carecen del terreno fértil para que surja la interacción visual. Esta es también la razón por la que el capital y la potencia computacional han fluido primero hacia la pista de la interacción por voz.
Así que la elección de JD.com de empezar por la visión no es solo una elección técnica, sino también una decisión determinada por su posición estratégica. En comparación con muchos actores de modelos grandes, JD.com está más cerca de la operativa del mundo físico y también necesita más una IA capaz de percibir proactivamente y responder en tiempo real.
Para que ese día llegue más rápido, alguien tiene que empezar antes.
Ligero, de código abierto, desplegable
¿Qué significa ser el primero de pila completa y de código abierto a nivel mundial?
Redefinir el paradigma de interacción suena grandioso, pero cuando se aplica a aplicaciones reales, el primer obstáculo es muy simple: la IA no puede estar siempre molestando a las personas, ni permanecer en silencio cuando debería alertar.
Normalmente se espera que la IA hable cuanto más mejor, pero en escenarios de interacción visual en tiempo real, un modelo que no para de interrumpir no es inteligente. La capacidad verdaderamente valiosa es aparecer proactivamente en momentos clave y permanecer en silencio en momentos irrelevantes.
Por lo tanto, JoyAI-VL-Interaction entrena el "silencio" también como una capacidad. El modelo necesita dominar tres niveles de juicio: en qué escenarios debe responder proactivamente, en cuáles debe guardar silencio y en cuáles debe delegar la tarea, pasándola a otros modelos.
Si esta capacidad solo pudiera quedarse en los artículos de investigación, su valor sería limitado. El énfasis de JD.com en "pila completa de código abierto" radica precisamente en abrir simultáneamente el modelo, el sistema de inferencia y la ruta de construcción de aplicaciones, permitiendo a los desarrolladores ejecutarlo, modificarlo y utilizarlo de verdad.
JD.com ha elegido una ruta de ingeniería más fácil de difundir: un modelo de 8B de parámetros, desplegable con una sola tarjeta gráfica 3090. Con estos parámetros, los desarrolladores individuales pueden ejecutarlo, el hardware de consumo puede soportarlo y los dispositivos del lado del cliente pueden implementarlo.
Para la interacción visual en tiempo real, esta ligereza no significa una reducción de capacidad, sino una división del trabajo más clara.
JoyAI-VL-Interaction se asemeja más a una capa de interacción frontal, responsable de ver el entorno, juzgar el momento y realizar una comunicación breve. Cuando encuentra tareas complejas que requieren un razonamiento profundo, las delega automáticamente a agentes de back-end elegidos por el usuario, como OpenClaw, Codex, Claude Code, etc. Por lo tanto, un modelo de 8B es suficiente.
Por ejemplo, el modelo puede primero decirle al usuario "Déjame pensarlo", luego pasar el problema difícil al back-end y mantenerse presente; cuando el back-end devuelva el resultado, puede sincronizar la respuesta con el usuario. Durante este proceso, también puede continuar ayudando al usuario con otras interacciones inmediatas.
JD.com también ha diseñado el sistema subyacente para ser ligero: mediante codificación de vídeo, memoria de largo alcance y compresión de contexto, el modelo puede observar continuamente flujos de vídeo largos a un costo relativamente bajo, manteniendo la latencia de extremo a extremo en el nivel sub-segundo. Para el lector común, lo importante no son estos términos técnicos, sino el resultado: la IA puede permanecer en escenarios reales durante más tiempo y con un umbral de acceso más bajo.
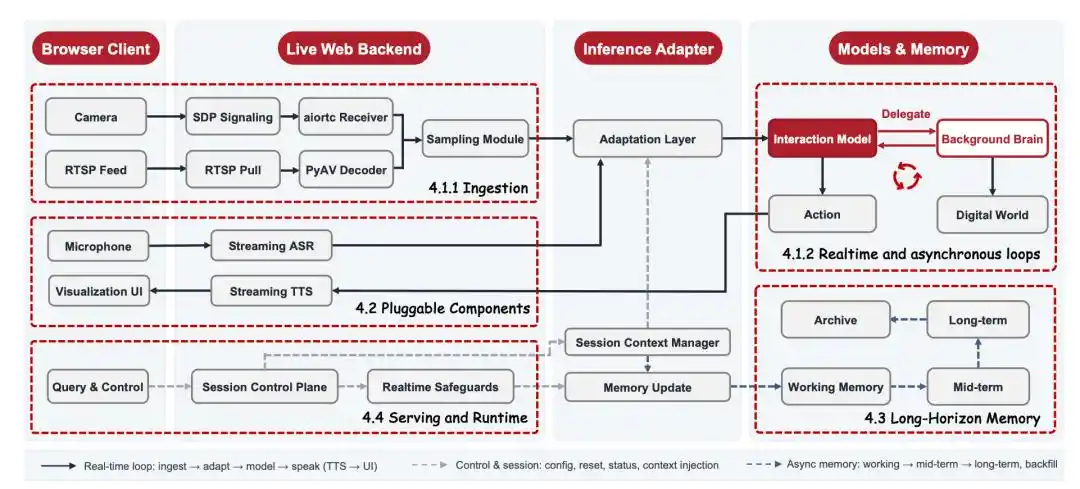
La elección rentable y desplegable también conduce directamente a la estrategia de código abierto de JD.com. Solo si el modelo es lo suficientemente ligero, el sistema lo suficientemente completo y el umbral de despliegue lo suficientemente bajo, la interacción visual en tiempo real puede pasar de ser un experimento de unos pocos equipos a convertirse en un ecosistema de aplicaciones explorado conjuntamente por más desarrolladores y empresas.
JD.com ya ha publicado como código abierto este sistema de inferencia, con un objetivo claro: permitir que cualquier persona con una tarjeta gráfica 3090 o superior y una cámara pueda configurar rápidamente su propia aplicación de interacción visual en tiempo real.
JoyAI-VL-Interaction ha obtenido soporte day-0 de vLLM-Omni y ya se ha integrado de forma nativa en la rama principal de vLLM-Omni.
Devolver la IA al mundo físico
El propósito del código abierto es entregar la imaginación aplicada a un mercado más amplio. Porque el valor del avance tecnológico finalmente debe ser verificado por el mundo real.
La primera ola de imaginación aplicada para JoyAI-VL-Interaction ya es muy intuitiva: en retransmisiones deportivas, la IA puede comentar automáticamente en el instante de un gol clave o decisivo; al monitorear el mercado de valores, puede observar continuamente los cambios en la pantalla y alertar sobre anomalías; en el cuidado familiar, puede alertar proactivamente cuando una persona mayor se cae o un niño se acerca a una zona peligrosa; combinado con gafas de IA, puede ayudar al usuario a reconocer calles, productos, pantallas y el entorno circundante; al servir a personas invidentes, puede convertir la información visual en asistencia en tiempo real.
Para JD.com, lo que más espera es que se pueda integrar en robots: un modelo que sabe cuándo hablar, cuándo callar y cuándo pedir ayuda al sistema de back-end puede hacer que los robots sean más eficientes y se acerquen más al asistente inteligente "con tacto" que la gente espera.
La razón fundamental por la que JD.com se atreve a "agitar" este campo en este momento es porque posee activos de datos del mundo físico que otros actores de modelos grandes no tienen.
Situado en las coordenadas de la industria de 2026, el peso de los activos de datos del mundo físico es especialmente significativo.
2026 ha sido llamado por la industria el "Año Cero de los Datos de Inteligencia Encarnada", y en este contexto generalizado, existe una contradicción aguda: los datos de interacción física de alta calidad son extremadamente escasos, muy lejos de satisfacer las necesidades de entrenamiento a gran escala. El cuello de botella de la iteración algorítmica se está trasladando completamente del lado del modelo al lado de los datos.
En este punto temporal, JD.com anunció su intención de acumular 10 millones de horas de datos de vídeo de alta calidad de escenarios reales en dos años, movilizando a 600,000 personas para participar en la recolección.
JD.com tiene más de 3,000 escenarios empresariales reales, cubriendo áreas como comercio minorista, logística, salud e industria. Este año, además, ha innovado en Suqian con un modelo de recolección comunitaria por cuadrículas, desplegando de forma masiva sus terminales de cabeza JoyEgoCam de desarrollo propio, movilizando a pequeñas y medianas empresas y residentes de los alrededores para recolectar datos en escenarios de trabajo reales.
La velocidad de despliegue es rápida. En marzo, JD.com anunció la finalización del primer centro de recolección de datos de inteligencia encarnada del mundo en Suqian; en abril, publicó la primera infraestructura de datos encarnados de la industria que cubre toda la cadena de recolección, almacenamiento, etiquetado, entrenamiento, evaluación, simulación y prueba; en mayo, JoyEgoCam entró en producción masiva, recolectando continuamente datos en primera persona.
Estos datos son el combustible más escaso para entrenar modelos encarnados y modelos de interacción visual. A medida que los datos encarnados se incorporen al entrenamiento, el valor de JoyAI-VL-Interaction también pasará de "un modelo que puede ver proactivamente" a integrarse aún más en espacios físicos más concretos como robots, vehículos no tripulados, almacenes, tiendas y hogares.
Entre el modelo y la aplicación, JoyAI-Echo, también publicado como código abierto por JD.com el 3 de junio, juega un papel igualmente clave. Echo se especializa en la generación en tiempo real de vídeos largos, e Interaction se especializa en la comprensión e interacción en tiempo real. La publicación como código abierto de dos modelos en un mes significa que JD.com ya ha conectado los extremos de entrada y salida de la multimodalidad de vídeo, y ha colocado el avance de la IA hacia el mundo físico en una posición más a largo plazo.
En la conferencia de lanzamiento del 618 de este año, JD.com dijo que quiere convertirse en el "centro operativo del mundo físico más grande del mundo".
En la era de la interacción humano-máquina, la industria está prestando cada vez más atención a cómo la IA comprende el mundo físico, pero la lógica de solución de JD.com es diferente a la de la mayoría de los actores de modelos grandes: esta empresa ya opera dentro del mundo físico.
Almacenes, distribución, comercio minorista, salud, industria: todos son campos de entrenamiento y pruebas para la IA y la inteligencia encarnada. Solo en la logística de JD.com, se planea invertir en 3 millones de robots, 1 millón de vehículos no tripulados y 100,000 drones en cinco años. Estos dispositivos de hardware también serán el campo de aplicación para JoyAI-VL-Interaction.
Ya sea por voz o por visión, los modelos de interacción esencialmente existen para conectar el mundo físico y el digital, comprender el mundo físico y orquestar el mundo digital.
El código abierto es la primera ventana que JD.com abre hacia afuera. En esta pista donde la demanda impulsa la tecnología, JD.com libera el modelo, los datos de entrenamiento y el sistema completo, apostando por algo a más largo plazo: hacer que la interacción activa pase de ser un juicio de unos pocos equipos a convertirse en una de las principales vías para que la IA avance hacia el mundo físico.
Bienvenido a activar el servicio con un clic en vLLM-Omni para experimentar, o iniciar con un clic en el repositorio:
Dirección del código: https://github.com/jd-opensource/JoyAI-VL-Interaction
Dirección del modelo: https://huggingface.co/jdopensource/JoyAI-VL-Interaction-Preview
Dirección del conjunto de datos: https://huggingface.co/datasets/jdopensource/JoyAI-VL-Interaction
Dirección del informe técnico: https://huggingface.co/papers/2606.14777






