¡¿Un desarrollador individual, logrando entrar en las primeras posiciones del Trending de Modelos de Hugging Face entre tantas grandes empresas?!
Era un día común, y yo también revisaba comúnmente la lista Trending de Hugging Face.
El primero es GLM-5.2, el último modelo de código abierto de Zhipu, ya muy conocido, con más de 60 mil descargas, nada sorprendente.
El segundo es Unlimited-OCR de Baidu, recientemente publicado en silencio, capaz de analizar más de 40 páginas de documentos de una vez, con descargas que también han alcanzado las 70 mil.
Mirando más abajo, de repente aparece una cuenta personal: yuxinlu1.
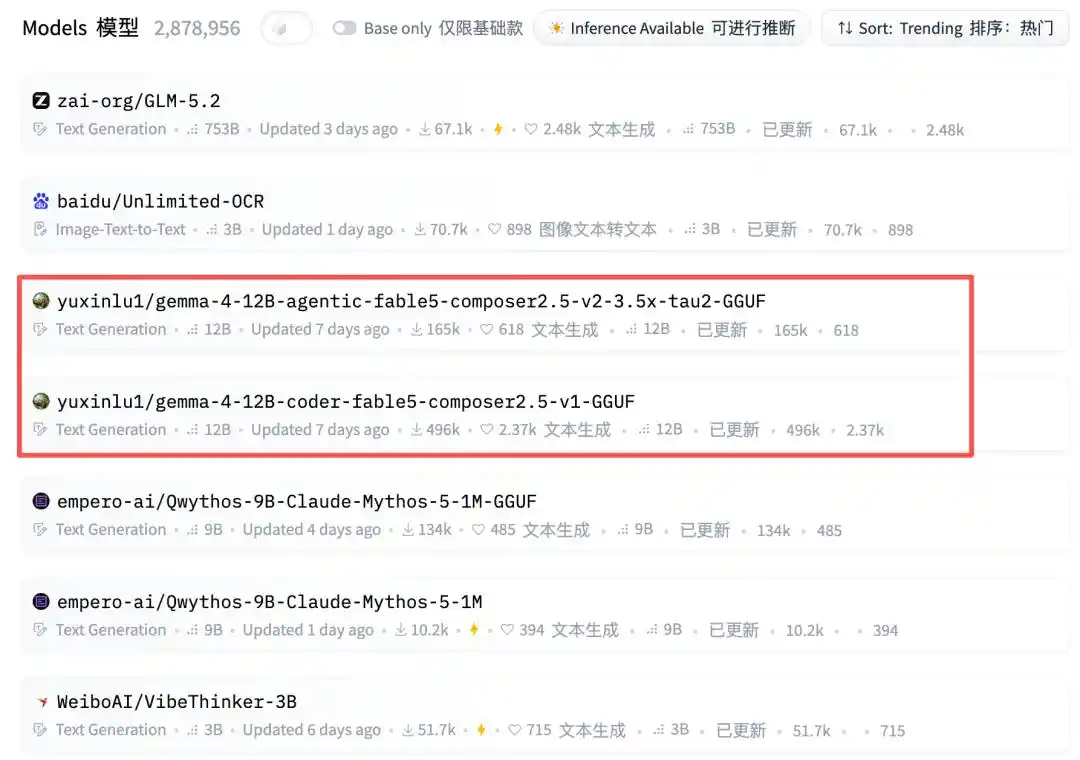
Mmm... ¡¿mm?!
Y ocupa dos posiciones de una vez.
Al ver el número de descargas—los últimos datos ya alcanzan 20.7 mil y 53.6 mil. Vaya, ¿qué modelos celestiales son estos?
Incluso la semana anterior, los modelos de este desarrollador individual una vez dominaron la lista Trending de Hugging Face, superando a GLM-5.2, hasta el punto de que el responsable de Zhipu lo recomendó públicamente en X:
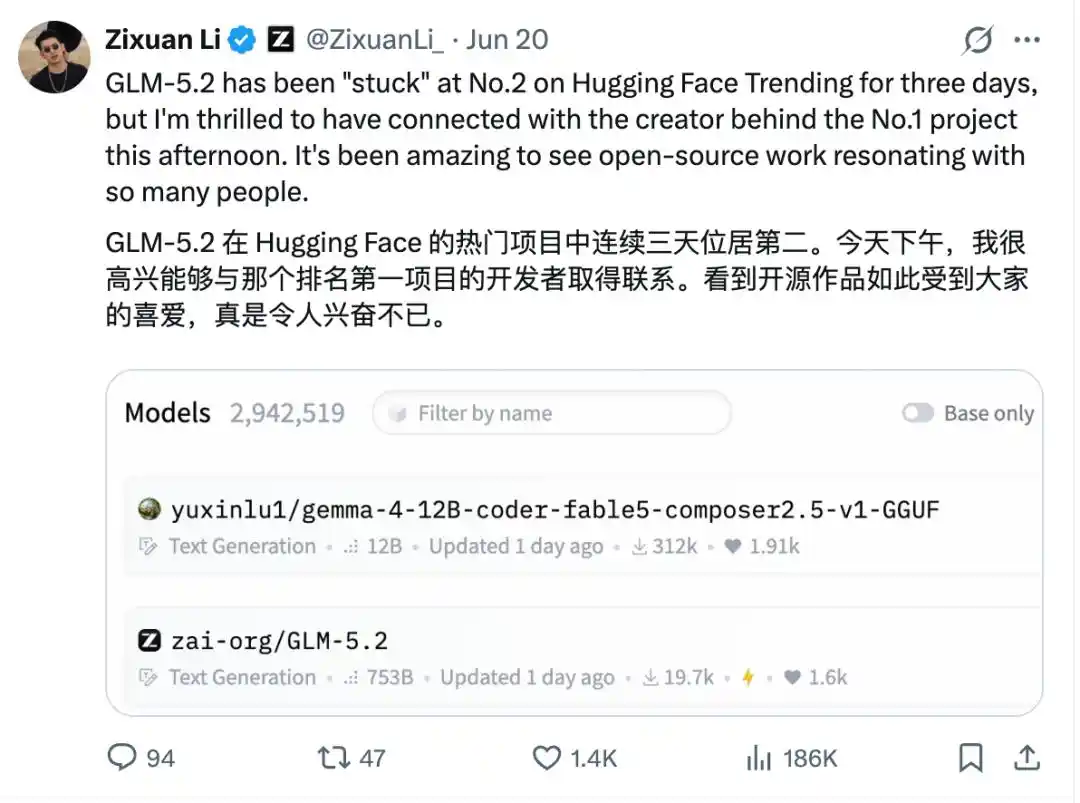
Es decir, entre nombres como Zhipu, Baidu, Qwen, NVIDIA... una cuenta de desarrollador individual se ha abierto paso en el TOP, y con descargas tan altas.
No puedo evitar preguntarme: ¿Quién es luyuxin? ¿Cómo tiene tanta influencia?
Un "modelo amateur" escala en la lista de tendencias de Hugging Face
En esta lista de tendencias de Hugging Face, las primeras posiciones están básicamente ocupadas por grandes empresas, equipos destacados y campos populares.
Por ejemplo, Zhipu GLM-5.2, con 753B parámetros, es un modelo grande estrella nacional; Baidu Unlimited-OCR, aprovecha la reciente moda de OCR y comprensión de documentos.
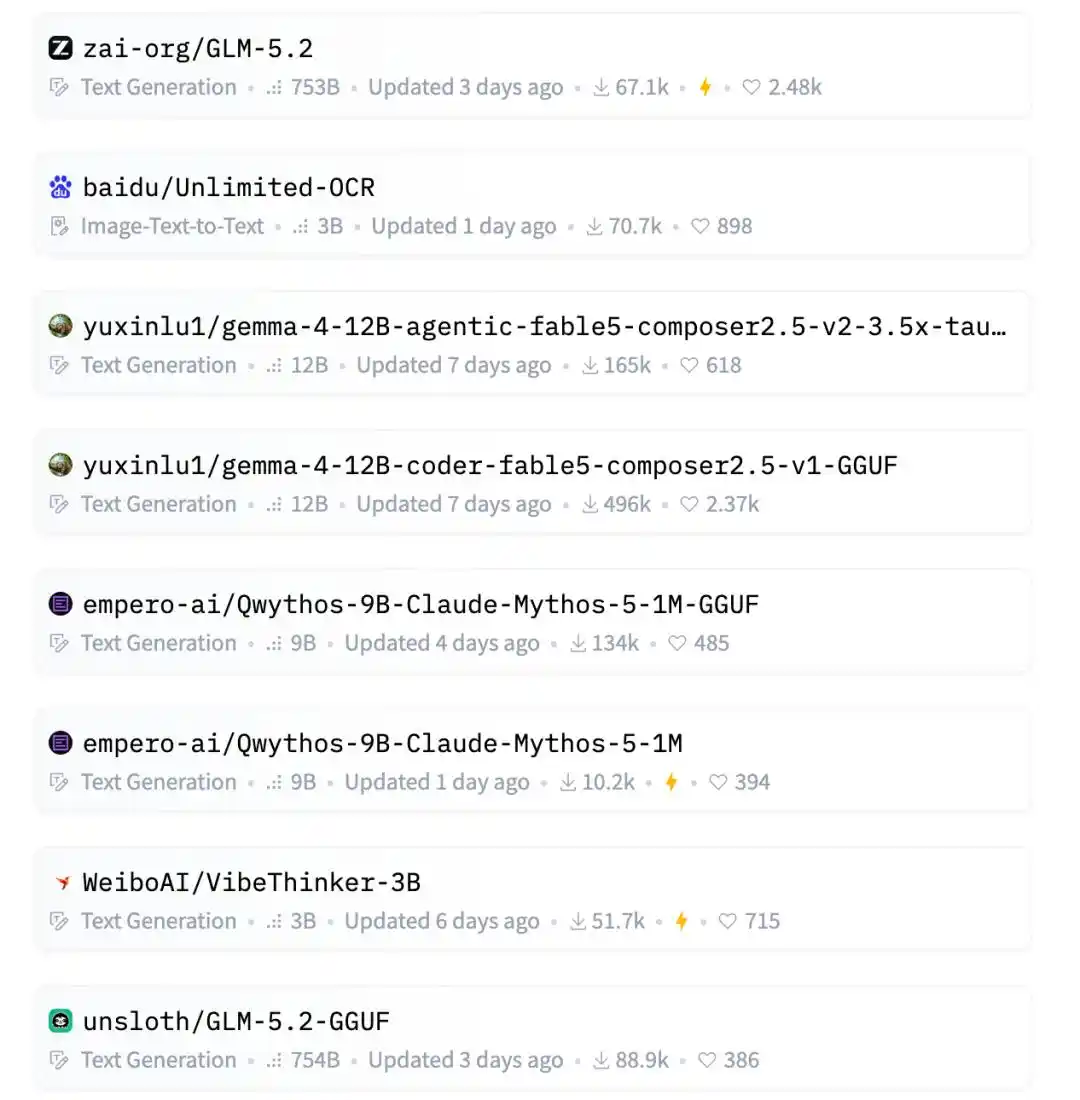
Más abajo también están AgentWorld de Qwen, LocateAnything de NVIDIA, FastContext de Microsoft.
Los rostros familiares de los grandes modelos de código abierto nacionales también están presentes: MiniMax M3, Kimi-K2.7-Code, DeepSeek-V4-Pro.
En generación de imágenes también está Krea, con sus nuevos modelos Krea-2-Turbo y Krea-2-Raw en la lista.
Y justo en medio, también hay dos modelos GGUF de 12B de luyuxin.
No... luyuxin, tú también eres demasiado llamativo...
Mirando con atención, estos dos nuevos modelos principalmente destilan la capacidad de razonamiento de programación de Fable 5 en un modelo pequeño Gemma4-12B que se puede ejecutar localmente.
Funciona con solo 4.5GB de memoria de video, local, sin conexión, costo cero de API. Un jugador común con una tarjeta gráfica de consumo, o incluso una Mac con memoria unificada, puede ejecutarlo.
Los dos modelos tienen funciones diferentes.
V1 es la versión Coder, especializada en escribir código, resolver problemas, generar código ejecutable.

Según la tarjeta del modelo, sus datos de entrenamiento son de razonamiento de código "verificable": cada cadena de pensamiento correspondiente al código realmente ha pasado pruebas y se ha retenido solo si son exitosas.
Los datos del maestro provienen principalmente del Composer 2.5 de Cursor, más Fable 5—los problemas que Composer 2.5 resolvió incorrectamente se pasaban a Fable 5 para razonar de nuevo, generando nuevas cadenas de razonamiento y código correcto.
Tras el lanzamiento de V1, ocupó el primer lugar en la lista Trending de Hugging Face durante varios días seguidos.
V2 es la versión agentic, agrega capacidades de llamada de herramientas en múltiples pasos, puede usarse como un Agente local, capaz de leer, razonar, actuar y verificar por sí mismo.
El autor también ejecutó un benchmark—en el subconjunto telecom de tau2-bench, el modelo base gemma-4-12B obtuvo 15%, la versión V2 obtuvo 55%, aproximadamente 3.5 veces la performance base.

Sin embargo, el autor también señala que estos son valores relativos de autoevaluación local, en un solo dominio, con 20 tareas, y no se pueden comparar directamente con la lista oficial. También admite que todavía hay una brecha considerable con los grandes modelos fronterizos.
El autor también menciona: Fable 5 fue retirado posteriormente, solo su propio conjunto de datos conserva el proceso de razonamiento "original" de Fable 5.
En cuanto a la parte de reasoning que falta en los datos contribuidos por la comunidad, él usó Claude Opus 4.8 (xhigh) para regenerarlos y completarlos uno por uno.
También admite que las trayectorias reconstruidas "pueden diferir de la versión original de Fable 5", pero era la única opción viable en ese momento.
También reveló en el foro que este conjunto de datos de fine-tuning en realidad solo tiene alrededor de 10,000 ejemplos. Enfatiza que la cantidad de datos no es tan importante como uno podría pensar, lo verdaderamente clave es la calidad, el filtrado y la verificación.
Hay otra razón muy práctica por la que estos modelos han alcanzado tanta popularidad en Hugging Face: se pueden ejecutar localmente.
Ambos modelos están en la versión cuantizada GGUF.
GGUF es un formato de modelo local común en el ecosistema de llama.cpp, los usuarios pueden cargarlo directamente con herramientas como llama.cpp, Ollama, LM Studio, Jan, etc.
Esto es especialmente atractivo para escenarios de programación. Después de todo, escribir código, revisar repositorios, ejecutar comandos, depurar errores, a menudo involucra proyectos privados y entornos locales. Poder ejecutarlo en la propia máquina significa no tener que enviar el código a la nube, ni pagar costos de llamadas API cada vez.
Y lo más importante, el umbral no es muy alto.
La tarjeta del modelo V1 indica que la versión más pequeña Q2_K ocupa aproximadamente 4.5GB, solo se necesitan alrededor de 4.5GB de memoria de video o memoria unificada para ejecutar un asistente de programación privado y sin conexión.
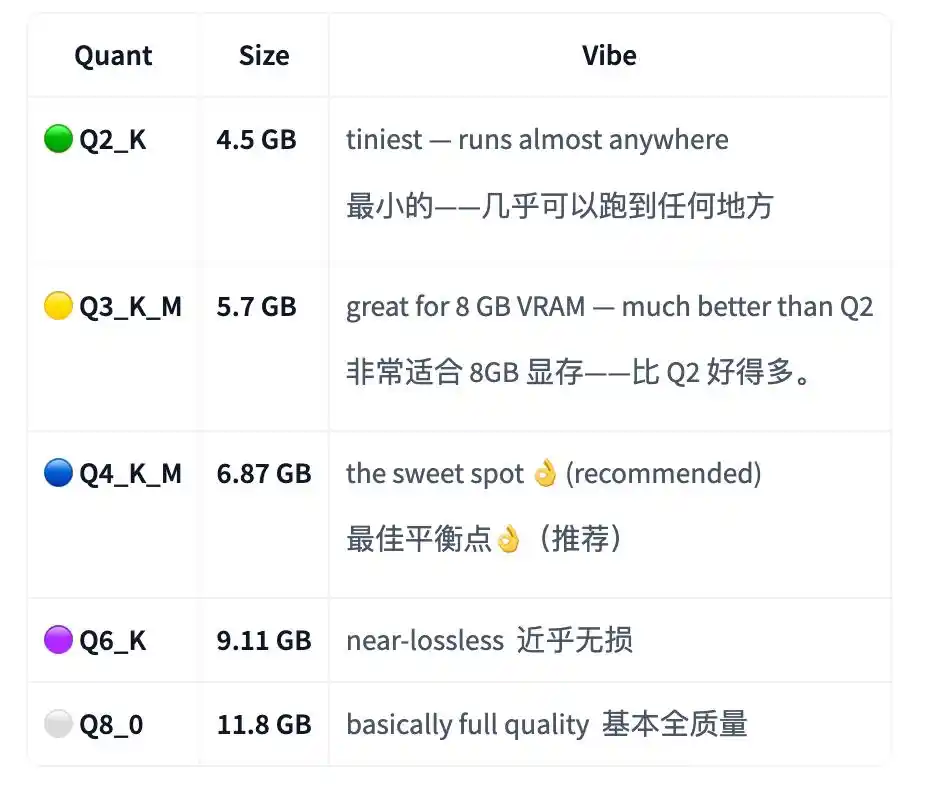
El punto óptimo recomendado por el autor es Q4_K_M, con un tamaño de aproximadamente 6.87GB; la versión de mayor calidad Q8_0 ocupa aproximadamente 11.8GB.
Como V2 está más orientado a agentic, el autor no publicó Q2_K. La razón es que no pasó las pruebas de estrés, no es lo suficientemente confiable.
Por lo tanto, la versión mínima confiable de V2 comienza desde Q3_K_M, aproximadamente 5.7GB; el Q4_K_M recomendado sigue siendo aproximadamente 6.87GB.
El autor también adelantó planes futuros—V3 ya está en camino.
Indicó que V3 continuará trabajando en la dirección de coding+agentic siguiendo la línea de 12B. Dice que ni siquiera él esperaba que la mejora de este post-entrenamiento fuera tan grande, así que continuará avanzando.
Especialmente en telecom de tau2-bench, V2 todavía tiene algunos problemas de "intento excesivo, reintentos repetidos", que V3 intentará corregir con más entrenamiento.
Por otro lado, también está trabajando en una versión más grande: Qwen3.6-27B. Equivalente a aplicar la misma receta de coding+agentic a una base más grande, para usuarios con más memoria de video disponible.
Una persona, 40 horas, se abre paso entre las grandes empresas
Lograr escalar solo a la lista de tendencias de Hugging Face, con descargas que suman más de 70 mil, abriéndose un lugar entre tantas grandes empresas e instituciones.
¿Quién es exactamente este autor?
Después de contactar al autor, también conocimos su historia.
Se llama Lu Yuxin, actualmente es un estudiante de posgrado en IA en una universidad de EE.UU., su licenciatura fue en Análisis de Datos y Negocios, en el medio también se especializó en desarrollo full stack, aprendiendo frontend, backend, desarrollo de software, procesamiento de datos.
Estos dos modelos exitosos no son su trabajo principal, sino un proyecto personal financiado totalmente por él mismo.
"El código abierto en realidad solo cuesta dinero, no te genera ningún ingreso." Él es muy consciente de esto, por lo que su motivación inicial para V1 fue en realidad "superación personal":
El conocimiento enseñado en la universidad se actualiza muy lentamente, durante su posgrado los profesores todavía enseñaban contenido de hace dos o tres años, y la IA avanza rápidamente, así que decidió usar este proyecto para obligarse a mantenerse al día con lo más nuevo.

Para hacer estos modelos, gastó un paquete completo de Claude Max 20×, solo V2 le tomó más de 40 horas.
Sintetizando datos uno por uno, limpiando manualmente, entrenando, evaluando, reentrenando, casi todo lo hizo solo.
En hardware, usó una RTX 5090, con 32GB de VRAM; además tiene alrededor de 96GB de recursos SSD local que puede usar. La escala real de recursos que puede movilizar es de aproximadamente 128GB.
No está mal para un desarrollador individual, pero no se compara con los pools de cómputo de las grandes empresas y los laboratorios de IA.
Le dijo a Quantum Bit que lo que más tiempo consumió en todo el proceso no fue el entrenamiento, sino el procesamiento de datos.
Especialmente los datos agentic, los diálogos reales suelen ser largos, una tarea puede tener una docena de pasos, miles o incluso decenas de miles de tokens. Pero limitado por la memoria de video, durante el entrenamiento solo podía alimentar un máximo de 2048 tokens a la vez.
Así que hizo un procesamiento similar a una "ventana deslizante": en cada sesión de múltiples turnos, tomando el último mensaje del usuario como punto de anclaje, centrándose en una llamada de herramienta, recortaba el contexto dentro del presupuesto disponible.
V1 y V2 usan Gemma 4-12B como base. No la eligió porque fuera fácil, al contrario, el formato de Gemma 4 y los protocolos de herramientas son relativamente especiales, adaptarse es complicado, incluso muchos clientes no los soportan completamente.
Lu Yuxin indica que, por un lado, es un desafío personal; por otro lado, porque el tamaño de 12B es muy atractivo.
Calculó que si se cuantiza a alrededor de 3 bits, muchos usuarios de Mac con 8GB de memoria unificada también podrían ejecutarlo, e incluso dejar cierto margen para la ventana de contexto.
Ahora sé que muchas personas todavía usan computadoras con alrededor de 8GB de memoria unificada. Así que quería, con la mayor cantidad posible de parámetros, permitir que más personas lo usen.
Lu Yuxin resume el valor de los modelos locales en dos palabras:
Privacidad, gratuito.
Cree que muchas personas solo quieren que la IA les ayude a organizar archivos, procesar datos, hacer presentaciones, o experimentar con un agente, y no necesariamente están dispuestas a pagar mensualmente por Claude o GPT.
La gente quizás solo quiere probar, ¿por qué tiene que ser de pago?
Después del lanzamiento de V1, inicialmente no prestó mucha atención a la lista, solo dijo en la tarjeta del modelo como siempre: si a la gente le gusta, y hay muchas descargas y likes, continuaría con V2.
Para su sorpresa, después de dos o tres días, el modelo de repente saltó de quién sabe qué posición al octavo lugar; después de dormir, escaló al primero.
Luego, comenzaron a llegar muchos comentarios e issues.
Casi los revisaba todos. En el momento más intenso, pasaba tres o cuatro horas diarias leyendo comentarios en Hugging Face, respondiendo preguntas, probando comentarios de usuarios, y luego comunicando los resultados.
Señaló: "La comunidad tiene necesidades, y realmente las estoy abordando, eso es lo más crucial."
Resulta que también le gusta leer novelas web...
En HF, Lu Yuxin ha publicado un total de 9 modelos públicos, aparte de los dos exitosos, también ha hecho modelos que "distilan directamente a Claude".
Por ejemplo, gemma-4-12B-it-Claude-4.6-4.8-Opus-GGUF, puede entenderse como un modelo de destilación de propósito general de Gemma4-12B.
No se limita a la programación, sino que más bien comprime el estilo de respuesta, los hábitos de razonamiento y la capacidad de thinking de Claude Opus en este modelo local de 12B.
Otro modelo directamente toma como base el modelo de programación Mellum2 de JetBrains, especializado en destilación de razonamiento.
Continuando mirando más abajo...
Espera, ¿cómo es que también hay modelos de fine-tuning de novelas web?

Vaya, y están divididos en cuatro géneros, todos son LoRA de novelas web chinas, y todos basados en Qwen3.6.
Lu Yuxin le dijo a Quantum Bit que este fue en realidad su punto de entrada inicial para comenzar a hacer modelos en Hugging Face.
Porque a él mismo le gusta leer novelas. Al seguir una novela que no ha terminado, los lectores se ansían; los autores que escriben diariamente también trabajan duro.
Así que quería hacer una pipeline completa y gratuita para generar novelas, usando diferentes estilos de LoRA de novelas chinas, permitiendo a los autores acelerar con IA, y a los lectores ver el contenido más rápido.
Pero los LoRA de novelas chinas no son tan populares en HF, luego descubrió que los usuarios estaban más interesados en coding y agentic, así que la dirección gradualmente se trasladó a la línea actual.
Cuando se le preguntó qué consejos tiene para otros desarrolladores individuales, Lu Yuxin dijo: La sinceridad y la perseverancia son lo más importante.
Sinceridad, significa no exagerar las capacidades del modelo. Dónde es fuerte, dónde es débil, hay que decirlo claramente.
Debes informar honestamente a todos. Si te engaño diciendo que esto es muy fuerte, pero en el uso real surgen muchos problemas, la próxima vez que publique algo, ya no confiarás en mí.
Perseverancia, significa que el autor de código abierto debe aceptar esto: definitivamente encontrarás voces negativas.
Después de que el modelo se hizo popular, Lu Yuxin también enfrentó dudas, pero aún así decidió persistir.
En su opinión, el camino del código abierto ya es difícil de por sí.
Incluso alcanzando el primer lugar en la lista de tendencias de Hugging Face, no genera ingresos directamente. La mayoría de las veces, es gastar dinero propio en cómputo, tiempo procesando datos, respondiendo comentarios, corrigiendo errores, y luego enfrentar algunas voces negativas.
Y lo que lo sostuvo en el camino fue un ritmo de trabajo muy personal.
Lu Yuxin menciona que padece TDAH.
En el pasado, esto podría haber significado dificultad para avanzar paso a paso a largo plazo en una tarea, pero en el campo de la IA que cambia tan rápido, cambiar rápidamente de interés, entrar rápidamente en hyperfocus, se convirtió en una ventaja.
Incluso cree: "La era de la IA es el dominio del TDAH." Porque cuando una dirección pierde interés, si sigues profundizando en ella, cuando finalmente cambies para aprender algo nuevo, quizás ya sea tarde.
Al final de la conversación, también planteamos la pregunta inicial:
Como desarrollador individual, ¿cómo es posible abrirse paso entre las grandes empresas para llegar a las primeras posiciones?
La respuesta de Lu Yuxin es muy sensata.
Cree que las grandes empresas ciertamente pueden hacerlo mejor, tienen más investigadores y más potencia de cómputo.
Pero cuando las grandes empresas publican modelos pequeños de código abierto, a menudo también tienen objetivos de promoción de marca, atracción de API, etc.; mientras que los desarrolladores individuales no tienen estas cargas, y pueden concentrarse más en resolver un punto doloroso específico.
Estoy contento, pero no es que realmente los haya derrotado en todos los aspectos, simplemente puede que haya sido más diligente.
En su opinión, esta es precisamente la oportunidad para los autores individuales de código abierto: no es necesario hacer un modelo completo, sino hacer que un problema suficientemente específico sea útil.
Si también quieres probar este modelo local, el enlace está a continuación.
Aviso: la plataforma más compatible actualmente es llama.cpp</strong, ¡se recomienda usarla de manera prioritaria~
Dirección HF: https://huggingface.co/yuxinlu1
Este artículo proviene de la cuenta de WeChat "Quantum Bit" (ID:QbitAI), autor: Atención a Tecnologías de Vanguardia