Título original: DeepSeek's 10 trillion USD grand strategy
Autor original: @bookwormengr
Traducción original: Peggy, BlockBeats
Nota del editor: En el último año, la discusión en torno a DeepSeek se ha centrado principalmente en el rendimiento del modelo, la estrategia de código abierto y la guerra de precios. Pero si entendemos a DeepSeek solo desde la perspectiva de "vender o no suscripciones", "tener o no multimodalidad", "poder o no hacer de agente de programación", probablemente estemos subestimando lo que realmente quiere cambiar.
Este artículo plantea un juicio más radical: el objetivo de DeepSeek no es necesariamente monetizar a corto plazo en la capa de aplicación, sino remodelar la estructura de costes del entrenamiento y la inferencia de IA a través de una serie de innovaciones en la arquitectura subyacente, e impulsar indirectamente la formación de un nuevo ecosistema de hardware. Desde MoE y MLA, hasta DSA, CSA, mHC y Engram, pasando por Dual Path y TileLang, la ruta tecnológica de DeepSeek siempre se ha centrado en una cuestión central: cómo obtener modelos más potentes utilizando menos capacidad de cálculo de gama alta, en un contexto de limitaciones en HBM, procesos avanzados, empaquetado y el ecosistema CUDA.
Lo más destacado del artículo no es "si DeepSeek puede ganar unos cientos de millones de dólares con su API o suscripciones", sino si está vinculando la capacidad del modelo, el sistema de memoria y el ecosistema de hardware nacional. La compresión de KV Cache reduce la dependencia del HBM, la memoria NAND y los SSD pueden asumir el caché de larga duración, la LPDDR se puede utilizar para la carga en streaming de pesos y el almacenamiento Engram, mientras que TileLang intenta debilitar la ventaja competitiva de CUDA. Si estas innovaciones se difunden continuamente, los beneficiarios no serán solo DeepSeek, sino también el almacenamiento, los ASIC, las GPU, los chips de red y toda la cadena de infraestructura de IA.
Por supuesto, los juicios del artículo sobre un "ecosistema industrial de 10 billones de dólares" y una "valoración de 1 billón de dólares" todavía tienen un fuerte carácter especulativo. Pero proporciona una vía importante para entender a DeepSeek: el código abierto no significa necesariamente renunciar a la comercialización, y los precios bajos no son solo subsidios al mercado. Para DeepSeek, el verdadero negocio puede no estar en la capa de aplicación, sino en ayudar a que más hardware sea utilizable y hacer posible una oferta de IA de menor coste. En otras palabras, lo que vende quizás no sea el modelo en sí, sino la viabilidad de la próxima generación de infraestructura de IA.
A continuación, el texto original:

¿Te has preguntado alguna vez cómo va a ganar dinero DeepSeek, y posiblemente mucho dinero?
No ha lanzado un plan de suscripción competitivo para programación como GLM, MoonShot y MiniMax; tampoco tiene modelos multimodales, de audio o de vídeo. Hasta ahora, ni siquiera tiene su propio "harness", es decir, el marco de ejecución externo para la invocación del modelo, la conexión de herramientas y la ejecución de tareas, aunque recientemente han comenzado a contratar para puestos relacionados, preparándose para construir este sistema.
Mientras tanto, DeepSeek parece mantenerse firme y a largo plazo del lado del código abierto, incluso compartiendo gustosamente sus "secretos". ¿No es esto una locura? ¿No es como quemar dinero? ¿Acaso los inversores que están preparados para invertir 100.000 millones de dólares están tirando el dinero por el desagüe?
Personalmente, creo que la respuesta es todo lo contrario.
A continuación, basándome en lo que DeepSeek ha hecho hasta ahora, presentaré algunas observaciones y analizaré la estrategia que parece estar siguiendo. El objetivo del CEO de DeepSeek, Liang Wenfeng, podría ser mucho más grande que la competencia actual de modelos. Quizás esté apuntando a un premio mayor: DeepSeek tiene la oportunidad de alcanzar una valoración de 1 billón de dólares, impulsando al mismo tiempo la formación de una nueva industria de 10 billones de dólares.

Informe de TechInAsia sobre la última ronda de financiación de DeepSeek
Revisando el "viaje del héroe" de DeepSeek
DeepSeek siempre ha ido contracorriente. No ha optado por lanzar constantemente modelos un poco más potentes y luego empaquetarlos apresuradamente como aplicaciones directamente monetizables, como planes de suscripción para programación. El 27 de enero de 2025, publiqué un tuit muy difundido describiendo el "viaje del héroe" de DeepSeek tal como yo lo veía. Hoy, esta historia se ha vuelto aún más interesante.
Mientras otros intentaban construir modelos densos, DeepSeek eligió los más difíciles de entrenar: Modelos Mixtos de Expertos (Mixture of Experts, MoE).
Adoptaron un enfoque de "primeros principios", inventando un nuevo algoritmo GRPO para reemplazar el entonces dominante y más costoso algoritmo de aprendizaje por refuerzo PPO.
Descubrieron que el Aprendizaje por Refuerzo basado en Recompensas Verificables (Reinforcement Learning from Verified Rewards, RLVR) era una estrategia clave para mejorar la capacidad de razonamiento del modelo.
También propusieron una estrategia simple de decodificación especulativa a través de la "Predicción de Múltiples Tokens" (Multi Token Prediction), al mismo tiempo que hacían que la señal de entrenamiento fuera más densa.
Perfeccionaron el pipeline "burbuja cero" (ZERO bubble) para mejorar la eficiencia del uso de recursos limitados de GPU.
Publicaron un equilibrador de carga de expertos, facilitando que todos pudieran desplegar modelos MoE. Especialmente a través de la estrategia de "Paralelismo de Expertos Amplio" (Wide Expert Parallel), los modelos podían servir con lotes más grandes, reduciendo significativamente los costes de inferencia.
Inventaron mecanismos como MLA, DSA, CSA, HCA para reducir la necesidad de KV Cache, y hacer que la demanda computacional que crece con la longitud del contexto se mantuviera lo más cercana posible a una constante.
Inventaron Engram, intercambiando memoria por eficiencia computacional.
También inventaron mHC, permitiendo un entrenamiento estable incluso cuando se amplía la escala del modelo. Hay muchos ejemplos similares.
En la narrativa más universal del "viaje del héroe", el héroe nunca decide al principio adónde conduce exactamente su viaje. Él va descubriendo su verdadera y gran misión a lo largo del camino, aprendiendo y completándola a pesar de los obstáculos. Encuentra muchos escépticos, pero elige ignorarlos. También se enfrenta a muchos actores malintencionados. Tiene defectos o debilidades evidentes, pero al final los supera y completa su misión. Se enfrenta a desafíos aparentemente insuperables, pero encuentra formas de aliarse y aprende a usar sabiamente recursos limitados y preciosos. Es esto lo que hace que el público quiera animar al héroe. Esta es también la razón por la que DeepSeek gana seguidores, respeto global y opositores.
Como detallaré a continuación, DeepSeek ha estado en este camino durante mucho tiempo y ha ido descubriendo gradualmente su destino final: su objetivo no es vender planes de suscripción para programación, sino impulsar un ecosistema de hardware de IA chino de 10 billones de dólares y lograr una valoración propia de 1 billón de dólares. En el proceso, también creará oportunidades para muchos nuevos participantes en el ecosistema de hardware occidental.

Empecemos con algunos cálculos interesantes sobre KV Cache
Mira este oportuno tuit reciente de @SemiAnalysis_:
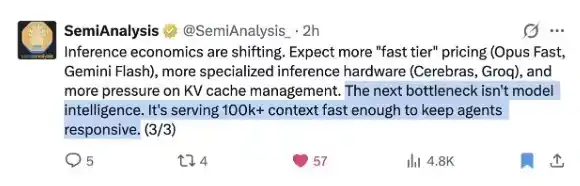
¡DeepSeek ha resuelto este problema mejor que nadie!
Hagamos primero algunos cálculos interesantes sobre KV Cache. No te preocupes, incluso si no te gustan las matemáticas. Usaremos la calculadora de KV Cache recientemente publicada para ver cuánto ahorro de KV Cache trae DeepSeek V4 Pro y compararlo con los últimos modelos GLM y Qwen.
Aquí calculo para una longitud de contexto de 1 millón, asumiendo una precisión KV de 8 bits y una precisión del indexador de 16 bits. También puedes probar tú mismo esta calculadora: https://kvcache.ai/tools/kv-cache-calculator/
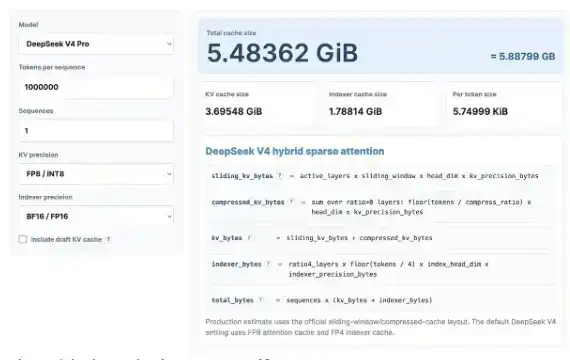
¡También puedes probar la calculadora tú mismo!
Con una longitud de contexto de 1 millón:
· DeepSeek V4 solo necesita 5.48 GB de HBM;
· GLM-5 necesita 60 GB de HBM;
· Qwen3-235B-A22B necesita hasta 89 GB de HBM.
Es importante tener en cuenta que:
· DeepSeek es un modelo de 1.6 billones de parámetros;
· GLM-5 tiene aproximadamente 700 mil millones de parámetros y ya adopta MLA y DSA de DeepSeek, aunque no utiliza el último mecanismo de atención comprimida;
· Qwen3-235B-A22B tiene aproximadamente 235 mil millones de parámetros y utiliza el mecanismo de atención GQA.
DeepSeek ya ha hecho contribuciones fundamentales para aliviar la presión sobre la memoria. Si este tipo de innovaciones se adoptan ampliamente, reducirán drásticamente el coste de ejecución de agentes de largo ciclo y desbloquearán la siguiente ola de nuevas aplicaciones.
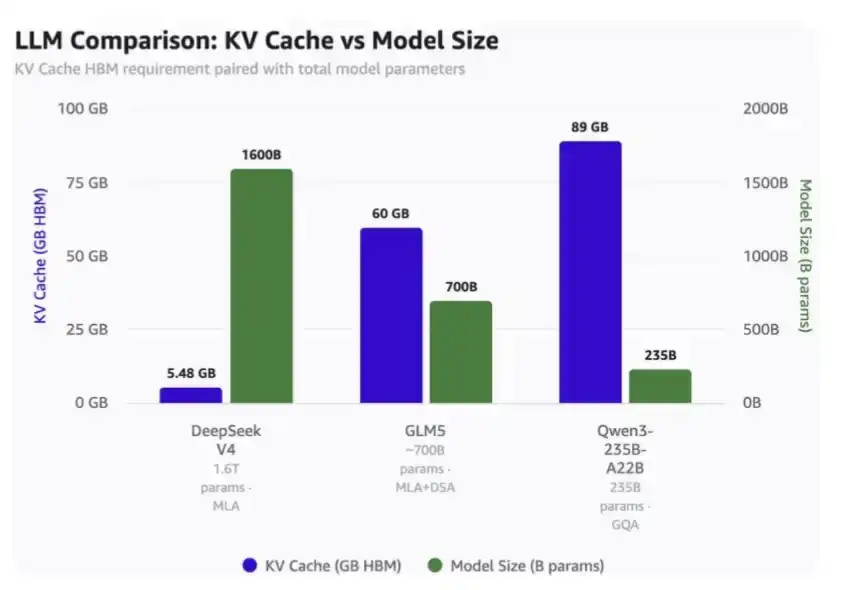
Comparación de la ocupación de KV Cache para un contexto de 1 millón de tokens y diferentes escalas de modelo
La metodología detrás de la "locura"
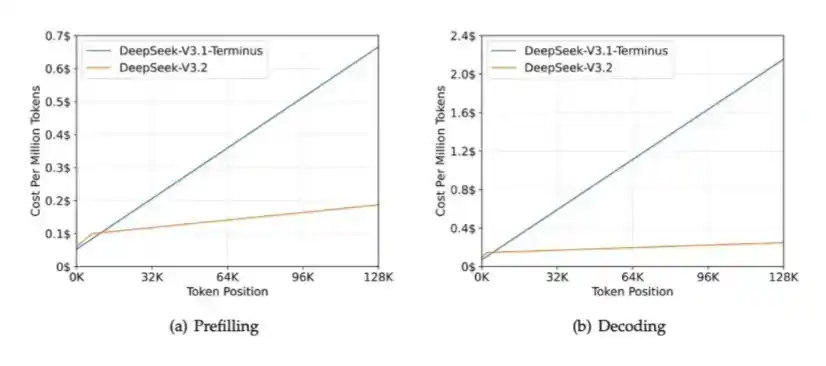
El hecho de que el volumen de KV Cache pueda ser tan pequeño sin sacrificar la calidad del modelo es precisamente la razón por la que DeepSeek puede ofrecer caché de larga duración a un precio extremadamente bajo: menos del 3% del precio de acierto de caché de Sonnet 4.6, y DeepSeek puede retener el caché durante horas.
Para tareas de largo ciclo, un KV Cache más pequeño significa que puede descargarse económicamente a SSD y recargarse cuando sea necesario. Esto reduce la dependencia del HBM. Desde la perspectiva de la industria de hardware de IA chino, el HBM no solo tiene suministro limitado, sino que también es uno de los tipos de memoria más difíciles de fabricar.
Además, DeepSeek ha desarrollado tecnología para cargar KV Cache desde SSD más rápidamente, como se describe en su artículo sobre Dual Path.
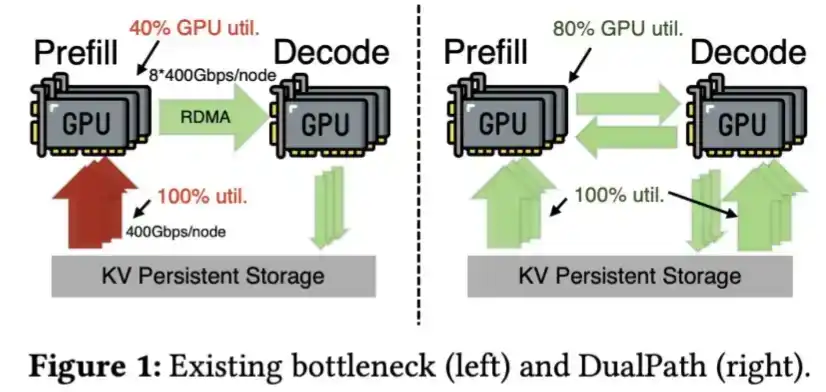
DeepSeek V4 comprime tanto el KV Cache que este paso podría incluso dejar de ser necesario.
Entonces, ¿quién se beneficia más directamente de la compresión de KV Cache?
¿Quién suministra SSD a gran escala? No olvidemos que YMTC (Yangtze Memory Technologies Co.) se está convirtiendo en un gigante en el campo de la NAND 3D. La NAND puede ayudar a DeepSeek a evitar recalcular el KV. A su vez, DeepSeek crea un mercado enorme para la NAND y los SSD, beneficiando no solo a YMTC, sino también a otros fabricantes relacionados.

Sin embargo, no se trata solo de NAND y SSD.
La memoria LPDDR también tiene un gran potencial. Puede servir como lugar para almacenar los pesos del modelo y transmitirlos en streaming al HBM cuando sea necesario, aliviando así la presión sobre la demanda de HBM. El equipo de SGLang publicó una buena entrada de blog al respecto. El siguiente diagrama muestra cómo funciona este esquema.
Aunque DeepSeek no ha diseñado específicamente para este esquema, su arquitectura MoE, su gran cantidad de modelos expertos y sus pesos de 4 bits facilitan la implementación de este enfoque.
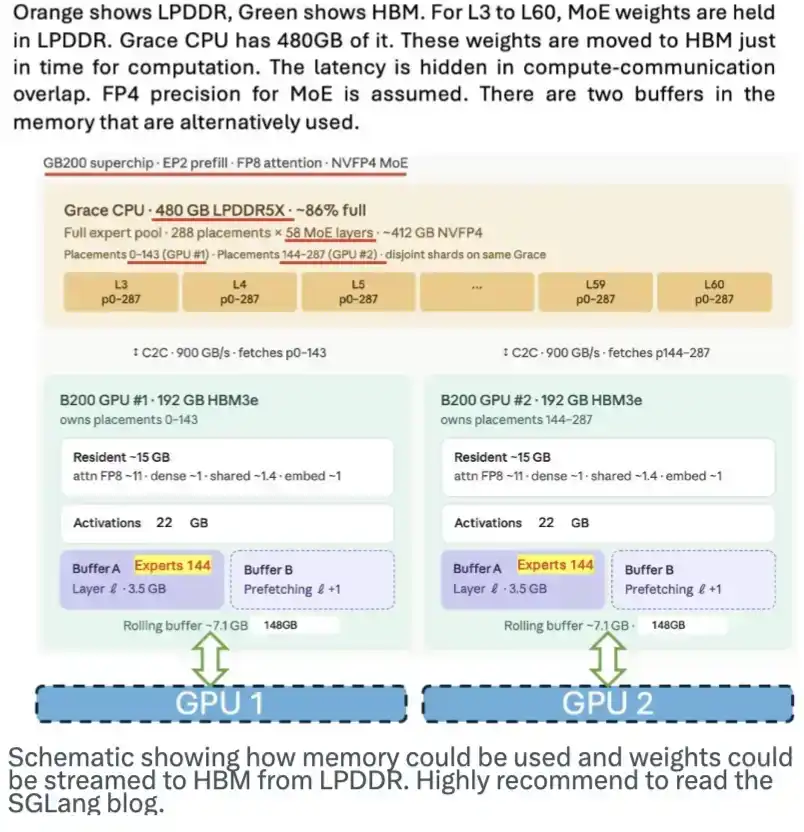
Este diagrama esquemático muestra cómo podría usarse la memoria y cómo los pesos del modelo podrían transmitirse en streaming desde LPDDR al HBM. Recomiendo encarecidamente leer la entrada del blog de SGLang.
Si se combina esta innovación con un KV Cache extremadamente compacto y sin pérdidas, se reducirá significativamente la necesidad de HBM.
Entonces, ¿quién produce LPDDR en China? La respuesta es CXMT, es decir, ChangXin Memory Technologies. Solo están aproximadamente medio generación atrás en velocidad de LPDDR y una generación atrás en densidad, la diferencia no es enorme.
Además de un suministro abundante de NAND, el ecosistema de IA chino también tendrá en un futuro próximo un suministro abundante de LPDDR. ¿Esto puede aliviar la presión sobre la capacidad de cálculo? Respuesta: Sí. Sigue leyendo.

El uso inteligente de la memoria también puede aliviar la presión sobre las GPU / ASIC
El uso de NAND para almacenar KV Cache es bastante fácil de entender: permite retener el KV Cache durante más tiempo, reduce la presión sobre el HBM y evita recalcular el KV Cache, aliviando así la carga computacional de las GPU y ASIC.
Entonces, ¿puede la LPDDR funcionar de manera similar? Además de ser una ubicación de almacenamiento desde la cual se pueden transmitir los pesos "bajo demanda" al HBM, ¿puede reducir aún más la presión computacional?
Respuesta: Sí.
La LPDDR se puede utilizar para almacenar grandes cantidades de contenido llamado Engram. En el artículo de Engram de DeepSeek, señalan que MoE puede expandir la capacidad del modelo a través de cálculo condicional, pero el Transformer carece de un mecanismo nativo de "búsqueda de conocimiento". Por lo tanto, los Transformers a menudo tienen que simular de manera ineficiente el proceso de recuperación a través del cálculo.
Para resolver este problema, DeepSeek propuso el módulo Engram. Modernizó el embedding clásico de N-gram, transformándolo en un mecanismo de búsqueda basado en hash O(1), creando así una ruta de esparcimiento complementaria que llaman memoria condicional (conditional memory).
Este enfoque puede ahorrar cálculo, pero también requiere memoria para albergar la tabla de embedding, que en sí misma puede ser muy grande.
Esencialmente, este es un esquema típico de "intercambiar memoria por cálculo". Pero la idea clave es: desde el coste de lectura por bit de datos, el lado de la "memoria" es mucho más barato: una búsqueda en LPDDR es mucho más barata que hacer que los datos pasen completamente por múltiples capas de Transformer para un cálculo hacia adelante. Por lo tanto, a gran escala, este es un intercambio muy rentable.
Así es como DeepSeek intercambia algo de memoria para ahorrar cálculo.
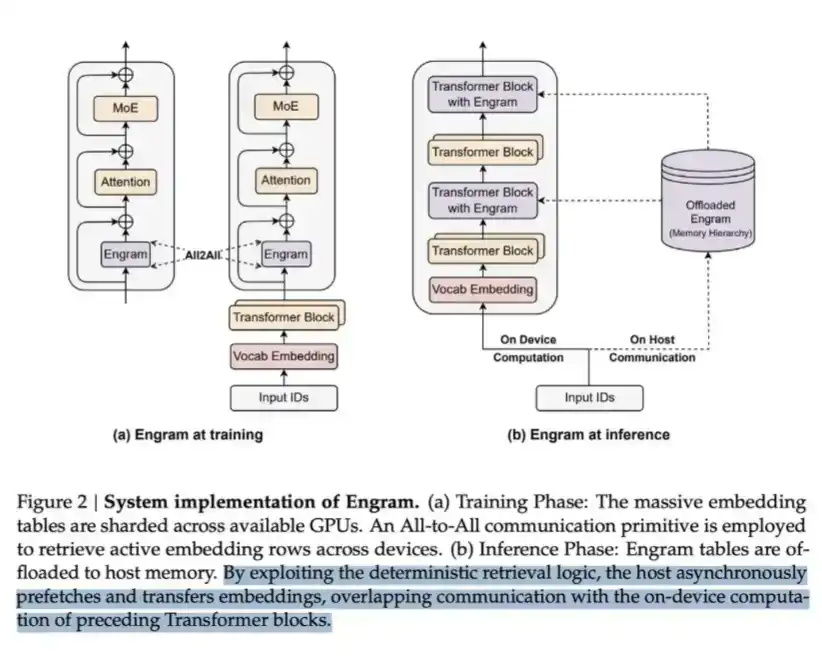
Un intercambio que vale la pena
Dado que no tienen la misma densidad de transistores en chips, ni EUV, es probable que las GPU y ASIC chinas sigan estando por detrás de las GPU occidentales en términos de potencia bruta de FLOPs a largo plazo. También tienen brechas evidentes en empaquetado avanzado. Por lo tanto, este tipo de intercambios valen mucho la pena, especialmente dado que China puede producir grandes cantidades de memoria NAND y LPDDR.
Revisando la estrategia a largo plazo de DeepSeek
A partir de estas innovaciones, el objetivo de DeepSeek parece no ser ganar unos cientos de millones de dólares en beneficios a corto plazo. Muchas de sus elecciones pasadas lo demuestran: hasta ahora no tiene multimodalidad, ni modelos de voz, y mucho menos modelos de vídeo.
En lo que realmente está participando es en un juego a largo plazo, potencialmente de 10 billones de dólares: impulsar la formación de un ecosistema alternativo de hardware de IA.
Esto no es solo para que los fabricantes de memoria chinos se conviertan en actores clave en el mercado de hardware de IA chino y global, sino también para reducir fundamentalmente los requisitos de recursos, haciendo que el entrenamiento y servicio de modelos de IA sean más eficientes en costes. De esta manera, muchos fabricantes de GPU, ASIC y chips de red pueden convertirse en opciones viables.
Al mismo tiempo, estas innovaciones también beneficiarán al ecosistema de código abierto occidental y a los nuevos fabricantes de hardware.
Todos los indicios ya han aparecido. Repasemos en detalle las innovaciones que DeepSeek ha propuesto hasta ahora:
1. Modelo Mixto de Expertos (MoE) y MLA introducidos en DeepSeek V2
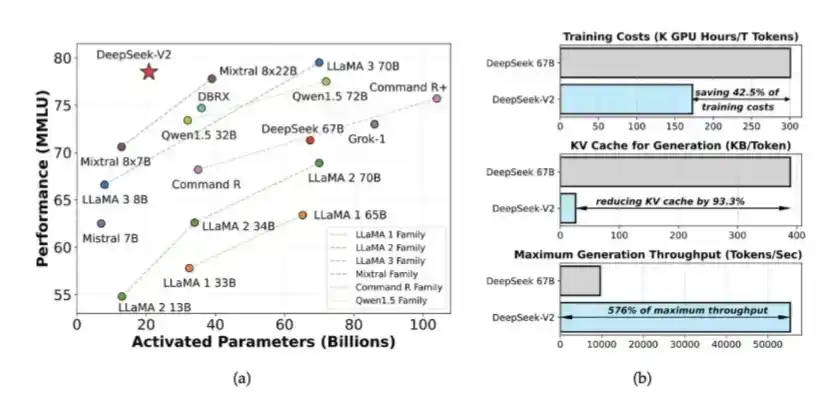
DeepSeek introdujo MoE y MLA en V2. MoE redujo la cantidad de cálculo necesario para entrenar modelos de alta inteligencia en aproximadamente un 40% a 50%; MLA redujo el KV Cache en un 90%.
Esto hizo que descargar el KV Cache a SSD fuera bastante eficiente.
Estas ideas aparecieron por primera vez en el artículo de DeepSeek V2 publicado por DeepSeek en mayo de 2024. Más tarde, también sentaron las bases para el entrenamiento de DeepSeek V3. En ese momento, DeepSeek entrenó un sistema con un rendimiento cercano al de los modelos propietarios utilizando solo 2048 GPU H800 con rendimiento reducido.
2. DSA: Introducido en DeepSeek V3.2 Exp para reducir la sobrecarga computacional en escenarios de contexto largo y aliviar la presión del ancho de banda del HBM.
El papel central de DSA es garantizar que la cantidad de cálculo no crezca continuamente con el aumento de la longitud del contexto. Observa el gráfico a continuación: a medida que aumenta la longitud del contexto, el tiempo de procesamiento de DeepSeek-V3.2 se mantiene básicamente estable.
3. mHC: Propuesto por DeepSeek en diciembre de 2025 en el artículo "mHC: Manifold-Constrained Hyper-Connections".
mHC es una innovación arquitectónica a nivel macro de DeepSeek que rediseña cómo fluye la información entre las capas del Transformer.
En el pasado, desde ResNet, los modelos solían usar conexiones residuales estándar, es decir, x + F(x). Lo que hace mHC es expandir el flujo residual en múltiples canales de información paralelos y permitir que el modelo mezcle de manera aprendible entre estos canales. La clave es que restringe la matriz de mezcla para que sea doblemente estocástica, es decir, la limita al politopo de Birkhoff a través de la proyección de Sinkhorn-Knopp. Esto garantiza matemáticamente que la amplitud de la señal pueda mantenerse estable sin importar cuán profundo sea el apilamiento del modelo.
Esto resuelve el problema de inestabilidad catastrófica que enfrentaban las Hyper-Connections sin restricciones. Las Hyper-Connections fueron propuestas inicialmente por ByteDance, pero sin restricciones, la amplificación de la señal explotaba hasta 3000 veces a una escala de 27 mil millones de parámetros, lo que finalmente hacía colapsar el entrenamiento por completo.
El coste computacional de mHC es bajo: solo agrega aproximadamente un 6.7% de sobrecarga real en el tiempo de entrenamiento, porque no cambia los FLOPs de las capas de atención o FFN, solo cambia cómo se enrutan las salidas de estas capas entre las capas.
Pero la mejora de rendimiento es bastante notable: a una escala de 27 mil millones de parámetros, mHC mejora 7.2 puntos en tareas de razonamiento de BIG-Bench Hard, 3.2 puntos en DROP, 2.8 puntos en tareas matemáticas de GSM8K y 1.4 puntos en tareas de conocimiento general de MMLU. Y estas mejoras se logran con la misma escala de modelo y un presupuesto computacional casi idéntico.
Esencialmente, mHC logra una mayor inteligencia por parámetro sin agregar FLOPs adicionales, al proporcionar a la red una topología de enrutamiento de información entre capas más rica y expresiva.
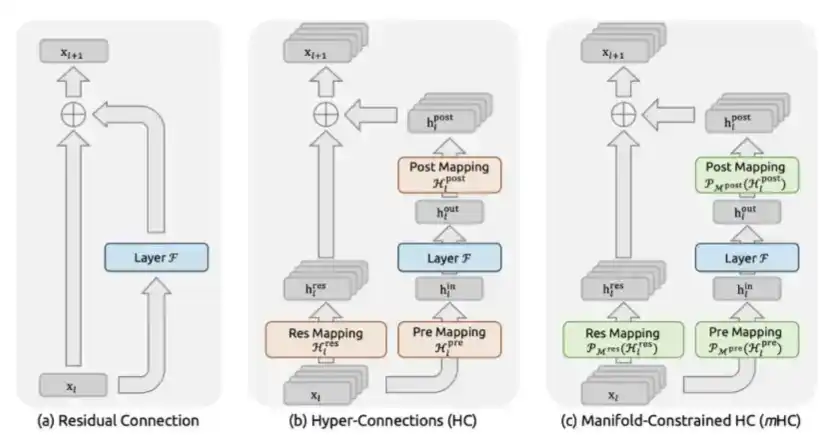
mHC es un diseño arquitectónico complejo, pero permite un proceso de entrenamiento más estable y una mayor inteligencia por parámetro.
4. CSA, HSA: Introducidos por DeepSeek en V4 en abril de 2026.
El objetivo de CSA y HSA es reducir la necesidad de KV Cache en otro 90% mediante la compresión de tokens KV, reduciendo significativamente los FLOPs requeridos y aliviando simultáneamente la presión sobre el HBM y las GPU / ASIC.
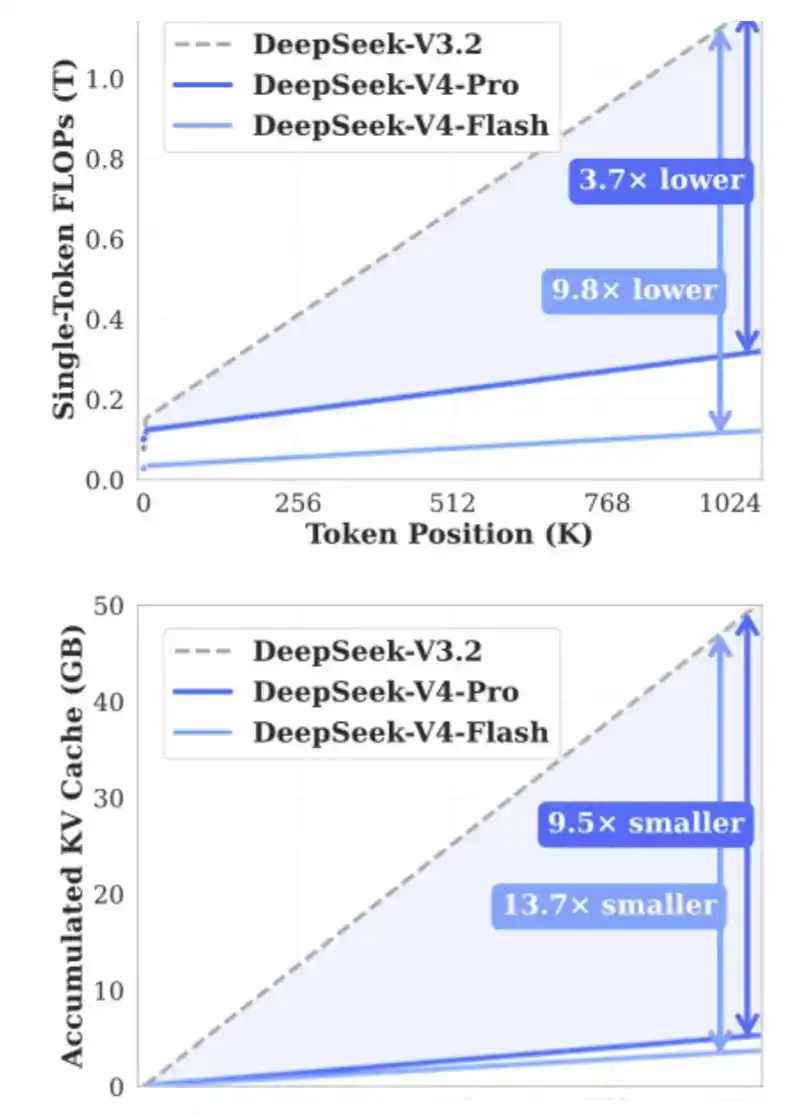
5. Engram: Introducido por DeepSeek en el primer trimestre de 2026, esencialmente intercambiando memoria, es decir, memoria LPDDR, por eficiencia computacional en cierta medida.
Como se muestra en el gráfico detallado a continuación, con el mismo presupuesto total de parámetros, Engram aporta una mejora de rendimiento notable.
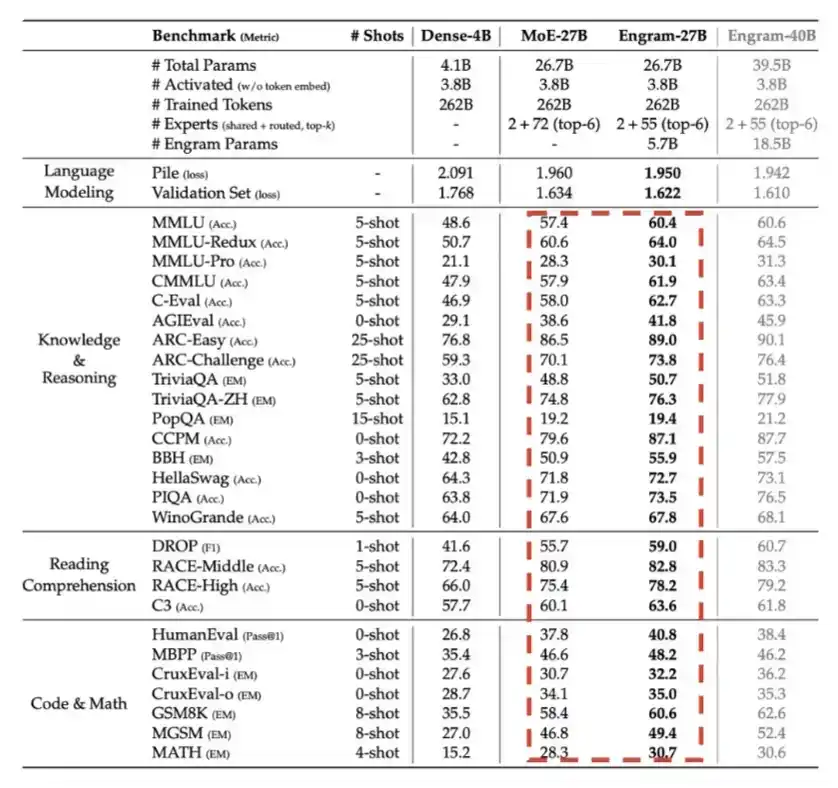
6. Engram: Introducido por DeepSeek en el primer trimestre de 2026, esencialmente intercambiando memoria, es decir, memoria LPDDR, por eficiencia computacional en cierta medida.
Como se muestra en el gráfico detallado a continuación, con el mismo presupuesto total de parámetros, Engram aporta una mejora de rendimiento notable.

Esta es la recomendación que DeepSeek compartió con los fabricantes de hardware en su artículo de V4. Estoy seguro de que en las conversaciones privadas dan aún más retroalimentación.
7. La inversión en TileLang también apunta en la misma dirección: DeepSeek no solo está resolviendo sus propios cuellos de botella de cálculo, sino que está impulsando la capacidad del ecosistema de hardware chino para competir con el occidental.
Con TileLang, los desarrolladores pueden escribir el kernel solo una vez, es decir, el código subyacente para el cálculo, y luego hacer que se ejecute con éxito en múltiples plataformas de hardware, siempre que estas plataformas tengan un backend de TileLang correspondiente.
Espero que otros laboratorios de IA chinos se unan gradualmente. Esto ayudará a los fabricantes de hardware chinos a abordar la llamada "ventaja competitiva de CUDA" de manera indirecta. Al mismo tiempo, también liberará el potencial de más hardware occidental, como AMD.
Es necesario aclarar que muchas plataformas de hardware de IA chinas ya ofrecen compatibilidad con CUDA o una capa de traducción de CUDA. Por ejemplo, Moore Threads, Metax, Biren y Tianshu Zhixin son fabricantes de chips chinos que logran un alto grado de compatibilidad con CUDA a través de capas de traducción. Por lo tanto, en teoría, no necesariamente necesitan TileLang.

Aprendizaje por refuerzo a gran escala y RSI
A medida que DeepSeek obtenga más fuentes de capacidad de cálculo, es decir, más opciones de hardware, y al mismo tiempo disminuya la demanda de recursos computacionales del propio modelo, podrá avanzar en proyectos de entrenamiento más ambiciosos, especialmente el post-entrenamiento por refuerzo.
El aprendizaje por refuerzo requiere generar muchas trayectorias, es decir, generar billones de tokens. Este proceso rápidamente se vuelve extremadamente costoso. Además, si se quiere entrenar un modelo con una longitud de contexto de 1 millón, se necesitan generar trayectorias de la misma longitud. Solo entrenando el modelo en estas trayectorias ultra largas se puede soportar realmente tareas de largo ciclo.
Además, al aumentar las opciones de hardware, DeepSeek tendrá acceso a más recursos de hardware, lo que impulsará la investigación automatizada, es decir, RSI. RSI se refiere a que la IA diseña y ejecuta sus propios experimentos. Este método implica mucho ensayo y error, y los costes aumentan rápidamente. Pero RSI es crucial para explorar el espacio completo de diseño de modelos. Antes de avanzar hacia AGI, y posteriormente hacia ASI, DeepSeek debe poseer capacidades de RSI.
Lo que DeepSeek hace hoy, toda la industria lo seguirá mañana
Las innovaciones de DeepSeek en torno a Modelos Mixtos de Expertos, MLA, DSA, etc., ya han sido adoptadas gradualmente por otros laboratorios de IA a nivel global y en China.
Por ejemplo, ZAI, el desarrollador de la serie de modelos GLM, utiliza MLA y DSA. Kimi, es decir, Moonshot, también adopta MLA y no evita afirmar que su arquitectura se basa en el diseño de arquitectura de DeepSeek. A su vez, DeepSeek también utiliza el optimizador Muon, que fue adoptado primero por Kimi (Moonshot) para entrenamiento a gran escala.
Es necesario aclarar:
MoE fue propuesto por primera vez por Google en 2017, siendo Noam Shazeer un autor clave. La contribución de DeepSeek radica en aplicar MoE a gran escala e inventar sus propios trucos complementarios.
Muon, es decir, el optimizador MomentUm Orthogonalized by Newton-Schulz, fue propuesto por el investigador de aprendizaje automático Keller Jordan a fines de 2024. El equipo de Kimi (Moonshot) fue el primero en utilizarlo para entrenamiento a gran escala.
¿Y qué hay del problema de ganar dinero?
Podemos mirar el interesante ejemplo de OpenAI.
OpenAI obtuvo warrants / opciones para comprar acciones de AMD y Cerebras a un precio bajo, vinculados a sus hitos de consumo de capacidad de cálculo. Para AMD y Cerebras, este fue un trato muy rentable. Porque una vez que OpenAI se compromete a usar su hardware, su probabilidad de éxito a largo plazo aumenta drásticamente.
El anuncio de AMD incluía este párrafo:
"Como parte del acuerdo, para alinear aún más los intereses estratégicos de ambas partes, AMD emitió a OpenAI warrants para comprar hasta 160 millones de acciones ordinarias de AMD, que se otorgarán gradualmente según el logro de hitos específicos. El primer lote se otorgará al completar el despliegue inicial de 1 gigavatio, y los lotes posteriores se otorgarán gradualmente a medida que la escala de adquisición se expanda a 6 gigavatios. Las condiciones de otorgamiento también están vinculadas a que AMD alcance objetivos de precio de acciones específicos y que OpenAI logre hitos tecnológicos y comerciales necesarios para un despliegue a gran escala por parte de AMD."

Espero que DeepSeek también llegue a acuerdos similares con múltiples fabricantes chinos de memoria, ASIC, CPU y tecnologías de red, colaborando profundamente con ellos para que sus pilas de hardware puedan manejar cargas de trabajo de IA líderes.
Considerando que la capitalización bursátil total de todas las acciones de IA occidentales, incluidos los aliados del este de Asia, supera con creces los 10 billones de dólares, este enfoque de "obtener retorno de capital a través de la cooperación" permitirá a DeepSeek ayudar a China a construir una industria igualmente enorme y obtener su parte del pastel, logrando finalmente su propia valoración de 1 billón de dólares.
Esto no solo hará que DeepSeek gane mucho más dinero que los negocios tradicionales de suscripción de aplicaciones, sino que también logrará su objetivo declarado de "hacer que AGI beneficie a todos". Liang Wenfeng es un gran admirador de Jim Simons y un jugador de capital lo suficientemente inteligente como para no perderse esto.
Si miras hacia atrás a todo lo que DeepSeek ha hecho hasta ahora, esta es la única explicación que tiene más sentido.
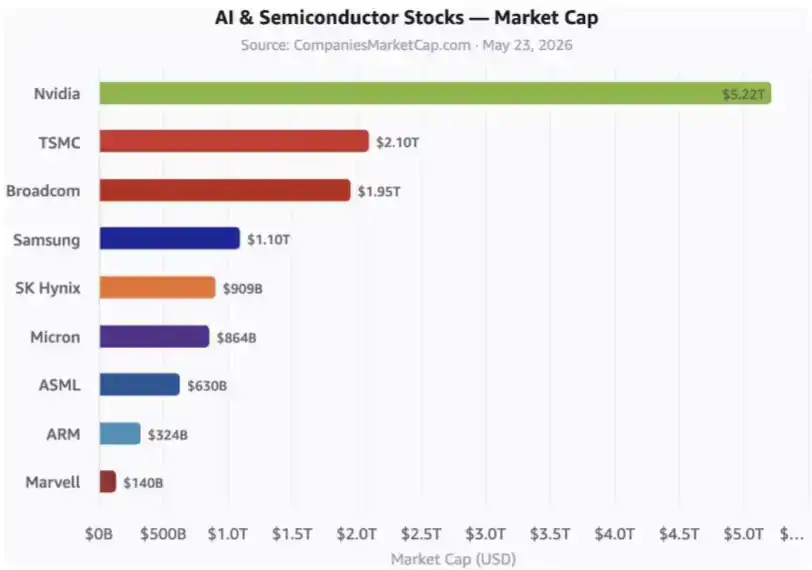
Estas son las acciones clave de IA. El gráfico aún no incluye a los hyperscalers, es decir, los grandes proveedores de nube, ni a muchas otras empresas relacionadas.
Enlace al artículo original