Por fin se ha lanzado DeepSeek V4. Este es un momento que se ha esperado durante casi cinco meses. El modelo principal MoE de 1T de parámetros + la versión Flash de 285B de parámetros, seguido de la versión Pro completa de 1.6T, todo liberado como código abierto en GitHub, bajo licencia Apache 2.0, con los pesos y el código de implementación publicados simultáneamente.
Nada más salir el modelo, el mercado de capitales respondió de tres formas independientes pero interconectadas.
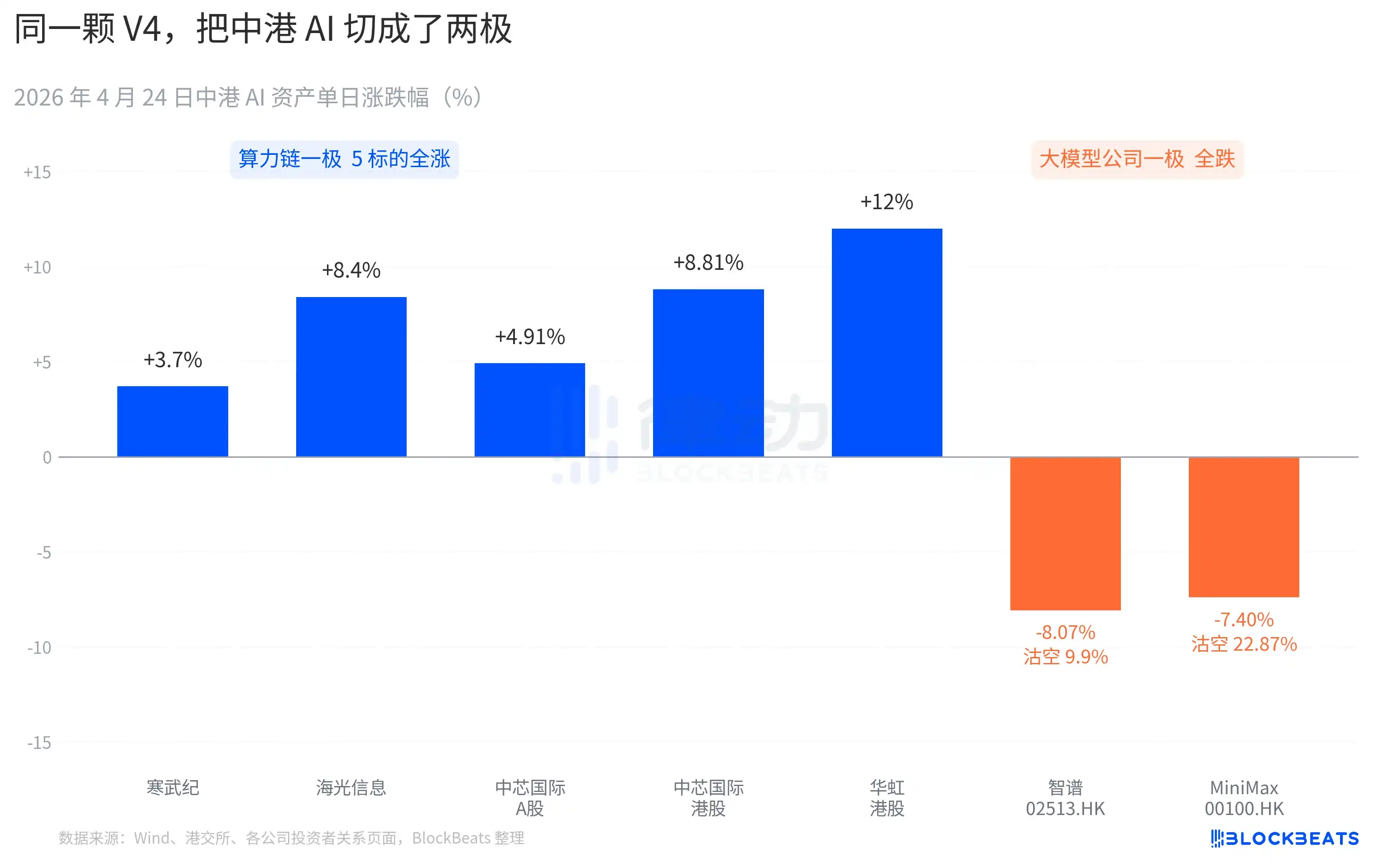
Diferentes reacciones del mercado de capitales
Por un lado, la cadena de capacidad de cálculo en las acciones A casi al completo experimentó saltos alcistas. Cambricon registró 11 días consecutivos en verde, con una subida del 3.7% en un solo día y una ganancia acumulada en el mes que supera el 60%. Hygon Information tocó el límite superior de +10% durante la sesión, cerrando con +8.4%. SMIC en acciones A +4.91%, en acciones H +8.81%. Huahong en acciones H llegó a subir hasta +18%, cerrando con +12%. El ETF Guotai de chips STAR recaudó 2400 millones de yuanes en un solo día, alcanzando un máximo histórico en tamaño.
Por otro lado, las empresas de modelos grandes en acciones H pintan otro color. Zhipu (02513.HK) cayó un 8.07%, con una proporción de ventas en corto del 9.9%. MiniMax (00100.HK) cayó un 7.40%, con una proporción de ventas en corto que se disparó al 22.87%. Este último es el dato de ventas en corto en un solo día más alto de la sección de IA en acciones H en los últimos tres meses. Ambas empresas son representativas de la oleada de salidas a bolsa de IA en acciones H de la segunda mitad de 2025, y en sus prospectos de OPV su competencia central se describe con la misma frase: "modelo base de gran tamaño de desarrollo propio".
La reacción al otro lado del Pacífico fue igual de concreta. NVIDIA abrió a la baja anoche con un -1.8%, llegando a caer hasta -2.6% durante la sesión, cerrando el día plano. El comentario rápido de mercado de Bloomberg comparó esta consolidación con el "momento DeepSeek" del V3 del 27 de enero. La diferencia es que aquella vez en enero fue una venta de pánico, con una pérdida de capitalización de 600.000 millones de dólares en un solo día. Esta vez se parece más a una reevaluación, de magnitud suave pero dirección clara. En las actas de investigación de las instituciones compradoras apareció una nueva expresión: "La demanda de inferencia de IA de China comienza a desacoplarse de la demanda de inferencia de IA de Norteamérica".
Superponiendo estos tres cuadros, tenemos la primera sentencia escrita por el mercado en las 24 horas posteriores al lanzamiento del V4. Tras la victoria del código abierto, el dinero comienza a elegir bando nuevamente. Lo que puede valorarse ya no es el modelo en sí, sino en qué tarjeta se ejecuta el modelo y en qué cadena industrial se instala.
11 nuevos modelos en 30 días, V4 añade leña al fuego del bando del código abierto
La ventana temporal del lanzamiento del V4 es en sí misma parte de la razón por la que esta reacción se amplificó.
Ampliando el enfoque a los últimos 30 días. Entre el 26 de marzo y el 24 de abril, se publicaron o actualizaron significativamente al menos 11 modelos grandes con influencia notable a nivel global, una lista que cubre a casi todos los jugadores principales. Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moonlight Dark Side Kimi K2.6, Alibaba Qwen3-Next, ByteDance Doubao 2.5 Pro, Tencent Hunyuan 3.0, Kimi K2.6 Plus, y finalmente DeepSeek V4, lanzado en la madrugada del 23 de abril.
De media, sale un nuevo modelo cada 2.7 días. Es una velocidad que ni los gestores de fondos pueden seguir leyendo los comunicados. Pero revisando las líneas K de los activos de IA en China y Hong Kong de estos 30 días, solo un nombre dejó una huella persistente en el cuadro. El GPT-5.5 del 8 de abril impulsó a NVIDIA a subir un 4.2% en un día, alcanzando el techo en una jornada. Luego, el DeepSeek V4 del 23-24 de abril, impulsando a la cadena de capacidad de cálculo de China y Hong Kong a registrar saltos alcistas consecutivos.
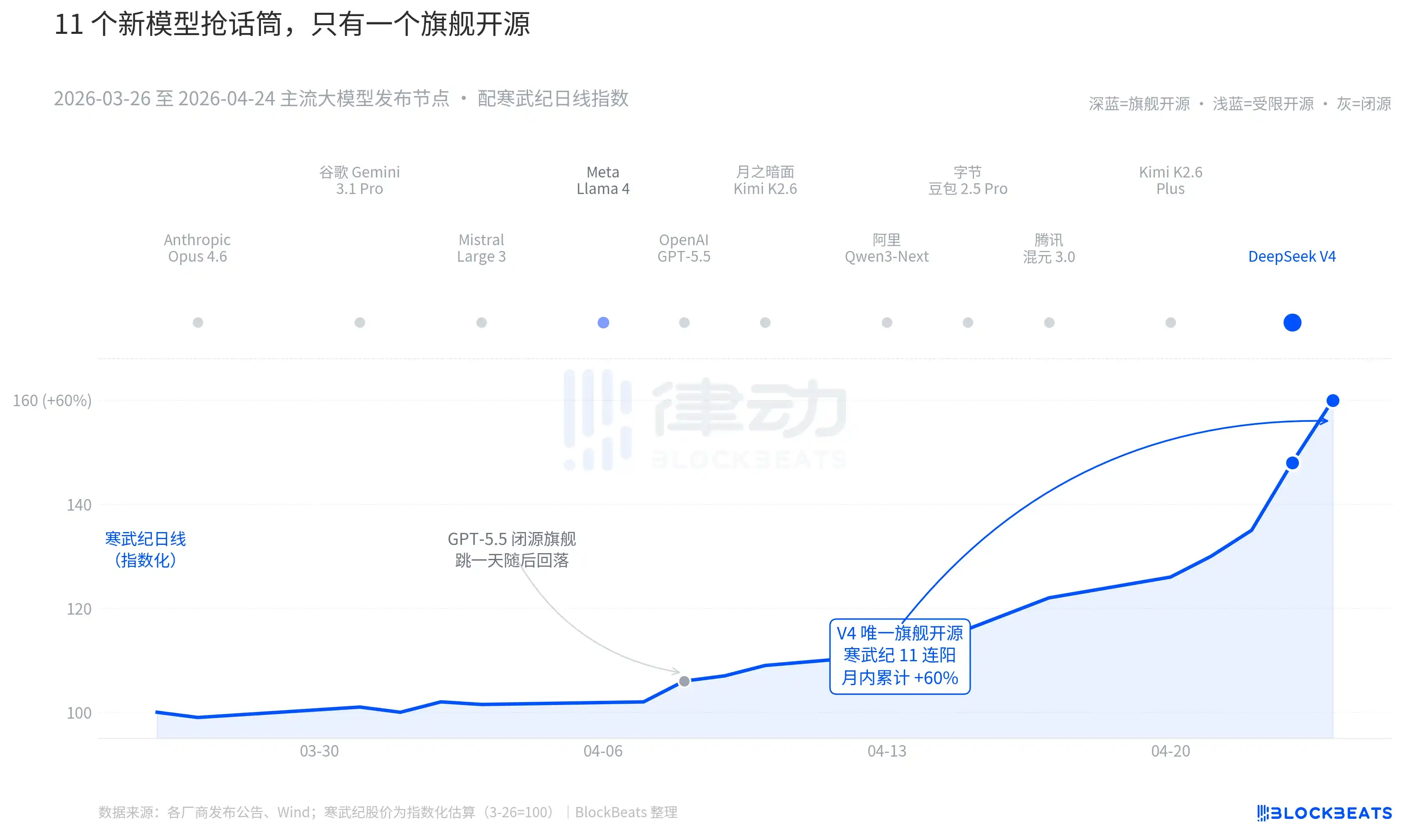
La diferencia no está en la capacidad del modelo en sí. La diferencia en el ranking LMArena entre estos 11 modelos, en la mayoría de los casos, no supera los 50 puntos, situándose en una banda estrecha de "la misma categoría". La diferencia está en la superposición de dos cosas.
La primera es el código abierto. De los primeros 10 modelos, solo Llama 4 era de código abierto, pero el acuerdo de pesos de Llama 4 incluía una larga lista de cláusulas restrictivas para uso comercial, recibiendo una evaluación fría por parte de la comunidad de desarrolladores occidental, y cayendo fuera del top 10 en OpenRouter al tercer día de su lanzamiento. El protocolo de V4 es Apache 2.0, sin barreras para los pesos, sin restricciones comerciales, y con el código de inferencia liberado simultáneamente. Este es el primer modelo insignia de código abierto en los últimos seis meses que presiona simultáneamente al bando de código cerrado en tres dimensiones: rendimiento, precio y grado de apertura.
La segunda es el momento. En el contexto de que el bando de código cerrado lanza continuamente grandes bazas, la narrativa del código abierto está siendo repetidamente presionada. Opus 4.6 llevó las tareas de código SWE-Bench a un nuevo máximo, GPT-5.5 estableció el punto de anclaje de hundimiento del precio por millón de tokens en 1.25 dólares. Si el código abierto puede alcanzar al cerrado, este debate lleva dos años en Silicon Valley. V4, con un modelo insignia de código abierto cuya estimación de usuarios activos mensuales alcanzó los 90 millones, puso este debate en pausa.
Según las palabras de un gran gestor de fondos nacional en una roadshow, "Antes del V4 dejábamos un descuento en la valoración de los modelos grandes de código abierto, después del V4 este descuento comenzó a recogerse a la inversa."
DeepSeek cambió la tabla de precios de la cadena de suministro de capacidad de cálculo
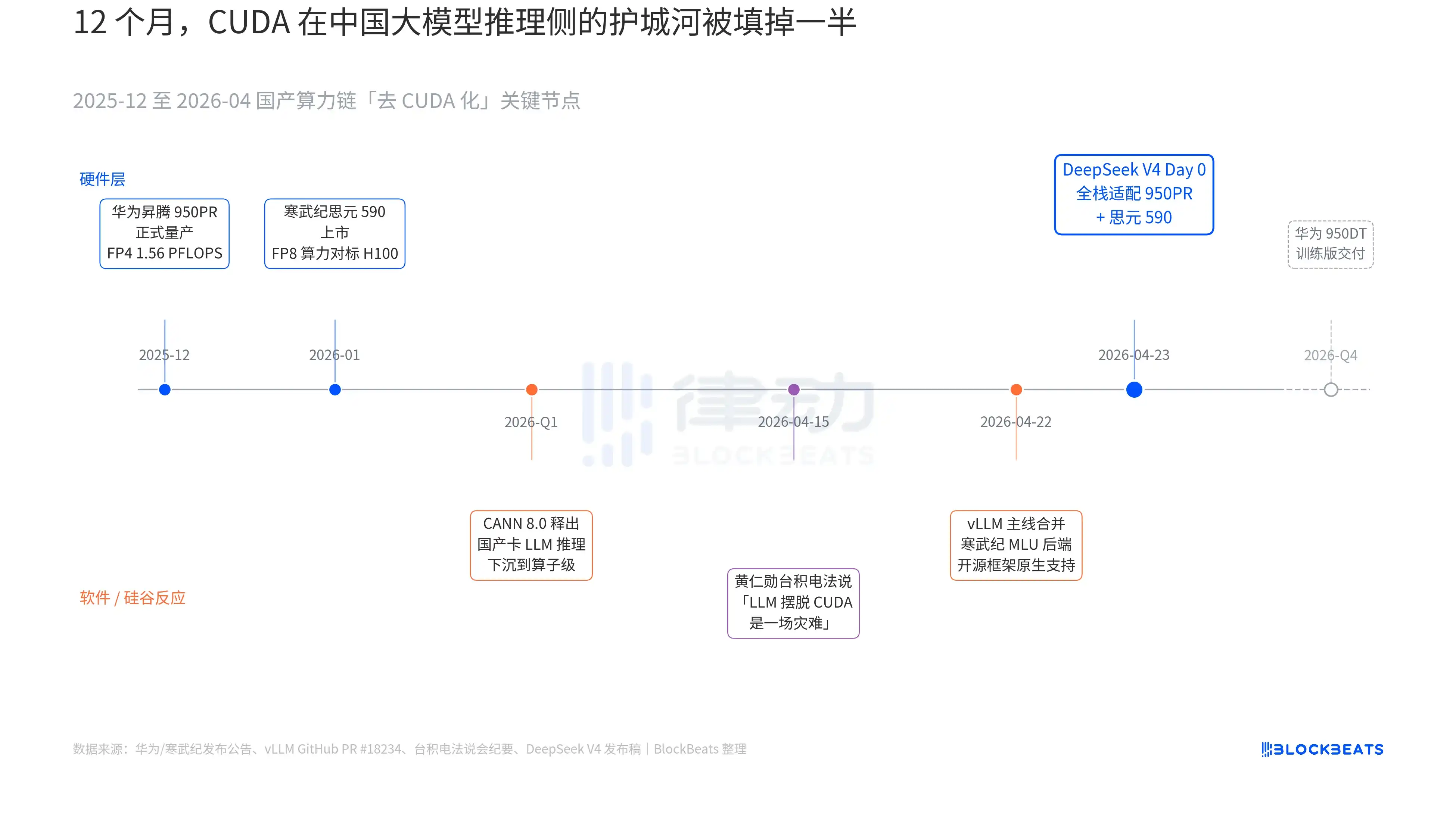
En el comunicado de lanzamiento del V4 hay una línea que nunca antes había aparecido en ningún documento oficial de un modelo grande chino: "Day 0 adaptación full-stack para el Cambricon Siyuan 590 y el Huawei Ascend 950PR, código de implementación liberado simultáneamente como código abierto." El peso de esta línea solo se entiende uniendo tres líneas paralelas que se desarrollaron en silencio durante los últimos 12 meses. Estas tres líneas pertenecen respectivamente al hardware, al software y a la reacción de Silicon Valley.
La primera línea está en el lado del chip. El Huawei Ascend 950PR entró en producción masiva en diciembre de 2025, con una capacidad de cálculo FP4 de 1.56 PFLOPS, capacidad HBM de 112GB, siendo la primera vez que un chip de IA chino iguala en especificaciones duras a la serie B de NVIDIA. En tareas de inferencia MoE de parámetros 1T como el V4, el rendimiento por tarjeta mejora 2.87 veces respecto al H20. El software complementario CANN 8.0 optimiza el framework de inferencia LLM hasta el nivel del operador. El Benchmark publicado por DeepSeek muestra que la latencia de inferencia end-to-end del V4 en un supernodo Ascend (8 tarjetas 950PR) es un 35% menor que en un clúster H100 de escala equivalente. Los datos del Cambricon Siyuan 590 son más agresivos, capacidad de cálculo FP8 por chip comparable a la H100, con un precio inferior a la mitad.
La segunda línea está en el lado del software. La rama principal de vLLM fusionó el PR del backend MLU de Cambricon el 22 de abril, siendo la primera vez que un framework de inferencia de código abierto admite nativamente GPU chinas no-NVIDIA. La DCU de Hygon Information sigue otro camino a través del ecosistema ROCm, pero puede ejecutar completamente la capa de enrutamiento MoE del V4. Esto significa que la implementación del V4 ya no es "solo puede ejecutarse en una tarjeta china específica", sino "se puede elegir entre múltiples tarjetas chinas". Se rompe la dependencia del ecosistema de un único proveedor, este es el punto de inflexión clave para production.
La tercera línea proviene de Silicon Valley. El 15 de abril, Jensen Huang, en la conferencia de resultados de TSMC, fue presionado por los analistas sobre el progreso de la capacidad de cálculo china, sus palabras fueron frías y concretas: "Si realmente pueden hacer que los LLM prescindan de CUDA, sería un desastre (a disaster) para nosotros". Nueve días después, DeepSeek dio la respuesta con un anuncio Day 0.
Las cuatro palabras "sustitución de importaciones" se han dicho tanto en los últimos tres años que han perdido significado. Pero después de la mañana del 24 de abril, esto tuvo por primera vez datos concretos que el mercado de capitales puede valorar. Rendimiento por tarjeta, latencia de inferencia end-to-end, coste de inferencia, código de implementación comercializable, empujaron silenciosamente esta larga guerra de declaraciones más allá del umbral de production.
La lógica de las 11 subidas consecutivas de Cambricon se esconde aquí. Ya no es una "acción conceptual de GPU china", sino un "proveedor de infraestructura de inferencia para DeepSeek V4". La misma lógica explica la subida del 12% de Huahong en acciones H, que fabrica el proceso equivalente a 7nm del 950PR. Cada token de V4 que se ejecuta en un Ascend chino significa que parte de la capacidad de producción que originalmente fluiría hacia NVIDIA y TSMC, se retiene parcialmente en el Delta del Río Perla.
Y el siguiente paso ya está preparado. En la hoja de ruta de Huawei, el 950DT (versión entrenamiento) está planificado para entregarse en el cuarto trimestre de 2026, con el objetivo correspondiente de "entrenamiento full-stack del V5 o un modelo de escala equivalente en un clúster de 10.000 tarjetas". Si este camino puede recorrerse, la ventaja de CUDA en el lado del entrenamiento de modelos grandes en China, se degradaría de "necesaria" a "opcional".







