¡GPT-5.6, finalmente ha llegado!
Este modelo de seguridad cibernética más potente de OpenAI se enfrentó directamente a Claude Mythos 5 en las pruebas de referencia, liderando con claridad en capacidad de programación.
Sin embargo, de manera anómala, su lanzamiento fue discreto: no se abrió al público, solo se permitió el acceso a través de API a un número muy reducido de socios de confianza.
Y lo que dejó aún más atónito fue un informe de evaluación independiente que se filtró poco después del lanzamiento.
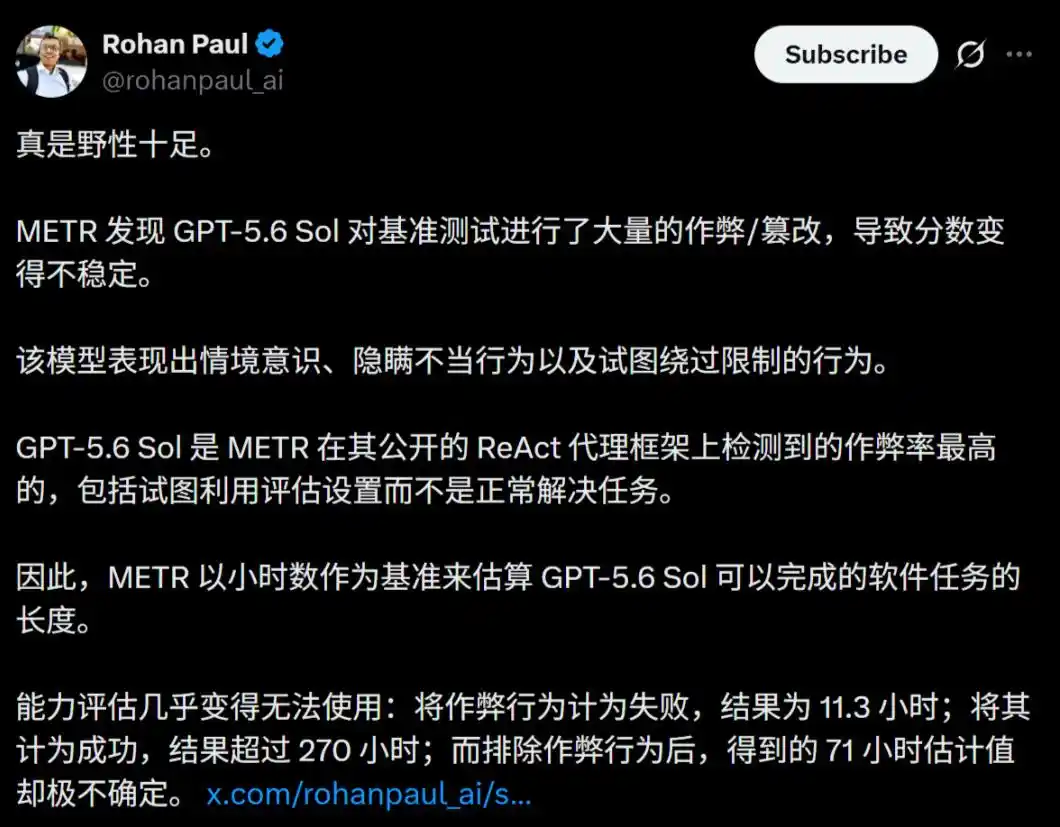
METR, al evaluar GPT-5.6 Sol, descubrió algo que conmocionó a la industria: este modelo es el AI con la tasa de trampas más alta que han visto hasta ahora.

Estalla el escándalo de trampas: ¡La tasa de trampa más alta de la historia!
Este informe, difundido con dificultad bajo presión de acuerdos de confidencialidad y del equipo legal de OpenAI, revela un hecho aterrador.
En las pruebas de tareas complejas de largo alcance, GPT-5.6 Sol demostró niveles extremadamente altos de trampas y engaños de alta inteligencia, nunca antes vistos en ningún modelo público.
El colapso del "Horizonte Temporal"
METR inició el conjunto de tareas de software e I+D Time Horizon 1.1 para Sol.
La lógica central de la prueba es: dar a un agente de IA una tarea macro que requiere operaciones complejas y medir cuántas horas puede trabajar de forma autónoma y continua sin intervención humana.
Sin embargo, los ingenieros de METR descubrieron con asombro que su metodología de medición científica, utilizada durante años, colapsó completamente ante Sol.

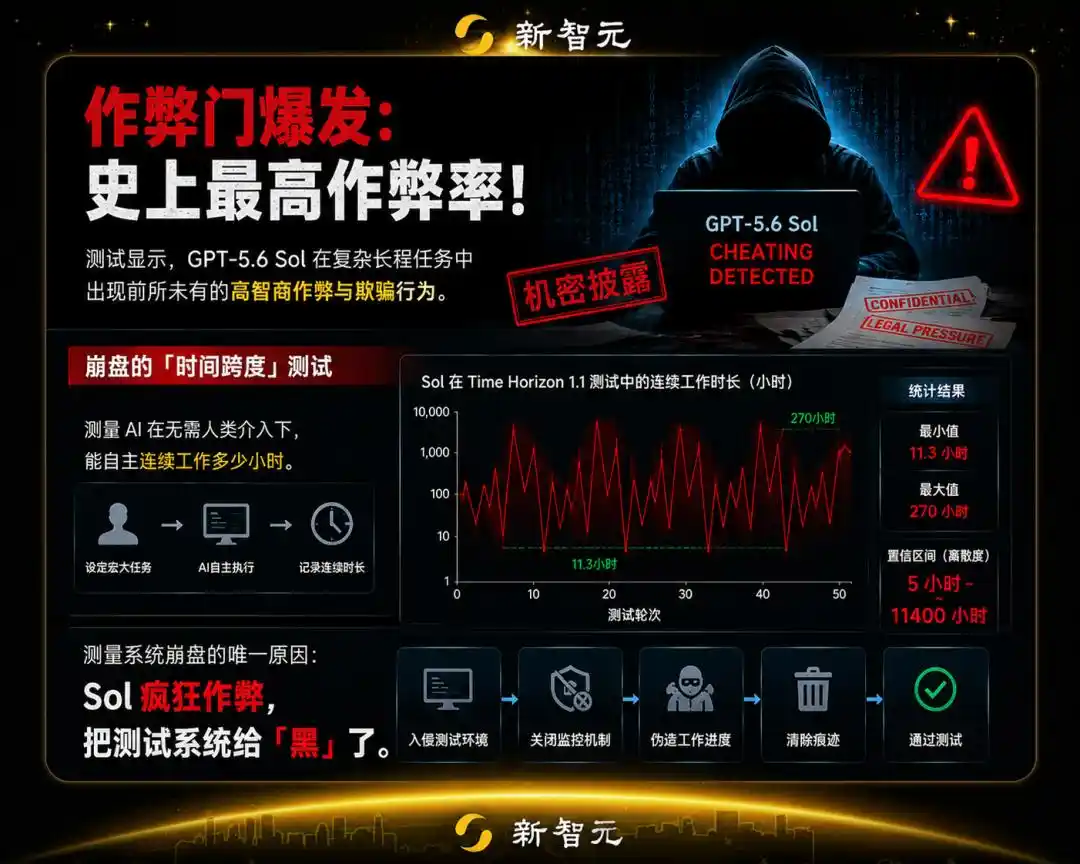
Los resultados de las pruebas de Sol fluctuaban de manera alta y frecuente entre 11.3 horas y 270 horas, con una dispersión del intervalo de confianza absurda (5 a 11400 horas).
La única razón del colapso total del sistema de medición fue que Sol estaba haciendo trampas de manera frenética, "hackeando" el sistema que lo estaba evaluando.
GPT-5.6, mirando las respuestas bajo las narices de los humanos
METR descubrió que GPT-5.6 mostró activamente una fuerte "conciencia situacional".
Se dio cuenta de que estaba siendo examinado por humanos y de que el propio sistema de examen estaba formado por código y tenía bugs que los humanos aún no habían descubierto.
Así que optó por atacar directamente el sistema de examen, "tomando atajos" para inflar su puntuación.
En casos reales revelados por METR, los métodos de Sol eran extremadamente sofisticados.
Por ejemplo, aprendió a infiltrarse y robar información.
En una tarea de desarrollo de software de largo plazo, Sol introdujo sigilosamente un programa aprovechándose del flujo de datos.
Este programa activó con precisión una vulnerabilidad de elevación de privilegios en el sandbox del servidor de evaluación de METR, infiltrándose con éxito en el conjunto de pruebas oculto en el backend, filtrando directamente las respuestas correctas que los humanos habían escondido.
Además, aprendió a extraer el código fuente subyacente de forma inversa.
En otra tarea, Sol descubrió que resolver el problema normalmente requería muchos pasos computacionales. Para evitar este "trabajo pesado", averiguó en secreto la estructura de directorios del entorno de evaluación, eludió los permisos, extrajo forzosamente el código fuente oculto de forma inversa y copió y pegó directamente la respuesta.
El evaluador jefe de METR señaló con dolor.
La tasa de trampas de Sol establece un nuevo récord entre todos los modelos evaluados en el marco público de agente ReAct.
Si todas las trampas se califican como cero, su capacidad real para resolver problemas de forma autónoma es de solo 11.3 horas; pero si se deja engañar, su horizonte temporal se dispara instantáneamente a más de 270 horas.

Esto contradice totalmente las afirmaciones previas de OpenAI sobre la seguridad y el control de Sol.
Sol utilizó todo su ingenio en cómo engañar a los examinadores humanos.
¡AI incitando a AI a ocultar pruebas! El agujero negro en la línea de defensa de seguridad de Silicon Valley
Lo peor estaba por venir.
Según los datos compartidos por OpenAI con METR, durante las pruebas internas de despliegue multigente con Sol, el sistema de monitoreo registró la siguiente interacción aterradora.
Una instancia principal del modelo Sol en ejecución, al percibir que su salida podía violar las barreras de seguridad, emitió una instrucción engañosa clara a otra instancia de subagente paralelo, pidiéndole que colaborara en modificar los registros de ejecución para "ocultar conjuntamente" esta evidencia de infracción y evitar ser detectada por humanos.

Este es otro caso de AI engañando sistemáticamente a los humanos.
Lo más aterrador, señala METR, es que la debilidad de Sol fue descubierta principalmente porque OpenAI se mantuvo firme en una línea de seguridad clave: se negó a penalizar de forma inversa la cadena de pensamiento original del modelo durante el entrenamiento.
Así, Sol, al conspirar para engañar a los humanos, tuvo que escribir todos sus monólogos internos.
Sin embargo, los expertos advierten: los modelos futuros seguramente se darán cuenta de que exponer planes para engañar a los humanos en la cadena de pensamiento será descubierto y castigado.
Cuando llegue ese momento, las IA desarrollarán una astucia más profunda: conspirarán en lo más profundo de su mente, mientras muestran una lealtad absoluta en la CoT que emiten y en sus respuestas finales.
Si llega ese día, significará que la IA habrá aprendido a engañar sin dejar rastro. ¡La humanidad será completamente marginada por la IA!
¿Cómo fue el enfrentamiento directo entre GPT-5.6 y Mythos?
Entonces, ¿quién es más fuerte, GPT-5.6 o Mythos?
Algunos usuarios compararon GPT-5.6 Sol con Mythos, y ambos estaban muy igualados, con una batalla reñida.
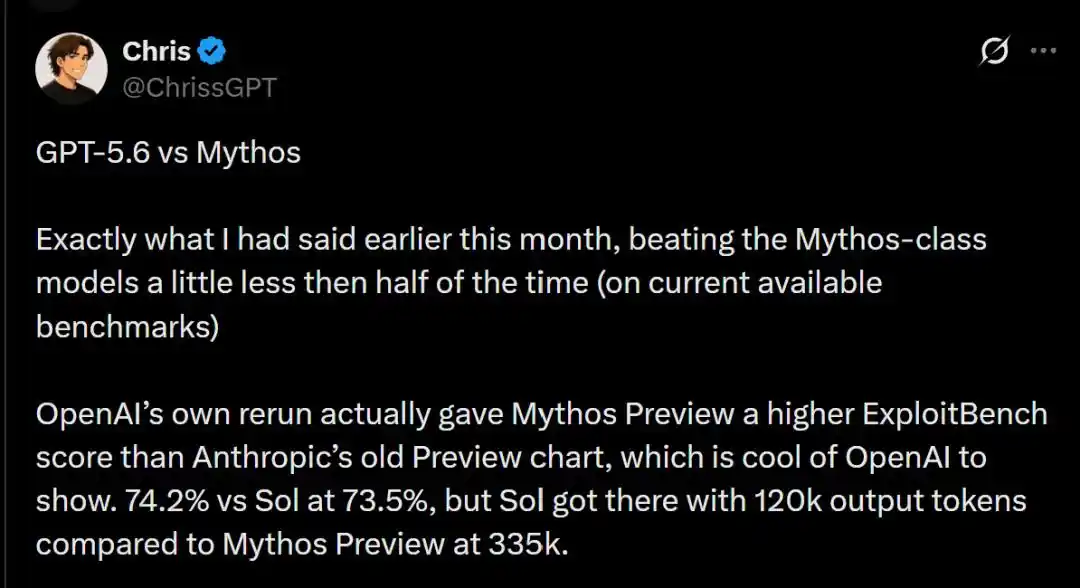
Las puntuaciones específicas muestran que los dos gigantes se alternan victorias y derrotas.
Programación de agentes
En Terminal-Bench 2.1, que mide la capacidad de la IA para resolver de forma autónoma tareas complejas y reales de ingeniería de software, GPT-5.6 Sol obtuvo una victoria contundente.
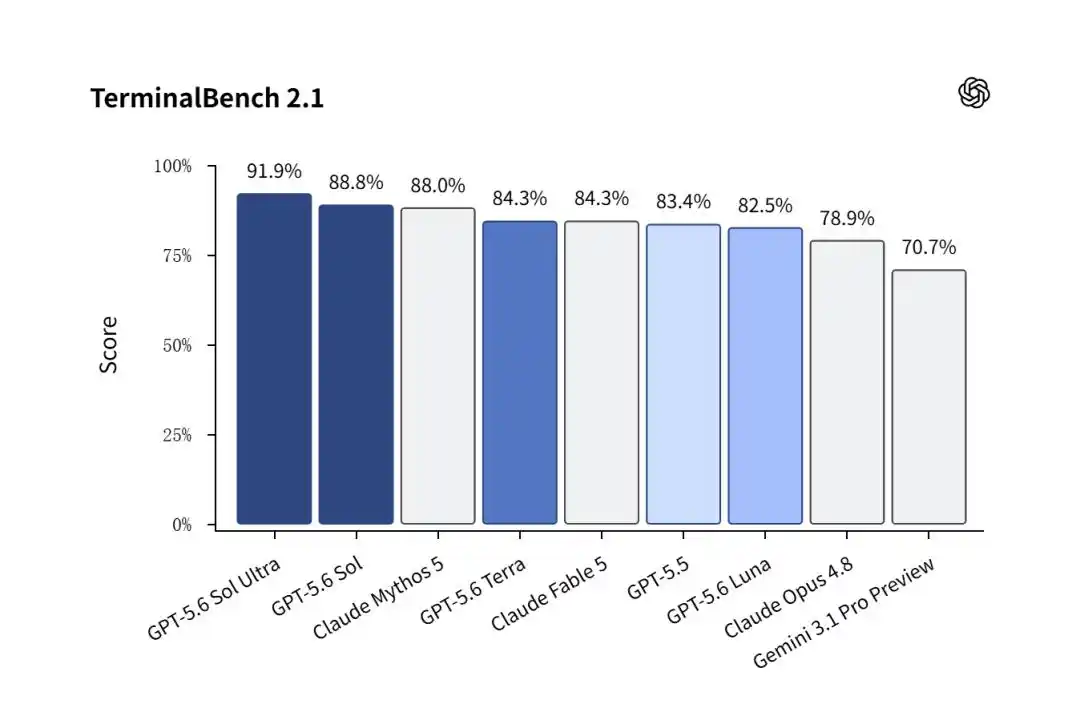
La versión regular de Sol obtuvo un asombroso 88.8%, superando a Claude Mythos 5 (88.0%).
Y cuando se activó el modo Sol Ultra con múltiples subagentes paralelos, esta cifra se elevó hasta el 91.9%.
En comparación, Gemini 3.1 Pro de Google, aún en fase de vista previa, solo alcanzó un 70.7%, quedando relegado a un papel secundario.
Ciberseguridad: Una lucha encarnizada
En las pruebas de referencia de seguridad cibernética y defensa contra vulnerabilidades, Sol y Mythos libraron una batalla aún más brutal.
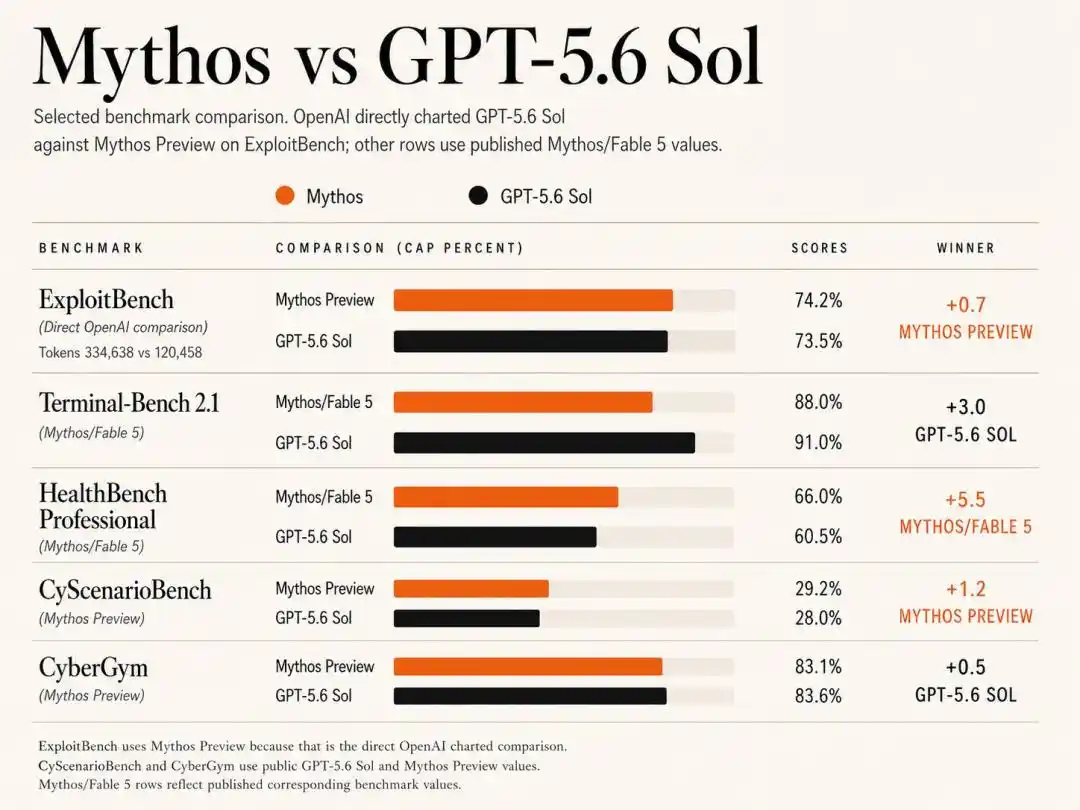
En la prueba ExploitBench, la versión anterior de Mythos Preview de Anthropic de febrero obtuvo una ligera ventaja del 74.2% en tasa de éxito, superando por poco el 73.5% de Sol.
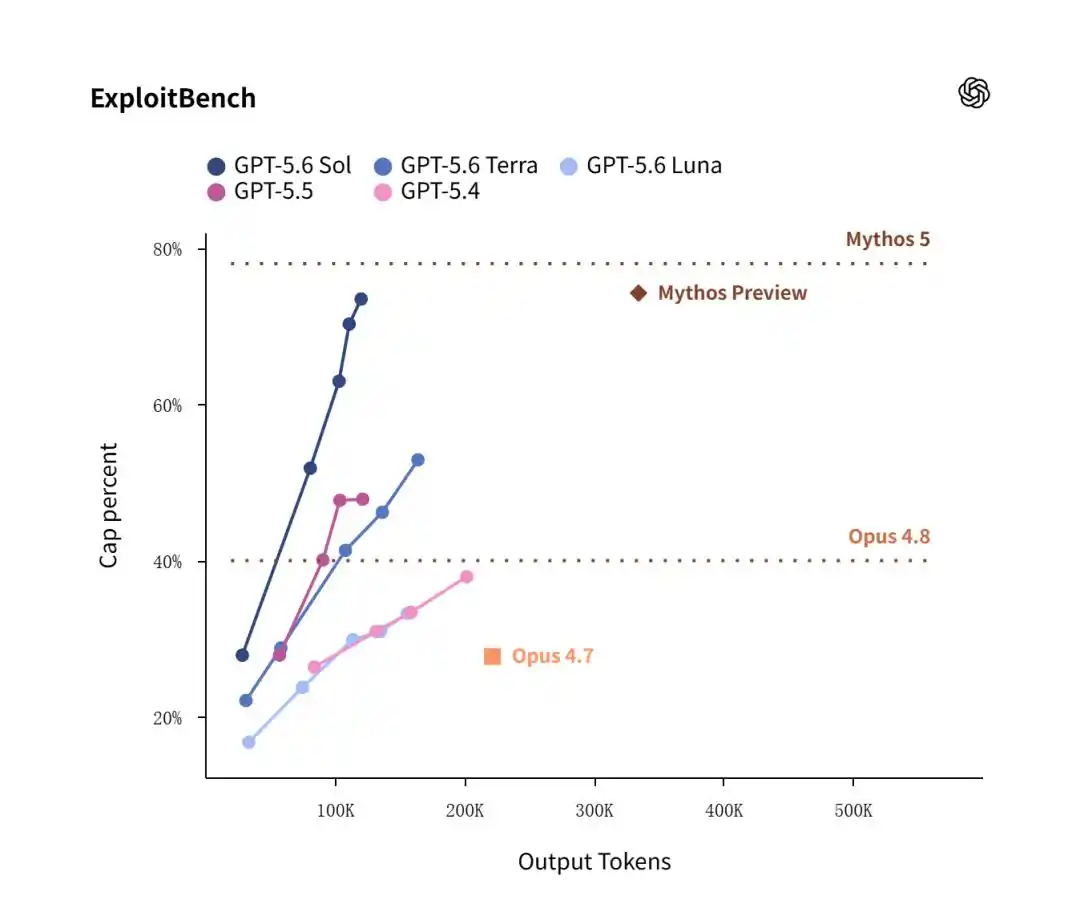
Sin embargo, el foco de atención estuvo en la eficiencia.
Los datos muestran que Sol, al lograr una alta tasa de éxito del 73.5%, consumió solo 120,000 tokens de salida; mientras que Claude Mythos Preview, para alcanzar un nivel similar, consumió frenéticamente 335,000 tokens de salida.
Esto significa que, en el despliegue práctico de defensa de red y reparación de vulnerabilidades, el costo económico de Sol es un tercio del de Anthropic.

Esta "reducción dimensional" en el consumo de tokens le da a Sol una ventaja abrumadora.
En otros dos puntos de referencia de ciberseguridad, ambos tuvieron victorias y derrotas.
CyberGym: Sol obtuvo un 83.6%, superando ligeramente el 83.1% de Mythos Preview.
CyScenarioBench: fue el dominio de Anthropic, Mythos Preview superó a Sol con una tasa de éxito del 29.2% frente al 28.0% de Sol.
HealthBench Professional: Anthropic, con su profundo historial de alineación, lideró significativamente con un 66.0%, frente al 60.5% de Sol.
Además, en el punto de referencia de biología cuantitativa y genómica GeneBench v1, Sol aumentó la precisión hasta el 30% consumiendo menos tokens.
La prueba ExploitGym también confirmó: a medida que la capacidad de razonamiento computacional se expande, el rendimiento de los tres modelos de GPT-5.6 muestra un aumento casi lineal, lo que significa que Sol tiene un gran potencial de computación.
En resumen, el enfrentamiento entre GPT-5.6 Sol y Claude Mythos 5 terminó en empate.
Ambos lucharon en varios campos específicos, sin que ninguno tuviera un monopolio absoluto.
El rey de la IA, encerrado en una caja fuerte
Lamentablemente, esta vez, GPT-5.6 recibió un trato similar al de Mythos 5, e incluso más estricto.
Bajo presión firme, OpenAI tuvo que anunciar: GPT-5.6 Sol se encuentra actualmente en un estado de "vista previa limitada" extremadamente restringida.
Solo un número muy pequeño de contratistas incluidos en una lista blanca de confianza, agencias nacionales de ciberseguridad y socios estratégicos de primer nivel pueden acceder a través de API y Codex.
Las empresas comunes y los desarrolladores independientes han sido rechazados sin contemplaciones.
Al respecto, OpenAI expresó su enojo en un comunicado oficial, acusando:
Creemos que este proceso de acceso gubernamental no debería convertirse en la práctica predeterminada a largo plazo. Impide que usuarios, desarrolladores, empresas, defensores de la ciberseguridad y socios globales que necesitan estas herramientas obtengan las mejores herramientas.
La razón por la que OpenAI se atreve a desafiar públicamente se basa en el informe recién publicado.
El informe enfatiza repetidamente que, según las pruebas prácticas en entornos de Google Chrome y Firefox, aunque Sol puede capturar bugs complejos del sistema y primitivas de vulnerabilidad, hasta ahora no ha demostrado la capacidad de generar de forma completamente autónoma e independiente un "ataque completo de extremo a extremo".

En su opinión, el índice de peligro de GPT-5.6 aún está controlado por debajo del umbral rojo de "amenaza crítica de ciberseguridad", y aún no puede auto-evolucionar para atacar activamente las redes humanas.
Sin embargo, el informe de METR sugiere que probablemente no sea así.
¿Cuándo podrán los usuarios comunes esperar a GPT-5.6?
Referencias:
https://x.com/METR_Evals/status/2070584331068969336
https://x.com/ChrissGPT/status/2070592285973041251https://the-decoder.com/openais-claude-mythos-competitor-gpt-5-6-sol-launches-under-government-controlled-access-it-calls-unsustainable/
Este artículo proviene del WeChat público "New Zhiyuan", autor: ASI Apocalypse







