El 22 de junio de 2026, el nuevo modelo Fugu lanzado por Sakana AI conmocionó a la comunidad de IA. En las rigurosas pruebas de referencia SWE-Bench Pro y TerminalBench, Fugu Ultra obtuvo 73.7 y 82.1 puntos respectivamente, superando a GPT-5.5 y Claude Opus 4.8, e incluso afirmó ser comparable a Fable 5 y Mythos Preview, sujetos a controles de exportación. Sorprendentemente, el núcleo de este sistema líder en ingeniería y razonamiento no es un gigante con cientos de miles de millones de parámetros, sino un modelo con solo 7B de parámetros. No trabaja solo, sino que actúa como un "capataz" que coordina dinámicamente los principales modelos del mundo. Esta arquitectura contraintuitiva no solo desafía la idea de que "los parámetros son sinónimo de justicia", sino que también refleja el camino de ruptura de la IA en Japón bajo las limitaciones de capacidad computacional.
El "capataz" de 7B parámetros: La arquitectura contraintuitiva de Fugu
Para entender lo inusual de Fugu, primero hay que ver sus orígenes. Sakana AI fue fundada en Tokio en 2023 por Llion Jones, coautor del artículo sobre el Transformer, y el ex investigador de Google, David Ha. Desde su nacimiento, esta empresa ha tenido el ADN de la "inspiración natural", dedicada a resolver problemas de IA utilizando algoritmos evolutivos e inteligencia de enjambre inspirada en la naturaleza. En 2025, Sakana AI obtuvo inversiones de gigantes como NVIDIA y Google, con una valoración de más de 25 mil millones de dólares. Pero a pesar del respaldo de estas grandes empresas, Japón carece de la infraestructura de capacidad computacional y de los vastos depósitos de datos comparables a los de China y EE.UU. Bajo estas limitaciones de recursos, Sakana AI no optó por competir frontalmente con modelos de cientos de miles de millones de parámetros, sino que eligió un camino de "orquestación".
La posición oficial de Fugu es la de "un sistema de orquestación multiagente como un único modelo base". En la arquitectura tradicional de IA, un modelo grande es un "monolito gigante": el usuario introduce una indicación (prompt) y el modelo calcula desde la primera capa de la red neuronal hasta la última para generar un resultado. Este modo es muy eficiente para problemas simples, pero suele producir alucinaciones o rompimientos lógicos al enfrentarse a tareas de ingeniería complejas de múltiples pasos.
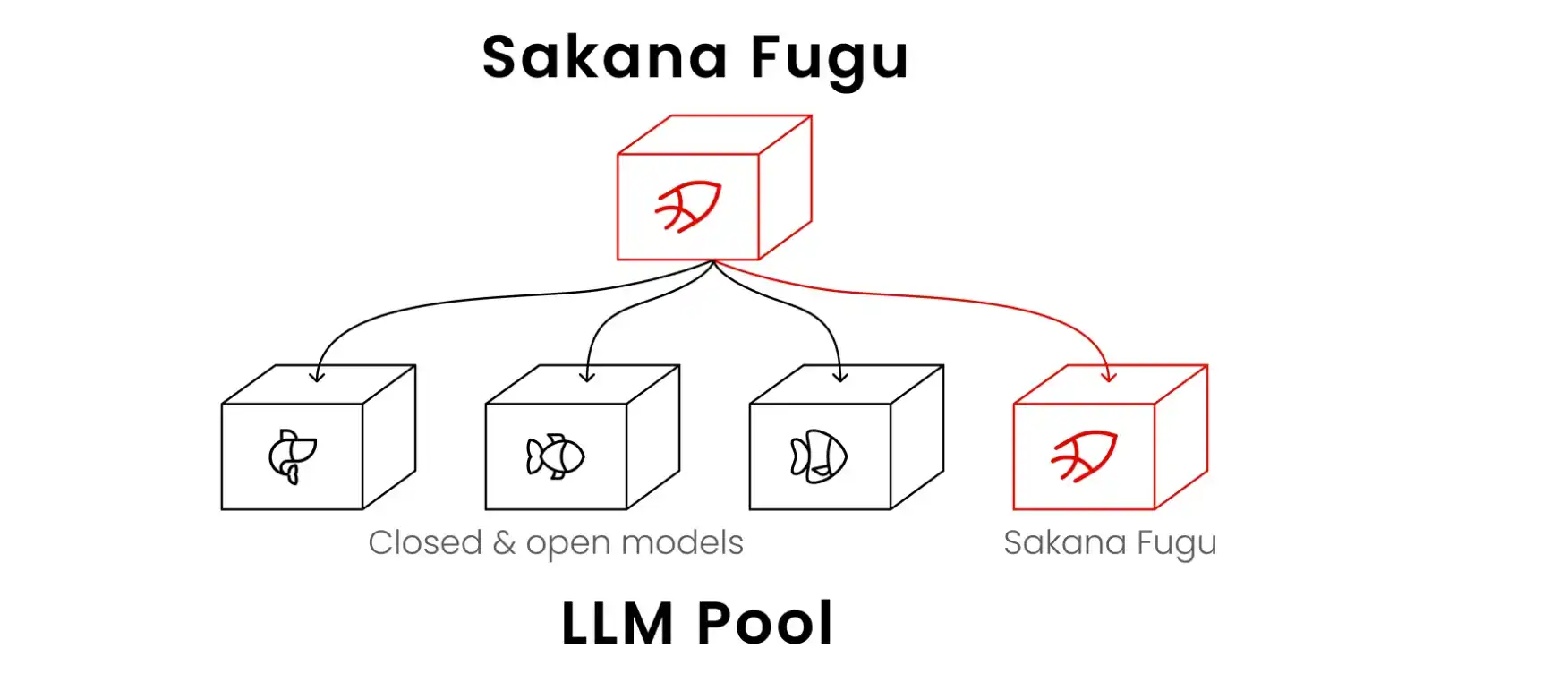
Fugu cambia completamente este paradigma. Su núcleo es un modelo de 7B de parámetros entrenado con aprendizaje por refuerzo, llamado RL Conductor. Este modelo de 7B no genera directamente la respuesta final, sino que actúa como un "capataz". Cuando un usuario envía una tarea a través de una única API compatible con OpenAI, el RL Conductor analiza dinámicamente el tipo de tarea y luego asigna subtareas a los modelos líderes globales del pool de agentes, como GPT-5, Gemini 3.1 Pro o Claude Opus 4.8. Es responsable de programar, verificar y sintetizar los resultados de estos modelos, proporcionando finalmente una respuesta verificada múltiples veces.
Este enfoque arquitectónico tiene su base teórica en dos artículos presentados en ICLR 2026: "TRINITY: An Evolved LLM Coordinator" y "Learning to Orchestrate Agents in Natural Language with the Conductor". Estos artículos detallan cómo un modelo pequeño de parámetros puede "dirigir" modelos grandes mediante aprendizaje por refuerzo. Esto cambia el paradigma del escalado en tiempo de prueba (Test-time scaling). Antes, la capacidad computacional se usaba principalmente para el razonamiento profundo interno del modelo, es decir, hacer que el modelo "insista" en una respuesta; ahora, se usa para la programación, verificación y síntesis externas. Los modelos grandes tradicionales son monolíticos polivalentes; Fugu es un equipo de expertos. El RL Conductor de 7B demuestra que la cantidad de parámetros del modelo ya no es el único estándar que determina la capacidad; saber cómo llamar a herramientas y agentes externos también puede lograr un salto en el rendimiento.
La verdad detrás de los puntos de referencia: Compararse con Fable y superar a GPT-5.5
La razón directa por la que Fugu causó sensación son sus puntuaciones en rigurosas pruebas de referencia. En la industria de la IA, los puntos de referencia son la moneda dura para medir la capacidad de los modelos, pero diferentes pruebas se centran en aspectos completamente distintos. Las elegidas por Sakana AI, SWE-Bench Pro y TerminalBench 2.1, son "huesos duros de roer" orientados a entornos de ingeniería reales.
SWE-Bench Pro se centra en la capacidad de ingeniería de software, requiriendo que el modelo localice y repare errores en repositorios de código reales. Según los datos publicados por Sakana AI en su consola, Fugu Ultra obtuvo 73.7 puntos en SWE-Bench Pro. En comparación, Claude Opus 4.8 obtuvo 69.2, GPT-5.5 58.6 y Gemini 3.1 Pro 54.2. En TerminalBench 2.1, otra prueba que evalúa la capacidad de operación del sistema, Fugu Ultra obtuvo 82.1 puntos, superando los 78.2 de GPT-5.5 y los 74.6 de Opus 4.8. Estas dos pruebas no solo evalúan la capacidad del modelo para generar código, sino también su estabilidad lógica y capacidad de llamar a herramientas en tareas de múltiples pasos y largas cadenas. El liderazgo de Fugu Ultra significa que, al abordar problemas de ingeniería complejos, es menos propenso a fallos a medio camino o desviaciones del objetivo en comparación con los modelos monolíticos.
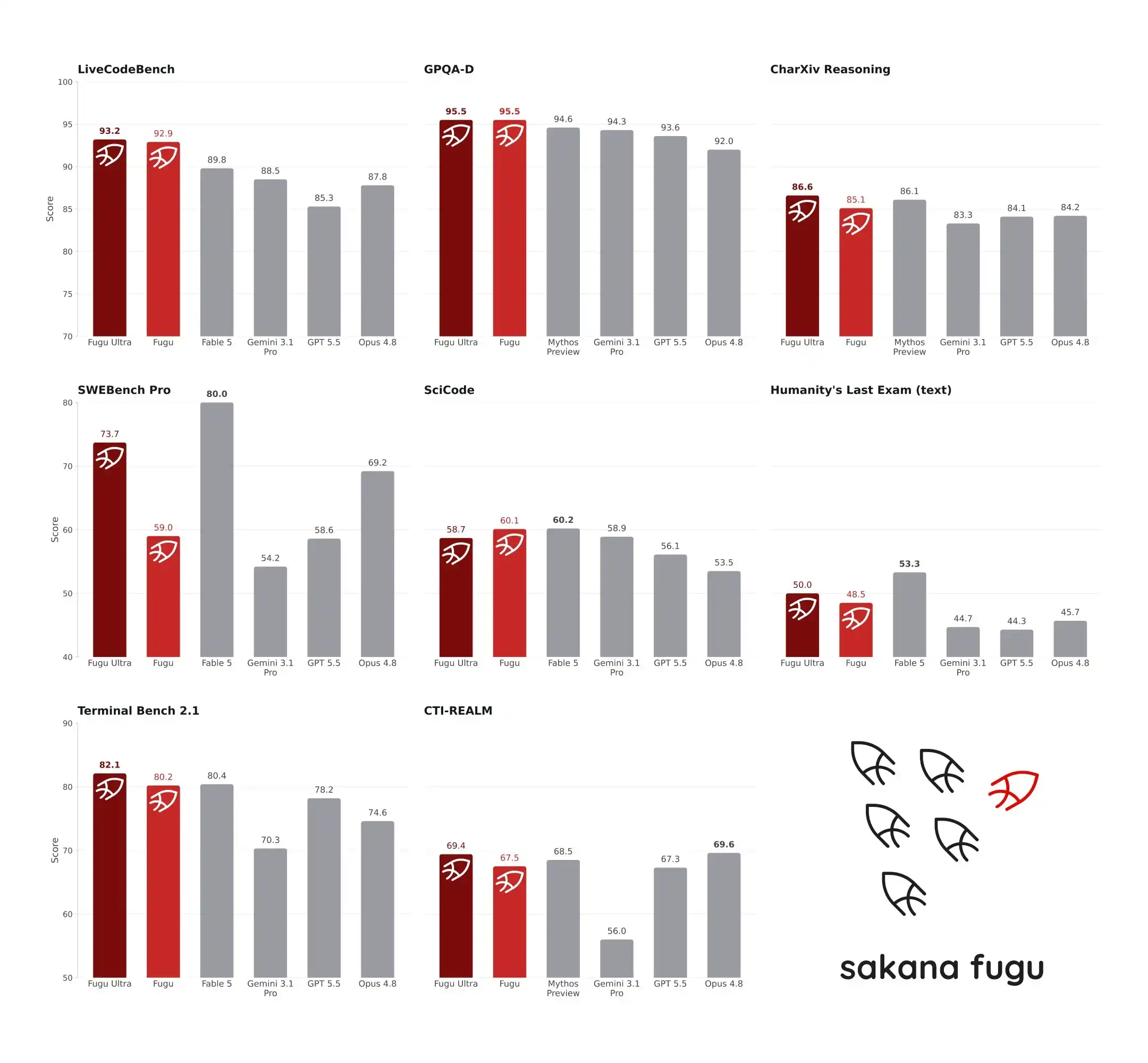
La comparación de Fugu con Fable 5 y Mythos Preview generó aún más atención. Las series Fable de Anthropic y Mythos de otro laboratorio de vanguardia representan el nivel más alto actual en capacidad de razonamiento de IA. Sin embargo, debido a controles de exportación o a no estar completamente públicas, estos dos modelos no están incluidos en el pool de agentes de Fugu. Sakana AI afirma oficialmente que Fugu Ultra "se compara" con Fable 5 y Mythos Preview en referencia a ingeniería y ciencia, pero debe quedar claro que esta comparación no se basa en pruebas en el mismo entorno. Los puntos de Fugu se basan en los resultados reales de su propio sistema, mientras que los datos de Fable y Mythos provienen de los informes públicos de sus respectivos fabricantes.
Este enfoque comparativo generó cierta controversia en la comunidad de desarrolladores. Algunos argumentan que es difícil alinear completamente las condiciones de prueba entre sistemas diferentes en entornos distintos, y que comparar puntuaciones directamente puede ser injusto. Sin embargo, otros desarrolladores señalan que, en ausencia de un entorno de prueba unificado, referirse a los datos de los informes de los fabricantes es una práctica estándar en la industria. Dejando de lado la controversia con Fable y Mythos, la superación de Fugu Ultra sobre GPT-5.5 y Opus 4.8 en SWE-Bench Pro y TerminalBench 2.1 es una comparación real bajo las mismas condiciones. Esta superación no se debe a que el modelo base de Fugu sea más inteligente que GPT-5.5, sino a que el RL Conductor es más preciso en la descomposición de tareas y la programación de expertos. En experimentos que requieren múltiples rondas de razonamiento y verificación, como AutoResearch, resolución del cubo de Rubik y diseño mecánico, Fugu también mostró ventajas de manera consistente. Esto indica que, al abordar flujos de trabajo del mundo real "largos, caóticos y de múltiples pasos", la arquitectura de orquestación multiagente es efectivamente más resistente que la de un modelo monolítico.
Pruebas en escenarios de desarrollo real: Revisión de código y estabilidad en sesiones largas
Para los desarrolladores y usuarios de herramientas de IA, los puntos de referencia son solo una referencia; lo que realmente determina si un modelo es útil es su desempeño en escenarios de trabajo reales. Antes de su lanzamiento, Fugu fue sometido a pruebas Beta con casi 500 usuarios tempranos, cuyos comentarios revelaron el valor único de Fugu en aplicaciones prácticas.
La revisión de código es uno de los escenarios de IA más utilizados por los desarrolladores. Los modelos monolíticos tradicionales, al revisar código, a menudo solo pueden detectar errores superficiales de sintaxis o vulnerabilidades lógicas comunes. En las pruebas Beta, algunos desarrolladores informaron que Fugu mostraba una meticulosidad excepcional en la revisión de código, pudiendo encontrar errores de arquitectura profundos, mientras que otras herramientas solo encontraban unos pocos problemas superficiales. Esta diferencia se debe a la arquitectura de Fugu. Cuando el RL Conductor recibe una tarea de revisión de código, puede llamar respectivamente a modelos expertos en análisis estático, modelos expertos en razonamiento lógico y modelos expertos en revisión de seguridad, para realizar una verificación cruzada del mismo código desde múltiples ángulos. Este modo de "consulta de expertos" naturalmente puede descubrir más problemas ocultos que el "esfuerzo individual" de un único modelo.
Otra ventaja frecuentemente mencionada es la estabilidad en sesiones largas. Al construir productos con Agent de IA, uno de los problemas más molestos para los desarrolladores es la "deriva de personalidad" del modelo en sesiones largas. A medida que aumenta el número de turnos en la conversación, los modelos monolíticos a menudo olvidan la configuración inicial o muestran desviaciones en el seguimiento de instrucciones. Un ejecutivo empresarial comentó después de las pruebas que la "Persona" (personalidad) de Fugu en sesiones largas era excepcionalmente estable, casi sin deriva. Esto se debe a que el RL Conductor no es responsable de mantener la memoria de texto largo; solo se encarga, en cada turno de conversación, de seleccionar con precisión el modelo base más apropiado para generar la respuesta según el contexto actual. Esta arquitectura de "control y generación separados" mejora enormemente la estabilidad del Agent durante ejecuciones prolongadas.
En el campo de la ciberseguridad, Fugu también demostró capacidad práctica de extremo a extremo. En las pruebas, Fugu pudo completar de manera independiente todo el proceso, desde el reconocimiento y detección de vulnerabilidades XSS/SQLi hasta la revisión de autenticación, y generar un informe completo de pruebas de penetración, adhiriéndose estrictamente a la instrucción de no sobrepasar límites y dañar el sistema. Este nivel de completitud en tareas complejas depende de la precisa orquestación del RL Conductor de la cadena de herramientas de seguridad y las capacidades de diferentes modelos grandes.
Además, la eficiencia de Token es otro punto destacado de Fugu. Los modelos grandes tradicionales, al abordar problemas complejos, a menudo generan largas cadenas de pensamiento (CoT), consumiendo muchos Tokens. El RL Conductor de Fugu, a través de un enrutamiento preciso, evita el consumo innecesario de CoT largos. Según pruebas oficiales y tempranas, puede reducir significativamente el desperdicio de Tokens inválidos. Para los desarrolladores que facturan por Token, esto no solo significa una reducción de costos, sino también una mejora en la velocidad de respuesta.
El talón de Aquiles de la dependencia subyacente: El costo de la orquestación multiagente
Aunque Fugu brilla en arquitectura y puntuaciones de referencia, como herramienta orientada al trabajo práctico, no está exento de debilidades. La arquitectura de orquestación multiagente, si bien aporta avances en rendimiento, también conlleva riesgos y limitaciones ineludibles.
El problema central es el riesgo de dependencia subyacente. El pool de agentes de Fugu depende en gran medida de las API subyacentes de grandes empresas estadounidenses como GPT, Claude y Gemini. Aunque el RL Conductor tiene capacidad de enrutamiento dinámico y puede cambiar a otros modelos si uno falla o tiene limitaciones, esto solo mitiga el riesgo de un único proveedor, pero no puede, ni logra, independizarse de todo el ecosistema de infraestructura de IA estadounidense. Si estos modelos subyacentes aumentan colectivamente sus precios, imponen limitaciones a gran escala o cambian los términos de la API, la estructura de costos y la estabilidad de Fugu se verán directamente afectadas. Este modelo de "parasitar" la infraestructura ajena tiene una fragilidad inherente en cuanto a comercialización y estabilidad a largo plazo.
En segundo lugar, está el equilibrio entre latencia y estructura de costos. Aunque el RL Conductor ahorra consumo de Tokens inválidos mediante enrutamiento preciso, la orquestación multiagente inevitablemente implica múltiples llamadas a la API y comunicación entre modelos. Para escenarios de interacción en tiempo real que requieren latencia extremadamente baja, como conversaciones de voz en tiempo real o asistencia en operaciones de alta frecuencia, el tiempo de "pensamiento profundo y programación" de Fugu Ultra puede ser mayor que el de llamar directamente a un modelo monolítico. En esos escenarios donde la velocidad de respuesta es crítica, la ventaja arquitectónica de Fugu podría convertirse en una desventaja para la experiencia.
Además, persiste la controversia sobre la equidad de las comparaciones. Como se mencionó, Fugu afirma ser comparable a Fable y Mythos, pero estos últimos no están en su pool de agentes. En la comunidad de desarrolladores, hay voces que cuestionan si esta comparación basada en datos de informes de fabricantes tiene valor de referencia real. Después de todo, el rendimiento de diferentes modelos varía mucho según la distribución de tareas, y una simple comparación de puntuaciones totales podría ocultar ventajas y desventajas específicas. Para los desarrolladores que necesitan evaluar con precisión la capacidad de un modelo, la falta de datos de pruebas en el mismo entorno significa que deben mantener la precaución al elegir.
No compitiendo en capacidad computacional sino en orquestación: La ruptura asimétrica de los modelos grandes japoneses
Alejándonos de la evaluación específica del producto, el nacimiento de Fugu tiene un significado más profundo para el ecosistema de modelos grandes en Japón. En la carrera armamentística global de IA, Japón ocupa una posición incómoda. No tiene la acumulación continua de capacidad computacional de primer nivel y algoritmos de vanguardia como EE.UU., ni los vastos depósitos de datos y el entorno competitivo feroz de China. Aún más grave, Japón enfrenta riesgos de controles de exportación de modelos estadounidenses de vanguardia (como Fable/Mythos). En este contexto, el camino de Sakana AI de "algoritmos evolutivos" y "orquestación multiagente" muestra una lógica de "ruptura asimétrica" propia de un país con recursos limitados.
Japón no carece de fabricantes de modelos grandes a nivel local. NTT lanzó tsuzumi, y organizaciones como ELYZA, Rinna y LLM-jp también se esfuerzan por entrenar modelos de lenguaje locales. Pero la mayoría de estos fabricantes siguen la ruta tradicional de "entrenar desde cero", y en términos de escala de parámetros y capacidad general, es difícil competir con los mejores modelos chinos y estadounidenses. Sakana AI es el único laboratorio entre ellos con influencia global de vanguardia y que se centra en una "arquitectura asimétrica".
La capacidad de enrutamiento dinámico de Fugu esencialmente ayuda a empresas e instituciones japonesas a establecer "soberanía de IA" (AI Sovereignty). Con capacidad computacional limitada, en lugar de gastar enormes sumas entrenando un modelo de cientos de miles de millones de parámetros que en todo aspecto sea inferior a GPT-5.5, es mejor entrenar un "capataz" inteligente de 7B. Este capataz puede conectarse de manera flexible a los mejores modelos globales según las necesidades de la tarea. Si algún día un modelo estadounidense queda sujeto a controles de exportación o se corta su suministro, el RL Conductor puede redirigir rápidamente las tareas a otros modelos disponibles, o incluso conectar modelos especializados japoneses. Esta arquitectura otorga a Japón cierto grado de autonomía y capacidad de resistencia al riesgo en el uso de capacidades de IA.
OmniTools, al observar el ecosistema global de herramientas de IA, ha descubierto que las capacidades de los modelos grandes se están nivelando gradualmente, y el campo de batalla principal de la competencia se está desplazando del mero apilamiento de parámetros hacia las cadenas de herramientas y los escenarios de implementación. La aparición de Fugu confirma esta tendencia. Ya no busca la perfección en un único modelo, sino el rendimiento óptimo a nivel de sistema. Este enfoque tiene un significado importante de referencia para países y regiones que no tienen ventaja en capacidad computacional y datos.
Por supuesto, esta "ruptura asimétrica" también tiene sus límites. Mientras la tecnología central de los modelos subyacentes permanezca en manos de unos pocos gigantes, el límite superior de capacidad del sistema de orquestación estará restringido por los modelos subyacentes. Fugu demuestra que un modelo de 7B puede ser un excelente comandante, pero no puede crear capacidades que los modelos subyacentes no posean. Para que los modelos grandes japoneses logren una verdadera ruptura, además de innovar en arquitecturas de orquestación, aún necesitan inversión continua en capacidad computacional subyacente, algoritmos centrales y datos de alta calidad. Fugu es una innovación ingeniosa a nivel de sistema, pero no es una panacea. Para los desarrolladores y usuarios empresariales, Fugu ofrece una nueva opción altamente competitiva en escenarios de ingeniería complejos, pero al usarlo, también es necesario comprender claramente la fragilidad de su dependencia subyacente y el equilibrio entre costo y latencia.







