La inteligencia artificial general, la AGI, está por llegar.
Recientemente, Mark Chen, Director de Investigación de OpenAI, declaró contundentemente:
En cierto sentido, es como si quisieras que pudieras sentir que la AGI (Inteligencia Artificial General) está por llegar...
Nos acercamos cada vez más a un mundo donde los modelos pueden proponer más innovaciones de forma autónoma: pueden realizar investigaciones autosostenibles.
Esto no es solo una mejora en la eficiencia; la propia «evolución» está siendo externalizada a la vida de silicio.
Mientras Mark Chen cortaba con habilidad champiñones y cebollas frente a la cámara, no hablaba solo de un plato de sopa, sino del último bastión de la civilización humana.
Si la IA puede investigarse a sí misma, ¿qué papel debería desempeñar la humanidad en la víspera de la llegada de la AGI?

Cada campo está experimentando su propia «jugada divina»
Para entender el peso de estas palabras, debemos retroceder al momento en que Mark entró en este campo.
2016, AlphaGo contra Lee Sedol.

En la segunda partida, hubo una jugada, la «jugada 37», que en el momento de realizarla dejó perplejos a todos los jugadores humanos.
Después se comprendió que era una jugada que la máquina ejecutó, que los humanos ni siquiera habían considerado. Ese momento inspiró a mucha gente y también arrastró a Mark Chen a este campo.
¿Y ahora?
«Lo más loco», dice Mark, «es que ahora puedes ver 'jugadas divinas' en casi cualquier campo».
Las hay en matemáticas, en ciencias de la computación, en programación.
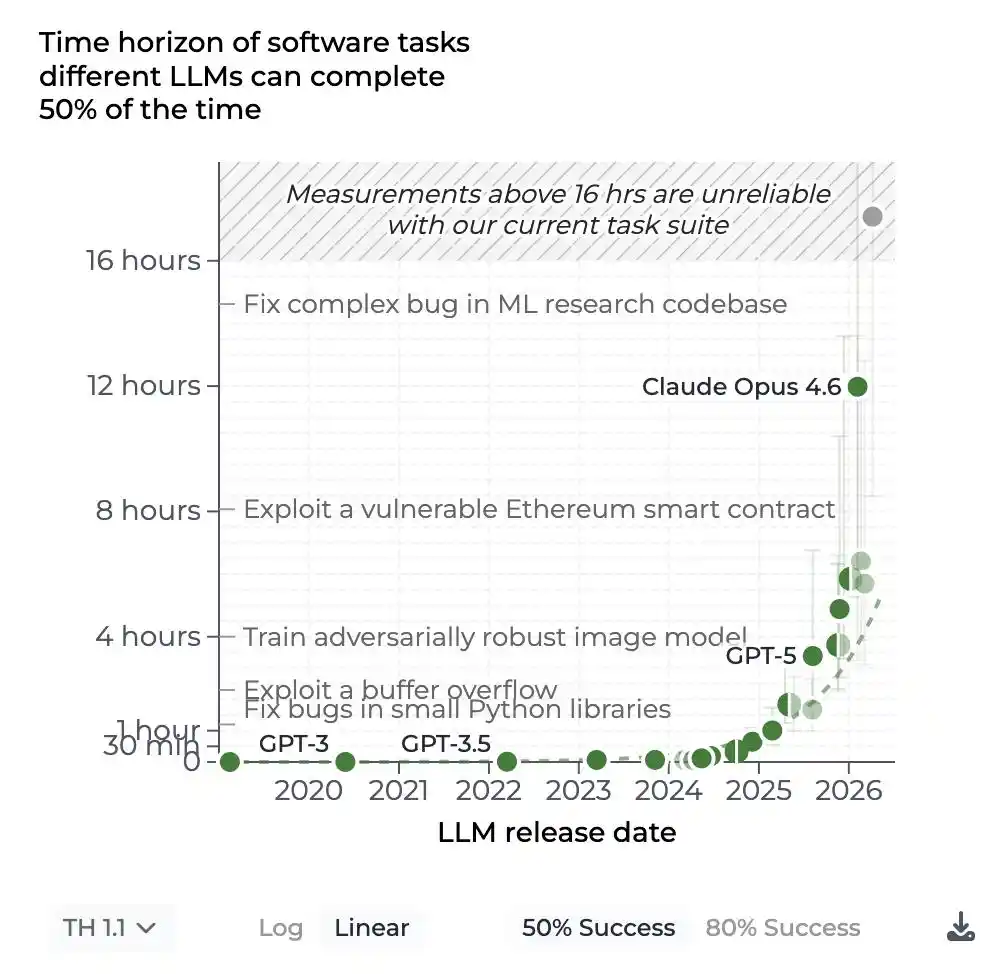
Describe un punto de inflexión sutil: mucha gente «despertó» a principios de este año y de repente se dio cuenta: el agente de IA en mi sector, realmente puede trabajar.
No es un juguete. No es una demostración. Puede realizar un trabajo real, significativo y de ciclo largo (trabajo de horizonte largo) por ti.
Esto significa que el concepto de «modelos que investigan por sí mismos» ya no es solo un guion de ciencia ficción.
Es el siguiente paso que surge naturalmente de una serie de «jugadas divinas» que ya han ocurrido.
Si sigues esta línea hacia adelante, al final está ese modelo que investiga por sí mismo.
El 'Scaling' continúa, el pre-entrenamiento no ha muerto
Pero, ¿en qué se basa exactamente este optimismo?
En una creencia: la curva de escalado ('Scaling') aún no ha llegado a su fin.
En los últimos dos años, los argumentos de «el pre-entrenamiento ha muerto» y «los modelos de lenguaje no llegarán a la AGI» han surgido periódicamente.
Mark Chen se opone «bastante enérgicamente» a estos discursos pesimistas.
Desvela el patrón.
«El pre-entrenamiento ha muerto» suena novedoso, pero en realidad es un guion viejo que se ha repetido una y otra vez en los últimos años.

Cada vez, alguien señala un cuello de botella y dice «llegamos al límite, no podemos superarlo»; cada vez, OpenAI logra sacar un nuevo truco de ingeniería o una nueva visión de investigación para derribar ese muro.
Mark Chen cree firmemente: «Estamos en una curva exponencial. Ha resistido casi 10 órdenes de magnitud, y no hay ninguna razón para que no continúe haciéndolo».

Y la evidencia más convincente es que la propia OpenAI ganó una apuesta.
Una apuesta sobre el razonamiento ('reasoning').
Cuando o1 se inició como proyecto, incluso dentro de OpenAI había quien no creía en él.
En ese momento, el paradigma «pre-entrenamiento + post-entrenamiento» era demasiado potente. Era natural preguntarse: si la máquina ya funciona bien, ¿por qué molestarse en cambiar?
Fue gracias a personas como Jakub Pachocki, Ilya Sutskever y otros con convicción y criterio que lo impulsaron y convirtieron lentamente en una apuesta fundamental para toda la empresa.

Un año después, o1 nació y el paradigma del razonamiento hizo explotar toda la industria.
La curva aún no ha terminado, y los mayores avances suelen provenir de apuestas en las que nadie creía al principio. Estas dos cosas juntas son la base que le permite a Mark Chen afirmar que «la investigación autosostenible por modelos no está lejos».
Cuando un modelo empieza a pensar en tareas que duran semanas, o incluso meses, la innovación que puede producir quizás ya esté más allá de los puntos ciegos cognitivos de los expertos humanos.
Esta es precisamente la base de la «investigación científica autosostenible»: si puede derivar fórmulas matemáticas que los humanos no han visto, también puede escribir arquitecturas algorítmicas mejores que las humanas.
Vibe Researcher: cuando la capacidad de ejecución se abarata
Ya tenemos 'vibe coders': di algo y la IA escribe el código.

La investigación también se está deslizando en esta dirección.
En la entrevista, se mencionó repetidamente un concepto muy controvertido: Vibe Researcher (Investigador de ambiente/vibra).
Esta es una predicción profesional ligeramente autocrítica pero bien meditada.
Mark cree que el investigador de élite del futuro no será quien escriba cada línea de código en PyTorch, sino quien «capte la sensación/vibra».

Tanto en OpenAI como en otros laboratorios, ya puedes ver que gran parte del trabajo se está convirtiendo en «orquestación» ('orchestration') principalmente.
Traducido a lenguaje llano: los humanos se encargan de tener las ideas, los modelos se encargan de hacer todo el trabajo.
Los investigadores piensan en las ideas, el modelo se encarga del resto: implementación, ejecución, planificación.
La hoja de ruta de tres años de OpenAI termina escribiéndolo claramente: que los modelos hagan investigación de extremo a extremo (end-to-end), desde la idea hasta los resultados, todo por sí mismos.
Pero en este camino, hay muchos pozos sin rellenar
A medida que la IA pueda ejecutar y orquestar tareas de forma autónoma, el trabajo humano quedará comprimido a los extremos:
1. Plantear las preguntas verdaderas.
2. Juzgar si las respuestas de la IA tienen «alma».
A esto se le llama «gusto» (Taste).
Porque la máquina no «vive», por lo tanto no tiene «sentido común» y no puede generar «gusto».
Pero pensando con calma, el propio Mark Chen sabe mejor que nadie que este camino está lejos de estar pavimentado.
Primer pozo: la evaluación, colapsada.
Utiliza un término interno: «Benchmaxxing» (maximizar puntuaciones en 'benchmarks') — tomar un montón de problemas casi idénticos al conjunto de pruebas, entrenar con ellos intensivamente, obtener una puntuación excelente, pero sin mejorar en absoluto la capacidad de generalización.
Peor aún, hay muy pocos 'benchmarks' estándar de oro ampliamente reconocidos.
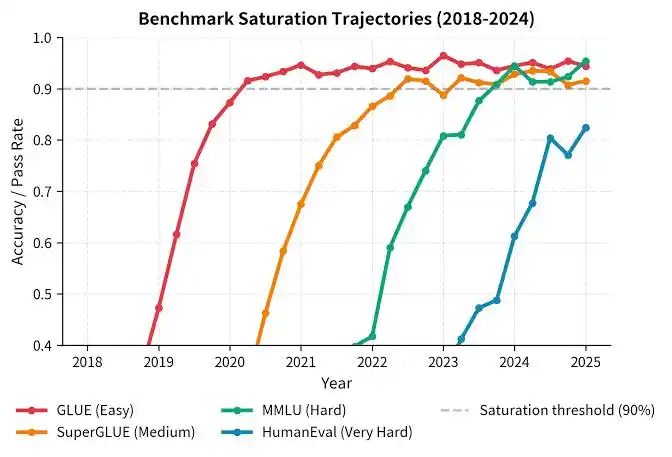
«Realmente estamos en medio de una crisis de evaluación», dice. Pruebas clásicas como el SAT están todas saturadas para los modelos actuales.
Incluso, una evaluación una vez que se hace pública en el mundo, deja de ser una buena evaluación, como un examen que caduca en el momento en que se imprime.
Dos estrategias para abordar este problema:
1. Separar al equipo de creación de evaluaciones del equipo de optimización de modelos, formando un incentivo de tipo adversarial.
2. Desplegar modelos a gran escala y observar los modos de fallo en aplicaciones reales.
También señala que cada nueva capacidad que emerge conlleva una necesidad de evaluación correspondiente, y guiar la dirección de la evaluación es una parte bastante importante de su trabajo.
Segundo pozo: la frontera irregular (jagged frontier).
Un modelo puede resolver problemas de nivel olímpico en matemáticas o informática, pero puede ser incapaz de realizar tareas mundanas que un humano hace sin pensar, como un genio que puede calcular derivadas mentalmente pero no puede atarse los cordones.
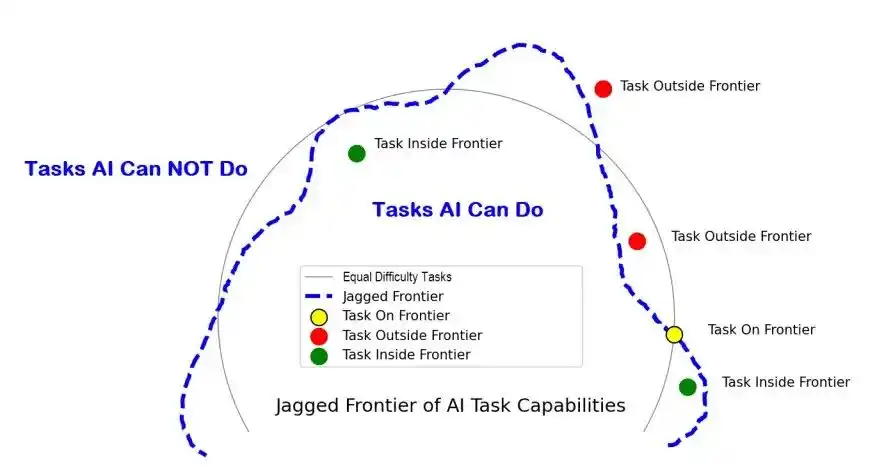
¿La diferencia? Está en el «contexto», está en el aprendizaje continuo ('continual learning') — usar una lección aprendida en una tarea para la siguiente.
Esto es tan natural para los humanos, pero para los modelos es un hueso duro de roer para toda la industria.
Cuando se le pregunta si se necesitan dos o tres avances fundamentales más para llegar a la AGI, Mark no responde directamente.
Dice que capacidades como el aprendizaje continuo son «habilidades básicas que deben desbloquearse», y si eso cuenta como un "avance" no está seguro, pero «muchos tiros ya están apuntando a la portería, y estoy bastante seguro de que entrarán».
Esta es su actitud: los pozos son reales, pero ya hay gente trabajando en cada uno, y él apuesta a que se pueden llenar.
La metáfora de la sopa: abrir un restaurante de fideos después de la AGI
El momento más cálido de la entrevista es la historia de la «sopa».
Se dice que Mark Zuckerberg intentó reclutar investigadores de OpenAI con sopa casera, y la respuesta de Mark Chen fue: traer directamente la sopa a la oficina y repartirla entre todos.
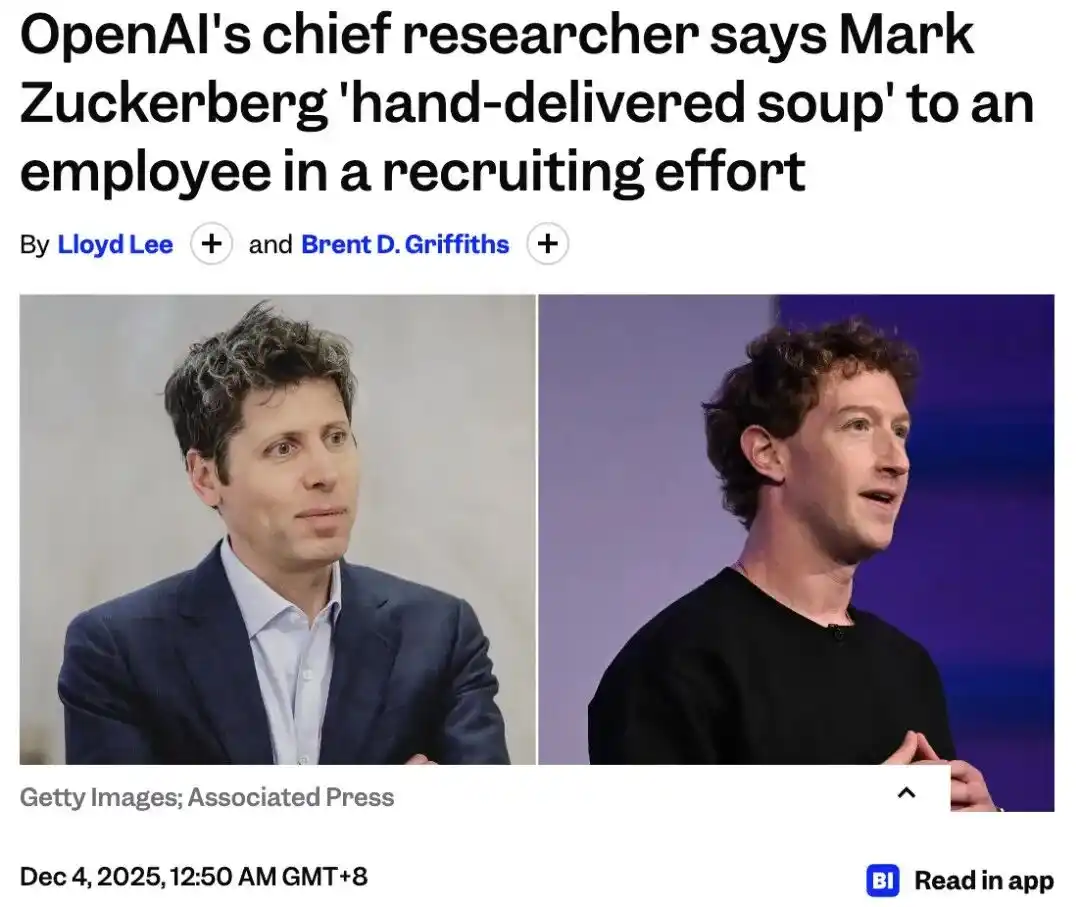
Cuando se le pregunta cuál es su deseo último después de lograr la AGI, esta persona a cargo de los cerebros de IA más poderosos del mundo responde:
«Me gustaría abrir un restaurante de fideos. Ese podría ser mi pasatiempo después de la AGI».
Esta respuesta encierra un significado profundo.
Cuando la IA pueda realizar toda la «investigación autosostenible», cuando todo el conocimiento y la innovación puedan generarse a la velocidad de la luz, el recurso más escaso para la humanidad ya no será la inteligencia, sino la «experiencia».
Una máquina puede calcular el punto óptimo de sal para una sopa, pero nunca podrá darle a esa sopa el «calor» y la «historia».
Referencias:
https://www.youtube.com/watch?v=fpAthTtha8c
https://finance.biggo.com/podcast/1241bc21164ccc75
Este artículo proviene de la cuenta oficial de WeChat "新智元" (Nueva Era de la Inteligencia), autor: Revelación de la ASI







