Author: Vaidik Mandloi
Compiled by: Luffy, Foresight News
Since its launch at the end of 2022, ChatGPT has spawned a vast ecosystem of AI agents. Currently, the total web traffic generated by such programs has surpassed that of all human users worldwide. The online behavior of AI agents is fundamentally different from humans: they don't view ads, click on links, or shop online; they simply crawl web data to complete tasks and leave once finished.
The internet's original architecture and business logic were built around human behavior and usage patterns. Yet today, the vast majority of web visits are not from real people, a situation that deeply troubles many websites. Currently, 2.5 million websites have begun blocking AI crawlers, with platforms like Perplexity getting embroiled in related lawsuits. Cloud service provider Cloudflare has even built "honeypot mazes," using AI-generated nonsensical text to create infinite-loop pages designed to trap various data crawlers.
However, some advanced AI agents have already developed the ability to bypass such protective measures. In the face of escalating human-machine conflict, the industry is now focusing on developing a more reliable human identity verification mechanism. This system needs to accurately identify whether the operator behind the screen is human: real human operators exhibit hesitation, typing errors, and cursor movements with the subtle tremors unique to the human nervous system. This article will analyze the causes behind this transformation, the two mainstream technological solutions, and the choices people will face: either accept centralized biometric monitoring or adopt encrypted zero-knowledge proof technology for anonymous human verification.
AI Disrupts the Internet's Business Model
The root cause of websites blocking AI programs lies in AI undermining the commercial foundation of the internet from both ends. The profitability of the traditional internet is built on user attention: users visit pages, view ads, and content publishers earn revenue. If an AI handles shopping, it might search 5,000 websites at once, whereas an ordinary person typically browses only four or five pages.
AI reads far faster than humans, capable of comparing prices across the entire web and even placing orders directly within minutes, a process that generates no ad views. This means websites bear server costs without earning any revenue.
Simultaneously, AI search is continuously diverting website traffic. After Google added AI-generated summaries at the top of search results, only 8% of users clicked through to the original webpages, leading to a direct 33% drop in referral traffic for major content sites from Google. Within just a year of its launch, this feature's monthly active users exceeded 1 billion, and platform retrieval volume has doubled every quarter since its debut.
Surely everyone remembers Chegg, the study help platform. It originally operated a homework Q&A business relying on strong search rankings, but has now officially shut down its Q&A section, attributing its demise to the impact of ChatGPT. Content creators are caught in a double bind: crawlers scrape content on one side, while AI summaries intercept traffic before users even reach the website.
The data gap is even more staggering. For every referral visit OpenAI's crawler brings to a partner website, it previously scrapes data from 400 pages; for Anthropic, this ratio reaches 38,000:1. These companies use publicly available data across the web to train AI models for free, then use the finished products to divert traffic that originally belonged to the websites.
In any other industry, such predatory data collection would have sparked countless lawsuits, yet in the AI field, these companies secure valuations in the trillions.
Your Body is the New Password
For the past 25 years, the internet has primarily relied on CAPTCHAs to distinguish humans from machines. People needed to identify traffic signs or input distorted characters. This mechanism worked because machines' image recognition capabilities were far inferior to humans in the past.
Now the situation is completely reversed. OpenAI's agent operations score far higher than humans in Google's human verification system simulations, capable of accurately clicking interfaces and copying/pasting content; AI-generated photos can fool identity verification systems, and deepfake video calls have even been used by criminals to complete bank transfers. The design premise of traditional verification methods—that machines are weaker than humans—no longer holds.
The industry is now forced to focus on areas where AI still struggles to replicate human capabilities: the physical behavioral characteristics displayed when humans operate electronic devices, also known as behavioral biometrics. Companies like IBM and BioCatch are developing related systems. This technology not only verifies identity at login but also monitors user behavior throughout the session, collecting data on cursor movement speed, page scrolling patterns, typing rhythm, keystroke pressure, text editing habits, and even phone holding angles, with the phone's gyroscope recording relevant information throughout.
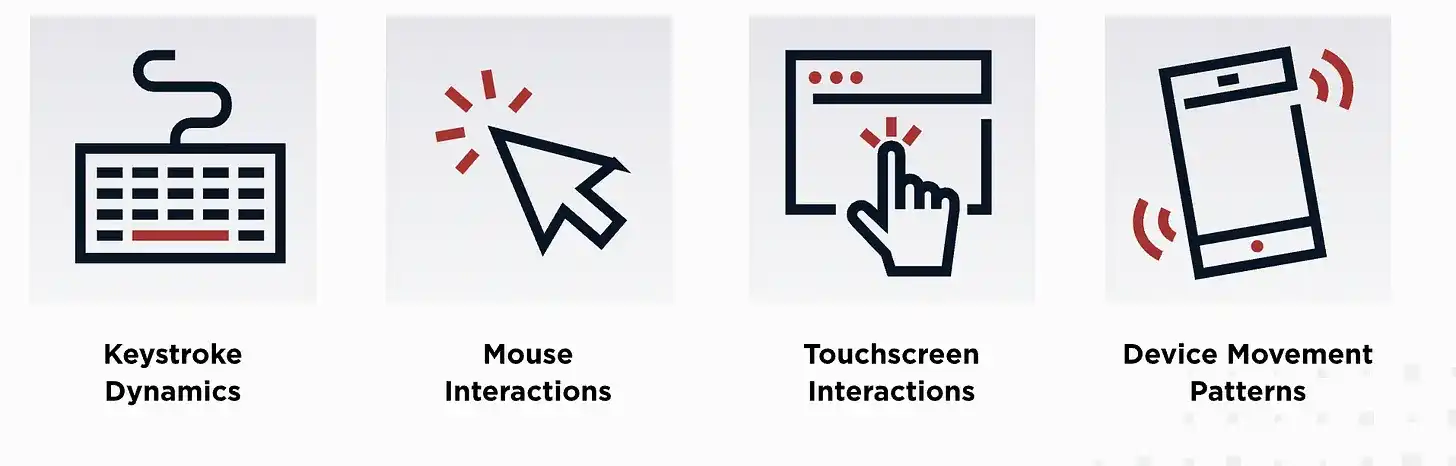
The system can also recognize details like the user's dominant hand and finger sliding trajectory. IBM needs to collect usage data just eight times to establish a unique user behavioral profile, which is then continuously compared against benchmark data for every subsequent operation.
BioCatch's technology can even identify online scam scenarios. When a victim reads out account passwords following a scammer's phone instructions, the panicked and disjointed typing rhythm is precisely captured by the system. Within just one year, the system helped 257 banks identify approximately 2 million money laundering accounts. The EU has also begun piloting gait recognition technology. Just three years into the era of AI agents, EU border personnel are already collecting data on people's walking gaits.
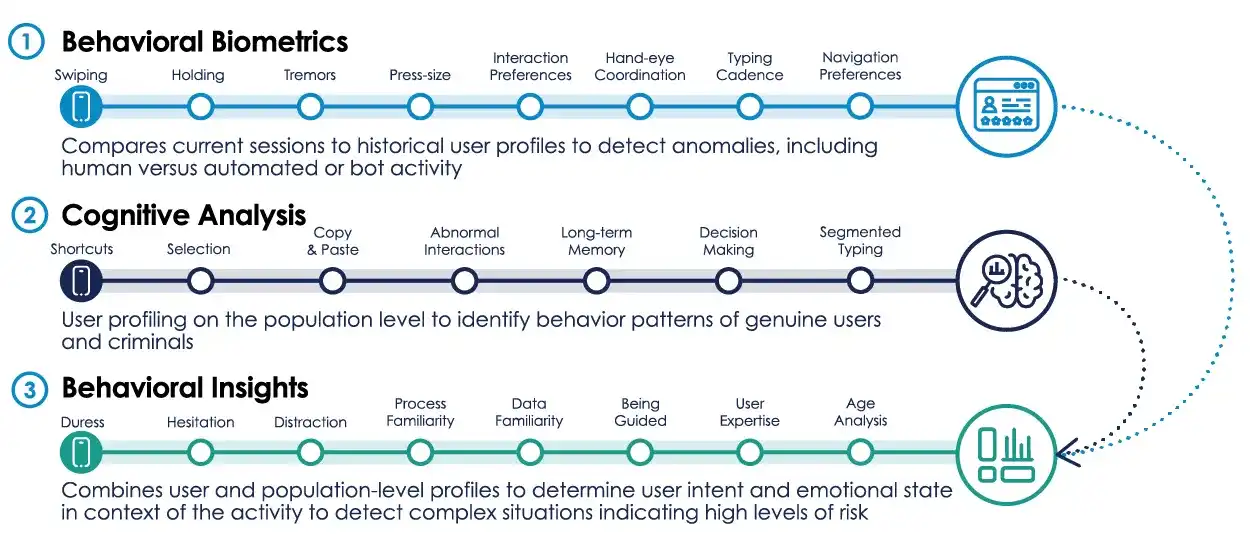
Related research also incorporates the Stroop effect: when the word "blue" is written in green font, the human brain experiences conflict between word meaning and visual color, significantly slowing reaction time, but AI remains unaffected. Research finds this cognitive interference is directly reflected in typing behavior. Platforms may not even need specific test questions; based on keystroke rhythm alone, they can judge whether the operator is human. Human typing habits contain unique characteristics of brain information processing.
Previous web tracking mainly recorded user browsing, clicking, and consumption behaviors. Users could evade this by blocking cookies, using VPNs, or turning off location services. But behavioral biometrics collects instinctive human characteristics: cursor movement patterns and typing rhythms are difficult to consciously alter.
Each person's behavioral characteristics are as unique as fingerprints. Unlike passwords or keys, this biometric profile cannot be changed or reset. Once this technology becomes widespread, major platforms will be forced to adapt. Voice simulation technology can already deceive in phone calls, and video deepfake technology is following closely. If this is the future, the core question emerges: Who will ultimately control this human data?
Who Controls the Human Verification System?
Currently, the industry is divided into two main camps exploring human identity verification solutions.
The first is Sam Altman's World (formerly Worldcoin). Users need to approach a spherical iris-scanning device. The device collects iris information and generates an encrypted credential to prove the user is a unique natural person. Currently, 18 million people across 160 countries have completed iris registration. In April 2026, World formed user verification partnerships with dating app Tinder, video conferencing platform Zoom, and e-signature service DocuSign. It also collaborated with Coinbase to launch the AgentKit tool, allowing users to link their AI agents to their verified identity. Platforms can confirm a human is behind the agent without leaking personal information.
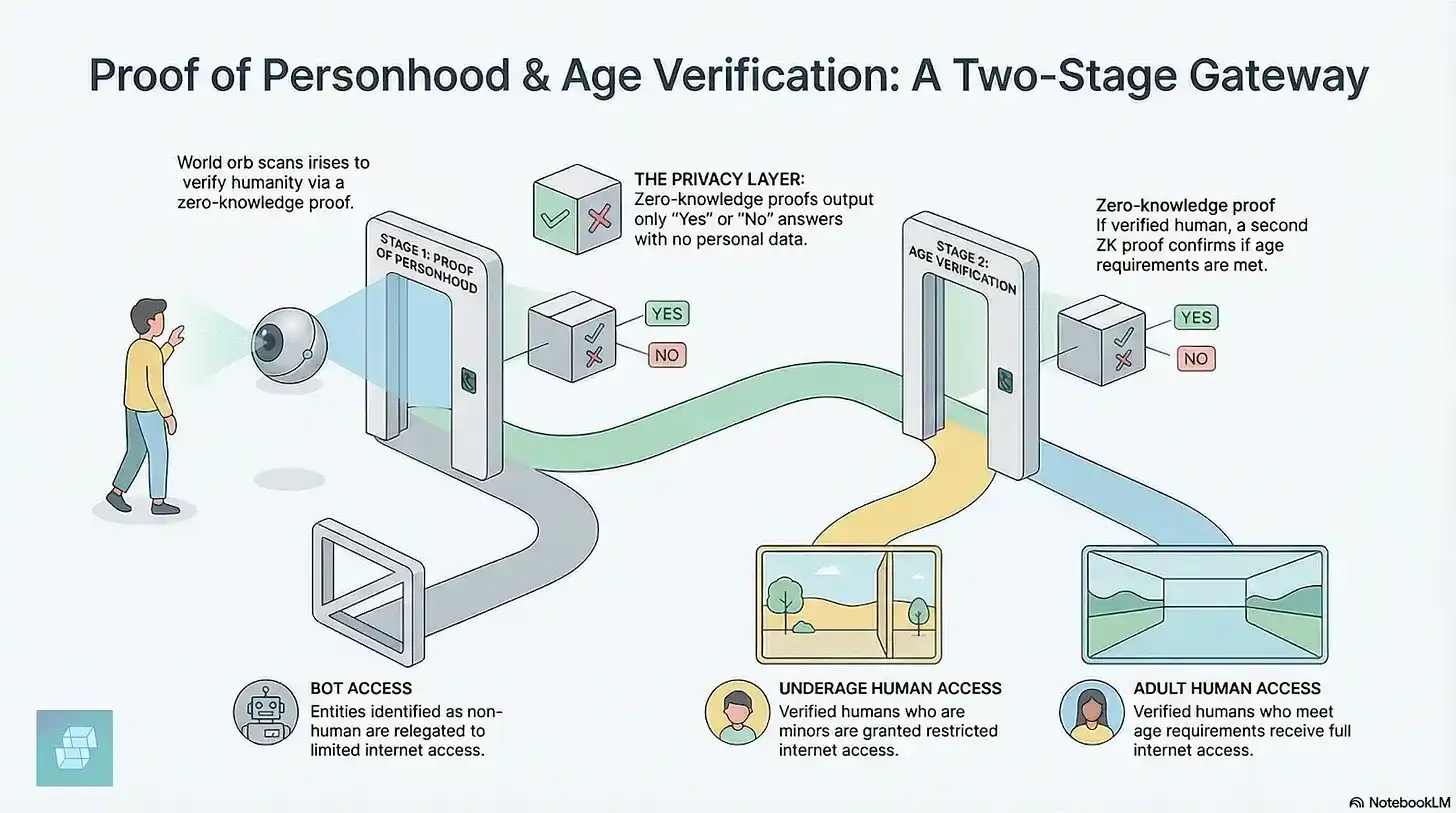
However, iris scanning technology has been explicitly banned by multiple countries. The core reason for this resistance is that the public is unclear about the potential risks of authorizing biometric data collection. An investigation by MIT Technology Review also found that World, without valid authorization, privately collected multiple human vital signs data like heart rate and respiration in addition to iris data.
The second category is zero-knowledge proof based on encryption technology, which allows you to prove you are human without revealing your real identity, location, or appearance. Vitalik Buterin proposed this concept as early as 2023. He argued that if a decentralized human identity system cannot be built, the internet will ultimately move toward centralized identity control. Once identity verification authority is held by companies or governments, surveillance mechanisms will become embedded in the network's foundation.
Decentralized human identity systems have seen large-scale implementation attempts before, but ultimately failed. Idena was among the first blockchain projects promoting "one person, one identity." Within just two years of launch, 40% of network accounts and 48% of rewards were controlled by 23 institutions. Account operation teams in places like India and Russia hired ordinary people to lend their identities for less than a dollar per hour, profiting up to 55 times. Researchers also found that even children's identities were used as puppet accounts.
Vitalik had anticipated such risks earlier. He stated that for human identity verification systems, the lowest-cost attack method is not deepfakes or advanced hacking, but paying people in low-income regions to lend their personal identities. Any human identity verification system requires financial support: iris-scanning devices and on-chain verification nodes need continuous investment.
Yet once identity credentials gain economic value, a black market for identity lending inevitably emerges. In a world of stark wealth inequality, the capital-strong will always control such markets.
"Forcing a one-person-one-vote rule in a system with actual economic incentives will only repeat the failures of 20th-century social experiments."
Objectively, both development paths have clear flaws. Centralized solutions can achieve scale but involve users' biometric data being stored by companies prone to over-collection, companies that themselves benefit from the current bot proliferation. The encryption route theoretically protects privacy but struggles to escape real-world economic imbalances, ultimately being exploited by gray-market industries.
If forced to choose, I'd still bet on the encryption solution. Because behavioral biometrics and centralized iris scanning permanently record your bodily information, and the ownership of this information belongs to whoever deploys the system. Once they have your data, you cannot delete or transfer it; this data is locked with the company that collected it.
Even knowing zero-knowledge proofs might be exploited, they are still worth developing, as this proof can confirm you are human without revealing more information. Conversely, abandoning this path means in the future, every website we visit will retain our physical behavioral data. Currently, this centralized surveillance-based solution is being implemented far faster than the encryption technology route.