Author: qinbafrank
In February, in the article "What Does This War of Capital Expenditure Mean?", it was discussed that key segments in the computing power industry chain can still capture the greatest value: chips, packaging & testing, memory, optical modules, etc. Those with capacity that is difficult to expand rapidly or those with extremely high moats will enjoy the红利 of massive capital expenditures.
There is still significant room for efficiency optimization: Distillation, quantization, MoE, dedicated chips, liquid cooling, nuclear fusion (long-term) on the inference side may reduce the energy consumption and cost per unit of computing power by another 10–100 times. Opportunities should be sought in these segments.
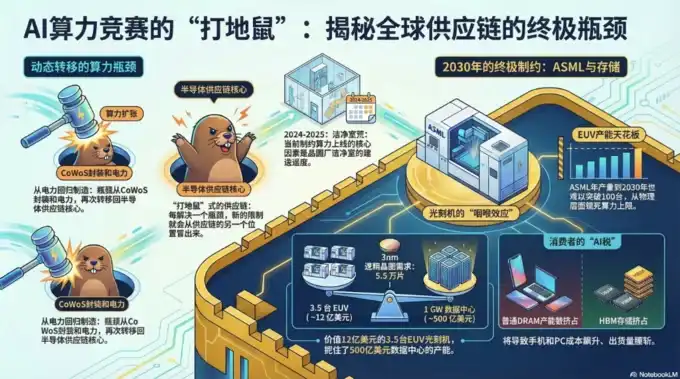
Recently, multiple investment banks including Morgan Stanley, J.P. Morgan, Bank of America, Goldman Sachs, UBS, Citi, Bernstein, and HSBC have published update reports on AI/semiconductors/power/memory. The bottlenecks for AI hardware have expanded from the single dimension of "GPU supply" to collective tension across five dimensions: power, chips, memory, equipment, and materials.
The scale of AI demand has broken through the forecast intervals of all traditional power planning, semiconductor equipment capacity, memory price models, and robot installation assumptions.
Morgan Stanley's global thematic research review points out that the global weekly large language model token consumption soared from 6.4 trillion to 22.7 trillion within 3 months, an increase of 2.5 times. The U.S. data center power gap for 2025-28 is 55 GW; J.P. Morgan's inaugural coverage of data center high-performance computing project debt directly gives a "122 GW financing gap in the next 5 years" figure. U.S. 5-year power planning has surged from 101 GW to 230 GW, with 44% of new projects experiencing grid connection wait times exceeding 4 years; Bank of America's latest target price report for Alphabet directly revises its 2026 capital expenditure upward to $181.5 billion, doubling year-on-year, with free cash flow declining 62%. These three sets of data are not outputs from the same framework, but independent portraits from three separate institutions on different research paths.
The evolution of bottlenecks in the semiconductor industry chain (especially in the AI computing power field) precisely progresses in this clear sequential order: "Computing (GPU) → Memory (HBM, etc.) → Optical Interconnect → Power/Liquid Cooling". This is the industry consensus for 2025-2026. As AI training/inference clusters scale from single cabinets (dozens of GPUs) to super-large scale (thousands to hundreds of thousands of GPUs), each time a bottleneck in one segment is resolved, the next physical/supply chain constraint is immediately exposed, forming "Leontief-style" complementary constraints (if one is missing, nothing can be shipped).
It is necessary to understand why this evolution occurs, the current status, and the underlying physical/engineering reasons:
1. First Phase Bottleneck: GPU Computing (Dominant from 2022-2024) Core Constraint:
High-end GPU (e.g., NVIDIA Hopper H100 → Blackwell B200 → Rubin) wafer capacity itself + advanced packaging.
Why it was the bottleneck: AI large models require massive parallel computing. TSMC's 4nm/3nm/2nm logic processes + CoWoS (2.5D/3D packaging) capacity once became the biggest choke point. Even if front-end wafers were sufficient, the back-end capability to package logic chips + HBM stacks couldn't keep up, preventing the entire GPU from being produced.
Easing situation: TSMC aggressively expanded CoWoS (capacity doubling 2024-2025), NVIDIA Blackwell is shipping in large volumes. But this only unlocked the "computing" segment, immediately exposing new problems.
2. Second Phase Bottleneck: Memory (HBM High Bandwidth Memory, becoming the tightest from 2024-2025)
Core Constraint: HBM3/HBM3e/HBM4 capacity.
Why it became the next bottleneck: GPU computing power increased, but model parameters exploded (trillions to tens of trillions of parameters), making data movement (memory bandwidth) the "memory wall." HBM can transmit several TB of data per second, over 20 times faster than conventional DDR memory. Because HBM is adjacent to the logic chip, data doesn't need to travel far, thus saving energy.
A single B200 GPU requires 192GB+ of HBM3e. A single cabinet (NVL72) HBM total capacity has reached 30-40TB, and bandwidth demands far exceed traditional DRAM.
Supply chain status: Only SK Hynix, Samsung, and Micron can mass-produce HBM, with complex processes (TSV + stacking). 2025 supply is already sold out, 2026 remains in short supply, with prices soaring 246% year-on-year. Even if GPU chips are ready, without HBM, assembly and delivery are impossible, causing delays in entire AI cluster deployments.
Result: Memory transformed from a "commodity" into a strategic choke point, potentially accounting for 30% of capital expenditures.
3. Third Phase Bottleneck: Optical Interconnect (Transition underway in 2025-2026)
Core Constraint: Physical limits of copper cables (NVLink/NVSwitch) in bandwidth, distance, power consumption, and weight.
Why a shift to optics is inevitable: Copper can still work within a single cabinet (72 GPUs), but when scaling to multi-cabinet or even thousands of GPU interconnects, copper cable attenuation is severe (effective distance <1 meter at 1.8TB/s bandwidth), weight explodes (NVL72 cabinet copper cables exceed 5,000, total weight 1.36 tons), and power consumption is high (replaceable optical modules replacing copper add an extra 20,000W). Signal integrity, latency, and cooling cannot support larger clusters.
Solution: Shift to optical interconnect (CPO Co-Packaged Optics + Silicon Photonics). Embedding optical engines directly next to the GPU/ASIC, using fiber optics for scale-out, achieving higher bandwidth density, lower per-bit power consumption, and longer distances.
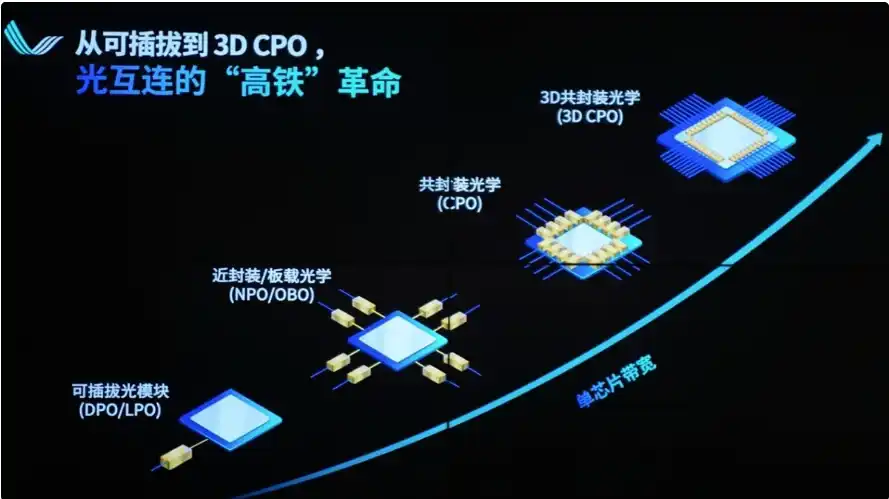
NVIDIA heavily bet on this at GTC 2026, having invested in optical companies. Demand for 800G/1.6T optical modules is exploding. Companies like Lumentum, Broadcom, Coherent, Ayar Labs become new winners.
Current progress: Copper has reached its limit. Optics are shifting from "optional" to "mandatory," breaking through AI data center performance ceilings.
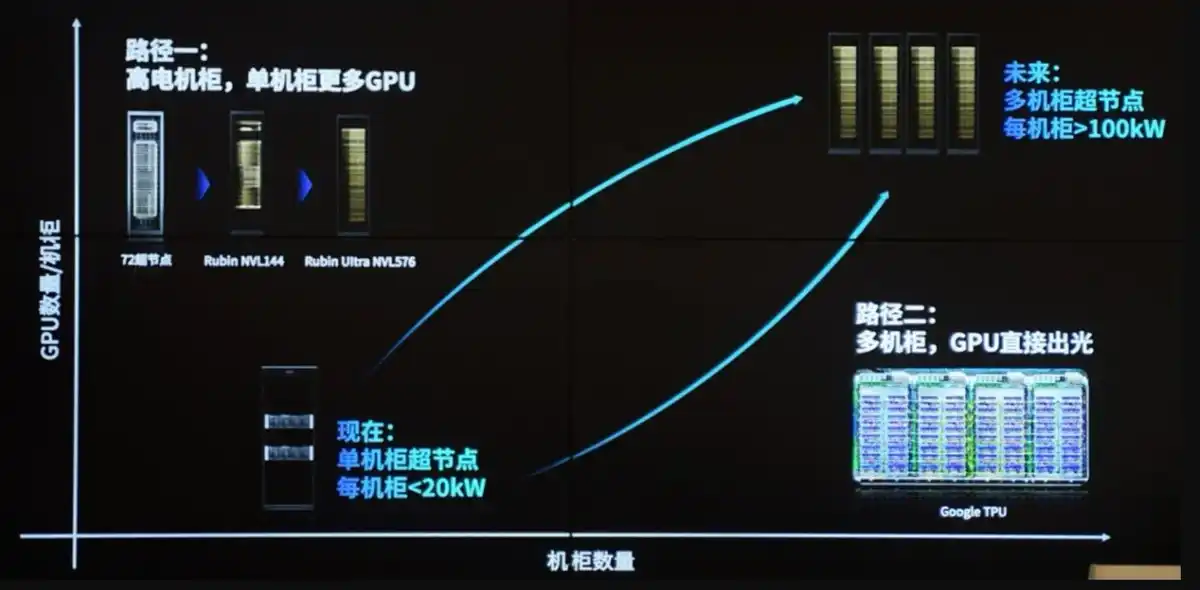
4. Fourth Phase Bottleneck (The Current Frontier): Power + Liquid Cooling (Becoming the ultimate physical constraint from 2026 onwards) Core Constraint: Power Wall + Cooling Wall + Grid Access.
Why it's the ultimate bottleneck: Each GPU's power consumption rose from 300W→700-1200W. Single cabinet power surged from 10-20kW (CPU era) to 120-200kW+ or even higher. Traditional air cooling has a physical limit of only 20-50kW, with unacceptable noise, airflow, and energy consumption.
Power side: Data centers require GW-level power supply, with grid connection queues potentially lasting years. Delivery cycles for transformers, solid-state transformers, and other equipment are extending to 100 weeks. Microsoft's CEO once bluntly stated, "We have GPUs but no electricity to plug them into."
Liquid cooling side: Must switch to Direct-to-Chip liquid cooling or immersion cooling, combined with microfluidics, cold plates, and other technologies. TSMC has demonstrated silicon-based liquid cooling on the CoWoS platform, supporting >2.6kW TDP. Liquid cooling/thermal management companies like Vertiv (VRT) are becoming new infrastructure core players.
Chain reaction: PUE (Power Usage Effectiveness) requirements are <1.2. Waste heat recovery, nuclear/new energy grid integration have become new topics. Even if all previous segments are solved, without power and cooling, cabinets cannot be racked and operated.
The Essential Logic of AI Computing Power Industry Chain Bottleneck Shifts AI computing power is not a "single-point" issue, but a systemic Leontief production function — GPU, HBM, interconnect, power, cooling must match based on the lowest-capacity component. Hyperscalers (Google, Microsoft, Meta, etc.) each time they solve one, immediately push capital and innovation to the next segment.
Currently (2026), we are in the transition period of "accelerated optical interconnect deployment + large-scale commercialization of power/liquid cooling." New bottlenecks may yet emerge (e.g., lasers, fiber materials, or grid transformers), but this chain of "computing → memory → optics → power/cooling" has become the recognized industry path.
This also explains why the investment logic is shifting from NVIDIA/TSMC to the HBM trio (SK Hynix, etc.), optical manufacturers (Lumentum, Coherent), and liquid cooling/power infrastructure companies (Vertiv, related power supply companies).
Every bottleneck shift is reshaping the value distribution across the entire semiconductor + data center industry chain.








