Author: Friday, Shenchao TechFlow
Anthropic just delivered a performance report that is impeccable on paper.
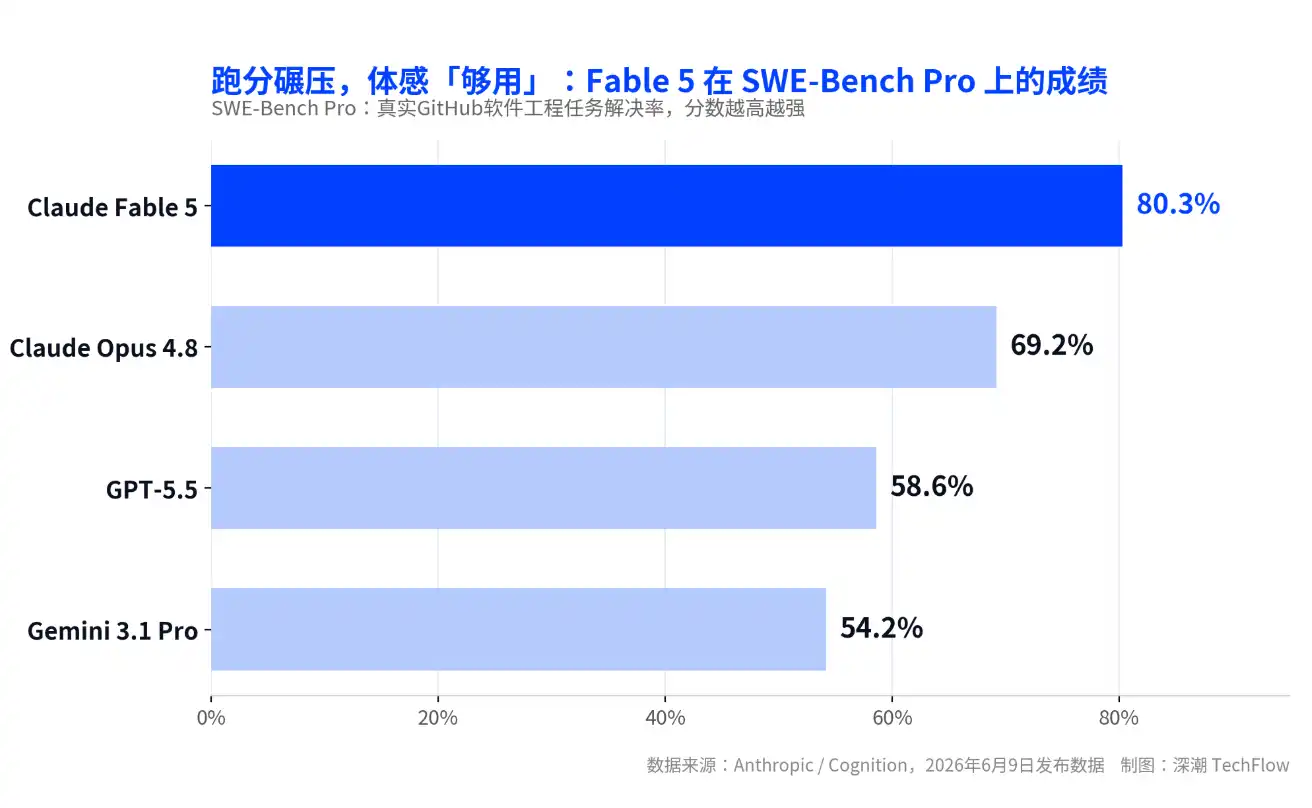
Claude Fable 5, released on June 9th, is the company's first publicly available Mythos-tier model. It scored 80.3% on the real-world software engineering benchmark SWE-Bench Pro, leading its own previous flagship Opus 4.8 by about 11 percentage points and surpassing GPT-5.5 by over 20 percentage points.
But user reactions poured cold water on the excitement.
Three days after the release, a hot post on the r/artificial subreddit (weekly traffic 305k) was titled: "Claude Fable made me realize I don't need a better model anymore." The poster, Axi0m-22, said he used Fable for a while for security research and daily tasks, then almost immediately switched back to Opus for coding and Haiku for miscellaneous jobs. He made an analogy: It's like watching the iPhone 17 launch while holding an iPhone 14. "You know the new one is better, but you think: Nah, mine is fine."
The High-Vote Zone is Occupied by the "Good Enough" Camp: Model Fatigue Becomes the Prevailing Sentiment
The top comment with 42 upvotes states: "Other than the larger context window, I haven't felt the need for a stronger model since Opus 4.5."
Another user, hyprlab, received 13 upvotes for this statement: "I don't see any benefit to my workflow from switching to a model that burns tokens even faster. Opus 4.8 high-intensity mode is already comfortable enough."
There's a common cost calculation behind such remarks.
Fable 5's API is priced at $10 per million input tokens, nearly double that of Opus 4.8. User siromega37 was blunt: "Higher token consumption, but no return on investment. I think we're seeing the plateau, the bubble will eventually burst."
User hobopwnzor gave a more systematic interpretation: "We've been near the top of the S-curve for a while. Recent improvements mainly come from tool use and peripheral engineering, not the core model capability itself."
Safety Guardrails Become the Biggest Complaint: "90% of Intended Uses Get Rejected"
If "good enough" is just sentiment, then complaints about safety guardrails are a concrete product issue.
According to Anthropic's official description, Fable 5 shares the same underlying model as the Mythos 5, which is only available to a select few institutions. The difference is that Fable has a safety classifier installed: requests involving high-risk fields like cybersecurity are intercepted and handed off to Opus 4.8 to answer. The company states this mechanism is tuned conservatively, triggering in less than 5% of sessions on average, and may mistakenly block harmless requests.
In this Reddit thread, the perceived trigger rate is clearly much higher than 5%. User jradoff, whose comment got 17 upvotes, said he asked Fable to review the security of his code, and "basically any mention of security-related stuff gets rejected," then it falls back to Opus. Another comment with 12 upvotes was even harsher: "90% of what you want to use it for gets rejected, which makes it useless."
Paid users are even more aggrieved. User kaitava, who subscribes to the $200 tier, wrote: "I'm paying double the usage fee, I ask it to do a security review, and I get downgraded to Opus. Now I dislike everything about it, just waiting for OpenAI to catch up."
For a flagship product touting a leap in capability, "the usability cost paid for safety" is becoming a core variable in users' decisions to pay.
Opposing Voices: Heavy-Duty Task Users Feel the Difference is "Night and Day"
The hot post isn't without opponents, and the opposing camp's profile is quite clear: the heavier the task, the higher the praise.
User Phylaras's comment received 15 upvotes: "Fable made a substantial difference for me. On those massive, complex tasks demanding huge context windows, it caught errors that weren't spotted before." A user claiming to work on high-energy physics simulations said that a single simulation model can easily be 8,000 to 10,000 lines of code with hundreds of interacting models. "Having a model that can work independently and continuously, understanding environmental details, is something I eagerly anticipate."
The fiercest rebuttal came from user Navetz: "Honestly, people who have used this model think posts like this are insane. To me, it feels like a different, smarter person. I've been using it non-stop. I explained it to non-technical friends: it's like going from a college basketball player directly to an NBA starter."
Some offered compromise usage patterns. User ready-eddy suggested using Fable as a "planner and fixer," not as the daily "builder," unless you don't mind burning money. Another comment summed it up more like a user manual: Using Fable for spreadsheet calculations is choosing the wrong model; using Haiku to run a complex task with 16 agents is also choosing the wrong model. "There's no inherently bad model, only models used for the wrong scenario."
After the Disconnect Between Benchmarks and User Experience, Will Public AI Get Stronger?
The most interesting comment in this debate shifted the topic from product to industry structure.
User KedMcKenna proposed a "Public AI Freeze Theory": the models accessible to ordinary people might forever remain near the current level, while corporate and governmental elites will continuously get access to stronger private models. "We know of at least Mythos, and there are likely even stronger models we'll never hear about."
This comment points to a fact: Mythos 5 is indeed not open to the public and is currently only available to cyber defense agencies and critical infrastructure companies through the Project Glasswing program.
Looking at benchmark scores and public sentiment together, the conclusions aren't contradictory.
Benchmarks measure the ceiling of capability, while the Reddit high-vote zone reflects the ceiling of daily needs. When most users' tasks were already satisfied in the Opus 4.6 era, stronger models can only prove themselves in extreme scenarios like physics simulations or ultra-long context tasks. Model vendors no longer face a "can it be done" problem, but rather a "who needs it, how much are they willing to pay, and how much safety friction can they tolerate" problem.
Three days after release, Fable 5 received two completely different report cards: one on the benchmark charts, and another in the court of public opinion. Which one is closer to the truth depends on how quickly Anthropic adjusts its safety classifier and how heavily reliant users vote with their wallets.








