How small can an image be compressed?
In February 2025, the Joint Photographic Experts Group (JPEG) quietly announced a milestone celebrated within the industry: the official release of JPEG AI, the first end-to-end learned image coding international standard, which had been years in the making and was highly anticipated.

The news spread, with many researchers reposting on social media, adding comments like 'AI has finally entered the standards.'
The JPEG standard was born in 1992 and has been a fundamental language for digital images for over three decades. Now, artificial intelligence is starting to rewrite the grammar of this language.
However, behind the celebration lies a subtle reality: even JPEG AI still has considerable distance from true 'perceptual compression.'
Engineers know that traditional metrics like Peak Signal-to-Noise Ratio (PSNR) have little to do with what the human eye perceives as 'good-looking.' An image scoring high on PSNR might look mediocre to a person, while another image with lower PSNR might appear detailed and realistic. Optimizing mathematical metrics and optimizing for human perception are two entirely different things.
For decades, from JPEG to VVC and now JPEG AI, the design logic of almost all codecs has revolved within the framework of mathematical metrics. Perceptual compression (directly optimizing for the human visual experience) has always seemed like a distant goal in academic papers, not an engineering reality that could fit into a phone.
At this critical juncture, a team of engineers at Apple quietly published a paper with their answer, codenamed: PICO.

Paper Title: What Matters in Practical Learned Image Compression
Paper Address: https://arxiv.org/pdf/2605.05148
Why is 'Looking Better' Much Harder Than 'Scoring Higher'?
To understand PICO, one must first understand what image compression is actually doing.
Saving a photo as a file is essentially a problem of 'choosing what to forget and what to remember.' With limited storage space, some information must be discarded while making it as unnoticeable as possible to the viewer. Different codecs follow different 'discarding' rules.
Traditional codecs like JPEG, AV1, and VVC are manually designed rule-based systems. They divide the image into blocks, transform, quantize, and entropy code—each step based on decades of accumulated human expertise. These systems can perform excellently on mathematical metrics like PSNR, but their design is inherently oriented toward 'reducing pixel error,' not 'reducing visual discomfort for the human eye.'
The problem is that the human eye is not a pixel error meter. The human eye's sensitivity to texture, text, and detail is far more complex than mathematical formulas. When you compress a street scene photo heavily, the PSNR might still be respectable, but you might see blurred building edges or distorted text on street signs—precisely what the human eye detects first.
The emergence of learned codecs theoretically opened a new door: neural networks could be trained end-to-end directly for human perception, rather than for mathematical formulas. But before PICO, existing perceptual learned codecs were either too slow for practical use, lacked cross-device compatibility, or couldn't flexibly control bitrate, making them impossible to integrate into a consumer-grade product.
Three Core Problems, Three Solutions
The full name of PICO is Perceptual Image Codec. This name directly states its goal: to satisfy the human eye.
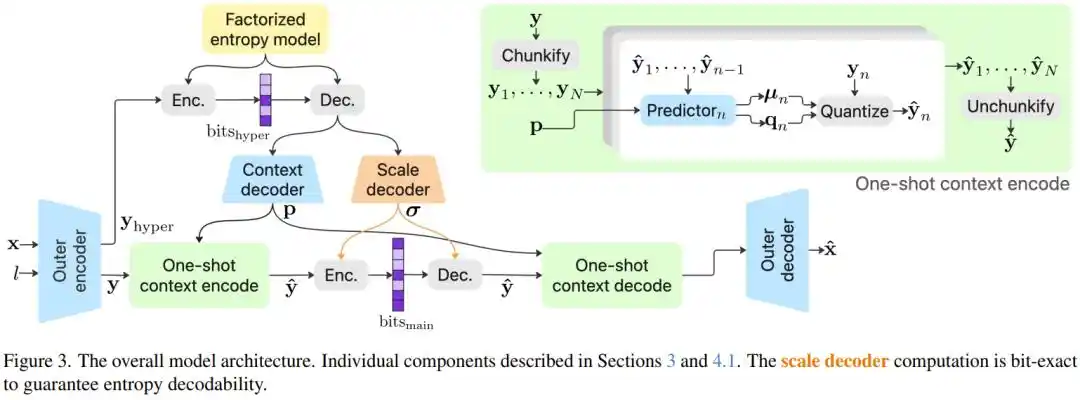
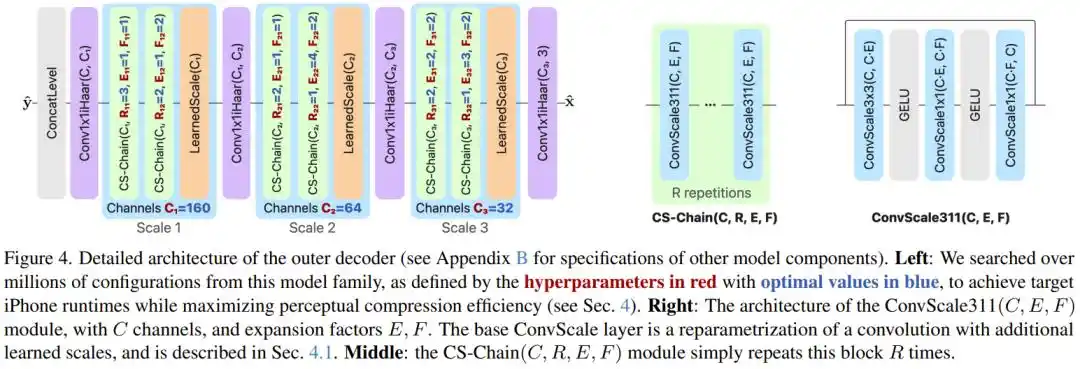
The research team systematically explored millions of model configurations and introduced several key technological innovations.
First Problem: Entropy Coding is Slow. What to Do?
A major challenge in image compression: to compress further, a codec needs an 'entropy model' to accurately estimate the information content of each pixel. The most accurate method is autoregressive coding: compressing each pixel requires looking at the surrounding already-compressed pixels for sequential prediction. It's like a chef checking the pot's state after adding each ingredient before deciding the next step. Accurate, but extremely slow.
PICO's solution is the 'One-shot Context Model': decoupling the crucial 'scale parameter' in entropy coding and computing it all in one forward pass, eliminating the need for waiting back and forth; other parameters can be computed in parallel. This retains the precision of autoregressive methods while circumventing their speed bottleneck. The result: removing this module degrades model performance by 10.28%; with it, speed is almost unaffected.
Second Problem: Perceptual Training Can Cause Hallucinations. What to Do?
Images trained with GANs (Generative Adversarial Networks) often 'look realistic,' but it might be a fabricated realism—hair strands turning into non-existent patterns, smooth surfaces gaining false textures. More troublesome, the human eye is extremely sensitive to text; even a slight distortion of a single letter is immediately noticeable.
PICO specifically designed TextFidelityLoss for text: using an off-the-shelf text detector to automatically find text regions in the image, then applying strict pixel fidelity constraints in these areas while suppressing the GAN's 'creative freedom' in text regions. Experiments showed that adding this loss function halved the absolute error in text regions.
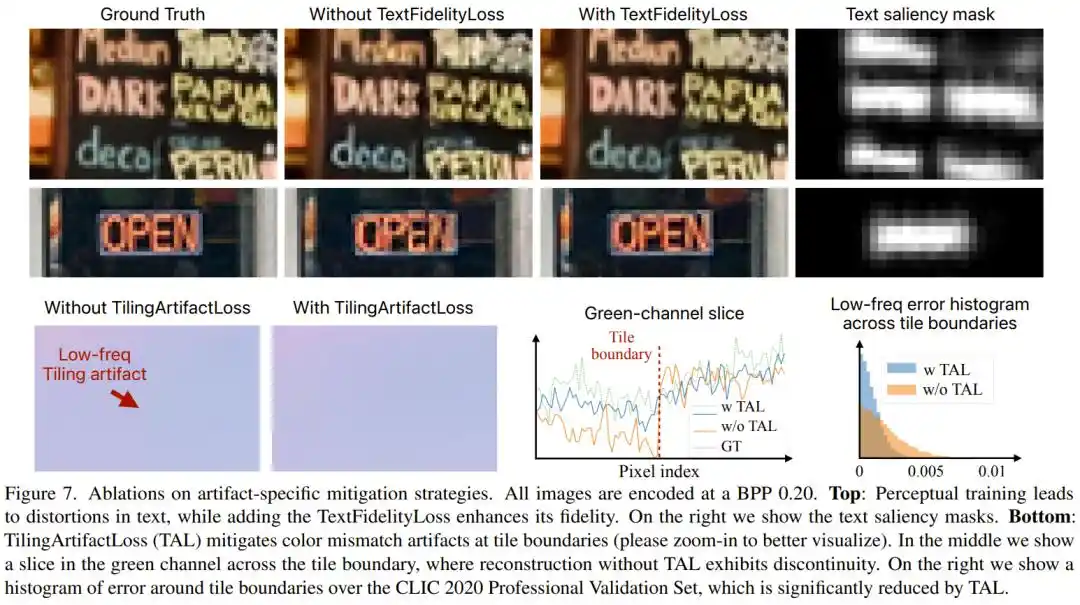
Third Problem: Processing Images in Blocks Leaves Color Block Boundaries. What to Do?
To run fast on mobile phone chips, PICO divides images into 504×504 pixel tiles, processes them separately, and then stitches them back. However, GANs during training tend to ignore low-frequency color, often causing visible color discrepancies between adjacent tiles, similar to a poorly 'stitched' feeling in photo editing. The research team specifically introduced TilingArtifactLoss, a multi-resolution L1 loss, forcing the model to maintain color consistency across multiple spatial frequencies. This measure reduced errors at tile boundaries by more than half.
Experimental Results
The Apple team didn't rely solely on benchmark metrics. They commissioned a third-party platform, Mabyduck, to organize a large-scale human subjective evaluation.
The evaluation used a blind, pairwise comparison method: 610 screened evaluators (required to pass color blindness and compression artifact detection tests) compared reconstructed results of the same image using different codecs in paired comparisons, ultimately aggregated into a Bayesian ELO score. A total of 74,925 pairwise comparisons were collected.

The final numbers tell the story: At the same visual quality, PICO's file size is only one-third to one-half that of AV1, AV2, VVC, ECM, and JPEG AI—in other words, to store the same image, it requires only 30%-43% of the bits needed by these standards. Compared to the strongest existing perceptual learned codecs (HiFiC, MRIC, etc.), PICO also saves 20%-40% in file size.
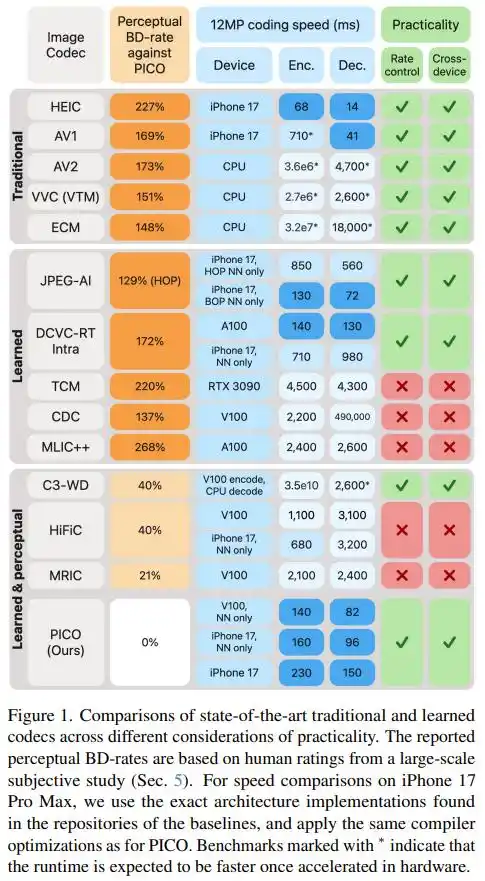
In terms of speed, on an iPhone 17 Pro Max, PICO encodes a 12MP photo in just 230 milliseconds and decodes in 150 milliseconds. Most top-tier ML codecs running on NVIDIA V100 server GPUs are slower than this.
Notably, the paper also specifically recorded a 'counterexample': on the traditional PSNR metric, PICO performed average, even inferior to DCVC-RT and VVC. This恰好印证了团队的基本判断 perfectly illustrates the team's fundamental judgment: optimizing perceptual quality and optimizing mathematical metrics are inherently two different directions; you cannot have your cake and eat it too.
A Milestone, Not the Finish Line
PICO certainly has limitations. The paper acknowledges that for highly regular synthetic images like cartoons or schematic diagrams, PICO's compression efficiency is inferior to traditional codecs, as such content is inherently more suitable for rule-driven autoregressive modeling than perceptual generation.
But these limitations do not diminish the significance of this work.
For the past thirty years, technological progress in image compression has almost exclusively occurred on the track of 'making the numbers look better.' From JPEG to HEVC to VVC, engineers optimized metrics like PSNR and SSIM generation after generation. Human visual perception remained a 'difficult problem' that was circumvented.
PICO is the first time someone has systematically and directly tackled this difficult problem: from architecture search and loss function design to large-scale human subjective evaluation, culminating in a codec that can run in real-time on a mobile phone.
The next time you share a photo from an Apple device, you might not notice anything different. But perhaps within that quiet compression process, an algorithm tailored for human perception is deciding which information is worth keeping and which can be quietly forgotten.
The Team: From WaveOne to Apple
The corresponding author of this paper is Oren Rippel, an Apple researcher and a familiar face in the compression field.
His name first gained widespread attention in 2017. At that time, he was at the startup WaveOne, publishing a paper titled 'Real-Time Adaptive Image Compression,' using neural networks to outperform all mainstream codecs while maintaining real-time speeds. That paper caused significant waves in academia and established Rippel's standing in the field of learned compression.

Afterwards, the same core personnel continued their work at WaveOne, introducing ELF-VC for video compression, achieving a 44% bitrate saving compared to H.264 on the UVG video test set while running over five times faster than similar ML codecs.
This team from WaveOne later joined Apple as a group. And this PICO is their first systematic answer on perceptual image compression, backed by Apple's computing power and platform resources.
This article is from the WeChat public account "Almost Human" (ID: almosthuman2014), author: Compression is Intelligence








