文 | AIDeepDive
今天,"全球大模型第一股"智谱(02513.HK)再次暴涨。
盘中涨幅一度突破30%。收盘报1282港元,全天涨幅超过26%,市值达到5715.7亿港元,再度创下历史新高。
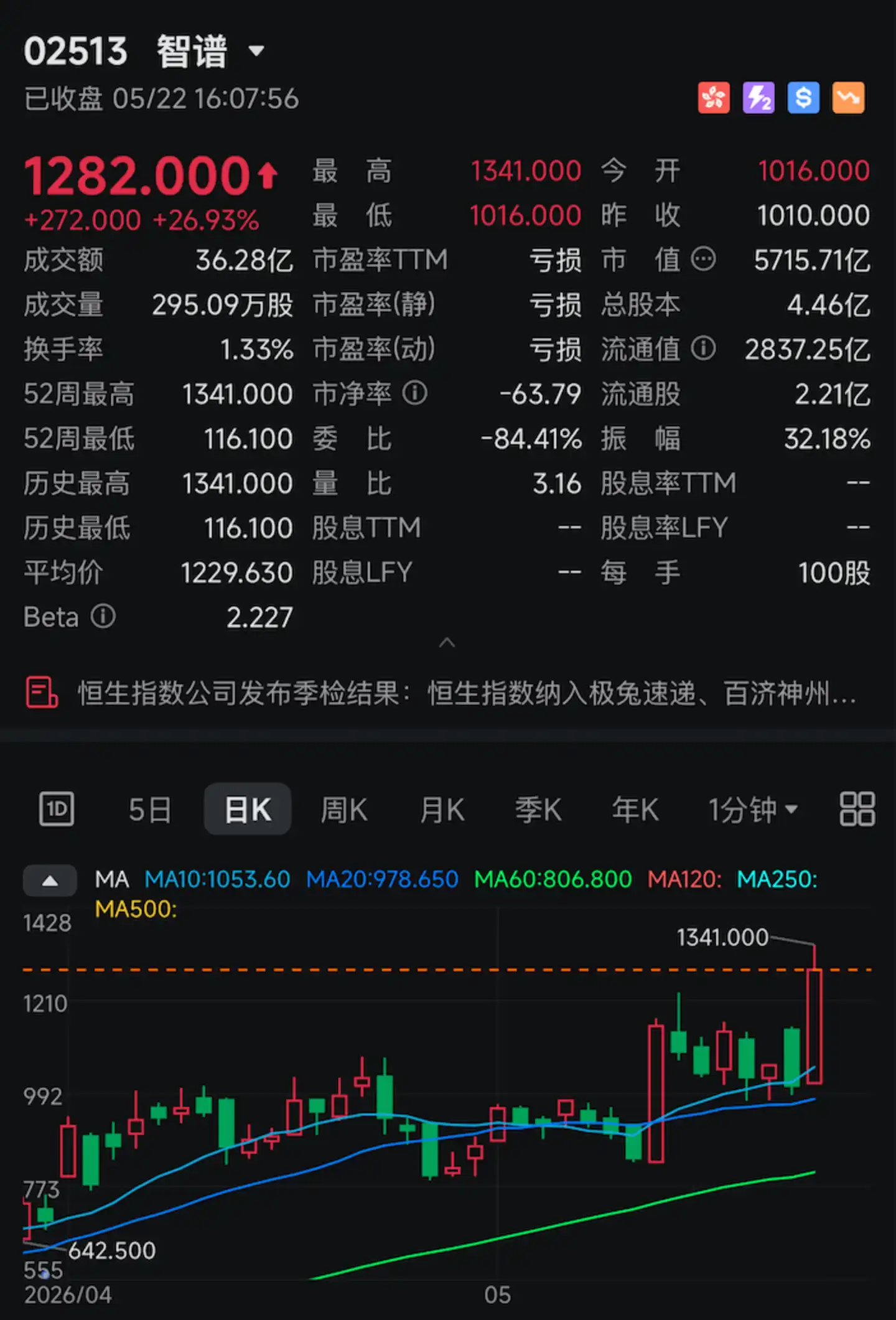
触发这场暴涨的,是一个具体的技术指标:400 tokens/s。
5月22日,智谱正式面向企业客户开放 GLM-5.1 高速版 API(GLM-5.1-highspeed),最关键的核心参数只有一个:模型输出速度达到每秒400个 token,刷新全球大模型厂商 API 速度上限。
我本来认为这又是一次国产大模型的公关包装,但仔细看了下技术细节,终于理解了资本市场背后的逻辑。
400 tokens/s是什么概念?
模型每秒能生成大约200个汉字,相当于一个专业作家一分钟的高强度产出,被压缩到了一秒钟之内。
一位创作者连续伏案数天才能写完的文字量,GLM-5.1 高速版在1分钟内便能交付完毕;一名工程师埋头3天才能完成的系统重构任务,它能在喝一杯咖啡的时间里跑完。
01 速度,比你想的重要
速度,历来是 AI 模型竞争中最容易被忽视的维度。
过去三年,大模型军备竞赛集中在两条赛道:参数规模(模型更大更聪明)和价格战(Token 更便宜更普惠)。"快",从来不是主角。
这是因为,过去的”快”通常是通过缩小模型参数来实现的。要提速,就必须用更小更精简的模型,代价是能力缩水。
GLM-5.1 高速版这次的意义在于,它在保留旗舰级全尺寸基座能力的同时,将速度推上了400 tokens/s。
无论是从国产模型来说,还是从国际范围来看,"旗舰能力"与"极致低延迟"第一次做到了不妥协。

为什么速度如此关键? 因为 AI 的主战场正在发生根本性的迁移。
当AI从ChatBot进入Agent时代,问答已经不是AI的主要场景,而Agent要完成一个任务,往往需要模型进行数十轮甚至上百轮的自我调用:写代码、调接口、搜信息、调用工具……
在这种工作模式下,每一轮调用之间的延迟会被无情地累加放大。一个需要50轮调用的任务,如果每次节省1秒,整个任务就快了将近1分钟。对于 AI 编程助手、语音交互、商业决策系统来说,这种差距是可以决定生死的。
从更深层面来说,在固定时间预算内,更快的推理意味着模型可以完成更深的推理路径、更多轮次的自我验证。速度,正在从系统指标变成智能上限本身。
02 速度这件事,有多难?
那现在行业里在速度方面大概什么水平?
头部厂商中,OpenAI 的 GPT-4o 约在100–150 tokens/s,Anthropic 的 Claude Sonnet 系列约在80–120 tokens/s,国内主流旗舰模型 API 大多在50–100 tokens/s 区间。400 tokens/s 大约是行业平均水平的3到5倍。
更关键的是,这个差距并不是投入更多算力就能弥补的。
一台搭载8块 H200 显卡的服务器,理论上每秒能搬运高达38TB的数据。对于 GLM-5.1,单次生成一个 token 只需读取约42GB的激活参数,纯理论上推算,应该能接近1000 tokens/s。
但现实系统往往只能跑出几十 tokens/s。
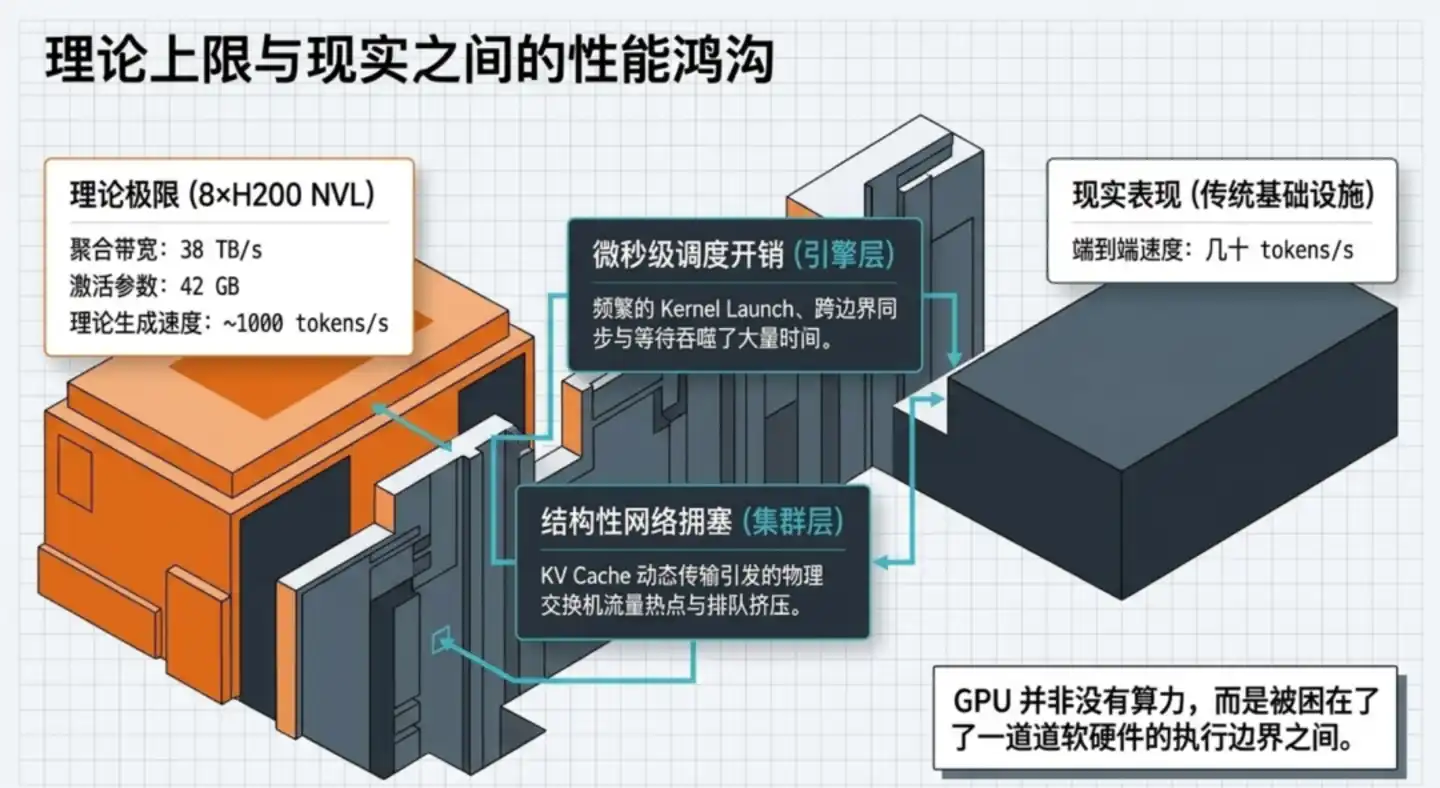
这是一个数量级的鸿沟。GPU 不是不够快,而是大量时间都被浪费在了等待、空转和无效调度上。
智谱这次正是在推理引擎、并行策略、网络架构三个层面同时创新,实现了对最终速度的突破。
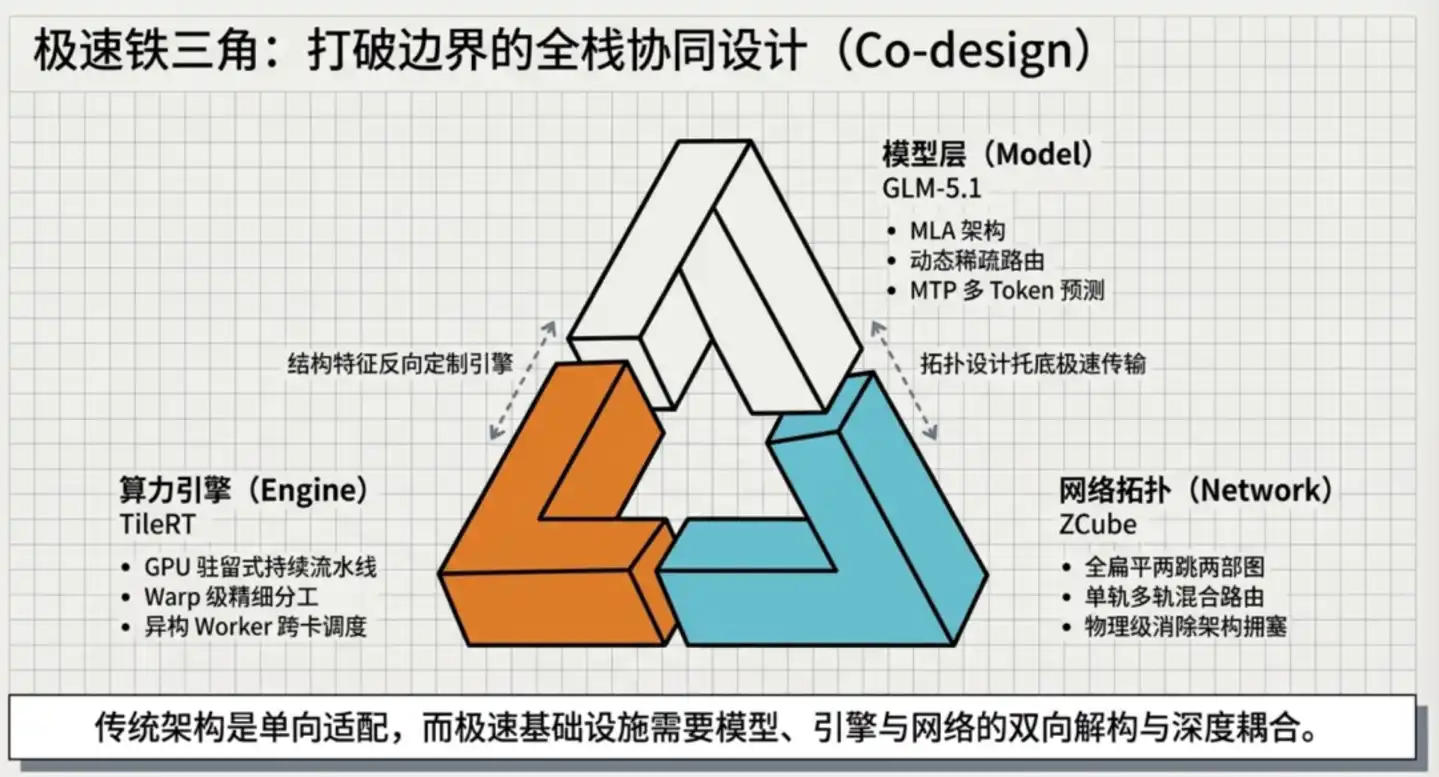
03 三层技术叠加,逼近硬件物理极限
大模型原来是这样运转的,大模型被分解成一个个独立算子,每个算子单独启动一次计算核心(kernel),计算完就停下,同步等待,再启动下一个。
在训练阶段,每次计算动辄几秒乃至几分钟,这些启动和等待的开销完全可以忽略。但推理时,单次生成一个 token,某个关键步骤可能只需要几十微秒,启动和等待的开销就相对变得不可忽视。
TileRT 的核心思路:把整个模型编译成一个持续运行的引擎,一次启动,永不停歇。
TileRT 在代码编译阶段提前把模型所有计算逻辑静态展开成一条连续流水线,运行时 GPU 始终保持高速运转,计算、数据搬运、通信并行推进,中间结果尽量留在 GPU 内部高速缓存里,不再反复写回慢速显存再重新读取。
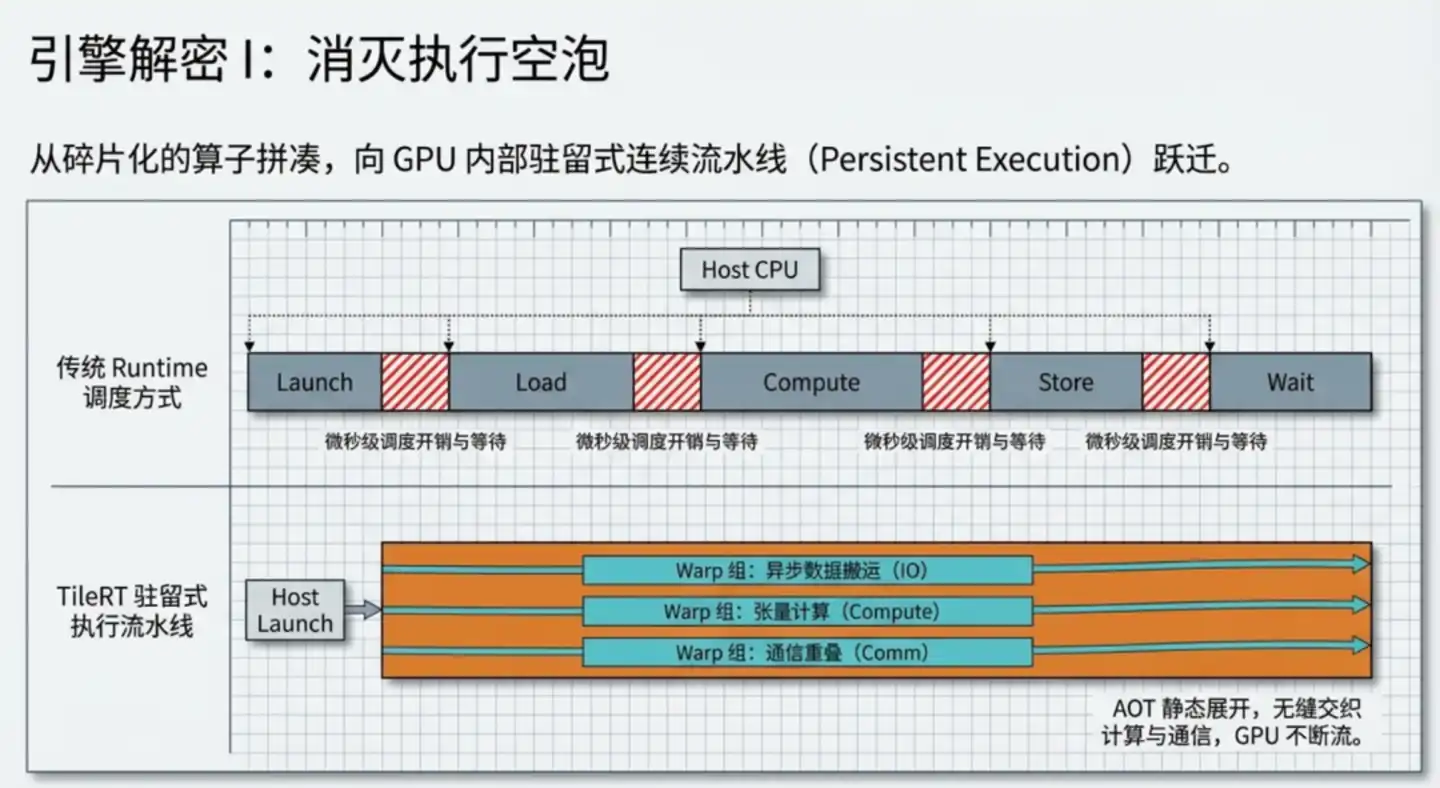
这里有一个关键的设计细节:Warp 专门化。
理解 Warp,需要先理解 GPU 的工作方式。GPU 与 CPU 最大的不同,是它内部有成千上万个相对简单的计算单元,这些单元以32个为一组捆绑在一起,这一组就叫 Warp。
同一个 Warp 里的32个单元必须始终同步行动、执行同一条指令,就像军队里的一个班,班长下令所有人同时做同一个动作。
传统框架里,所有 Warp 执行同一套指令序列;TileRT 让不同 Warp 组承担不同职责:一部分专门负责把下一批数据提前搬运进来,一部分专门负责数学计算,一部分专门负责与其他 GPU 通信。三组人同时工作、流水配合,互不等待。
就好比从"一个工人搬砖、砌墙、验收串行干",变成了"搬砖组、砌墙组、验收组同时转"。
单卡内部的效率解决了,多卡并行又有新挑战。
行业通行做法是张量并行(Tensor Parallel): 把模型的权重矩阵切分成若干份,每块 GPU 负责其中一份,各自计算完毕后通过高速互联(NVLink)汇总结果。
这套方案对矩阵乘法这类规整的密集计算效果很好,是目前几乎所有大模型推理框架的标准多卡方案。
GLM-5.1 采用 **MLA(Multi-head Latent Attention,多头潜在注意力),这是由DeepSeek 提出一种注意力机制。
传统注意力机制需要把每一步计算的大量中间数据(KV Cache)完整保存下来备用,非常耗显存;MLA 的做法是先把这些中间数据压缩成一个紧凑的"潜在向量"存起来,用的时候再展开还原,显存需求大幅下降,推理效率更高。
但 MLA 的计算流程里有一个特殊环节:需要从大量历史信息中做稀疏索引:类似在一个巨大图书馆里先快速找出最相关的几本书,再精读这几本书。
"找书"这个步骤依赖全局信息,不适合多卡平摊;"精读"才是适合多卡并行的密集计算。如果强行让所有8块 GPU 都参与"找书",大量时间会浪费在 GPU 之间的同步通信上。
TileRT 的解法是让GPU异构运行:GPU 0 专门担任"图书馆检索员",负责稀疏索引和路由决策;GPU 1–7 担任"精读分析员",负责密集的注意力计算和矩阵运算。两类工作者各自采用最适合自己的并行策略协同完成整个计算层。
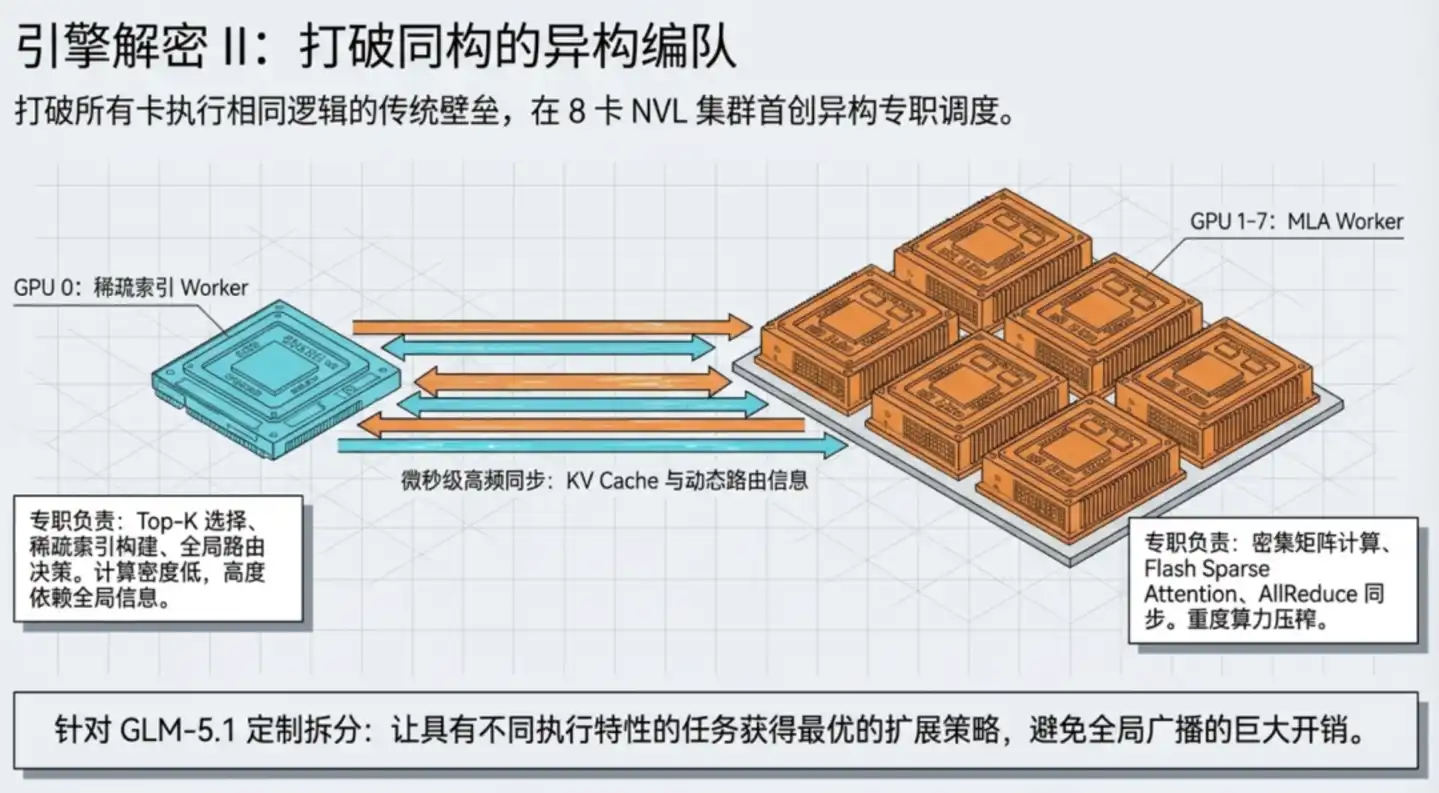
接下来,TileRT 把 GPU 之间的通信操作也直接内嵌进执行流水线,不再作为独立步骤。对外来看,整个8卡系统完成一层注意力计算只需要一次内核启动,内部的通信和计算全在持续流水线内部无缝完成。
以上两层解决的是单机范围内的问题。当集群扩展到数百乃至数千张 GPU,GPU 之间的数据传输本身就成了新的天花板。
行业通行做法是 ROFT(Rail-Optimized Fat-Tree),这是 NVIDIA 官方推荐方案,业界绝对标配。
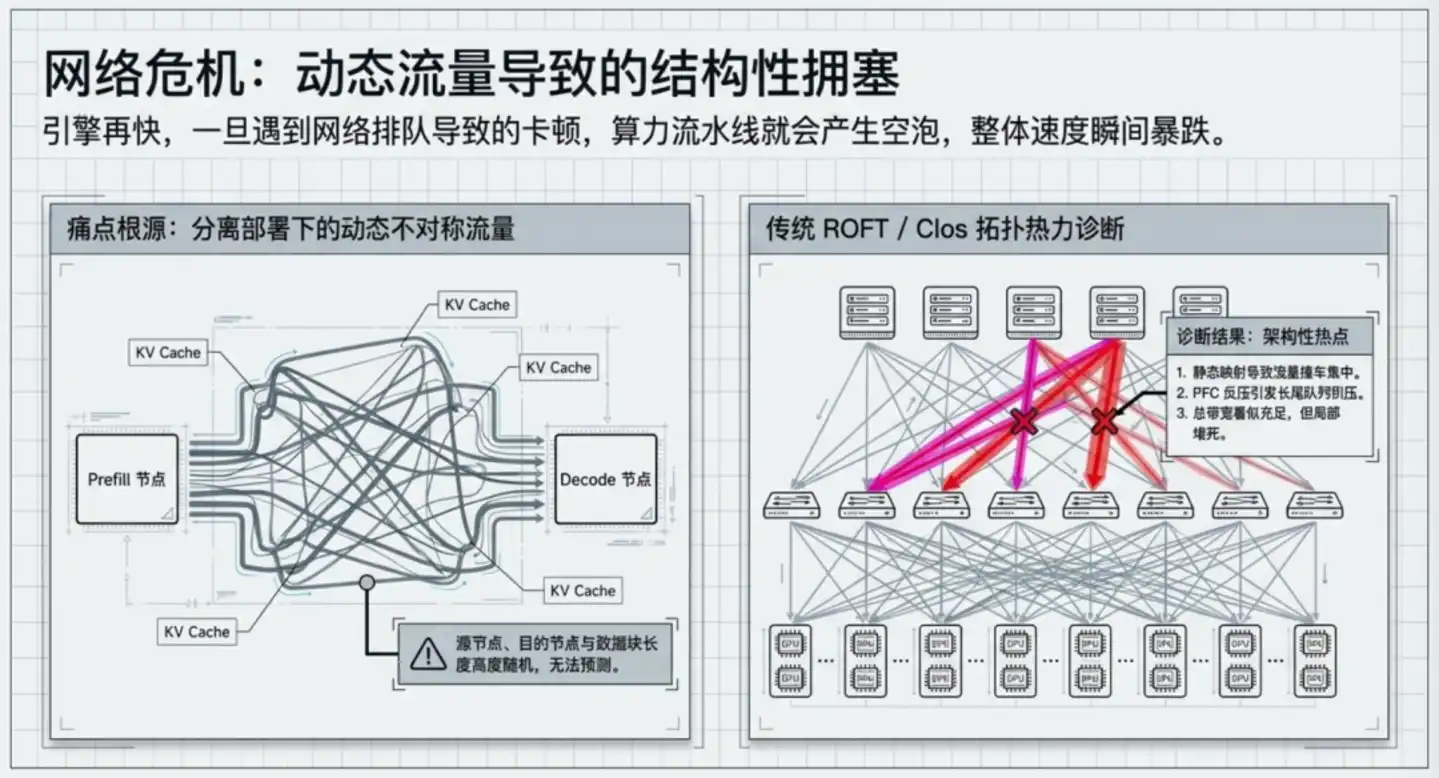
它的结构是一棵树:服务器先连接底层的 Leaf 交换机(接入层,直接面向服务器),Leaf 再向上连接 Spine 交换机(骨干层,负责不同 Leaf 之间的互联,如同高速公路枢纽)。数据在两台 GPU 之间传输,必须"先上行到 Spine,再下行到目标 Leaf",至少经过3跳。
为了避免流量集中在少数链路上,这套架构依赖 ECMP 算法让数据在多条路径之间分配,在互联网流量"统计均匀"的前提下运转良好。
但推理场景的流量完全不均匀。不同请求的上下文长度差异可达数十倍,GPU 之间 KV Cache 的传输方向几乎随机,某几台 Leaf 交换机会周期性地成为热点,触发反压机制,把拥塞从局部扩散到全链路。这种拥塞不是协议调参能解决的,是拓扑结构本身的产物。
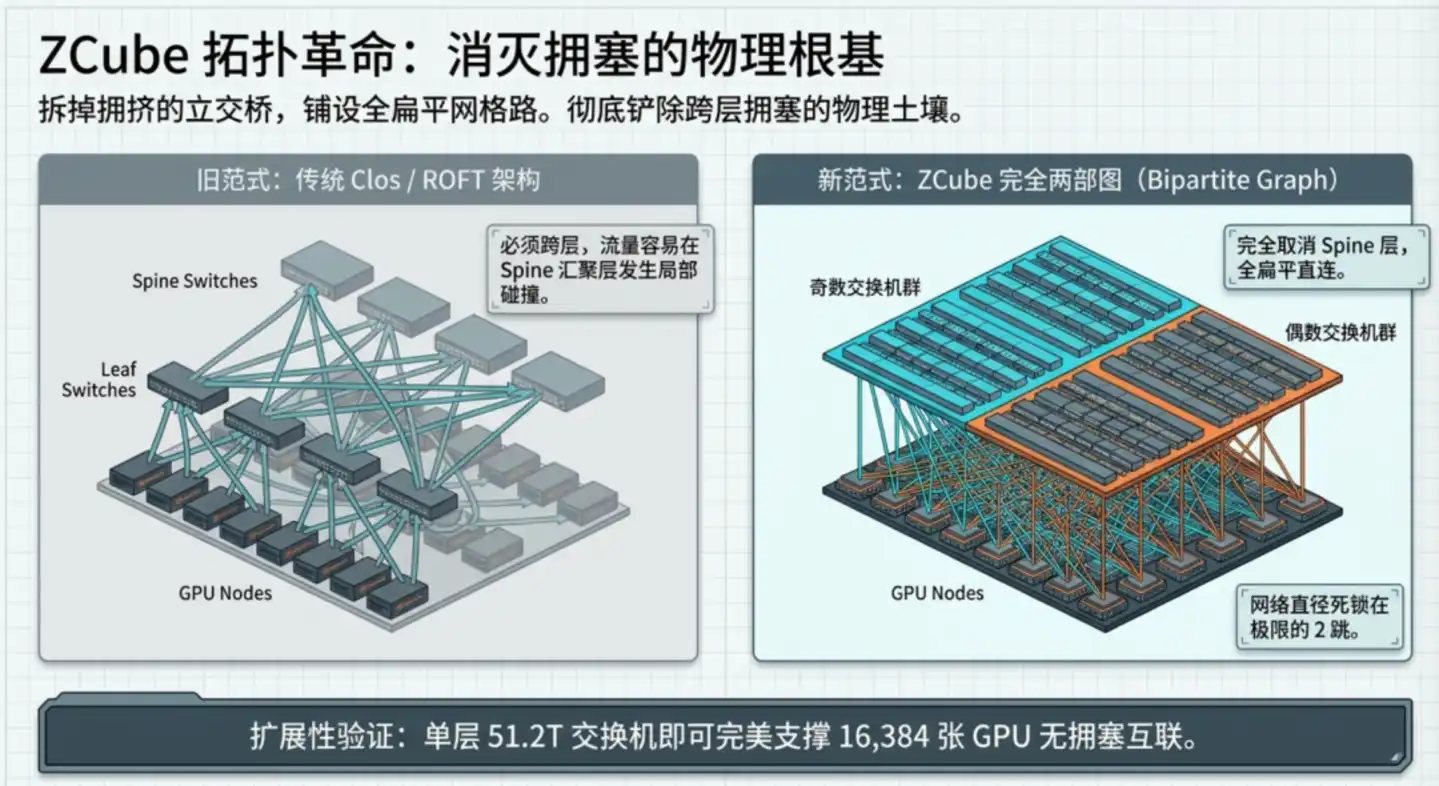
ZCube 的根本突破:从架构层面让这类拥塞在物理上无法发生。
核心设计分两步:
第一步,取消 Spine 骨干层,全网扁平化。把所有 Leaf 交换机按奇偶编号分成两组,两组之间完全互联,任意一台奇数交换机连接所有偶数交换机,反之亦然。任意两台 GPU 之间最多经过两台交换机即可互达,跳数从3跳降到2跳。
第二步,也是最精妙的地方:每张 GPU 网卡用两种截然不同的方式分别接入两组交换机。这种特殊拓扑带来一个关键的数学性质:全网任意两张 GPU 之间,有且仅有一条最优路径。
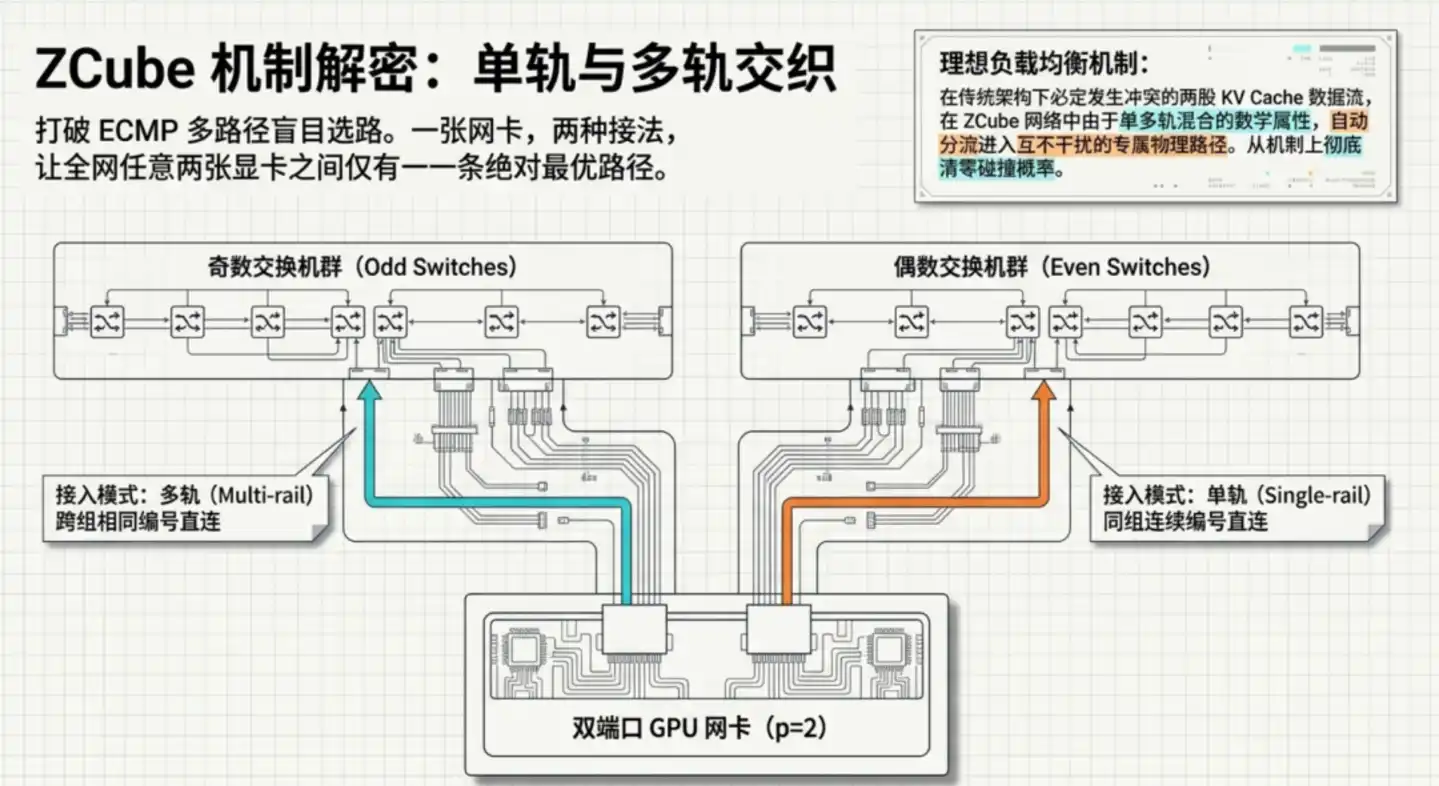
"唯一路径"直接消除了拥塞的根源。传统架构容易出现热点,恰恰是因为有多条路径可选,负载均衡算法选错了就会导致流量集中。ZCube 在设计上消除了"选择"这件事本身:不需要均衡,因为根本没有岔路。
04 同样的硬件条件下,账怎么算?
智谱将 GLM-5.1 生产集群从传统 ROFT 升级到 ZCube 后,得到三个数字:
总结来说的话,同样的 GPU 投入,集群可以服务更多用户;同样的用户体验要求,集群可以少买三分之一的网络设备。效率与成本双向改善。
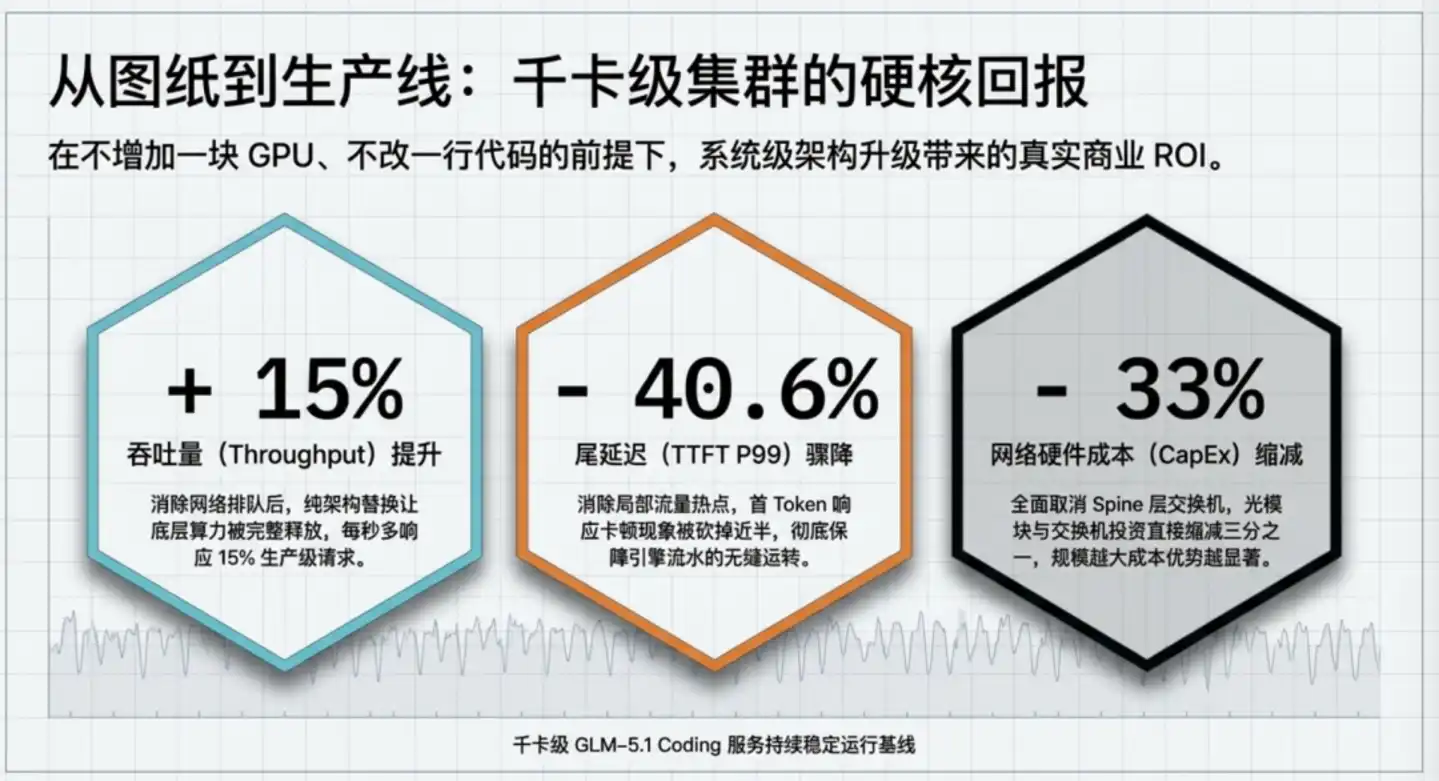
具体来说,吞吐提升15%,等于免费多出15%的算力。 在GPU数量不变的情况下,吞吐多15%,等价于每个 token 的均摊硬件成本下降约13%,或者说相同成本可以多服务15%的用户。
如果一个集群有1000张 GPU,这次升级相当于凭空多出了150张卡的产能,按当前高端推理卡市价,这是数亿元量级的算力价值。
尾延迟下降40.6%,解决的是稳定性而非平均速度。 一个需要50轮调用的 Agent 任务,如果尾延迟每次减少1秒,整个任务的最坏完成时间就压缩了将近1分钟。
成本减少三分之一,是建设层面的直接节省。 ZCube 取消了 Spine 层,相同集群规模下所需交换机和光模块数量直接减少三分之一。据智谱测算,在万卡规模集群中,仅此一项可节省约2.1亿至6.4亿元。
从长远来看,随着集群规模指数级加剧,GPU 间通信的复杂度增长数倍,拥塞的概率和影响也同步放大。这意味着 ZCube 这类架构级创新的价值,会随着推理集群的持续扩张而加速显现。明天万卡级别的集群收益可能不止今天这15%。
05 写在最后
看完智谱的技术报告,我在想,这是否会像DeepSeek横空出世一样,给行业带来一场风暴?
仔细想想,两者的影响好像在不同的方面。DeepSeek 出来的时候,它证明的是,同样的智能,可以用少得多的算力实现。市场担心"需要的 GPU 变少了",所以英伟达当天市值蒸发近6000亿美元。
但今天智谱的技术证明:同样的算力,可以产出更多。它是在重构"GPU 之外,其他基础设施应该长什么样"。
短期来看,英伟达不会受到影响,但从长期来看,GPU + NVLink 互联 + InfiniBand 网络 + CUDA 软件生态的护城河正在被“松土”,特别是英伟达 2019 年花 69 亿美元收购 Mellanox 买下的 InfiniBand,英伟达网络侧的溢价会被大幅侵蚀。
此外,ZCube 取消了 Spine 层,但它对 Leaf 交换机的端口密度要求反而更高。受益的是能做高密度、大端口 Leaf 交换机的厂商(锐捷、Arista、博通交换芯片),受损的是主要依赖 Spine 层高端交换机吃溢价的厂商。
2025年 Celestica 和英伟达合计占据约 50% 的 AI 后端网络交换机市场份额,这个格局在 ZCube 范式扩散后会面临重新洗牌。
光模块是这次产业链变化里最直接的受益方向,逻辑非常清晰。对国内光模块厂商(中际旭创、天孚通信等)来说,这是一个结构性利好:不仅总量在涨,而且 ZCube 范式下对高速光模块(800G、1.6T)的需求比传统架构更加集中和迫切。
无论是TileRT还是ZCube 架构,这是一套运行在标准 GPU 之上的纯软件推理引擎,不依赖英伟达私有的硬件特性,理论上可以移植到华为昇腾等国产芯片上。这个方向一旦走通,会大幅降低国产 AI 芯片在推理场景的软件栈门槛。
这或许才是这个技术创新背后更大的意义所在。







