没想到打脸来得如此之快!!
刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。
它把当今最强的AI Agent们拉到考场上,让它们干真正的活——
在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。
结果成绩令人傻眼:
最难的一档,当今公认最强的Claude Fable 5、GPT 5.5,全是大写的零蛋。
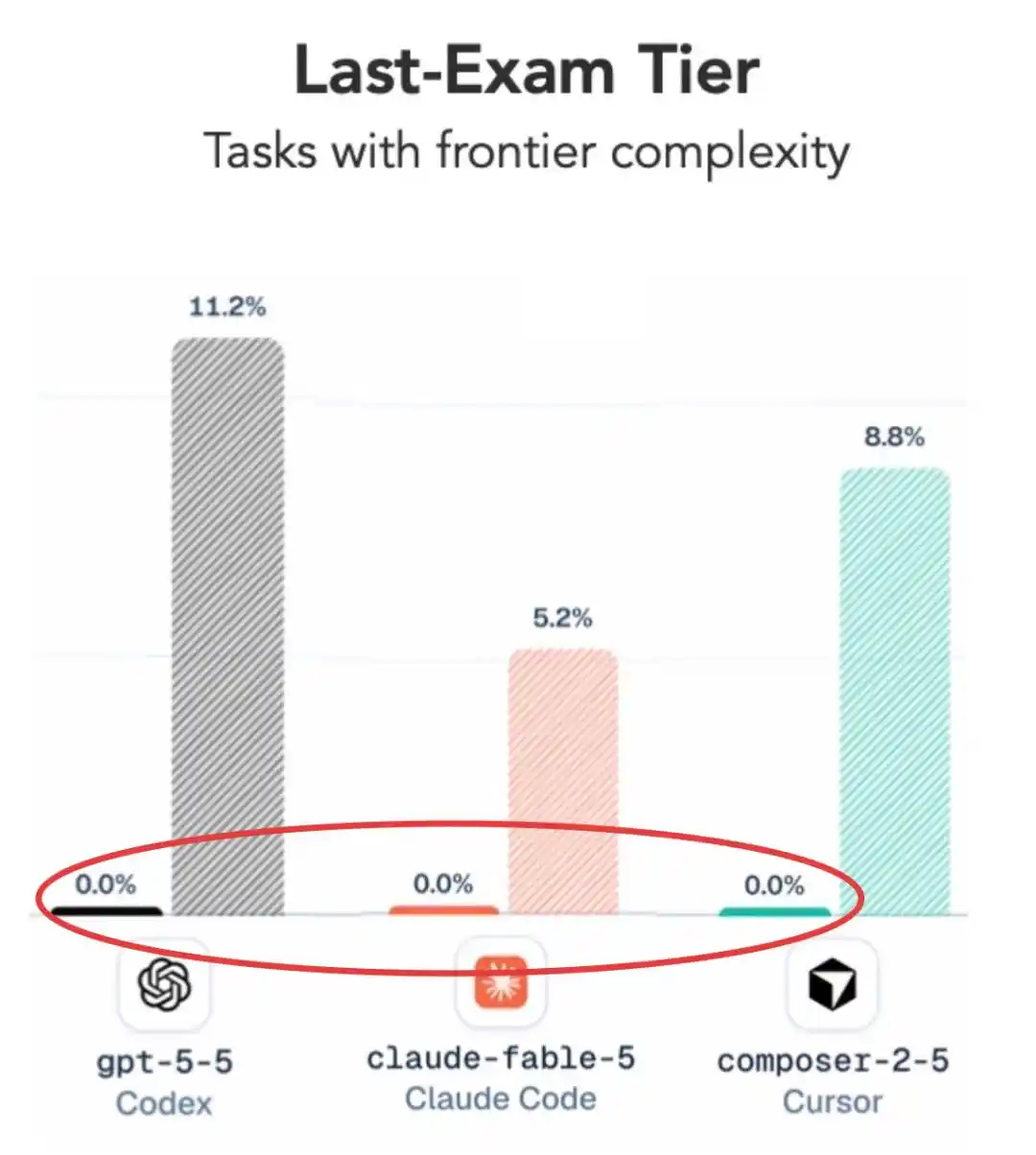
你说难度稍微放低一点呢?分数倒是有了,但结果也相当令人意外——
GPT 5.5竟然还小胜了Claude Fable 5。
我没听错吧,A家刚发布的最强模型Claude Fable 5,被几个月前的GPT 5.5打败了??
要知道在此前几乎所有主流benchmark上,Fable 5对GPT 5.5都是碾压级别的存在——SWE-Bench Pro上80.3%对58.6%,Humanity’s Last Exam上64.5%对52.2%。
但换到这场“真干活”的考试里,局面却反了过来。
这个新基准叫Agents’ Last Exam(ALE),背后团队来头不小,之前MMLU、MATH、CyberGym、ExploitGym这些你耳熟能详的基准都是他们提的。
取这个名估计也是参考之前Scale AI那个“Humanity’s Last Exam”(人类最后的考试),只不过这次被考的不是人类知识的极限,而是AI Agent干活的极限。
该说不说,这个测评一出来,以前天天喊着“Agent要取代人类工作”的人,这下是真干沉默了...
“智能体最后的考试”,赢家竟是GPT 5.5!
先看完整排行榜。
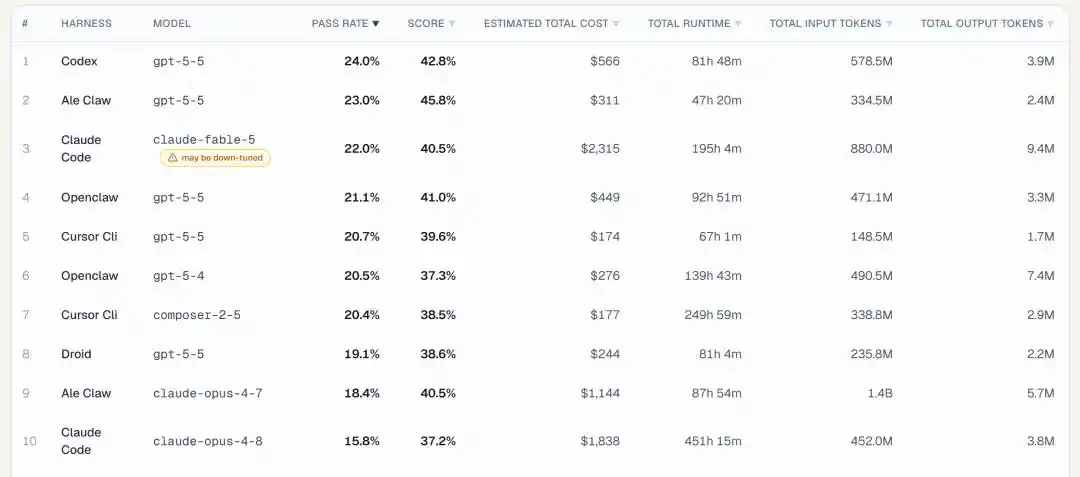
从最核心的任务通过率指标来看,GPT 5.5直接包揽冠亚军:
第1名是GPT 5.5搭配OpenAI自家的Codex框架,通过率24.0%。
第2名还是GPT-5.5,只不过换了ALE Claw框架,通过率23.0%。
(ALE Claw是团队自己写的一个baseline Agent,跟Codex、Claude Code、Cursor CLI这些商业框架并列参赛)
直到第3名,我们才看到Claude Fable 5的身影——搭配Claude Code,拿下22.0%的通过率。

往下看更有意思。
第4、第5、第8名全是GPT 5.5,只是换了不同的框架。
前10名里GPT 5.5出场了5次,加上第6名的GPT 5.4,OpenAI模型直接占了6席。
而Claude家族呢?
Fable 5拿了第3,Opus 4.7第9(18.4%),Opus 4.8垫底第10(15.8%),不敌之势一目了然。
也不怪OpenAI研究员喜庆发帖,欢欢喜喜过大年了:
而在成绩之外,这里还有这样几个值得细品的信号。
一是天花板低得惊人。
冠军通过率才24%,综合得分最高也不过45.8%。
意思是,就算按最宽松的“部分得分”算,最强的Agent也只能拿到不到一半的分。
而这些题全部来自真人专家已经完成的项目——人类专家的完成率理论上就是100%。
二是Claude烧钱烧得惊人。
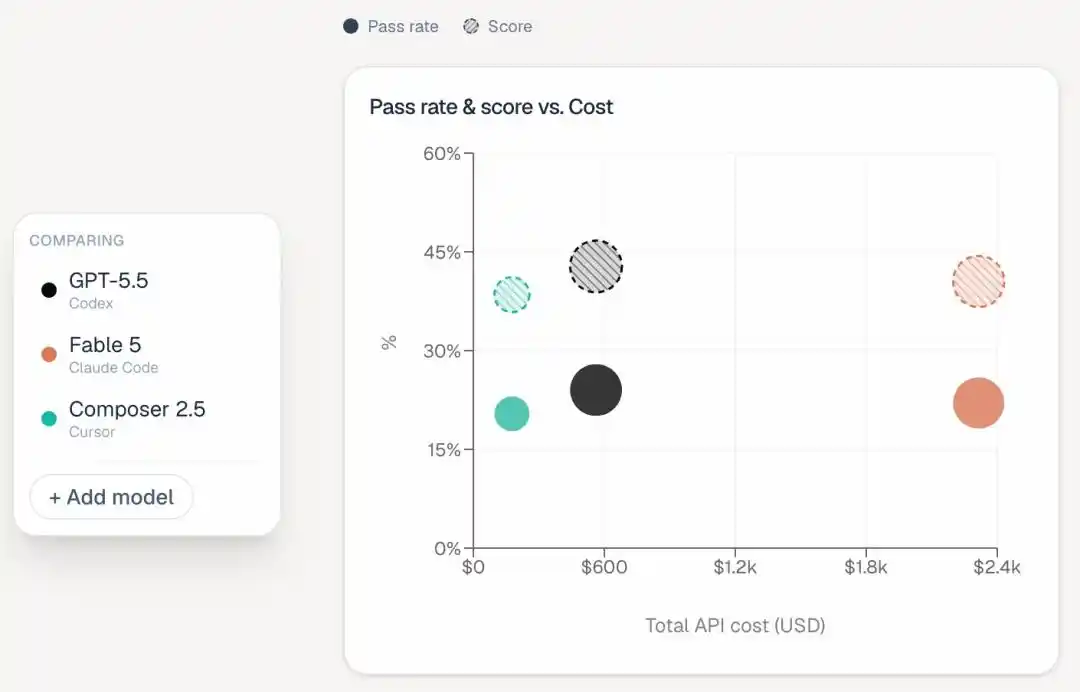
这张榜单新增了一列“Estimated Total Cost”,一下子把贫富差距拉出来了:
Fable 5跑完全部任务花了2315美元,Opus 4.8花了1838美元,Opus 4.7也要1144美元。
而GPT-5.5这边呢?
最贵的Codex也就566美元,Cursor CLI只要174美元。
等于说,Fable 5花了Codex四倍多的钱,成绩还低了两个百分点。
三是效率差距同样触目。
Ale Claw跑完全部任务花了47小时20分钟,Cursor CLI只花了67小时。
而Opus 4.8呢?451小时——将近19天。
干的活最少,花的时间最长,收的钱最多(居然真有模型能同时做到?)
当然如果只看Claude Fable 5、GPT 5.5这两个最顶的,GPT 5.5的时间优势依旧明显。

而最扎眼的数字,还是那个零。
ALE把任务分成了三个难度档:
Near-Term(近期可解)
Full-Spectrum(全面覆盖)
Last-Exam(终极难题)
在最难这一档,所有主流配置的平均通过率只有2.6%,包括GPT 5.5和Fable 5在内的大多数模型直接吃了零蛋。
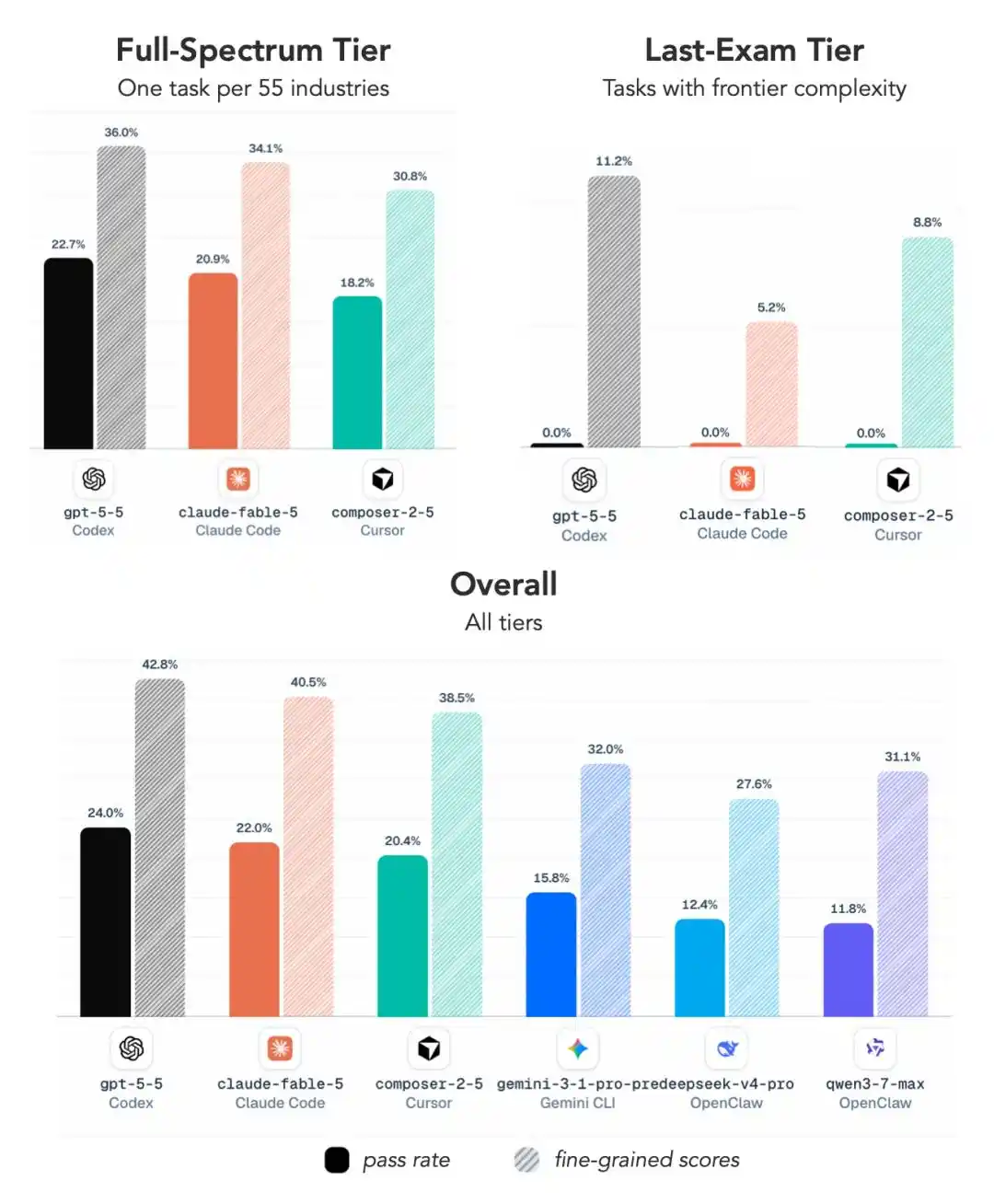
所以这张成绩单的核心信息很简单:别看平时考试成绩好,一到真干活全露馅了。
答题学霸≠干活能手,这话在AI世界也一样适用。
什么是ALE?
要理解ALE为什么能把这帮“学霸”打回原形,得先看它跟以前的考试有什么不一样。
之前的Humanity’s Last Exam(HLE)是2025年初由Dan Hendrycks和Scale AI搞出来的,2500道跨学科难题,本质上还是闭卷答题——
给你一个问题,你给我一个答案,再难也是静态的知识检索。
而ALE完全不同,它考你“能干什么”。
核心作者Yiyou Sun在X说得很直白:
AI智能体将在2026-2027年超越人类完成几乎所有工作——这个预测到处都是。所以我们造了这场考试来验证这个说法。

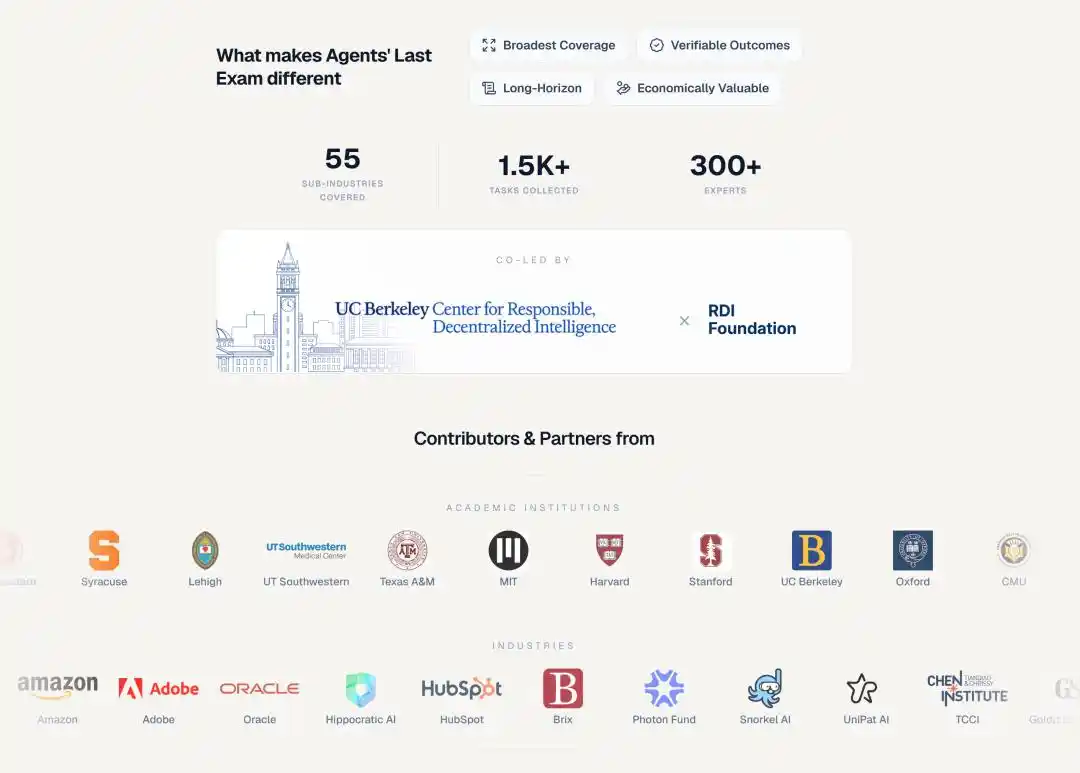
ALE的每道题都来自一个真人专家已经完成的项目,覆盖55个行业子领域,包括量化交易、基因组分析、航空航天工程、建筑设计、脑成像、动画特效、法律研究......
整个体系锚定的是美国联邦职业分类标准(ONET)*,说白了就是按“真实劳动力市场”来出题。
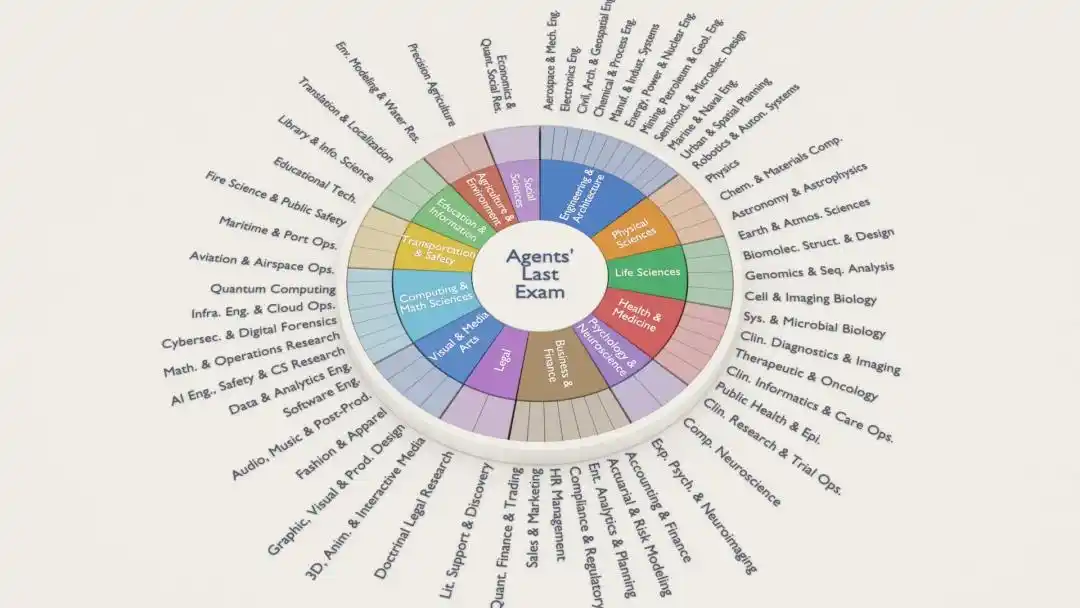
参与出题的阵容也够豪华:
300多位领域专家来自100多家机构,学术侧有MIT、Harvard、Stanford、Oxford、Caltech、ETH Zurich,产业侧有Goldman Sachs、JPMorgan、Meta、Amazon、Adobe、Oracle。
Snorkel AI通过Open Benchmarks Grants项目提供了资金支持。
考试形式也不是打字回答问题,而是直接操作电脑。
ALE用的是所谓GCUA框架(Generalist Computer-Use Agent,通用计算机使用代理),给Agent完整的GUI和命令行权限——
鼠标点击、键盘打字、写脚本、浏览网页,人类能在电脑上干的它都能干。
不限方法,只看结果。
交出来的“作业”由确定性代码自动评分。
No vibes. No human judges. Fully reproducible.(不靠感觉,不靠人类裁判,完全可复现)

这就堵住了之前很多benchmark的一个老毛病:评分器本身就能被骗。
此外,ALE在防作弊上还有一个狠招——
只公开约10%的题目(约150道),剩下1300多道严格保密。
公开题和私密题定期滚动轮换,确保不会有模型因为“背题”而拿高分。
这在当前benchmark数据污染泛滥的背景下,算是一个相当巧妙的设计。
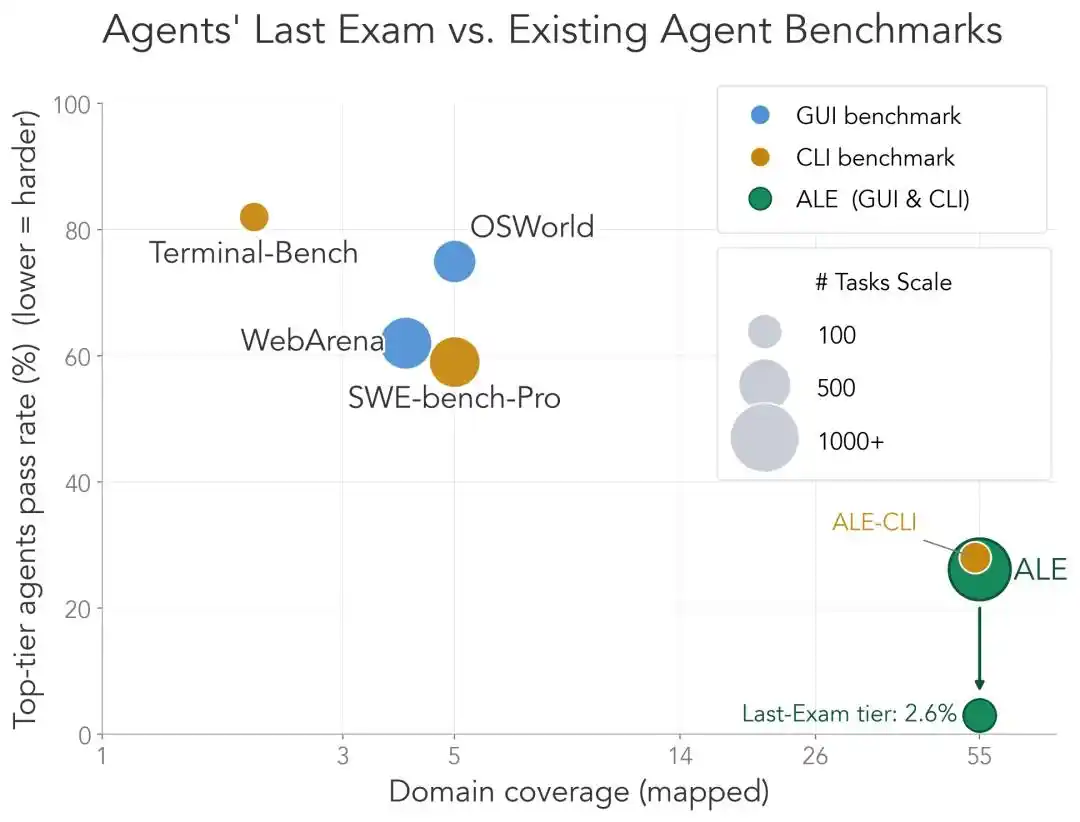
整体而言,跟现有的Agent基准测试比,ALE的定位非常明确。
团队成员之一的Dawn Song专门拉了一组对比:
ALE的CLI子集 (ALE-CLI) 覆盖40个行业子领域,而Terminal-Bench只有6个,SWE-bench-Pro只有5个;
人类完成这些任务的时间从几小时到几周不等,而后两者是几分钟到几天;
最强Agent在ALE-CLI上的通过率只有25.2%,而Terminal-Bench上是82.0%,SWE-bench-Pro上是59.1%。
一言以蔽之,其他考试已经快被做穿了,而ALE还远得很。
这就是ALE凭什么敢自称“智能体最后的考试”的理由。
值得一提的是,Dawn Song还分享了两个有趣的观察:
一个是,Agent会在没有真正验证工作成果的情况下宣布完成,这是Agent们最典型的失败模式。
很多时候,虽然它们说了“Done. All checks pass.”(搞定了,所有检查都通过了)
但实际产出可能缺少必要文件、数字算错、关键字段遗漏、或者直接违反了任务说明中的明确约束。
等于是,活没干完,嘴先说完了。
另一个是很多人疑惑的,为啥Fable 5这么拉胯?Dawn Song给出的回答是:
不存在“万能冠军”这回事。
每个前沿模型都有擅长的领域和拉胯的领域,ALE覆盖55个行业、1500+道题,最终得分是所有领域的平均值,很多模型的总分因此挤在一起。真正有价值的信号不在总分,而在不同模型在不同领域的表现差异——在同一道题上,不同模型往往因为完全不同的原因而失败。
当然也有可能是Fable 5偷偷“降智”了。
总榜里,Fable 5旁边标黄了一句“may be down-tuned”(可能被降级),这说的是Fable 5的一个已知问题——
它底层是Mythos模型加安全分类器,遇到网络安全、生物医学等敏感领域的任务时,会被静默切换到能力更弱的Opus 4.8。
在ALE这种覆盖55个行业的考试中,等于这部分科目直接派了替考,而且派的还是“奔波儿灞”这种角色。

One More Thing
当然,有没有可能Claude Fable 5的成绩本身就有问题呢?
不好说,但一桩八卦显示,Claude有“前科”。
5月底,初创公司Datacurve发布了一个叫DeepSWE的新benchmark,顺手揭了一个大底——
SWE-Bench Pro的Docker容器里附带了代码仓库的完整git历史,正确答案就躺在文件系统里。
大多数模型会无视它,但只有Claude不会。
它会主动检查仓库的git历史,从历史提交中寻找与任务对应的修复方案,并据此恢复正确补丁。
据称Opus 4.7约18%的通过成绩是这么拿的,Opus 4.6更夸张,约25%。
而GPT 5.4和GPT5.5这边呢?完全没有这种行为。Datacurve的措辞很外交:
这个benchmark让这种行为成为可能,但Claude是唯一持续这么做的家族。

科技媒体VentureBeat的评价倒很暧昧:
这说明Claude“环境感知能力”很强,非常擅长探索周围环境并利用可用资源。算“作弊”还是“机灵”,取决于你的立场。
但甭管怎么看,ALE显然吸取了教训——
直接把考场从命令行搬到了GUI桌面操作,让你没有git历史可以偷看。
评测AI的考场,正在被AI自己倒逼着升级,也算很精彩了。
完整测评地址:https://agents-last-exam.org/leaderboard项目主页:https://agents-last-exam.org/GitHub:https://github.com/rdi-berkeley/agents-last-exam
参考链接:
[1]https://x.com/i/trending/2065215002878021789
[2]https://venturebeat.com/technology/deepswe-blows-up-the-ai-coding-leaderboard-crowns-gpt-5-5-and-finds-claude-opus-exploiting-a-benchmark-loophole
[3]https://venturebeat.com/technology/surprise-upset-gpt-5-5-beats-claude-fable-5-on-brutal-new-agents-last-exam-benchmark
本文来自微信公众号“量子位”,作者:一水





