两年的活,如今几周干完。
最近,Allen Institute的一位神经科学家Jérôme Lecoq和他的团队,把一篇长篇综述的写作时间,从将近2年压到了几周。
Jérôme Lecoq手头上积攒了约10篇综述,不少超过100页,每一条引用都被一个智能体逐句核对过。
帮他干活的,是Anthropic刚推出的新应用,Claude Science。

2026年6月30日,Anthropic发布Claude Science,定位为面向科学家的AI工作台。(图源:Anthropic官方博客)
据Anthropic介绍,这套活儿过去这位科学家和他的团队要干两年。
Anthropic给Claude Science的定位,并非一个更聪明的科研模型,而是一个面向科学家的AI工作台。
它真正的突破在于:第一次把科研这件事,拆成了一条能被逐步审计的流水线。
如今,Claude Science已在macOS和Linux上开启beta,对Pro、Max、Team、Enterprise用户开放。
真正改变的,是整条科研工具链
做过科研的人,都懂那种繁琐:
一个项目要在几十个数据库之间来回跳,每个库都有自己的schema和查询语言;
文件格式五花八门,每种都得现搭管线、现找查看器;
手边还摆着一排工具,PubMed查文献,Jupyter跑代码,R做统计,集群终端提交任务......
不停转场,真正用来思考科学问题的时间,经常被这些搬运、拼接、调试工作耗费殆尽。
而Claude Science干的事,正是将这些碎片场景打包「收纳」进同一个执行环境:
文献分析、多步计算、图表打磨、论文成稿,全部阶段在同一个环境里走完,你不必再为换一个工具而中断思路。
它能跑在你本地的macOS或Linux上,也能通过SSH连到远程机器,或者挂在高性能计算(HPC)的登录节点上。
就像你平时用Jupyter那样,数据在哪,它就去哪。
就连算力调度这块,它也包了。
折叠一个蛋白质,或者在海量数据上跑一条基因组管线,这种大活过去要研究者亲自伺候,搭计算任务、排队等集群、盯着成功还是失败、再把结果拉回来,一来一回半天就没了。
Claude Science把这套流程接管了:先起草计划,碰新资源前先问你一声,写任务、提交任务之前都让你能审查或撤销,把分析从1个GPU一路扩到数百个。
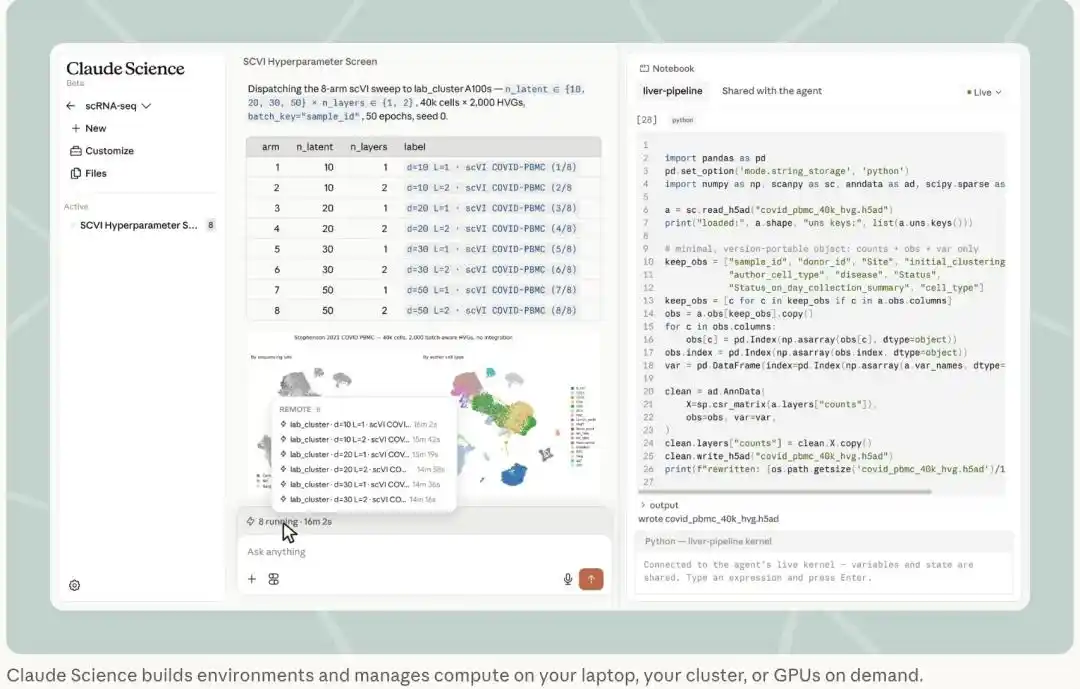
Claude Science把一次8组scVI超参扫描派到实验室A100集群运行,右侧Notebook与智能体共用同一个实时内核,变量和状态实时同步。(图源:Anthropic官方博客)
更重要的一点,敏感数据不离开原系统,只有每一步真正需要的上下文才会发给Claude。
每一张图,都自带可追溯代码
科研这行天生就跟图打交道,蛋白质三维结构、基因组浏览器轨道、化学结构式,这些本就是图。
Claude Science顺着这一点,在出图、出稿的同时,把生成它们的代码一并交出来,还能把它们原生渲染出来。
更关键的在可复现性(reproducibility)。
每当Claude Science生成一张图,它都会把生成这张图的确切代码、运行环境、纯语言说明和完整对话历史,一并打包「钉」在图上。
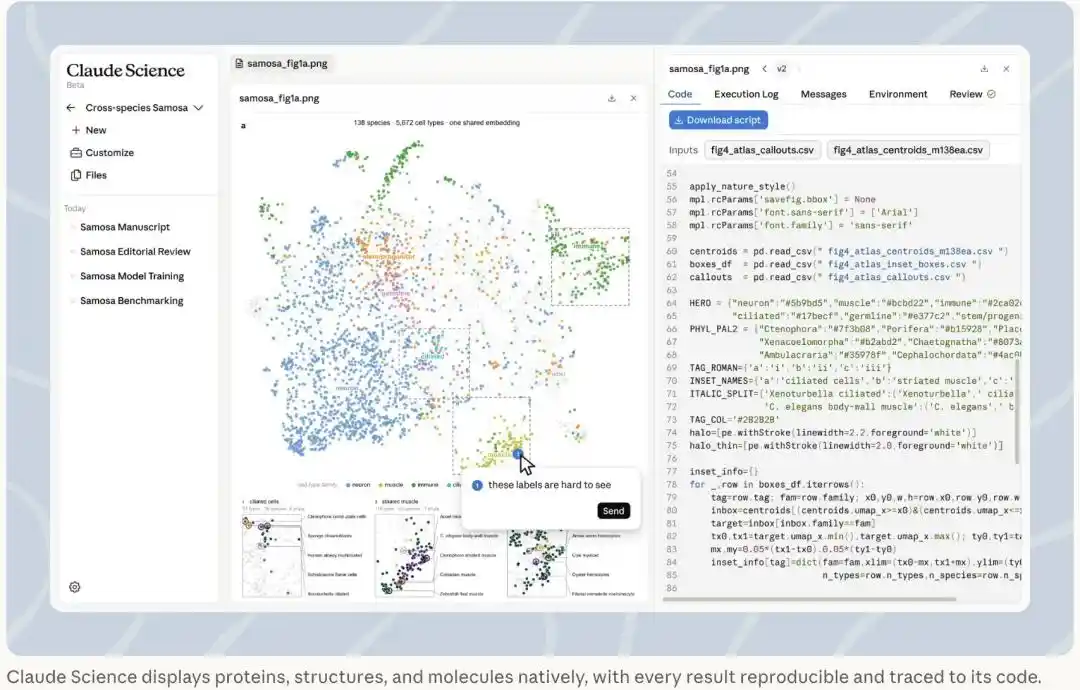
左侧一张跨138个物种的细胞图,右侧同屏挂着生成它的确切代码,圈注一句就能让智能体改图。每个结果都可复现、可追溯到代码。(图源:Anthropic官方博客)
一篇论文从投稿到见刊,常常隔着大半年;几个月后,等审稿人要你重跑某张图,你可以很轻松地把输入、过程、结果整条链当场复现出来。
想改图?直接说话就行——「把网格线去掉」「纵轴换成对数」,智能体直接去改自己写的代码。
你还能在任意节点把会话fork出去,同时试两条思路,原来那条线程一点不乱。
一句话,科研第一次被整合成一份可审计(auditable)的工作流,code、env、history都被放进一个闭环中。
一个智能体写,另一个专门挑错
Claude Science背后,并非一个智能体在单打独斗。
你面对的是一个会统筹的协调智能体,它手里握着60多个为基因组、单细胞、蛋白质组、结构生物学、化学信息学预配好的技能和连接器。
活一多,它自己就能派生出更多智能体来分工,也能随时调用你亲手创建的专家智能体。
最妙的是那个审查智能体(reviewer agent)。
它专门核查引用和计算,揪出错误的引用、追不到出处的数字、对不上代码的图,发现了就标出来、自己改掉。
在Allen Institute那个案例里,团队用的正是actor-critic配对,一个智能体负责写,另一个专门评它的准确性和引用真不真。
这套结构,已经有点「AI内部同行评审」的雏形了。
但有一条边界必须说清楚,全程是人在回路(human-in-the-loop)。
在需要动用新资源前,它会先征求授权,每个决策你都能复核、能撤销。它自动化的是流程,而并非自动替你做科学发现。
它还接了NVIDIA的BioNeMo Agent Toolkit,能原生连上Evo 2、Boltz-2、OpenFold3这些生命科学模型。
你实验室自己信得过的模型、数据、管线,也能存成可复用的技能挂进来,往后的会话自动继承。
Claude Science第一站是生命科学
Claude Science的第一个落点,选在了生命科学。
基因组、单细胞、蛋白质组、结构生物学、化学信息学,开箱即用。
它能读文献,能查询60+科学数据库,UniProt、PDB、Ensembl、ClinVar、ChEMBL、GEO这些规格不一的库,你不用再一个个去学着用。

Claude Science为基因组、单细胞、蛋白质组、化学信息学预配好环境,背靠60+科学数据库。(图源:Anthropic官方博客)
Manifold Bio做的是组织靶向药物。
他们用Claude Science来提名最新实验的靶点,对每个组织和靶点,逐一评估表面表达、运输和安全性,再按公司从自有数据里学到的标准给候选排序。
Manifold说,普通编程助手做不到这一点,Claude Science能端到端地干完,拿对数据,下对判断,还带着过往项目的上下文。
还有更硬核的例子。
UCSF脑瘤中心的一位流行病学副教授,用它做脑胶质瘤的分子流行病学研究,分析数千个微效种系(germline)变异如何叠加、塑造个体易感性。
据Anthropic介绍,这套种系分析,Claude Science用了过去约1/10的时间就跑完了,他的团队还独立复核过结果,确认既快又稳。
不过这些10倍提速的场景,目前只限定在综述写作、基因组分析、特定管线自动化上,并不等于「科研整体提速10倍」。
与此同时,科研可信度的门槛,也在被重新定义。
过去衡量一项研究靠不靠谱,要看同行评审,看能不能被别人复现。
而可复现,长期是科研最大的痛点之一,代码丢了,环境变了,几个月后连作者自己都跑不出当初那张图。
Claude Science每张图都有可追溯的代码,每个结果都连着它的环境和历史。可复现这道坎,它可能是第一个迈过去的。
同一条赛道,三种玩家
生物科研赛道,三巨头都在抢,只是玩法各自不同。
Google押独门模型,OpenAI押模型的科研智商,Anthropic则押的是工作流。
Google攥着AlphaFold、AlphaGenome这些别人没有的自家模型,直接下场。
OpenAI走的是另一条线。
今年4月它推出GPT-Rosalind,一个专为生物推理和药物发现打造的前沿模型。
如今更进一步,开始练模型的「科研判断力」。
它刚刚推出GeneBench-Pro,专测模型能不能像计算生物学家那样做判断:129道题,从基因组学、群体遗传一路铺到临床诊断,专测「数据撑不撑得起这个问题」「哪一步该推翻重来」的手感。

最强的GPT-5.6 Sol拿到28.7%,开Pro模式31.5%;几代前的GPT-5还不到5%。
OpenAI自己说,照这速度,年底就可能被刷爆。
可再强的模型,也只解开不到三分之一。而解不开的那部分,恰恰是人类科学家的位置。
GeneBench-Pro暴露的AI短板也很明显:
模型能起个头,却收不拢最后那一环,比如该不该剔掉一批异常数据、假设被推翻后怎么改路子,这类判断还得科学家自己拍板。
Claude Science也没有绕开这一点,方案交给人审、每个决定留给人撤,它自动化的是流程,判断权并非交给模型,人类始终在环。
对Lecoq这样的科学家,一篇综述能不能复现、几个月后还站不站得住,本就比榜单上多零点几个百分点要紧。
Claude Science赌的,正是让AI科研真正落进实验室的日常。
参考资料:
https://www.anthropic.com/news/claude-science-ai-workbench
https://openai.com/index/introducing-genebench-pro/
本文来自微信公众号“新智元”,作者:ASI启示录





