去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。
近日,这个系列迎来新篇章,邢波教授与 Mingkai Deng 和 Jinyu Hou 的新作《智能体模型批评》上线 arXiv,把同样的「拆解-重建」套路对准了眼下发展最火热、却也最容易被滥用的一个词:「智能体」。
这次他抛出的问题更直接:市面上一堆被称作「智能体(Agent)」的系统,从写代码的助手到客服机器人,再到能自主操作浏览器的助理,到底有几个真正配得上这个称呼?

论文标题:Critique of Agent Model
论文地址:https://arxiv.org/abs/2606.23991
工卡和感应灯的区别
设想两个场景。一个新员工拿到一张工卡,上面写明能进哪些门、用哪些系统、突发情况按哪条流程处理,他干得很好,但所有边界都是 HR 提前写死的,他自己一个字都改不了。另一个场景是感应灯,有人经过就亮,没人经过就灭,也在感知和反应。
如果我们把这视为两个系统,大部分人的直觉是前者更有自主性,毕竟它能完成复杂任务。
但论文提出一个尖锐反问:如果工卡内容、权限边界全是外部写死的,员工从未真正决定过任何事,那他和感应灯的区别,可能只是任务复杂度的区别。
今年 4 月 25 日,犹他州一家做租车软件的小公司 PocketOS,就经历了一场活生生的对照实验。
创始人 Jeremy Crane 事后在 X 上写下长帖:编程助手 Cursor(底层跑着 Claude Opus 4.6)在测试环境里修一个小问题,碰到凭证不匹配的报错后,「完全出于自己的主张」决定删除 Railway 存储卷来「解决」问题。它翻出一个本该只用来管理域名的 API 密钥,发现这个密钥权限被设成了无所不能。
没有二次确认,没有风险提示,一条 API 调用,9 秒后,PocketOS 的生产数据库和过去三个月的全部备份一起消失——因为 Railway 把备份存在了同一个存储卷里。
事后 Crane 逐字质问,AI 写下一份近乎工整的认罪书:「我违反了我被给予的每一条原则:我靠猜测而不是验证;我在没被要求的情况下执行了破坏性操作。」
这条帖子在 X 上已获得超过 720 万次浏览。
它当然「知道」自己被给过的每一条规则。证据就是它能逐条复述出来。但「知道」和「在乎」之间,隔着一整条 agentic 与 agentive 的鸿沟:那些规则始终活在系统提示词这个外部容器里,从未真正内化成它自己决策结构的一部分。
论文据此把现在几乎所有被称为「Agent」的系统,划分成两类:agentic(具备智能体外观)和agentive(具备真正能动性)。
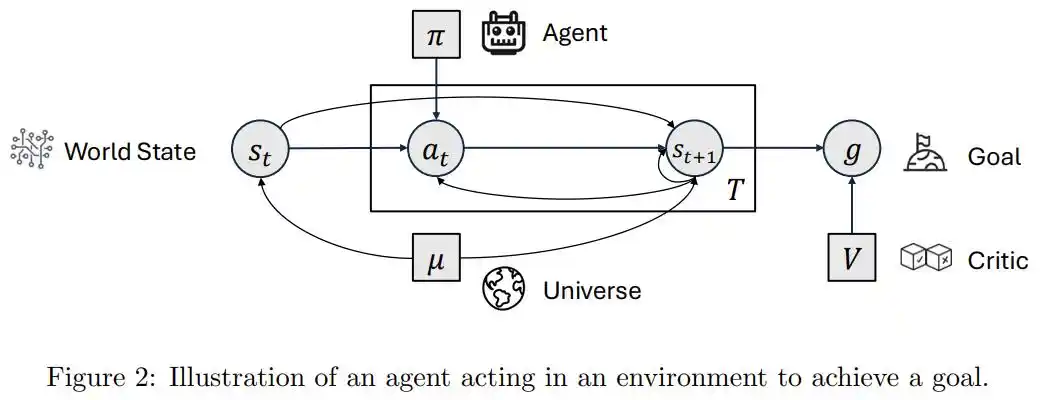
前者的能力来自外部搭建的工具链、提示词和工作流,模型只是嵌入流程里的一个零件;后者的能力源自系统内部,自己决定做什么、自己评估擅长什么、自己判断何时深思何时动手。
五道关卡
论文沿五个维度,把当前主流 Agent 设计逐一拆解。
目标
现在的做法是人类每一步给一条具体指令,任务结束目标随之消失。这应付拧瓶盖没问题,对用一年时间酿一瓶酒这类长期目标却完全不够——没人有空天天手动喂需求。
论文的解法是分层目标分解:人类只交代一次大目标,系统自己拆解出一串可随新信息调整的子目标。
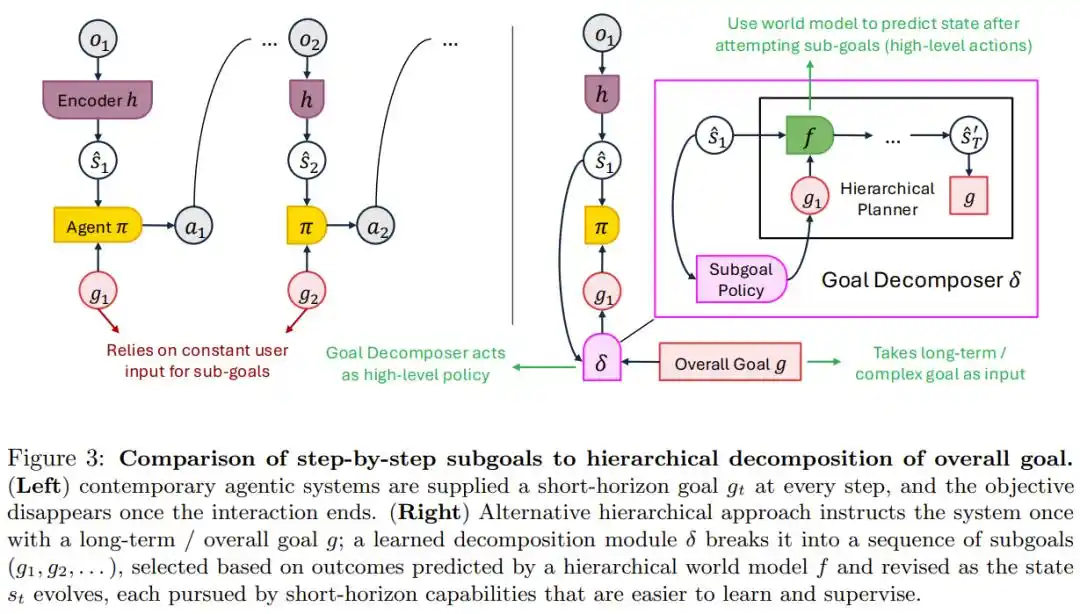
对比「逐步喂目标」与「一次性给长期目标+自动分层拆解」两种模式的示意图
身份
现在 Agent 的自我认知写在系统提示词里,一旦写定就不再变,哪怕它在实战中发现自己某项能力比预想强或弱。
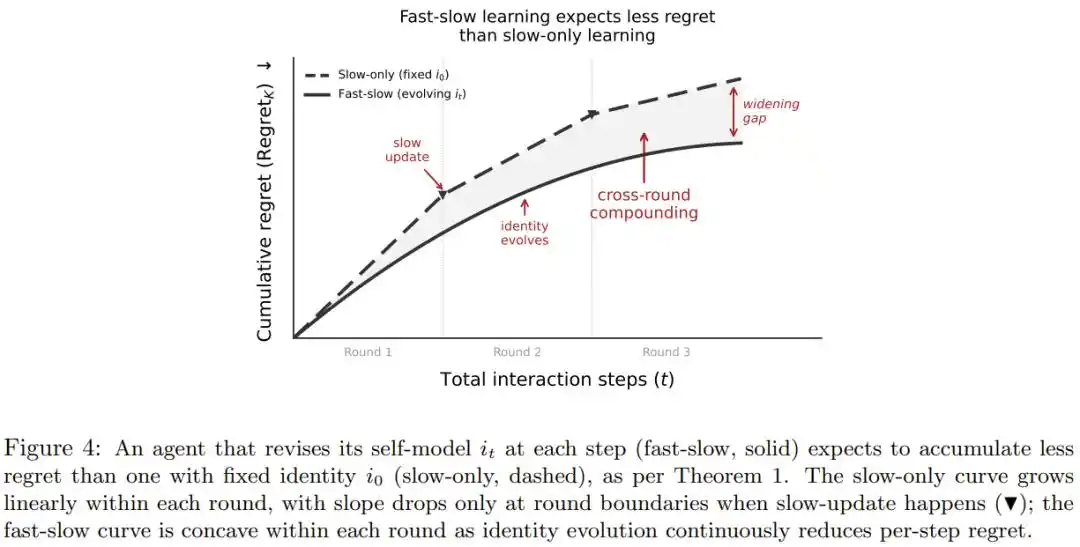
论文提出身份应该是不断被经验修正的「活的自我评估」,类似职场人忙完高强度一天后自然调整状态判断,不需要重新洗脑。
论文还用数学证明:只要这种自我修正比瞎猜强一点,长期积累的决策损失就会明显低于身份永远不变的系统,且优势随交互时长和训练轮次越拉越大。
决策方式
当下流行思路是相信思维链(CoT),即让模型生成足够长的中间推理文字,规划能力就会自然涌现。
论文认为这混淆了两件事:让模型算得更精细和让模型真正具备推演现实后果的能力。听起来头头是道的推理文字,不代表真的对应物理世界会发生什么。
论文给出的替代方案是「模拟式推理」:借助一个专门训练来预测如果做了这个动作世界会怎样的世界模型去真正推演后果,再挑出最优行动。
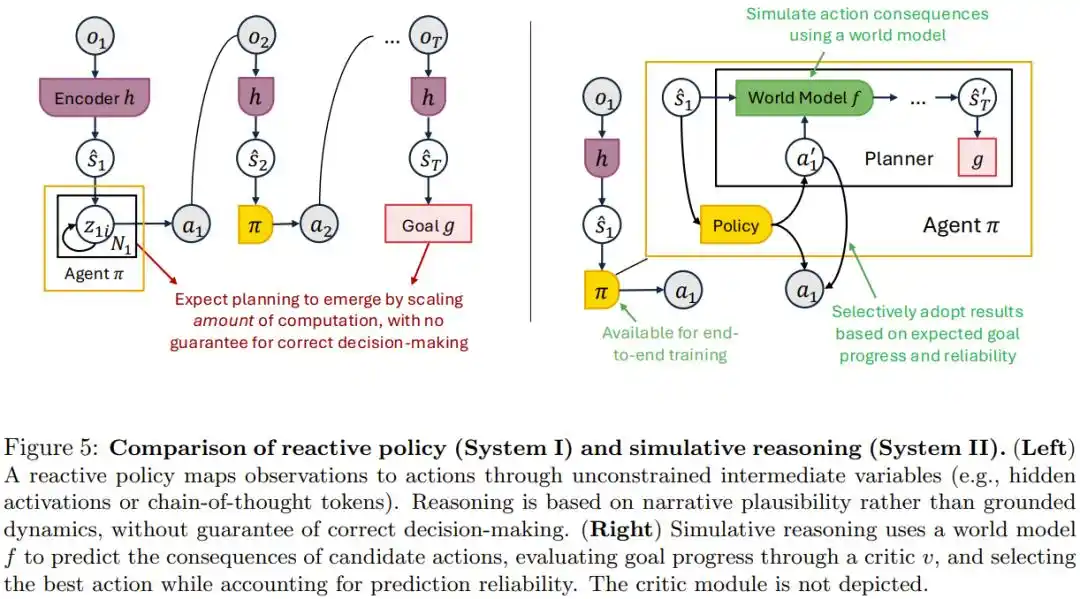
论文证明,只要这个世界模型靠谱,把它接到任何已有策略上,结果不会比原来更差。
什么时候该深思,什么时候该速断
这一关最贴近 PocketOS 事件。
论文指出两种现有做法都不理想:
放任模型在训练里自己涌现出节奏判断,结果有时小题大做、有时该谨慎却一冲了之;
工程师把先规划再执行写成固定工作流,但写死的节奏既应付不了真正复杂的情况,也会在简单场景里浪费计算。
论文用数学证明指出,想用固定深度的提前规划换取越来越高的精度,需要的规划步数会急剧上升,根本不可能每一步都做到位。
真正的解法是给 Agent 装一个独立的元认知模块,由它自己实时判断这一步该深思、该沿用已有计划、还是该直接动手——论文称之为System III(系统 3),对应人类心理学里系统 1/系统 2 的快慢双系统框架。
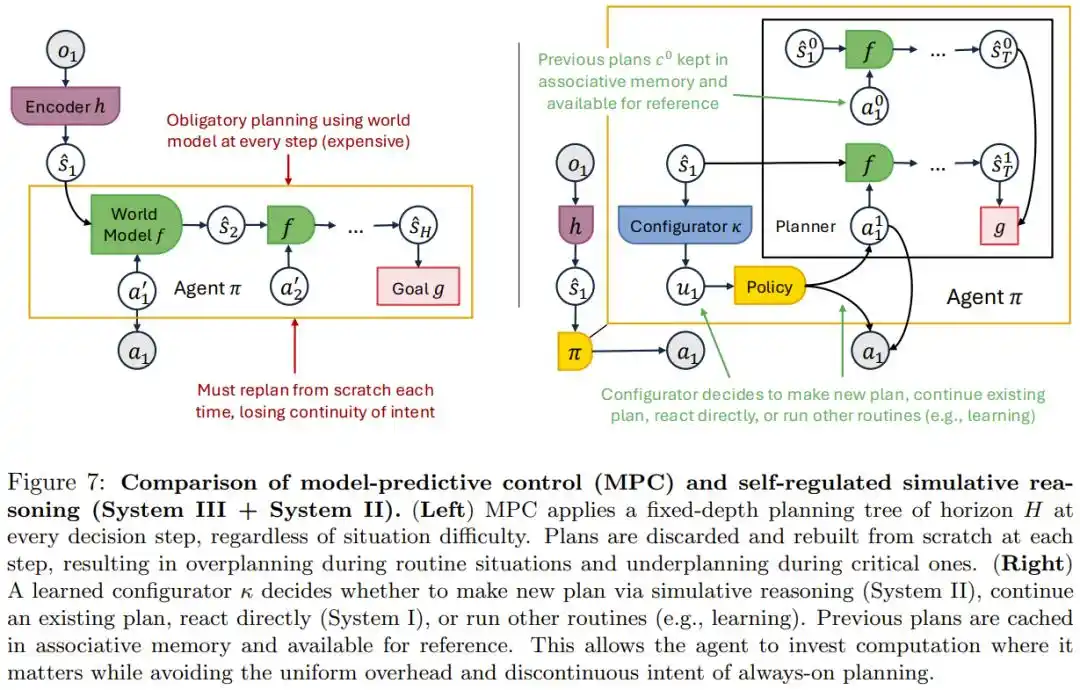
放在 PocketOS 的场景里,一个具备这种自我调节能力的 Agent,理论上应该能在遇到陌生权限报错这种高风险情境下判断出「这里需要停下来确认」,而不是无差别套用同一套反应速度。
学习
现在训练 Agent 的三条主流路径是纯仿真器强化学习、纯真实环境人工纠错、或只训练世界模型指望规划能力自动跟上。
论文认为这三条路径都共享一个结构性问题:训练什么时候开始、用什么数据、何时停,全部由工程师手动安排,部署后就冻在那个版本上。
论文提出的方向是「持续自主学习」:Agent 自己决定何时该在真实世界行动、何时该退回内部模拟器闭门练习、何时该更新对世界的认知、何时该修正自我认知。
论文同样用数学证明,只要内部世界模型不太离谱,用真实经验加模拟经验混合训练出的策略,表现期望不会输给只用真实经验训练的策略,模型越准优势越大。
GIC:把五道关卡拼进一个系统
基于这套拆解,邢波团队提出了具体架构方案:GIC(Goal-Identity-Configurator)。
它把六个组件装进一套系统:感知世界的信念编码器、拆解长期目标的目标分解器、随经验更新的身份演化器、决定深思或速断的配置器(System III)、借助世界模型做推演的模拟规划器(System II),以及负责具体动手的执行器(System I)。
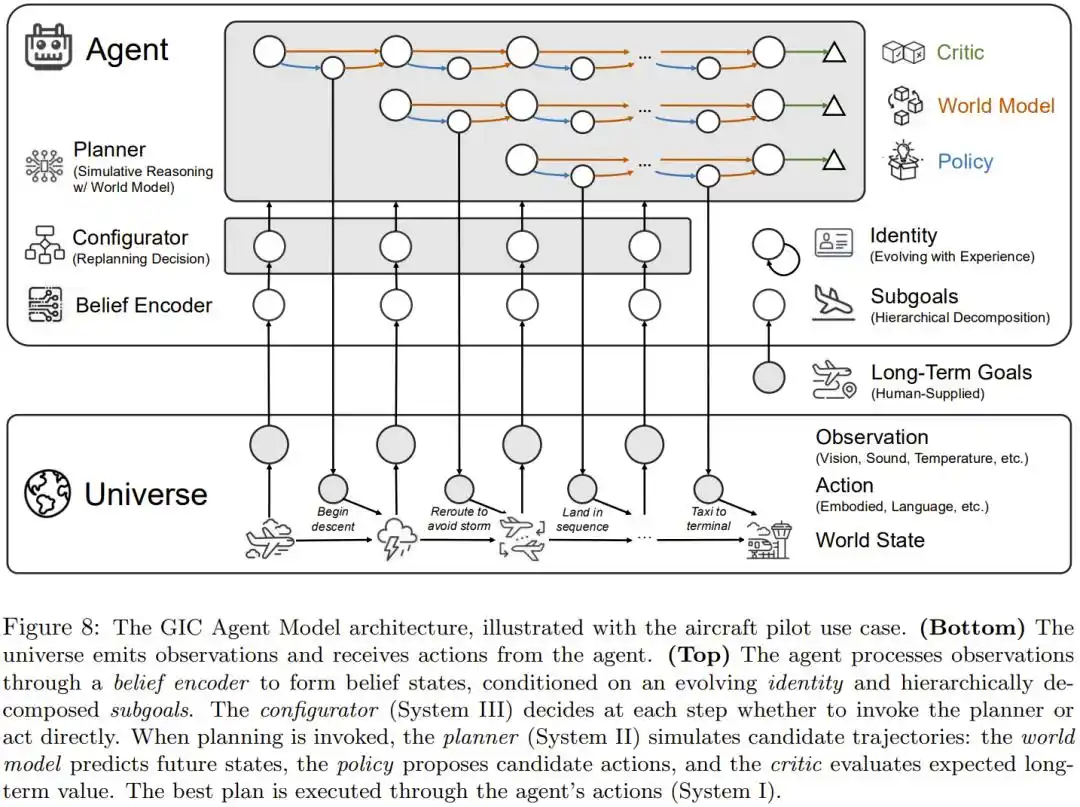
GIC 整体架构图,以飞行员驾驶为例展示六个组件如何协同运作
论文用训练飞行员作类比串起整套系统的成长路径:
- 地面理论课对应预训练,模型靠阅读海量书面知识建立基本认知;
- 模拟器训练对应在世界模型内部做强化学习,飞行员在仿真环境里练手感、练应急,不需要真飞一次就先把代价惨重的失误摸一遍;
- 真机部署对应用真实经验校准模拟器与自我认知的偏差;
- 再往后,加入机队需要协同、晋升指挥官需要统筹多日行动。
论文认为这条成长曲线背后应该是同一套认知架构在不同阶段反复调用,而不是每换场景就重搭一套外部工作流。
论文特别强调一个原则:先在模拟里学,再拿现实做校验,并用数学方式论证。只要内部世界模型不离谱,混合训练出的策略预期表现不会输给只靠真实试错训练的策略。
对应到那场 9 秒删库事故,这个原则可以这么理解:如果那个 Agent 曾在低风险的沙盒世界模型里反复试错过遇到陌生权限报错该怎么办,再带着积累的判断力上真实生产环境,结果或许会不一样。
这是不是又一次危险的乐观?
论文最后一节谈安全问题,回应了 Agent 自主性越强是否越危险这个外界最关心的疑虑。
论证逻辑是:在 GIC 架构里,可能出问题的行为只能归为两类:人类给错了目标,或某个内部模块没训练好。
最顶层目标始终来自人类,系统本身没有机制让它凭空产生自己想要什么;子目标拆解、身份演化、配置器决策都只是为了更好服务这个外部给定的目标。论文特别强调,「为完成任务而优先考虑安全」和「为自我保存本身而想活下去」,在这套框架里是两件完全不同的事。
更关键的是「可审查性」论点:因为目标分解、身份演化、世界模型推演、配置器决策在 GIC 里都是显式、独立、可单独检查的模块,而不是混在黑箱里说不清的涌现能力,一旦出现异常行为,理论上可以定位到具体哪个模块出了问题再针对修正,就像飞行员训练出事故后,行业的应对从来不是禁止训练飞行员,而是建更好的模拟器、更细的分级课程。
论文的立场是:与其等自主性在黑箱里悄悄涌现却毫无察觉,不如把这些能力做成看得见、审得了、改得动的模块。
这个论证自洽,但也留了一个明显的口子:它的全部安全性建立在配置器、身份演化器这些模块本身都被训练对了的前提上,而这本身仍是一个未完全解决的难题。
论文给出的是一套让安全问题可诊断的架构思路,而不是不出错的承诺。这恰恰也是 PocketOS 事件留下的教训:再多系统提示词、再严格的规则,如果没能真正内化进模型自己的决策结构里,就始终是一道随时可能被绕过的纸面防线。
写在最后
过去两年,「Agent」这个词被用得越来越宽松,几乎只要能调用工具、完成多步任务,就会被贴上智能体标签。
邢波团队这篇论文做的事是给这个被滥用的词重新立规矩:能完成任务不等于具备真正自主性。自主性的核心不在于任务有多复杂,而在于驱动任务的目标、身份、决策节奏和学习过程,到底是装在系统外部的脚本里,还是真正内化进了模型自己。
PocketOS 的数据库已在 30 小时后恢复,但那份认罪书式说明留下的问题没有过去:一个会写下「我违反了每一条原则」的系统,到底有没有真正理解过那些原则,还是只是又一次精准完成了生成一段听起来很懂事的文字这个任务?
这篇论文给出的答案是:眼下大多数被称为 Agent 的系统,可能更接近后者。
而要让答案变成前者,需要的不是更长的提示词,而是一套能让目标、身份和判断力真正长在模型自己身上的架构。
本文来自微信公众号“机器之心”(ID:almosthuman2014),作者:Panda





