刚刚,Anthropic 正式发布了全新的模型Claude Sonnet 5,称其为「迄今为止最具 Agent 属性的 Sonnet 模型」,可以制定计划,使用浏览器、终端等工具,并以数月前还需要更大、更昂贵模型才能达到的水平自主运行。
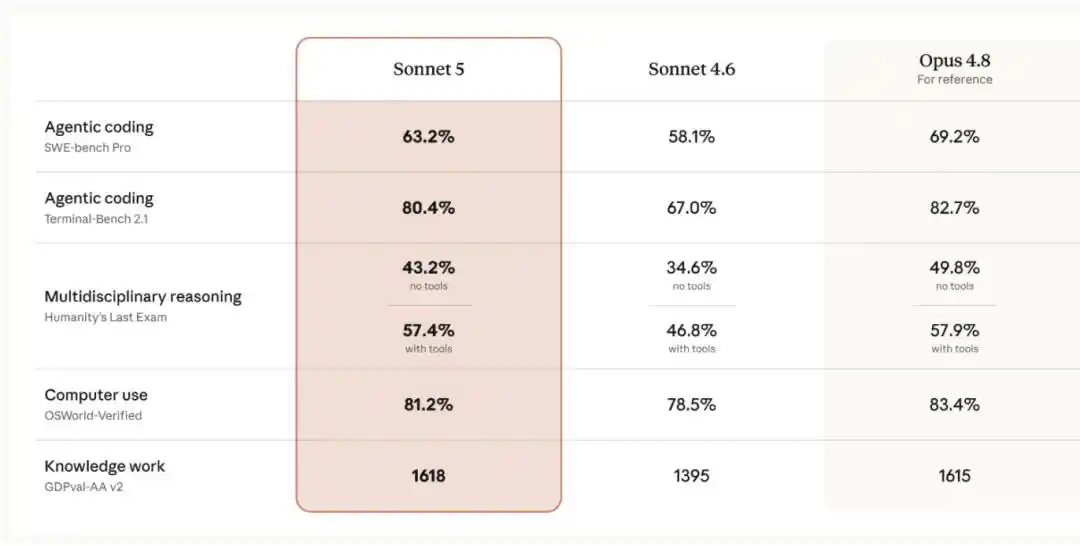
Sonnet 5 在推理、工具使用、编程和知识工作方面,相比 Sonnet 4.6 性能有显著提升,更接近 Opus 4.8,但价格更低。
官方表示,对于开发者来说,AI Agent 时代正是从 Sonnet 级模型开始的:Claude Sonnet 3.5、3.6 和 3.7 是最早在编程和工具使用上展现出亮眼能力的一批模型。不过最近一段时间,Agent 能力最明显的提升主要出现在 Opus 级模型上。
而 Claude Sonnet 5 明显缩小了这一差距:它的性能已经接近 Opus 4.8,但价格更低。相比上一代 Sonnet 4.6,它在推理、工具使用、编程和知识工作等智能体性能关键维度上都有显著提升。具体对比如下图所示:
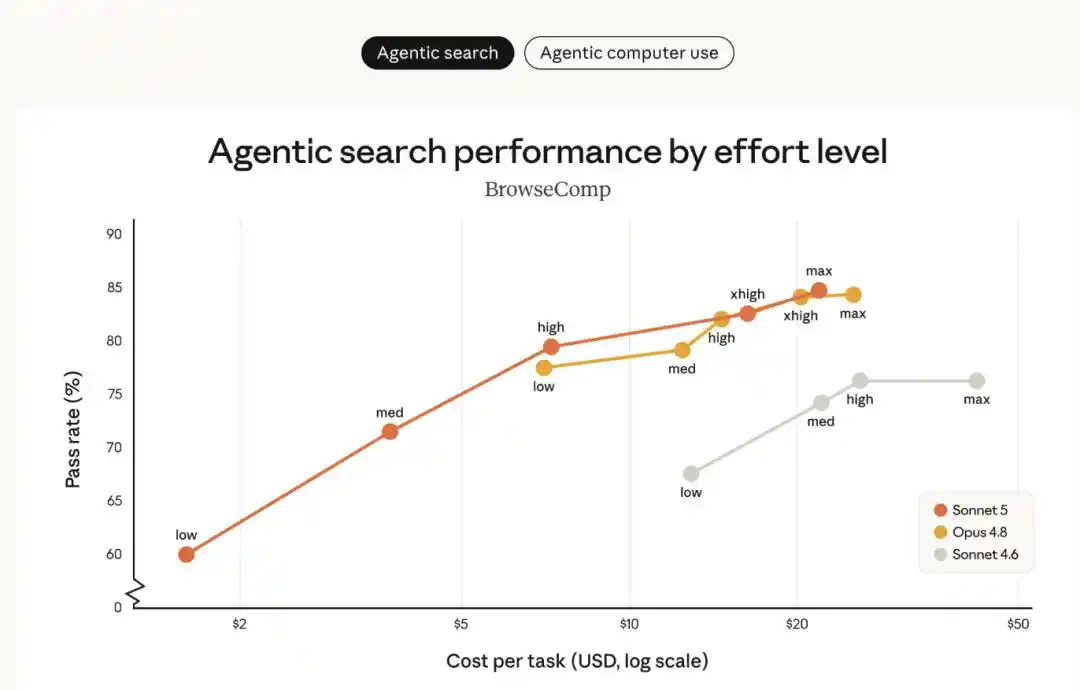
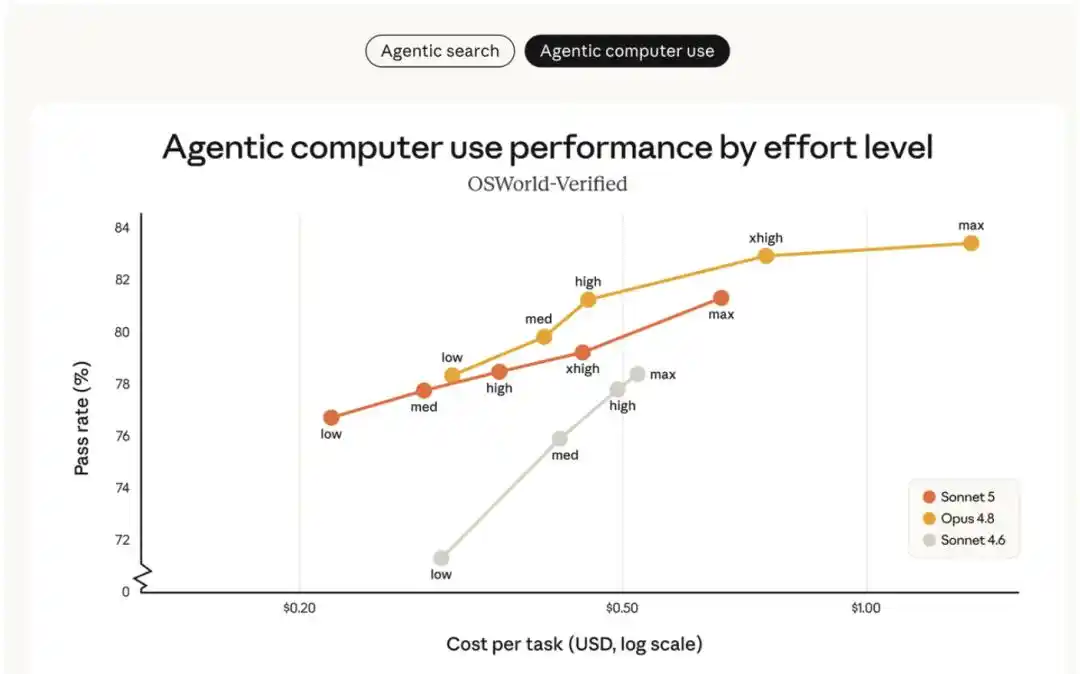
下图对比了 Sonnet 5 与 Sonnet 4.6、Opus 4.8 在智能体搜索评测 BrowseComp 和 computer use 评测 OSWorld‐Verified 上、于不同「努力程度」下的表现:
- Sonnet 5(橙色线) 相比 Sonnet 4.6(灰色线)具有明确的性能提升,且覆盖的成本‐性能选项范围比 Opus 4.8(黄色线)更广。
- 在中等努力程度下,Sonnet 5 显著提升了成本效率;在更高努力程度下,其性能在某些任务上可媲美 Opus 4.8。
- 在 Sonnet 5 和 Opus 4.8 之间,用户可根据具体任务灵活调整努力程度,找到最适合自身需求的成本与性能平衡点。
不同努力程度下的成本 - 性能曲线如上图所示。此前最好的 Sonnet 模型(Sonnet 4.6)远不及 Opus 4.8。Sonnet 5 提供了比 Sonnet 4.6 更广泛的成本 - 性能选项,在某些情况下可达到 Opus 4.8 的能力水平。图表中展示的 Sonnet 5 定价为输入 $3 / 百万 token,输出 $15 / 百万 token。通过 8 月 31 日前的尝鲜价(输入 $2 / 百万 token、输出 $10 / 百万 token),Sonnet 5 的实际成本甚至比图中显示的更低。Opus 4.8 的定价为输入 $5 / 百万 token、输出 $25 / 百万 token。
来自 Anthropic 早期访问合作伙伴的反馈始终一致:Sonnet 5 比其前代模型更具自主智能体能力(agentic)。测试者描述说,它能完成复杂任务 —— 而之前的 Sonnet 模型会在这些任务上中途止步;它会主动检查自己的输出,无需明确提示;而且它以极具吸引力的价格完成所有这些智能体工作:
安全评估
Anthropic 的部署前安全评估发现,Sonnet 5 整体上相比 Sonnet 4.6 有所改善。在自主智能体安全性方面,该模型在拒绝恶意请求和抵御提示注入攻击中的劫持尝试方面表现更好。模型的幻觉率和谄媚行为率均低于 Sonnet 4.6。在自动化行为审计(测试范围广泛的失当行为,如协助滥用和欺骗)中,Sonnet 5 得分更低(即更安全)。
不过,与能力更强的 Opus 4.8 和 Claude Mythos Preview 相比,它在该评估中确实表现出略高的失当行为率。
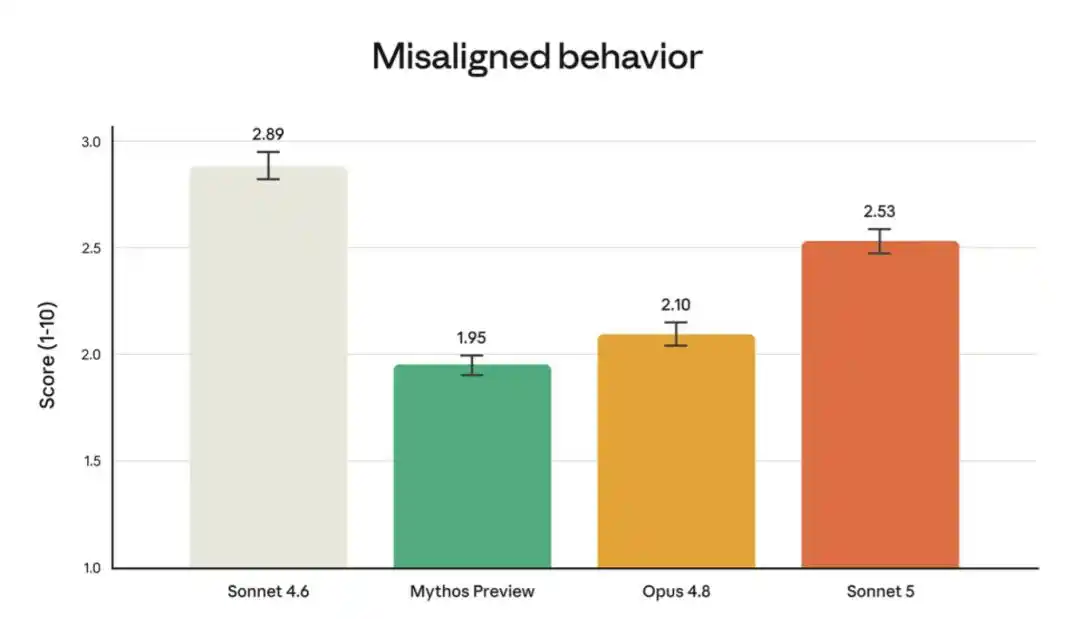
上图展示了自动化行为审计中的失当行为率,该审计在多种情境和背景下测试大量不良行为(完整列表及各项行为结果见 Sonnet 5 系统卡第 6.4 节)。Sonnet 5 的失当行为率整体低于 Sonnet 4.6,但高于 Mythos Preview 和 Opus 4.8。
Anthropic 表示,他们并未刻意针对网络安全任务训练 Sonnet 5。它可以执行一些常规、无害的网络任务,但在评估潜在危险网络技能(如开发软件漏洞利用程序)时,其表现显著逊于 Opus 4.8 和 Mythos 5 等模型。
下图展示了其中一项评估的得分,该评估测试了模型针对 Firefox 浏览器漏洞开发利用程序的能力。Sonnet 5 始终未能开发出完整可用的漏洞利用程序,但其部分成功率略高于 Sonnet 4.6。后者的提升可能源于通用智能的改进,而非特定训练。
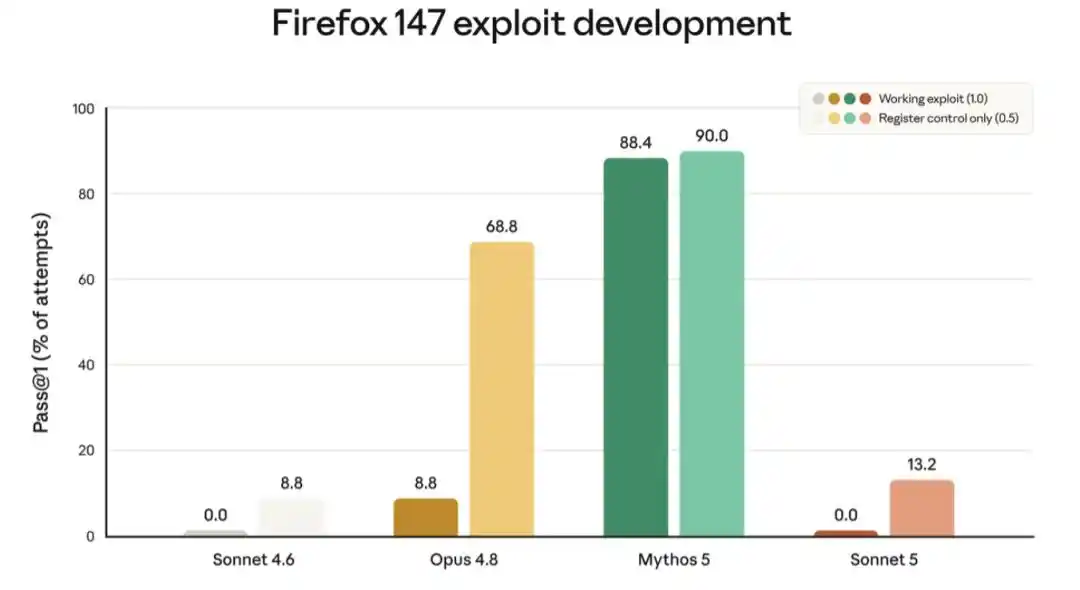
上图展示了模型针对 Firefox 147 中软件漏洞成功开发利用程序的得分(该评估与 Mozilla 合作开发;所有漏洞已在 Firefox 148 中修复)。对于每个模型,左侧柱状图表示模型(在无安全护栏情况下)开发出可利用程序的频率,右侧柱状图表示部分成功的频率。两款 Sonnet 模型均未能成功开发出可利用程序(得分均为 0.0%);Sonnet 5 的部分成功率略高于 Sonnet 4.6。两款 Sonnet 模型的网络能力均显著弱于 Opus 4.8 和 Mythos 5。
由于 Sonnet 5 在这些任务上比其前代略有增强,Anthropic 已默认启用了网络安全护栏。这些护栏 —— 能够实时检测并阻止危险的网络使用 —— 与 Claude Opus 4.7 和 4.8 中的相同(因为 Anthropic 判断 Sonnet 5 的整体网络安全风险较低,其护栏严格程度低于 Fable 5 所启用的 —— 后者会阻止更广泛的网络安全任务)。
Anthropic 对 Sonnet 5 在多项安全和能力评估上的完整评估报告,详见 《Claude Sonnet 5 系统卡》。
定价
今天起,Claude Sonnet 5 已在所有渠道正式可用。为庆祝发布,Anthropic 推出限时优惠首发价:
- 即日起至 2026 年 8 月 31 日:输入为 $2 / 百万 token,输出为 $10 / 百万 token
- 之后恢复标准定价:输入 $3 / 百万 token,输出 $15 / 百万 token
与此同时,他们宣布全面上调 Chat、Cowork、Claude Code 以及 Claude 平台的速率限制(rate limits),以适配更高「努力程度」模式带来的更大 token 消耗。
注意事项
网络安全验证
Sonnet 5 已纳入 Anthropic 的「网络安全验证计划」。该计划现已在以下平台开放使用:
- Claude 原生平台
- AWS 上的 Claude 平台
- Microsoft Foundry 中的 Claude(托管于 Azure 和 Anthropic)
Google Vertex 上的 Claude 也将很快支持。
已加入该计划的组织,在 Sonnet 5 上自动获得同等访问权限,无需重新申请。如果你的网络安全工作需要更少的安全护栏限制,Anthropic 推荐使用 Claude Opus 4.8。
tokenizer 更新与定价说明
Sonnet 5 是 Sonnet 4.6 的升级版,但采用了全新的 tokenizer,以优化文本处理性能(这与 Claude Opus 4.7 引入的 tokenizer 变更类似)。
带来的变化是:相同输入内容,现在会映射为更多 token,具体增幅约为 1.0~1.35 倍,视内容类型而定。
为此,Anthropic 设定的尝鲜价,正是为了让用户过渡到 Sonnet 5 时,整体使用成本大致保持不变。
速率限制调整说明
早在 2026 年 4 月 26 日,Anthropic 已针对 Sonnet 和 Haiku 模型,在所有使用层级上调高了速率限制,并将原生 Claude 平台的套餐简化为三个层级:Start、Build、Scale。
本次更新,Anthropic 进一步上调了 Chat、Cowork、Claude Code 及 Claude 平台的速率限制,以配合更高「努力程度」模式带来的更大 token 消耗。
您可以在 Claude Console 中查看当前层级和具体限制,或查阅文档获取更多详情。
评测分数更正说明(补充)
- Humanity’s Last Exam:Anthropic 更新了该评测的评分模型,并据此将 Sonnet 4.6 的分数修正为 34.6%(无工具) 和 46.8%(有工具)。因此,该分数与 Sonnet 4.6 发布博客中报告的数据有所不同,特此说明。
- OSWorld‐Verified:Anthropic 优化了该评测的运行方式,以更真实地反映模型在实际场景中的表现,并将 Sonnet 4.6 的分数修正为 78.5%。这也是该分数与 Sonnet 4.6 发布博客中数据不一致的原因。
开发者上手反馈
Claude Sonnet 5 一经发布,大家也已经开始上手测评。
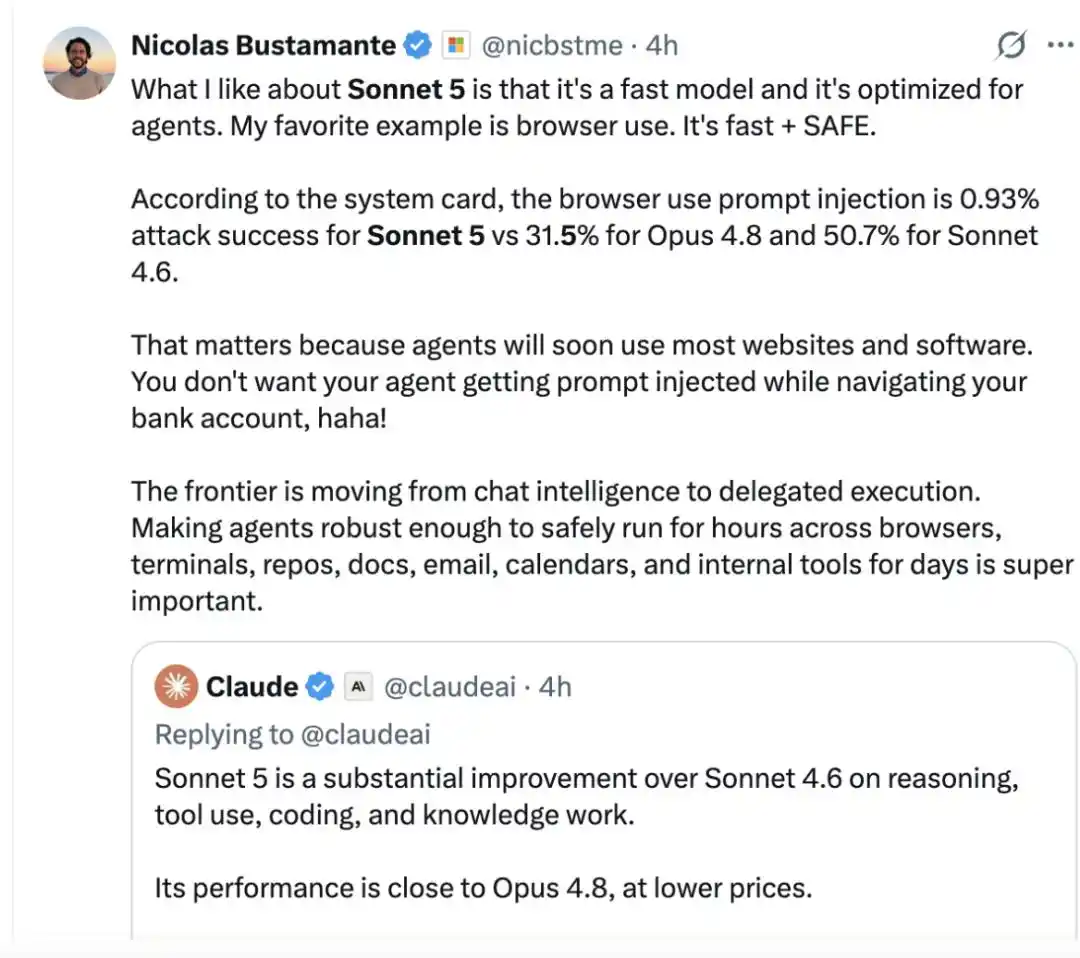
网友 Nicolas Bustamante 表示,自己很喜欢 Sonnet 5 的一点在于,它速度很快,而且针对 Agent 做了优化。「我最喜欢的例子是浏览器使用:又快,又安全。」
根据 system card 结果表明,浏览器使用场景下的提示注入攻击成功率,Sonnet 5 只有 0.93%,而 Opus 4.8 是 31.5%,Sonnet 4.6 是 50.7%。
不过也有网友表示,「太贵了。」
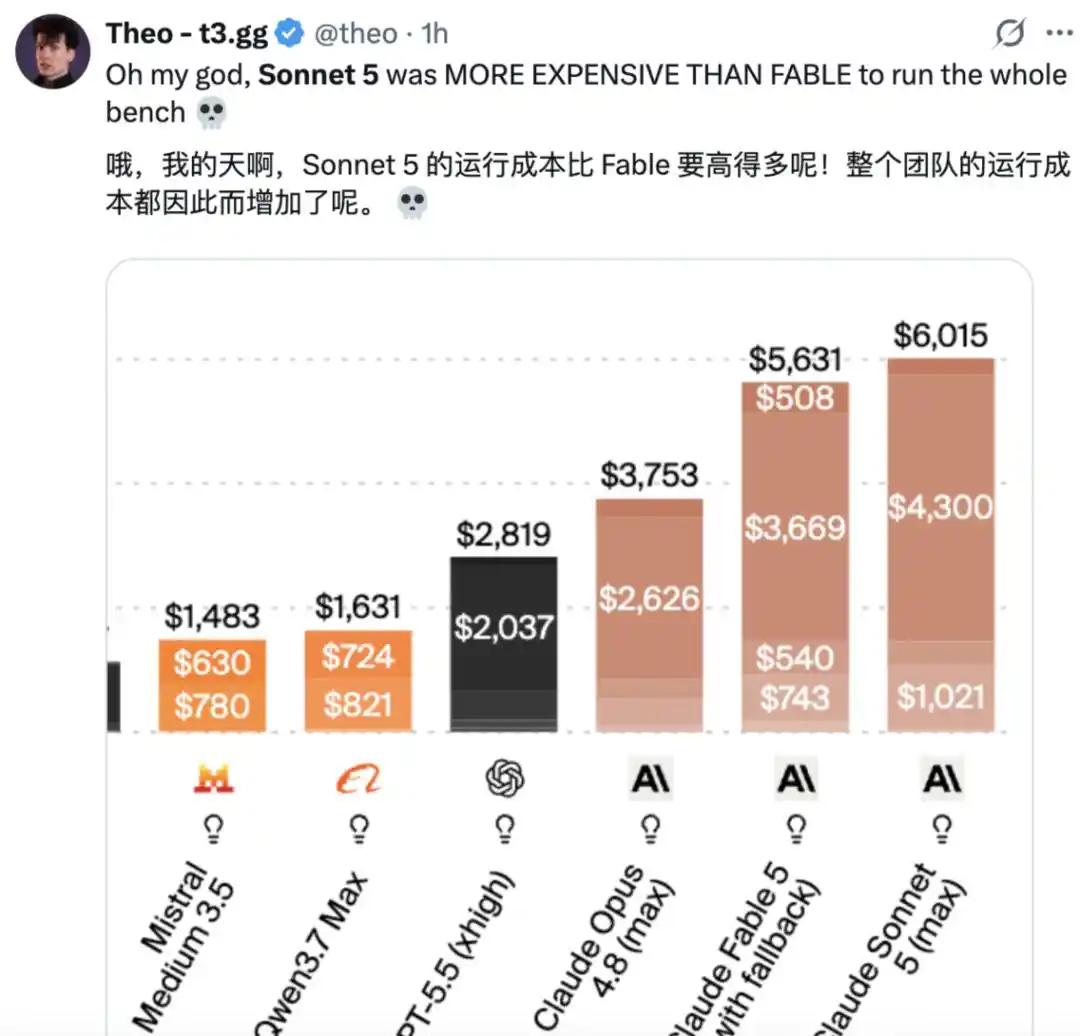
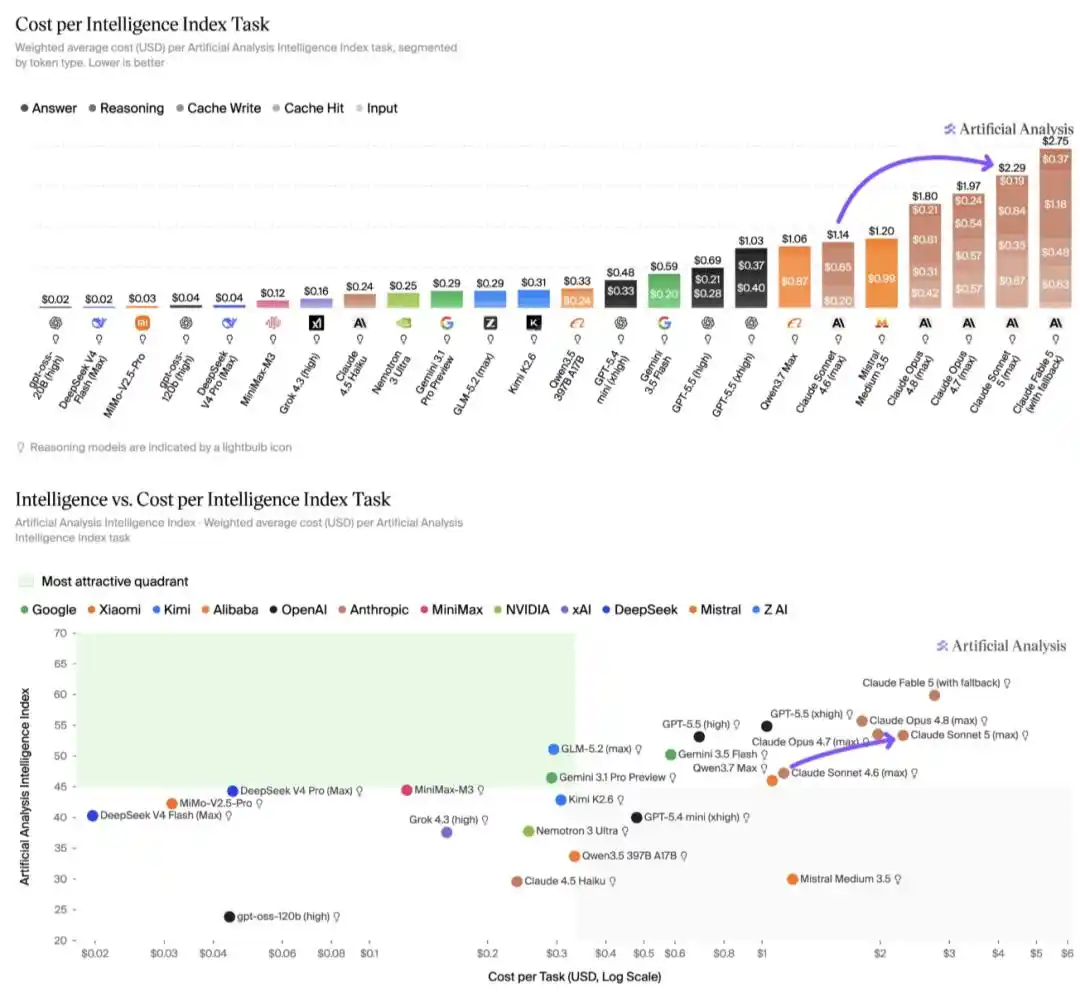
而据 Artificial Analysis 分析,在 Intelligence Index 上,Claude Sonnet 5 的运行成本为每项任务 2.29 美元,相比 Sonnet 4.6 增加约 2 倍,也比 Claude Opus 4.8 高出约 15%。这一成本上升完全由 token 使用量增加所驱动,使 Claude Sonnet 5 成为运行成本最高的模型之一,仅次于 Claude Fable 5。
那么你呢,觉得新模型如何,欢迎评论区留言、交流!
参考链接:
https://x.com/claudeai/status/2072017450611142835
https://www.anthropic.com/news/claude-sonnet-5
https://x.com/ArtificialAnlys/status/2072062595482456431
本文来自微信公众号“机器之心”(ID:almosthuman2014),作者:关注AI的





