撰文:KarenZ,Foresight News
原标题:大白话拆解 X 新推荐算法:从「捞数据」到「打分」
马斯克把推特的推荐系统从「人工堆砌规则和大部分启发式算法」改成了「纯靠 AI 大模型猜你喜欢」?
1 月 20 日,推特(X)正式披露新推荐算法,即推特首页「为你推荐」(For You)时间线背后的逻辑。
简单来说,现在的算法是:把「你关注的人发的内容」和「全网可能对你胃口的内容」混在一起,根据你之前在 X 上的一连串点赞、评论等动作按对你的吸引力排好序,中间经过两次过滤,最终变成你刷到的推荐信息流。
以下是用大白话翻译的核心逻辑:
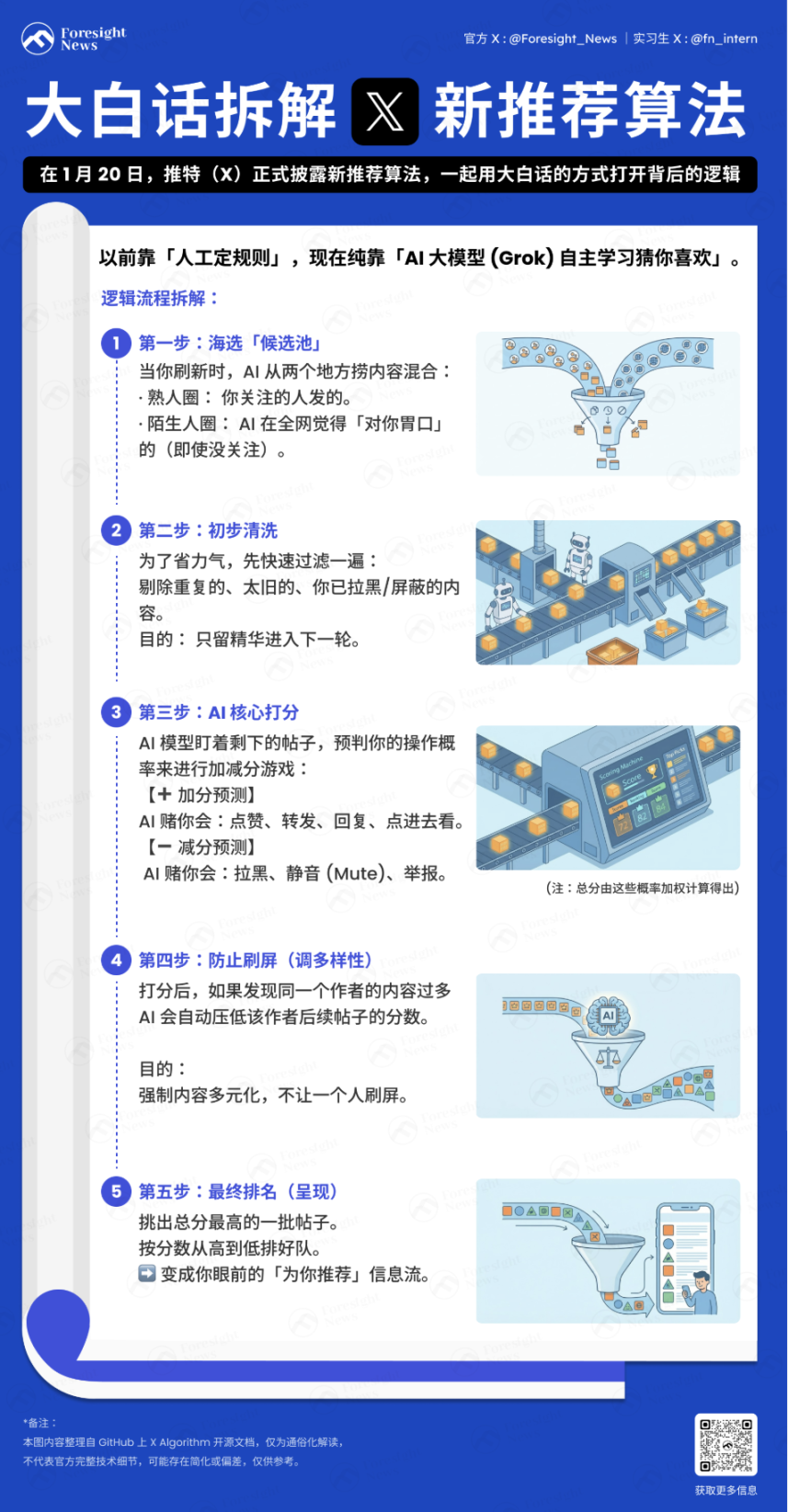
建立画像
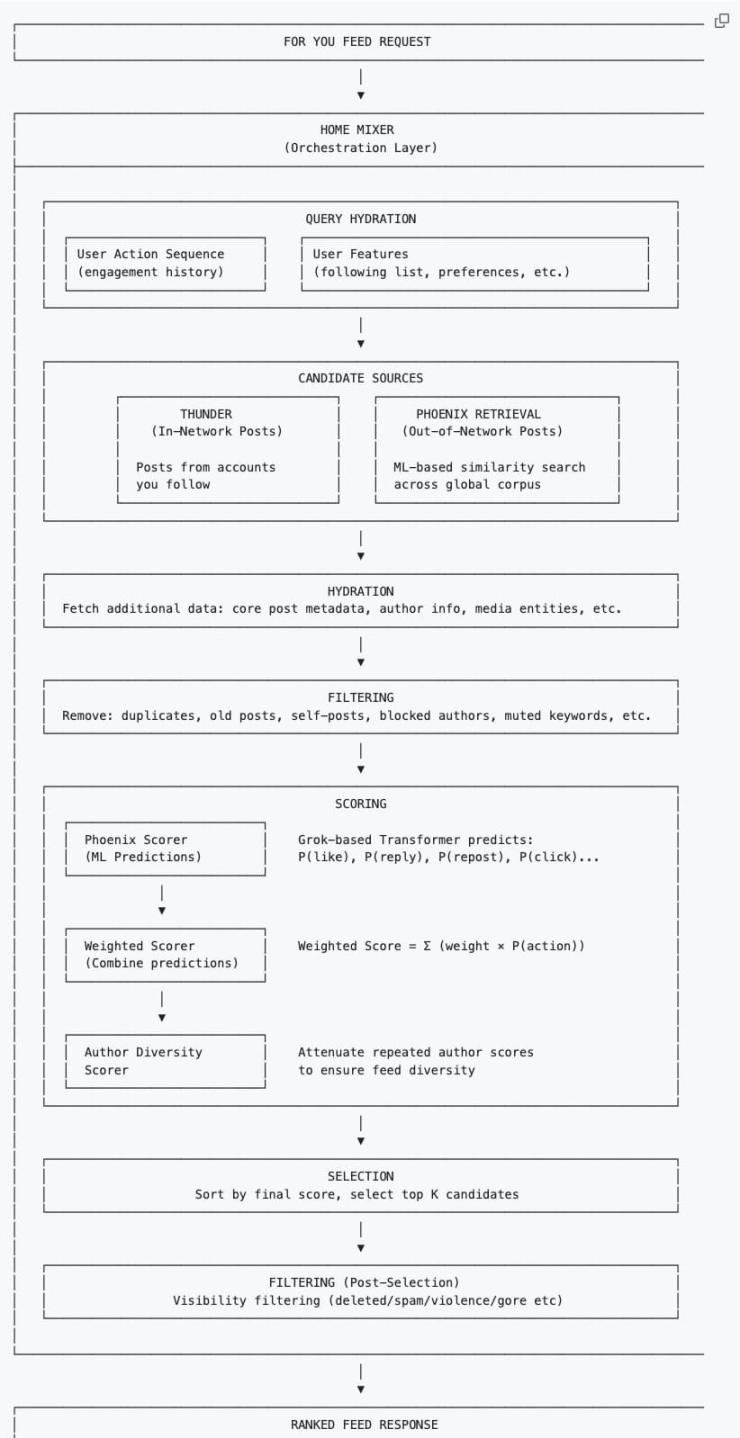
系统首先收集用户的上下文信息,为后续的推荐建立「画像」:
-
用户行为序列: 历史互动记录(点赞、转发、停留时长等)。
-
用户特征: 关注列表、个人偏好设置等。
内容从哪来?
每当你刷新「为你推荐」时间线时,算法会从以下两个地方找内容:
-
熟人圈(Thunder): 你关注的人发的推文。
-
陌生人圈(Phoenix): 你没关注,但 AI 会根据你的口味,去茫茫人海中把你可能感兴趣的帖子(哪怕你没关注作者)捞出来。
这两堆内容会混在一起,就是候选推文。
数据补全和初步过滤
捞上来成千上万条帖子后,系统会拉取帖子的完整元数据(作者信息、媒体文件、核心文本),这一流程叫 Hydration。然后会先进行一轮快速清洗,剔除重复内容、旧帖、用户自己发的帖、已拉黑作者的内容或屏蔽关键词的内容。
这一步是为了节省计算资源,避免无效内容进入核心打分环节。
怎么打分?
这是最关键的部分。基于 Phoenix Grok 的 Transformer 模型会盯着每一条过滤过后剩余的候选帖子,计算你对它做各种动作的概率。这是一个加分与减分的游戏:
加分项(正向反馈): AI 觉得你可能会点赞、转发、回复、点击图片、或者点进主页看。
减分项(负向反馈): AI 觉得你可能会拉黑作者、Mute、举报。

最终得分 = (点赞概率 × 权重) + (回复概率 × 权重) – (拉黑概率 × 权重)...
值得注意的是,新推荐算法中 Author Diversity Scorer(作者多样性打分器)通常会在 AI 算完最终得分之后介入。当检测到某一批候选帖子里,有同一个作者的多篇内容时,这个工具会自动「压低」该作者后续帖子的分数,让你刷到的作者更多元。
最后,根据按得分排序,挑分数最高的一批帖子。
二次过滤
系统把打分最高的前多少个帖子再检查一遍,过滤掉违规的(比如垃圾邮件、暴力内容)、给同一个 thread 的多个分支去重,最后按分数从高到低排好,变成你看到的信息流。
小结
X 已经在推荐系统中剔除了所有人工设计的功能和大部分启发式算法。新算法的核心进步在于「让 AI 自主学习用户偏好」,实现了从「告诉机器怎么做」到「让机器自己学会怎么做」的跨越。
首先是推荐更精准,「多维度预判」更贴合真实需求。新算法则靠 Grok 大模型预测多种用户行为 —— 不仅算「会不会点赞 / 转发」,还会算「会不会点进链接看」、「停留如何」、「会不会关注作者」,甚至会预判「会不会举报 / 拉黑」。这种精细化的研判,让推荐内容与用户潜意识需求的贴合度达到了前所未有的高度。
其次,算法机制相对更公平,在一定程度上可以打破「大号垄断」的魔咒,给新号、小号更多机会:过去的「启发式算法」有个致命问题:大号靠历史高互动量,发什么内容都能获得高曝光,新号哪怕内容优质,也因「没数据积累」被埋没。候选隔离机制让每条帖子独立打分,和「同批次其他内容是不是爆款」无关。同时,Author Diversity Scorer 也会降低同一作者同一批次后续帖子的刷屏行为。
对于 X 公司: 这是一次降本增效的举措,用算力换人力,用 AI 换留存。对用户而言,我们面对的是一个时刻揣摩人心的「超级大脑」。它越懂我们,我们越离不开它,但也正因为它太懂我们,我们将更深地陷入算法编织的「信息茧房」,并更容易成为情绪化内容的精准捕获对象。
Twitter:https://twitter.com/BitpushNewsCN
比推 TG 交流群:https://t.me/BitPushCommunity
比推 TG 订阅: https://t.me/bitpush