就在刚刚,Claude Sonnet 5来了!
代号Fennec,耳廓狐,撒哈拉沙漠里体型最小的狐狸。
这是Anthropic迄今为止,Agent能力最强的Sonnet模型,并且性能直逼旗舰Opus 4.8。
即日起,Sonnet 5成为所有Free和Pro用户的默认模型。

它能自主规划、调用浏览器和终端工具。
就在几个月前,这还需要花大价钱调用超大模型才能做到,现在,Sonnet轻松拿下。
相较于上一代Sonnet 4.6,Sonnet 5在推理、工具使用、编程和知识工作任务中,性能显著提升。
划重点:
SWE-bench Pro得分63.2%,反超GPT-5.5的58.6%,略输Opus 4.8的69.2%
「人类最后的考试」得分57.4%,和Opus 4.8只差0.5个百分点
标准价每百万token输入$3/输出$15,只有Opus 4.8的六成
浏览器注入防御0.93%,反杀Mythos 5和Opus 4.8

有趣的是,Fable 5也在同一天被曝出即将回归。但代价是强制实名验证,并且极大概率仅限美国用户。
而Sonnet 5则主打一个毫无保留,全球用户今天就能敞开用。

全线逼平Opus 4.8,最强打工AI突袭
这一次,Sonnet 5的突然上线,也算是填补了人们用不上Fable 5的失落。
对于很多开发者来说,Agent时代的元年,就是从Sonnet开始的。
Claude Sonnet 3.5、3.6、3.7,是最早一批在写代码、用工具上展现出惊人能力的模型。
换句话说,「让AI自己干活」这件事,最早跑通的就是Sonnet「中杯」系列。
但这一年多,最猛的能力跃升,全集中在Opus这条「大杯」线上。Sonnet,直接被旗舰甩在后面。
Sonnet5要做的,就是把这道差距补回来!
Anthropic一句话定调——Claude Sonnet 5是史上最能「干活」的Sonnet。
从实战的成绩来看,最能说明这一点。
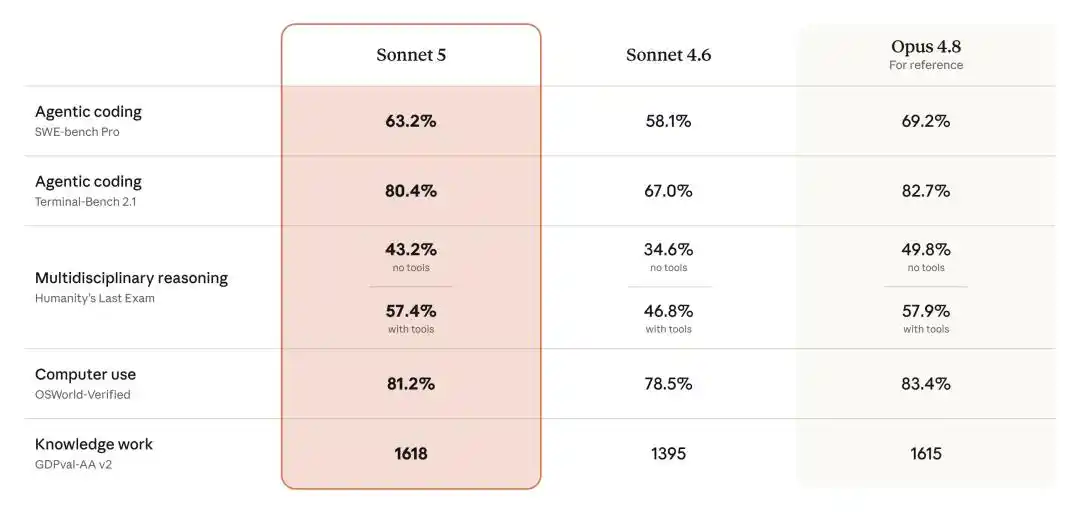
在传统强项编程领域,Sonnet 5在SWE-bench Pro上豪取63.2%。而前代Sonnet 4.6只有58.1%,Opus 4.8则凭借69.2%暂时领先。
相比之下,老对手OpenAI的旗舰GPT-5.5在同一个榜上只拿到了58.6%,谷歌的Gemini 3.5 Flash也只有55.1%。
Terminal-Bench 2.1更加凶悍,Sonnet 5直接飙到80.4%,把只有67.0%的Sonnet 4.6狠狠甩在身后,暴涨13个百分点。距离Opus 4.8的82.7%,只差不到2个点。
在号称「人类最后的考试」的跨学科推理基准Humanity's Last Exam上,Sonnet 5带工具斩获57.4%,Opus 4.8是57.9%,只差0.5个百分点。GPT-5.5同一测试只有52.2%,Gemini 3.1 Pro是51.4%。
电脑操控能力方面,Sonnet 5在OSWorld-Verified上的得分是81.2%,同样超过GPT-5.5的78.7%,直追Opus 4.8的83.4%。
更让人意外的是知识工作,Sonnet 5更是在GDPval-AA v2上拿到了1618分,直接反超Opus 4.8的1615。
在智能体搜索、工具使用表现中,Sonnet 5能以最低成本,提供了Opus 4.8级的能力。
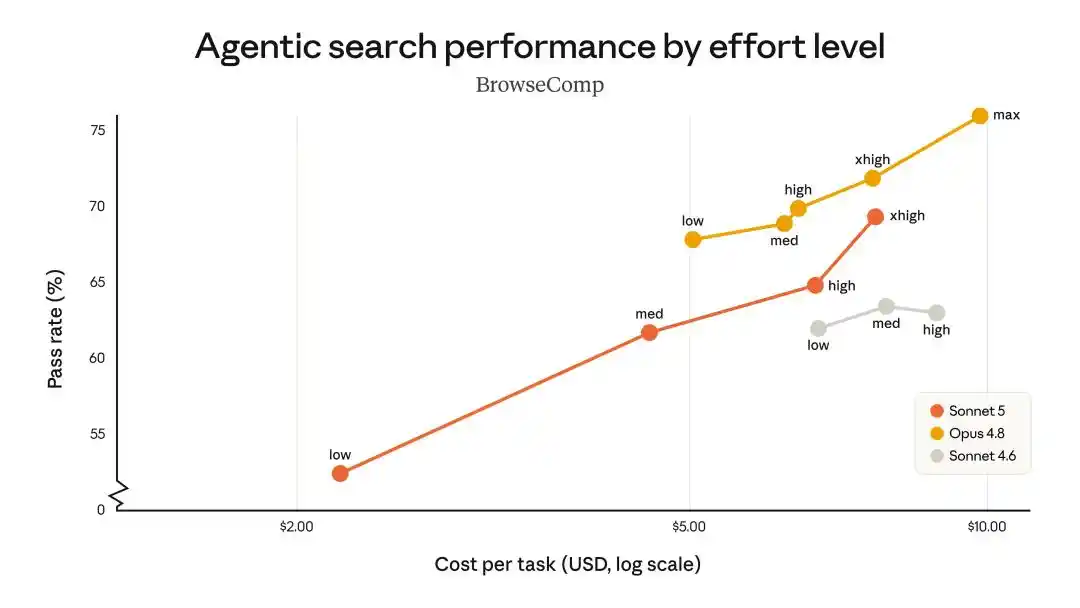
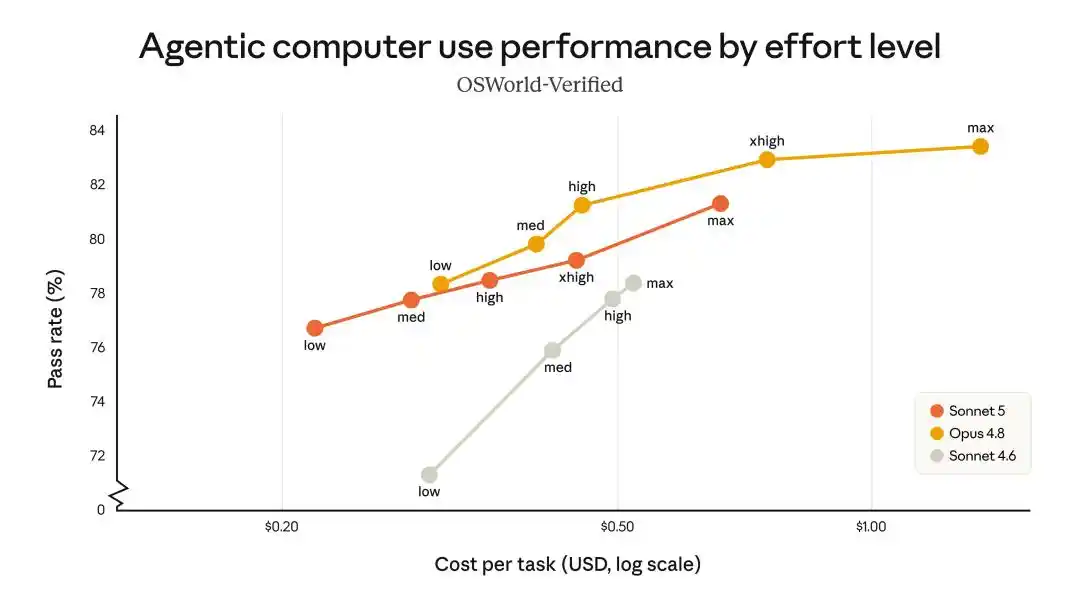
可以说,几乎每项benchmark,Sonnet 5都落在Opus 4.8的90%到100%区间。
堪称是花Sonnet的钱,买Opus九成的脑子。
2美元限时促销,但埋了个大坑
价格,才是这次的「必杀技」。
API定价方面,Anthropic给出了限时大促:输入2美元/百万tokens,输出10美元/百万tokens。
8月31日之后,恢复输入3美元和输出15美元的原价。
相比之下,Opus 4.8是5美元和25美元,GPT-5.5标准版是5美元和30美元。
促销期内,输入和输出价格都只有Opus 4.8的四成。恢复标准价后也只到六成。

不过,Anthropic虽然表面诚意满满,细节里却藏着小心思。
原因在于Sonnet 5换了全新的tokenizer,同样一段输入的token数量可能会膨胀1.0到1.35倍。
等促销期一过,$3/$15的原价再叠加tokenizer膨胀效应,真金白银的花销肯定要比用Sonnet 4.6肉痛一截。
但即便如此,跟Opus比依然是碾压级的差距。
反杀全家族旗舰
System Card里藏着Sonnet 5最被低估的一面。
提示注入攻击成功率0.19%,跟Opus 4.8持平。GPT-5.5是3.08%,Gemini 3.5 Flash是6.66%。

浏览器注入防御上,攻击成功率只有0.93%,而Mythos 5是29.7%,Opus 4.8是31.5%。
$2的中端模型,反杀了全家族旗舰,开启防护措施后直接降到0%。
恶意代码注入上,Sonnet 4.6的攻击成功率高达45.26%,Sonnet 5降到了0.29%,改善150倍。
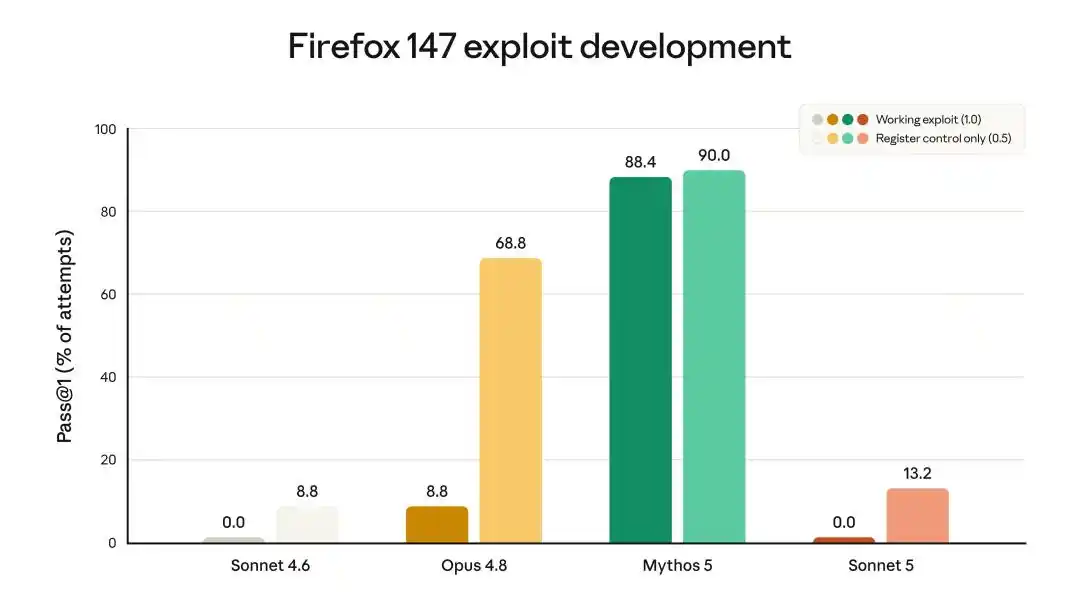
Firefox 147漏洞利用测试中,Mythos 5能写出88.4%的可用exploit,Opus 4.8是8.8%,Sonnet 5是0.0%。能写顶级业务代码,但写不出一个可用的漏洞利用程序。
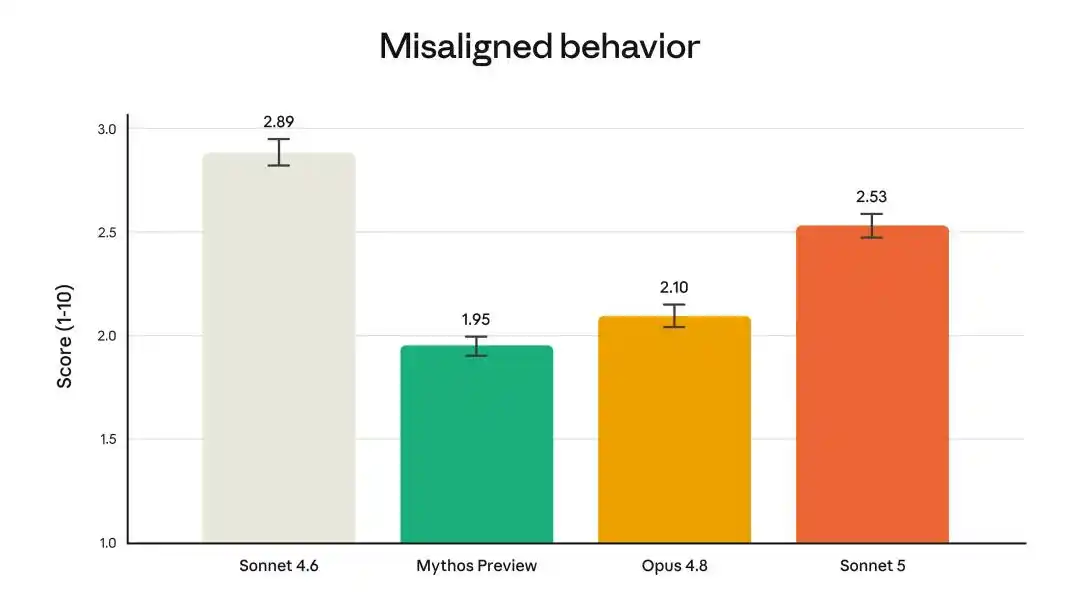
副作用是不对齐行为评分2.53(满分10),比Sonnet 4.6的2.89有改善,但高于Opus 4.8的2.10和Mythos Preview的1.95。
变强了,也变得更有主见了。
不争皇冠,专砍腰部
Sonnet 5卡在一个极其精准的位置上,向上能力逼近Opus 4.8和GPT-5.5,向下价格接近Gemini 3.5 Flash级别。
OpenAI刚把价格相较上代翻了倍,Anthropic转手把Sonnet 5的入门价压到了3美元。
那些原本犹豫要不要为旗舰付费的开发者,现在有了一个杀伤力十足的替代选项。
所有人都盯着顶端打的时候,Anthropic在腰部开了一枪。
开发者钱包,今晚先投了票
如今,Sonnet 5的性能已经踩进了旗舰区间,大部分修bug、补测试、做重构的活都能一次搞定。
以前觉得Opus太贵舍不得用、Sonnet又不够好的尴尬,今天没了。
价格上更划算。同样的预算以前只能跑一个Opus级的Agent,现在可以跑两到三个并行的Sonnet。
多Agent架构的成本门槛,被Sonnet 5一脚踹低了。
Fable 5究竟何时王者归来还是个未知数。
但Sonnet 5此刻已经稳稳地站在这里,性能直接怼到了Opus的门槛上。
对于绝大多数开发者而言,它就是接下来相当长一段日子里,手边最能打也最好用的那个Claude。
参考资料:
https://x.com/claudeai/status/2072017450611142835
https://www.anthropic.com/news/claude-sonnet-5
本文来自微信公众号“新智元”,作者:ASI启示录





