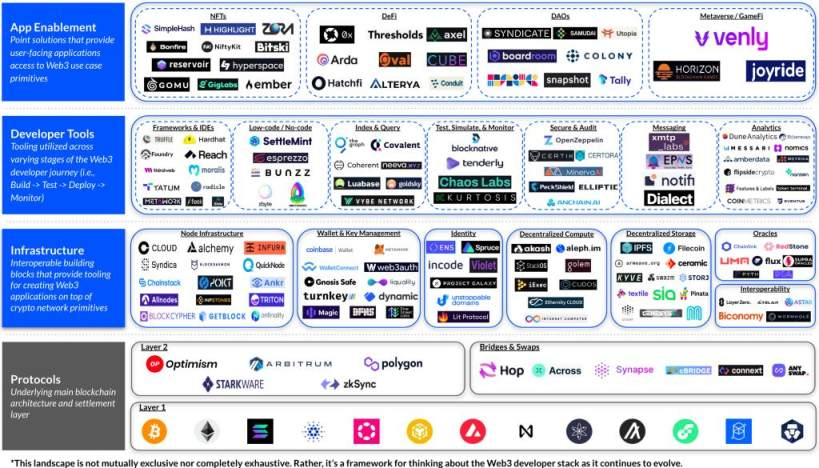
从协议层、基础设施原语、开发者工具再到应用支持层。
尽管比特币和以太坊的兴起,以及 DeFi、NFT、GameFi 和 DAO 等新类别的出现,web3 开发人员在全球 3110 万软件开发人员中的占比不到 1%。
那么为什么如今 web3 的开发者这么少呢?一方面,web3 开发人员可用的工具和基础设施远不如 web2 强大。这只会让在 web3 中开始构建、试验和部署变得更加困难。然而,这一切都在迅速改变,因为每月活跃的 web3 开发人员的数量在 2021 年底创下历史新高。为了支持这种不断增长的意外情况,一个充满活力的团队生态系统致力于简化整个 web3 开发人员的旅程,最终将帮助开启 web3 增长和创新的下一阶段。
在本期的 Around The Block 中,我们将探索不断增长的 web3 开发者堆栈。
Web3 开发人员堆栈
在 Web2 与 Web3 中构建
软件开发是构建计算机程序的过程。给定程序包含三个主要组件:
前端(用户与之交互的内容)
后端(用户看不到的地方)
数据库(存储关键数据的地方)
典型用户通过移动或桌面浏览器进行交互的前端在 web2 和 web3 中基本相同。像 Uniswap 这样的 web3 应用程序看起来与典型的 web2 应用程序相似,因为两个前端大部分都是使用 React 创建的——一个流行的 web 和移动应用程序开发人员框架。
这是 web2 和 web3 不同的地方。使 web3 的定义特征(用户定义的所有权) 成为可能的后端框架和数据库类型是新颖的和独特的。
web2 应用程序在很大程度上依赖于中心化数据库,而 web3 应用程序则建立在去中心化数据库(区块链)之上。这需要全新的后端和钱包等新的原语。
由于数十年的累积开发,帮助创建、部署和维护 web2 应用程序的工具对开发人员非常友好。开箱即用的解决方案、成熟的基础设施、共享代码库和易于使用的框架在很大程度上使 web2 中的构建变得轻而易举。
另一方面,Web3 仍然需要专业知识来与复杂的基础设施进行交互,并且通常涉及许多冗余流程,因为堆栈开发程度较低,使得团队不得不重新发明轮子。也就是说,将帮助下一个 100 万 + web3 开发人员加入的工具正在迅速改进。
让我们逐层(非详尽地)看看不断发展的 Web3 开发人员堆栈(* 表示 Coinbase Ventures 投资组合公司)。
协议层

web3 开发者必须做出的第一个决定是基于哪个区块链协议。基于比特币的构建与基于以太坊的构建完全不同,基于 Solana 与基于以太坊不同。
对于速度更快、成本更低的应用程序,开发人员可能希望基于 Optimism*、 Arbitrum* 等第二层协议。对于需要将价值从一条链转移到另一条链的应用程序而言,开发人员将希望利用 Hop* 或 Synapse* 等跨链桥。
一旦做出了这些决定,开发人员就可以开始整合构建模块,使用户应用程序成为可能。
基础设施原语

开发人员需要弄清楚的下一件事是他们的应用程序最终将如何与底层区块链交互。这就是基础设施原语发挥作用的地方。
节点基础设施—— 节点是应用程序与区块链「发生」交互的地方。一旦用户与应用程序交互,它们是读取区块链状态并向其写入更新的计算机。Coinbase Cloud、 Infura * 和 Alchemy * 等节点基础设施提供商让开发人员可以轻松设置、管理或访问区块链节点,从而为开发人员节省大量时间和资源。
钱包和密钥管理—— 区块链钱包,如 Coinbase Wallet,允许用户管理在 web3 应用程序中执行交易所需的私钥。Web3Auth * 或 Pine Street Labs * 等钱包和密钥管理提供商使开发人员能够在区块链钱包和面向用户的应用程序之间建立安全连接。
身份 ——像 ENS * 这样的协议在应用程序中充当用户的身份。Spruce * 提供框架和工具包,开发人员可以使用这些框架和工具包来验证用户凭据以验证以太坊上的操作。例如,开发人员可以使用 Spruce ID 工具包授权用户使用其 ENS 帐户登录 dApp。此外,像 Lit Protocol 这样的公司提供开发者工具,用于授权使用其代币或 NFT 访问内容、软件和其他数据。
去中心化计算—— 计算资源提供应用程序执行计算任务所依赖的处理能力。目前,大部分网络计算由 AWS 等中心化提供商提供。去中心化计算是向社区拥有的网络的转变,其中计算资源以低成本、无需许可的方式分布。Akash Network 和 Aleph.im 等项目已经出现,提供高性能的点对点计算资源,并针对智能合约和区块链应用程序进行了优化。
去中心化存储—— 将与给定 web3 应用程序相关的每条数据直接存储在区块链节点上的成本很高。web3 开发人员无需将数据存储在中心化数据库上,而是可以对某些数据使用 IPFS、 Arweave * 和 Ceramic Network * 等点对点数据存储协议。例如,web3 博客网站 Mirror 建立在以太坊上,但将实际博客内容存储在 Arweave 上。
预言机—— 对于典型的以太坊应用程序,区块链存储交易历史和「状态」(余额、智能合约和其他变量)。然而,它不能本地存储来自外部源的数据并与之交互——即来自其他区块链的交易历史或「真实世界」数据,如旧金山的天气。这就是像 Chainlink 或 Flux * 这样的预言机出现的地方,将区块链连接到链上和链下数据源。
互操作性 ——存在许多不同的区块链,但很少有能够交换价值和利用跨链信息的能力。LayerZero * 和 Astar Network * 等互操作性协议为开发人员提供 SDK 和 API,以构建可移植且可以与不同区块链通信的 dApp。
开发者工具

在允许应用程序与区块链网络交互的基础设施原语之上,是允许开发人员与上述原语交互的工具。
框架和 IDE — 开发人员框架由其他开发人员创建的代码库组成,使开发更容易。Truffle、 Moralis *、 Tatum 和 ThirdWeb * 等 Web3 框架让开发人员可以利用现有代码进行智能合约应用程序,因此他们不必从头开始构建所有内容。它们还允许开发人员测试和部署应用程序。Foundry 和 HardHat 等集成开发环境 (IDE) 结合了通用源代码编辑器,并将自动化和调试工具构建到一个易于访问的单一界面中。
低代码 / 无代码 —— 这些平台使面向用户的应用程序能够完全通过拖放界面快速设计 / 部署。像 Settlemint 这样的公司为开发人员提供了 NFT 的智能合约模板,以防止 web3 开发人员不得不重新发明轮子。
索引和查询 —— 数据索引器帮助人们定位和访问底层数据库中的特定数据。在 Web2 中,谷歌搜索是最流行的数据索引服务,它允许用户以亚秒级的响应时间查询存储在在线数据库中的数据。在 Web3 中,去中心化索引服务正在兴起,以帮助 dApp 开发人员获取、处理和查询区块链数据。Graph Protocol *、 Covalent * 和 Coherent * 都提供 API,用于从去中心化数据存储提供商和 EVM 兼容的区块链中提取和使用数据。
测试、模拟和监控—— 在 web3 应用程序发布之前测试和模拟它们是很重要的。像 Tenderly * 和 Kurtosis * 这样的公司提供了各种工具来模拟智能合约和交易,以及调试任何问题的工具。Blocknative * 提供仪表板和工具,用于在交易提交到链上之前对其进行监控。
安全和审计 —— 鉴于智能合约利用的潜力,这些平台允许开发人员将安全和审计最佳实践应用到他们的应用程序中。OpenZeppelin *、 Certik * 和 Certora * 都为开发人员提供了各种服务、框架和监控工具,以减轻潜在的安全风险和漏洞。
消息传递 ——Web3 应用程序通常涉及向最终用户发送各种通信。例如,加密钱包可能希望向用户推送有关交易确认的警报。 XMTP Labs * 和 EPNS 等公司正在构建安全的消息传递协议和去中心化通信网络,以推动用户参与并为 Web3 应用程序中的这些通知提供动力。
分析—— 有许多平台和服务可以让开发人员探索、分析、提取和可视化区块链数据。Dune *、 Nansen * 和 Messari * 均提供各种 API 和报告功能,以在 web3 应用程序中构建数据可视化功能。Flipside Crypto * 提供 SDK(软件开发工具包)和 API,以创建和共享有关各种加密项目的数据见解。
应用支持层

应用支持层将上述所有层与特定的 web3 用途联系起来。NFT、DAO、DeFi 和游戏都有自己定制的开发者解决方案。
专注于 NFT 的工具为创建和管理 NFT 资产提供了基础设施。DAO 工具为 DAO 创建(Syndicate *、Samudai *)、治理(Snapshot *)和资金管理(Utopia Labs *)提供解决方案。专注于 DeFi 的工具提供 API,让开发人员可以访问各种 DeFi 原语。专注于游戏的工具(Venly *、Joyride *、 Horizon Blockchain Games *)为创建虚拟世界和基于区块链的游戏提供解决方案。
不断发展的开发堆栈
上面提到的协议、基础设施和开发人员工具构成了新生的、但不断发展的 web3 开发人员堆栈。web3 的模块化和可互操作性意味着堆栈可以以无穷无尽的方式组合以创建新的和有趣的应用程序。
虽然我们强调的框架和层可能保持不变,但我们继续看到新的开发人员工具原语出现,并预计整个堆栈在未来几年将发生巨大变化。





