Source: Wall Street News
As AI models evolve into the era of massive 'Agents,' the bottleneck in data centers is gradually shifting from computing power to 'connectivity.' A fundamental infrastructure revolution transitioning from copper cables to fiber optics is now in full swing.
On the second day of the Computex conference in Taipei, Taiwan, Marvell Chairman and CEO Matt Murphy, a leader in AI custom chips, optical communications, and data center interconnect, delivered a keynote speech. NVIDIA CEO Jensen Huang made a surprise appearance as a special guest. The two leaders at the pinnacle of AI computing power and network connectivity shared the stage, bringing the deep strategic partnership between their companies into the spotlight. This joint appearance quickly became the highlight of the exhibition so far.

(Marvell CEO Matt Murphy and Jensen Huang in conversation at Computex)
Taking the stage, Jensen Huang set the tone with one sentence: "Ladies and gentlemen, the next trillion-dollar company" – he was referring to Marvell. The audience erupted in applause. As reported by Wall Street News, this reflects the deep alliance formed months earlier when NVIDIA announced a strategic investment of $20 billion in Marvell, and serves as the latest testament to their joint efforts in the AI data center infrastructure field.
Following the release of its latest quarterly earnings, the market is intensely focused on Marvell's position in the AI supercomputing cycle. In response, Murphy presented impressive results: a decade ago, Marvell's data center business accounted for less than 10% of revenue, but last quarter, that proportion exceeded 75% and is accelerating at an annual rate of about 40%. Based on the latest earnings guidance, Wall Street widely expects its revenue to reach a staggering $16.4 billion next year.
Behind this rapid growth, Huang and Murphy revealed the core investment thesis for AI infrastructure – once the bottlenecks of computing power and memory are overcome, 'connectivity' will define the ultimate system performance. The CEOs' key consensus is:
The next decisive battleground for AI infrastructure is not computing power, not memory, but connectivity. Marvell is at the heart of this revolution.
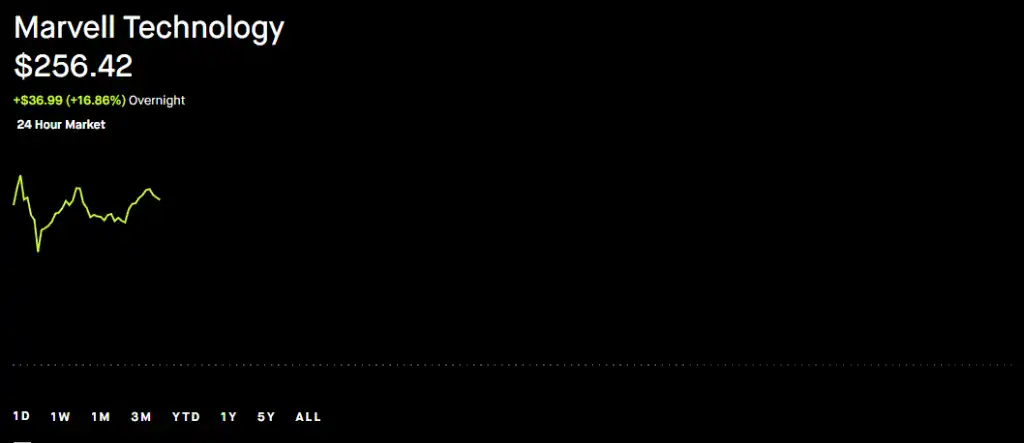
Notably, Marvell's stock surged over 16% in after-hours trading.
At the End of Computing Power Lies Connectivity: AI Enters 'Useful Phase,' Igniting Demand for Infrastructure Interconnect
Why has connectivity become so critical today?
In his speech, Murphy used a clear logical chain to explain why 'connectivity' is the current key constraint:
Bottlenecks in AI infrastructure appear and are overcome sequentially – Computing Power (led by NVIDIA, becoming the first company to reach a $5 trillion market cap) → Memory (the memory sector recently saw three new trillion-dollar companies) → Connectivity (happening now).
"Global top-tier hyperscale cloud service providers are re-architecting their entire network infrastructure. They realize that scaling AI infrastructure has become the primary connectivity challenge," Murphy said. "This isn't just my opinion; it's feedback from our largest customers."
Jensen Huang offered the most straightforward business logic during the conversation:
"Useful AI has arrived; it's profitable now, and tokens are profitable. When token production is profitable, everyone wants to produce more tokens. That's why demand for Marvell is so strong, and why our demand is so strong."
Huang pointed out that current AI is moving towards an 'Agent' model, a new computing paradigm that requires breaking tasks apart and distributing them across massive computing clusters. "When you decompose a computing problem into many parts and distribute it across the entire data center, the one thing you cannot do without is connectivity." Huang was lavish in his praise for his partner, even stating on stage: "Ladies and gentlemen, (Marvell) this is the next trillion-dollar company."
Murphy added that a single processor can no longer handle AI workloads; the future requires millions of processors working together.
"Scaling compute is fundamentally a connectivity challenge. The industry has solved the compute bottleneck, is solving the memory bottleneck, and the next bottleneck limiting infrastructure scale is connectivity."
"Use Copper Where You Can, Use Optics Only Where You Must"
The most market-significant part of the conversation between Murphy and Huang was their assessment of the timeline for the transition from copper cables to fiber optics.
Huang's strategic framework was blunt: "Use optics wherever you must, use copper wherever you can."
He explained that copper cables have physical limits in bandwidth and transmission distance. Before hitting those boundaries, copper is a simple, low-cost, practical choice. Once past that critical point, fiber optics takes over to handle expansion needs between racks, between data centers, and across data centers.
His core conclusion:
"For the next 5 to 10 years, we will still use a massive amount of copper, and also a massive amount of optics. These data centers are now part of the infrastructure."
This judgment of "copper and optics coexisting, each within its boundary" means that Marvell, being one of the few companies offering complete solutions in both directions, is poised to benefit continuously in both copper and fiber optic fields.
Behind the timeline for the copper-to-optics switch are unavoidable physical laws. Murphy explained: Copper transmission distance is inversely proportional to bandwidth; each time bandwidth doubles, transmission distance halves. The fastest mass-produced systems today achieve single-lane rates of 200Gbps, corresponding to a copper cable length of about 2.5 meters, while a rack is about 2 meters high – considering internal wiring, 2.5 meters is near the limit. "When we go to 400Gbps, copper will not be able to connect the entire rack. The Copper Wall is moving, and it's starting now." Every time the Copper Wall moves one step to the right, the number of connections increases by at least an order of magnitude, directly igniting demand for optical communications.
To address this physical limit, Marvell is heavily investing in CPO (Co-Packaged Optics) technology, bringing fiber optics directly into the package adjacent to the compute chip to solve density and power challenges. On the day of the conference, Marvell officially launched a new 100T Ethernet switch designed for AI data centers with industry-lowest power consumption, and showcased a 51.2T switch based on CPO, completely eliminating copper traces at the board level.
"This isn't some future concept; it's landing now," Murphy said. Once optical interconnect completely breaks the distance limitation, future data centers will no longer have rigid physical boundaries between compute and memory. Infrastructure will be able to dynamically combine at massive scale based on the needs of AI models.
NVLink Fusion Builds Heterogeneous Ecosystem: Marvell Aims to Be the 'Switzerland' of the AI Era
To address the extremely complex network architecture needs, NVIDIA previously made a strategic $20 billion investment in Marvell. Their collaboration is expanding into multiple dimensions including optical communications, silicon photonics, and NVLink Fusion.
The emergence of NVLink Fusion aims to address the customization pain points of Cloud Service Providers (CSPs). Huang explained that while cloud vendors design their own custom chips (ASICs), they still want to integrate into NVIDIA's system architecture.
"You don't have to buy everything from us, just buy a piece. By fusing NVIDIA's technology platform with Marvell's technology solutions, we can essentially build a disaggregated, distributed, and heterogeneous data center."
In such an ecosystem, Marvell has found its irreplaceable niche. Murphy emphasized Marvell's neutral and critical position:
"We work deeply with compute companies, and we work deeply with memory companies. In many ways, we are like the 'Switzerland' of the industry, working with everyone."
Marvell CEO's Computex Speech, Marvell CEO's On-Stage Conversation with Jensen Huang, and Marvell CEO's Conversation with ASE CEO Full Transcript (AI-Assisted Translation):
Host: Please welcome Marvell Chairman and CEO Matt Murphy.
Marvell CEO:
It's great to be here on the opening day of Computex, and great to be back in Taiwan.
My first time here was nearly 30 years ago, on my first business trip to Asia. I remember visiting several of the core technology companies here. Back then, they were mostly young, small companies, startups. Today, those companies are among the most important technology leaders in the world. I've had the chance to come back many times since, witnessing Taiwan's continuous growth.
Taiwan has become one of the world's leading technology centers. Today, a significant portion of the future of AI infrastructure is being built right here. Let me ask you a question: What ultimately determines the performance of AI infrastructure?
You might think of processors, GPUs, XPUs, or the process node used to make the chips – 3nm, 2nm, and the upcoming A14, A16. These are good metrics, reflecting the speed, efficiency, and density of compute. AI workloads are indeed incredibly demanding on compute, but that's not the whole story.
You might say, what about memory? AI workloads are also incredibly demanding on memory. Larger capacity, higher bandwidth, that's all important, absolutely critical, no question. But that's still not the defining characteristic of system performance.
Because a single processor, no matter how fast, no matter how much memory, is nowhere near enough to meet the demands of today's AI workloads. You need tens of thousands, and eventually millions, of processors working together, forming a massive compute engine.
That's why, at that scale, compute is fundamentally a connectivity challenge. And the architecture and characteristics of that connectivity are increasingly becoming the key determinant of overall system performance.
We've seen incredible breakthroughs in accelerated compute, and the emergence of high-bandwidth memory to meet the AI challenge. But what I'm here to tell you today is: The next wave of major innovation and scale will come from the connectivity technologies underlying these systems.
And as those connections transition from copper to optics, they will unlock entirely new architectural possibilities.
So today, I'll explain: why connectivity is becoming one of the most critical characteristics and challenges of the AI era, and what this technological shift means for optics.
This isn't the distant future; it's happening now – this year, next year, we're already in the ramp. At Marvell, we've been preparing for this moment for nearly a decade. We very intentionally, very deliberately, built this company around the infrastructure required to move data at massive scale.
To understand why we made that strategic bet, let's go back ten years – right around when I joined Marvell as CEO.
Before joining Marvell, I spent 22 years at a company called Maxim Integrated Products, a leading analog semiconductor company. Working at an analog chip company is unique: your products go into virtually every end device, every electronic system, every market in the world.
So over those two decades, I lived through the development of virtually every major technology trend – from the personal computer, to the laptop, to the digital camera, to the smartphone, and ultimately to the data center. I watched wave after wave of technology reshape the entire industry.
So when I joined Marvell, I didn't start by thinking 'what products do we have.' I thought about where the industry was going. And even back in 2016, it was pretty clear to me:
The next major growth cycle for the global semiconductor industry would be driven by the data platform companies. The same companies then as today – Google, Amazon, Microsoft, Meta. More specifically, the semiconductor technology those markets would need – to move data, store data, process data, secure data, and at massive scale. That was our vision at the time.
But when I looked at our product portfolio then, there wasn't much that really fit. That was a problem. Ten years ago, less than 10% of our revenue came from data centers, just a few hundred million dollars. And over 60% of our revenue at the time came from consumer electronics.
It was an exciting time – we did virtual reality headsets, gaming consoles, streaming devices, wearables. In fact, one of our proudest achievements back then was that Marvell chips were designed into the world's first WiFi-connected Barbie Dreamhouse. That was our big design win.
It's true. My first week at Marvell, the team made a point of showing me this amazing design achievement.
That's where we were. We had a vision, but there was a huge gap between that and where the industry was going. But we had conviction. And because of that, we decided to bet the entire future of Marvell on it.
To do that, we needed a clear vision. The vision at the time was simple –
By the way, ten years later, that vision hasn't changed: to build a premier pure-play semiconductor solutions company focused on data infrastructure.
Back then, 'data infrastructure' wasn't a widely recognized market category. It was our term to describe the infrastructure that would move the world's data, store the world's data, process the world's data, and secure it.
But as I said, we weren't really in that business yet, and frankly, we didn't have much to work with. We had some building blocks as we got going, but nowhere near enough.
So the team and I came to a conclusion: some of the capability we would have to build organically, and some we would have to acquire through strategic M&A. And we had to be focused. Because in a transformation, it's not just about deciding what you're going to do; it's equally important to decide what you're not going to do.
With that strategy, we got to work.
We built Marvell systematically around that vision, not a single move, but a series of deliberate choices. We looked for the best assets in the most important markets – the best companies, the most advanced technologies, the strongest teams, the most established market positions.
First, we divested businesses that didn't fit the strategy, some examples you can see. Then, we quickly acquired Cavium to strengthen our compute and networking capabilities, that was 2018.
In 2019, we divested the WiFi business – focus again; and we acquired Avera, establishing our custom chip business, and through an acquisition of assets from Qualcomm, further enriched our connectivity portfolio.
In 2021, we acquired Inphi for $10 billion, our largest acquisition to date. With that, we brought world-class data center connectivity technology into the company.
That same year, we also acquired Innovium, adding high-end data center switching capability to the portfolio.
Then we paused on M&A for a few years to digest, integrate, and focus on unifying and expanding the overall technology platform to address the data infrastructure opportunity.
But in the last 12 months, we re-engaged the M&A engine. We divested the automotive Ethernet business – focus power again – and we acquired Celestia AI for its photonic architecture technology; and we acquired XCON to enhance large-scale switching capability.
Adding it all up over the past decade: we invested about $22.5 billion through M&A, we invested about $18 billion organically inside Marvell on platform development, and we divested about $4.5 billion of assets.
Net, we've invested about $36 billion in this platform.
Now let me show you some of the results of those investments.
First, we've built a remarkable technology platform, and it all starts with leading-edge process nodes.
Becoming a process node leader was actually one of our most important decisions. In the past, Marvell, Cavium, and some of the companies we acquired, were 'fast followers' – meaning, one to two nodes behind in process technology. That was largely driven by scale; typically companies that take that approach do so for that reason.
But after integrating those businesses, we made a decision: if we were going to compete in data infrastructure, we had to be at the absolute cutting edge of technology, no choice.
Here's a little-known fact. Marvell skipped 7nm entirely, a full node jump. We went from 14nm and 16nm, all the way to 5nm in one step. I mean, nobody does that, nobody takes that risk or makes that bet, but we did, and it worked. Worked incredibly well, actually flawlessly. Our engineering team executed that transition brilliantly. So in early 2020, we taped out our first world-class IP platform, fully integrated with die-to-die interfaces, custom SRAM, high-speed SerDes, all of that.
Serdes is a great example of how we built this platform. It brought together Marvell's own core engineering strength with incredible talent from companies like Avera, Inphi. Today, that's an organization of 1,500 people within Marvell, among the largest and most capable in engineering scale and capability. To support the process data piece of our mission, we partnered deeply with the world's leading hyperscale cloud providers to build a world-class custom compute platform. That business has served us incredibly well.
In store data, we built a full portfolio, including storage controllers, CXL-based memory poolers, and near-memory compute. But where we've gone all-in is on move data. That's where our high-speed connectivity portfolio comes in. Today, across Marvell's data center business, the vast majority of revenue actually comes from connectivity – from high-speed optical interconnect inside the data center, to long-haul optics between data centers, to high-speed switching infrastructure.
So today, we are the undisputed leader in connectivity. Looking back at what we built, and where the market ultimately went, I think the results speak for themselves. Back in 2016, Marvell was a $2.3 billion company. After we started the transformation, the company doubled in size in the first five years, to $4.5 billion in revenue. **In the next five years, our growth accelerated further.** Based on the Street consensus for the year we are in now, we expect to grow about 2.5x over that last five years, reaching $11.4 billion.
And in recent years, if you look, Marvell has been growing at about 40% annually. So the growth rate has actually been accelerating over the last few years. **So at this point, Marvell is in a full sprint. Based on the outlook we shared on our earnings call last week, the Street consensus has moved up, expecting us to do $16.4 billion in revenue next year.
As I said earlier, when we started this journey, data center was less than 10% of our revenue, and we bet the entire company on it. **Last quarter, it was over 75%, and growing very fast.** So we are a very different company than we were, and that strategic vision has largely been validated. But we are still in the early stages of this infrastructure build. The next phase of opportunity lies ahead. We're going to see a different set of new requirements, which brings us back to connectivity. Over the last few years, as AI placed new demands on infrastructure, we've seen the industry break through one major bottleneck after another.
First, the compute bottleneck. The industry needed a massive step function in compute to support modern AI. NVIDIA has contributed incredibly in leading that revolution, and along the way became the first company to reach a $5 trillion market cap. Congratulations to Jensen and his entire team here today, it's truly an extraordinary, extraordinary achievement. Next came the memory bottleneck. Larger models required massive amounts of memory and bandwidth, and the memory companies stepped up to expand capacity to meet that demand. Just recently, we've seen three new trillion-dollar-plus companies emerge in that market. But the bottleneck is shifting again. Now, connectivity will determine the performance limits of infrastructure, just like compute and memory did. And the industry will come together to meet this challenge.
This isn't just me saying it; it's what we're hearing from our largest customers. The world's largest hyperscale cloud providers are re-architecting their entire network infrastructure. They realize that scaling AI infrastructure is now the primary connectivity challenge. As inference models, mixture-of-experts architectures, generative AI continue to evolve, more and more data needs to be moved across the infrastructure, with higher bandwidth and lower latency requirements. And the workloads are no longer confined to a single data center.
What do you do? They need to build larger data centers, or entire campuses of data centers, and high-speed interconnect between all of them. So connectivity becomes the key enabler to scale compute. Our customers are increasingly realizing that optics is the future. They want industry leaders like Marvell to help them build bigger, faster networks, at scale. Looking across the semiconductor industry, at the leading companies enabling this infrastructure build, you can see clearly, each of us is focused on a different part of the infrastructure.
You see that in the revenue mix of these companies. Some companies are compute-centric, meaning the vast majority of their revenue comes from compute, a small portion from connectivity, but the core is compute. That's obviously a critical part of the technology stack, and it's why that part of the market has produced several multi-trillion dollar companies. Then there are companies focused on memory, again, those are all trillion-dollar-plus companies today, incredible.
Marvell is different; we are unique. Today, the vast majority of our company's revenue actually comes from connectivity. We built the entire company around moving data. And today, the vast majority of our revenue does indeed come from connectivity. That spans a broad set of technologies. Even the portion of our revenue that comes from compute – as you can see – is fundamentally because customers embed our connectivity technology into their compute engines.
This gives us a unique position and perspective in the current technology transition. It also allows us to have very different partnership dynamics with other participants in the ecosystem. We partner deeply with compute companies, and we partner deeply with memory companies. These are highly strategic relationships. In many ways, we are like the Switzerland of the industry; we work with everyone.
One of the best examples of the role Marvell plays in this ecosystem is the recently announced expansion of our strategic partnership with NVIDIA. As part of that announcement we made a few months ago, NVIDIA invested $2 billion in Marvell, and we are expanding our collaboration across multiple dimensions, including optics, photonics, and NVlink Fusion. I'm thrilled to announce that Jensen himself is here today. He'll join me on stage, and we'll spend a few minutes talking about this partnership and where AI infrastructure is going next. Now, please welcome Jensen Huang to the stage.
Jensen Huang: Hey, brother.
Marvell CEO: How you doing, Jensen? You good?
Jensen Huang: Wow, this stage is huge, I had to run a long way to get up here.
Marvell CEO: You caught your breath? Okay? Alright, let's get started.
Jensen Huang: Great to see you.
Marvell CEO: Hahaha, there we go. Congratulations on the incredible kickoff of GTC yesterday, you guys are on fire this week.
Jensen Huang: Thank you, thank you.
Marvell CEO: You probably heard some of what I was just saying – today we're talking about this topic of connectivity.
Jensen Huang: Ladies and gentlemen, the next trillion-dollar company.
Marvell CEO: Wow, that's exciting! Let's do it together. Yes, together. But the starting point for all of this goes back to the broader dynamics in AI infrastructure right now. From a big picture perspective, how do you view this extraordinary moment? Customer demand has gone through the roof, what role does connectivity play in that? And what kind of interconnect technology is needed?
Jensen Huang: That's a great question. I said yesterday, Useful AI is here. That's why your company's demand is surging, and it's why our demand is surging. And the new computing model that makes this possible is called Agents. These agents have a specific computing platform and computing model – a disaggregated, distributed architecture. Once you decompose a computing problem into many parts and distribute it across the entire data center, connectivity becomes indispensable. That's why Matt is doing so well, and that's why Marvell is so important. By distributing and disaggregating the compute, allowing tasks to run across these enormous clusters, we're able to aggregate all of that computing power, memory, and bandwidth – and what makes that possible is connectivity. Yes, we've seen it. And, you know, you can consider them the next trillion-dollar company.
Marvell CEO: We've got some work to do, but we're on the right path. Thank you, Jensen. Let's talk about scale. We used to talk about interconnecting tens of GPUs, CPUs, XPUs, now it's scaling to thousands, and at some point in the future maybe even millions. As compute scale and connectivity scale continue to grow, we mentioned concepts like agents. How do you see these applications across data centers, within data centers? How do you view the role of large-scale connectivity there? And what technologies are most critical for that?
Jensen Huang: Fundamentally, the agent computing model requires an orchestration system that allows large language models and compute resources to think, reason, and formulate action plans. But at the same time, agents also have to be able to use tools – like browsing the internet, accessing memory, dealing with long-term memory and short-term working memory. All of that requires tremendous connectivity.
Also, look at how we introduced Vera Rubin to understand the logic: Hopper was for training; Grace Blackwell introduced NVLink 72, our first scale-out architecture, it introduced the idea of ultra-fast inference for gigantic mixture-of-expert models (MoE models), so Grace Blackwell was for inference; and Vera Rubin is for running agents. That's why the Vera Rubin system includes not just the Vera Rubin thinking AI, but also a Vera CPU for orchestration, and a Vera CX for storage acceleration, managing long-term memory.
The way I think about these systems is: sometimes a cloud service provider (CSP) might want to design their own custom chip. In that case, we can also work together on NVLink Fusion. That technology makes it possible to adopt a unified system architecture – building on Vera Rubin, incorporating your semi-custom chips, a whole bunch of interconnect, silicon photonics and optics, to build what is essentially a disaggregated, distributed, heterogeneous data center. That's the idea.
And their system architecture is completely consistent, the networking can borrow heavily from NVIDIA's technology stack, the CPU can be Vera, and also borrow heavily from Marvell's technology stack. So, NVLink Fusion is about fusing NVIDIA's technology and platform with Marvell's technology and solutions – that's why it's called 'Fusion.'
Marvell CEO: Yes, speaking of our partnership, we've been working together for a long time. To formalize it with an investment, we're really grateful. It means a lot to us, and we're honored.
Jensen Huang: You know, who doesn't love making money? It feels good to give.
Marvell CEO: Since the investment, it's been going great.
Jensen Huang: I love being rich. Just give all my money to Matt and watch him make me money.
Marvell CEO: Ha, that's exactly what I do every day. But I think the things you mentioned, we're actually delivering on them – NVLink Fusion, the collaboration in optics. I think this agent era and your new platform are a perfect match. The idea of NVLink Fusion, we actually had it a few years ago, right? But it was a bit ahead of its time. Now I want to ask if you agree: combining your platform, with our customers' needs for custom networking and compute, plus the ability and need for system interoperability and collaboration – now is the perfect time for Marvell and NVIDIA to empower customers together, giving them the flexibility they need, leveraging the agent era opportunity, and scaling our platforms together.
Jensen Huang: Yes, I think at the end of the day, if customers want to buy only NVIDIA, that's perfectly fine. But if customers really need to design their own ASIC, we're happy with that too – as long as NVIDIA gets into their data center. So customers don't have to buy everything from us, they just have to buy a piece. We're happy to support you, and support the customer.
Us two together, we bring a general-purpose, highly efficient, well-designed system, based on Vera Rubin, and then you can also extend it with specialized pieces on top of that. That's why your customers are our customers – NVIDIA is in AWS, Marvell is in AWS; NVIDIA is in all the clouds, and it's really wonderful to see Marvell also expand to these different clouds.
Marvell CEO: Okay, thanks. One last question for you.
Jensen Huang: Leave me some business, okay?
Marvell CEO: Listen, we're your best salespeople right now.
Jensen Huang: I'm your best salesperson.
Marvell CEO: Ha, partnership works. Last question: A big part of my talk today is about the transition, especially from copper to optics inside the rack. Obviously that's not going to happen overnight, it takes time, different use cases have different timelines. How do you see that progressing right now? The move from copper to optics, and our potential collaboration there?
Jensen Huang: We should use copper for as long as we can, as much as we can. But copper has its limits – it has a bandwidth-distance wall. So the right strategy is: use copper to scale out as much as you can, until you hit the wall; and then scale up, scale out, scale across with optics. So it's: use optics wherever you must, use copper wherever you can. I think that crossover is going to be for a long time.
The bottom line is: for the next 5 to 10 years, we will still use a massive amount of copper, and also a massive amount of optics. These data centers are now part of the infrastructure.
The reason I say Useful AI is here is because AI is profitable now, token production is profitable. When token production is profitable, everybody wants to produce more tokens – that's why Marvell's demand is so strong, and that's why our demand is so high. Because agents are using tokens everywhere, everybody wants to produce more.
Marvell CEO: Okay, I think you just did the rest of my presentation for me. If you want to do the rest of my demo, go ahead.
Jensen Huang: Everybody, these slides are beautiful. You just sit there, I'll do it – haha.
Marvell CEO: Okay, I'll hand it over to you. Alright Jensen, great to see you, brother, take care.
Jensen Huang: Okay, thank you everyone.
Marvell CEO:
Okay, awesome, as always great to have Jensen here. Okay, we've talked a lot about connectivity, Jensen and I just discussed it, so let's dive in a layer deeper.
AI infrastructure spans distances from hundreds or even thousands of kilometers between data centers, down to just millimeters inside a package. Each distance requires a different solution.
These are different technologies, different engineering teams, completely different groups of experts, and in many cases, different supply chains. So these aren't just simple variations of the same problem; these are fundamentally different engineering challenges, and we'll go through them one by one.
Okay, let's start with the longest distance. Jensen mentioned this – it's the scale of inter-data center connectivity.
Today, the major cloud providers have hundreds of data centers around the world, and all of them need to talk to each other. This is fundamentally a long-haul connectivity problem. We're talking about links that can span hundreds or even thousands of kilometers. This requires a very special, very complex technology called coherent modulation. At its heart is a specialized digital signal processor (DSP).
It's designed to move massive amounts of data over fiber cables over extremely long distances, with very high reliability. There are only a handful of companies in the world that can make these coherent DSPs, and we are one of them. Marvell has been leading in this technology for many generations. We produce optical modules that integrate all the electronics needed to drive and modulate the lasers, and enable the long-haul data movement.
I brought a little something in my pocket to show – not a chip this time, but an optical module.
This is our coherent optical module, an incredibly complex piece of engineering. At Marvell, we build the entire module ourselves, this is us. It contains an advanced-node CMOS digital signal processor (DSP) – that DSP alone is one of the most complex chips we design at Marvell. But it also integrates our fourth-generation silicon photonics technology, right inside. We've been developing and shipping this technology in silicon photonics for a decade. Plus, it contains broadband analog components of our own design, fabricated in silicon germanium.
Marvell pioneered this technology a decade ago at 100Gbps.
Then moved to 400G, and now shipping 800G in volume. Later this year, we'll sample the world's first 1.6 Terabit 2nm coherent optical solution, and the timing couldn't be better – bandwidth demand has never been stronger.
Okay, now let's move inside the data center. These are huge facilities, spanning hundreds of meters, filled with rows and rows of compute server racks.
Each rack typically has a switch at the top, and servers connect to it. Those rack-level switches connect to aggregation, then to core switches, building out the network fabric that ties the entire data center together. Everything is connected with fiber cables. Again, optical modules drive the data movement over those fiber cables, but this time with a different modulation scheme.
Instead of coherent, we use a more power-optimized modulation technology called PAM4. The two key semiconductor solutions in this market segment are the PAM4 chipset inside the modules, and the cloud switching infrastructure that ties the entire data center together. Marvell does both.
Starting with the PAM4 chipset, we built the industry-leading PAM4 DSP solution, and the accompanying high-speed analog components including transimpedance amplifiers (TIAs) and laser drivers.
By the way, those components are also fabricated in silicon germanium. We've led the industry through every major iteration of PAM technology – from 50G, 100G, to 200G, 400G, to 800G. Last year, we started volume production of Marvell's 1.6T 3nm PAM4 solution.
In Ethernet switching, Marvell also has a complete portfolio from 12.8 Terabit to 51.2 Terabit. Today, we launched a new 100T Ethernet switch, designed for AI data centers, with industry-lowest power.
(Audience cheers) Wow! Hahahaha
This is a special launch we held back for Computex, we announced it today.
So, taken together, we offer an end-to-end solution for intra-data center connectivity.
Now let's go inside the rack. The goal here is to connect as many processors together as possible in a full any-to-any architecture. That means every processor can talk directly to every other processor. Jensen talked about this too. The first company to bring this architecture to market was NVIDIA, with the NVL 72 – named for the 72 GPUs interconnected in a single rack.
This requires a completely different kind of connectivity: a new type of switch, and the ability to move ultra-high-speed signals over a copper backplane inside the rack. Today, this domain is dominated not by optics, but by copper, and the core difference is electrical SerDes technology, not optical.
Marvell today has leading 200Gbps technology, and we've demonstrated future 400Gbps technology over the past few years.
We're integrating that SerDes technology into customers' custom chips, XPUs, and into our own high-end scale-out switches.
Okay, now let's go all the way inside the package. Here, we're not talking meters, but millimeters. You might not think of this as a connectivity challenge, but most advanced chips today contain multiple chiplets inside the package. When using 2.5D or 3D packaging, this is fundamentally a connectivity technology, allowing those chiplets to be placed very close together inside the package,
and communicate over ultra-high-speed short-reach die-to-die interfaces. Marvell has leading die-to-die SerDes technology and advanced packaging capabilities, helping customers build the most complex, most unique multi-chip products in the industry.
So you can see, connectivity for AI data centers requires an incredibly broad set of technologies. Different distances require dramatically different solutions, and Marvell has the industry's most complete portfolio, covering every node from millimeters to kilometers.
It turns out, having all of these capabilities under one roof is very rare, maybe even unique. Typically in competition, we face different competitors in each of these domains across different distances. But that's our uniqueness – we are a one-stop shop, and we are the leader across the entire connectivity stack.
Which brings us to the next big challenge facing the industry.
You probably noticed as I described these different solutions on the last few slides, they were for different distances, and right now some of those connections are optical, and some are electrical. That's actually determined by distance.
The connections on the left side of the chart are optical today, meaning they use fiber cables carrying light signals, with complex electronics on either end to drive and modulate the lasers that transmit that light.
The connections on the right side of the chart are electrical, using copper cables, copper traces printed on circuit boards, or even tiny copper wiring inside the package. The common theme is copper.
And in the middle of the chart, you can see that wall – the Copper Wall. That wall is defined by the maximum distance a copper-based signal can travel, before you have to switch to optical connectivity.
This distinction is very important, because copper is simple, low cost, and as Jensen said, you should use it wherever you can, very practical. But optical is more complex, requires lasers, photonics, and precision electronics, it's harder to implement – but it's essential.
What I'm here to tell you today is: the Copper Wall is about to move. It's going to move again, and it's going to cover the rack itself. That will ignite demand for optics. An incredibly difficult engineering challenge is coming...
So, why is this happening? It's not anyone's personal preference; it's physics. Copper cable signal distance is inversely proportional to bandwidth. Every time you double the bandwidth, you have to cut the distance in half. For example, the highest rate in production systems globally today is a single lane at 200 gigabits per second.
At that bandwidth, copper cable length is limited to about 2.5 meters. By comparison, a system running at 100 gigabits can use about 5 meters of cable, and a rack is about 2 meters high. Considering all the internal wiring needs in a rack, 2.5 meters is at the limit. So when we go to 400 gigabits, copper will no longer be able to connect the entire rack.
That wall is coming, and it's now. Looking forward, even connections inside the rack will transition to optics, and the whole industry knows this is coming. So we've been preparing for this moment – not just Marvell, but the whole industry. By the way, you see it in the rapid expansion here in Taiwan and across the supply chain. The impact is actually enormous, because every time that wall moves one step to the right, the number of connections increases by at least an order of magnitude.
As I mentioned, this is triggering explosive demand growth, and the optical supply chain needs to scale massively and get ready. But we've seen this before, right? I mean, twenty years ago – I remember it clearly – the state of the art inside data centers then was 10 gigabits per second, 10G, and we used copper everywhere inside the data center. Optics then was only for very, very long distances.
It was essentially a telecom technology. But when that wall moved, the optics industry really stepped up. Today, every hyperscale data center in the world uses optical connectivity. And as we saw in that transition, it required entirely new solutions. You couldn't take the high-power approach from telecom, that's where PAM4 technology came in. PAM4 is optimized for power, density, and reach, completely tailored to the specific needs inside the data center, and Marvell was one of the core innovators there. So, as optics moves into the rack, we're about to see the same wave of innovation, and that brings us to a technology called **Co-Packaged Optics (CPO)**. You hear about it a lot now, let me walk you through it.
CPO is a technology that brings the optical connection all the way into the chip package itself, right next to the compute – whether that's a custom compute chip or a switch chip. The fundamental problem we solve with CPO is density and power. Remember, the number of connections inside the rack is about 10x the number of connections between racks. So, if we tried to just take the kind of optical technology used between data center racks and plug it in here, the power isn't there, the physical space isn't there, you simply can't fit all those standard optical modules and cables in.
It's impossible. So the whole industry has been inventing this concept of co-packaged optics, bringing the fiber directly into the package, and tightly coupling the electronics that drive those fiber signals with the custom compute chip or switch chip. This is a huge change, and the hard part is you need to bring together some of the most advanced technologies in the chip industry: leading-edge CMOS process, silicon photonics, advanced packaging, optical interconnect, all integrated into a small, highly integrated system.
The complexity is high, but it's the only way to continue scaling bandwidth, break through the copper limits I mentioned earlier, and also reduce power. This is where the industry is going, and it's one of the reasons Marvell has been investing in silicon photonics, optical DSPs, and all the related analog broadband components for over a decade. Plus all the advanced packaging technology needed to make it happen, all of which ultimately needs to come together in CPO. So, folks, this isn't some distant future; it's happening now. In fact, I brought a couple of physical examples from Marvell, let's do a quick show-and-tell. Okay, over here, is a traditional Ethernet switch.
This is our newly launched 100T Teralynx switch, and you all are actually the first to see it in person. You can see the switch chip in the middle of the board, copper traces inside the PCB carry the signals to the front panel, right here, where all the optical modules plug in. Now look over here, this is a CPO-based switch. Notice there's still a switch chip in the middle, right in the center of the package die. This one is our 51.2T switch, and around the edges are 16 3.2T optical engines.
16 times 3.2, gives you 51.2. So now the fiber is connected directly to these optical engines, instead of to the front panel. We've completely eliminated the copper traces on the PCB, the light comes straight out of the package. This is an incredibly complex piece of engineering, very exciting to be able to show it today. Okay, co-packaged optics is real, and the industry is scaling to meet the challenge. As we've seen time and again, every time we hit a physical wall, we break through it with technology.
And innovation. In this case, it's replacing copper with fiber optics. Because unlike electrons moving in copper wires, photons traveling through glass can move signals a distance that is essentially independent of bandwidth. So as AI infrastructure demands faster and faster speeds, and needs to scale to larger, more complex systems – now millions of processors connected together, not thousands or hundreds – optical connectivity will increasingly become the de facto solution.
So then, the real question becomes: what does it take to deploy optics throughout the entire AI infrastructure stack? What does it take? First, recognize there is no single technology that covers the entire data center. That's not how this works. There is no one-size-fits-all solution, no shortcuts, no easy path to the finish line. There isn't one single architecture, one modulation scheme, one frequency band, or one unique technology that solves everything.
There is no free lunch. That's why we are exploring multiple different, unique optical paths for every reach. Every technology shown here is optimized for a different design point. Every one of them enables a critical part of the infrastructure, meeting different needs for density, bandwidth, power, and integration across the entire stack. So, optical interconnect is the underlying technology on which the next generation of AI infrastructure will be built.
And Marvell is building the industry's broadest portfolio, with the deepest technology teams. But no single company can drive this transition alone, as Jensen said earlier, it takes the entire ecosystem. So, as I said, technology innovation is great, it's part of the challenge, but not the whole thing. What really matters is scaling to production. If you're still in PowerPoint, proof-of-concept, or press release stage today, it's not enough. Customers need solutions now, and those solutions have to be production-ready, volume-manufacturable, deployable at scale. So Marvell and our ecosystem partners have been at this for a long time, we've shipped hundreds of millions of DSPs.
Through that massive volume, we've accumulated hundreds of billions of hours of field data. That experience is critical, because these products have to work in the real world, not just the lab. But in the world's largest data centers, at very high volumes, reliably for years. That requires standing up the manufacturing ecosystem ahead of time, the capacity and supply chain infrastructure has to be built.
And ready before the demand arrives – that's why the ecosystem is so important, and by the way, it's especially critical here in Taiwan. In Marvell's journey, one of our most important partners has been ASE (Advanced Semiconductor Engineering). ASE is one of the world's leading semiconductor manufacturing companies, with over 100,000 employees, operations across Asia and globally. For decades, it has enabled virtually every major technology transition we've seen in the semiconductor industry.
And leading ASE through this current transition is someone I know very well. He's spent over 25 years helping shape this company and the entire industry. Today, I'm incredibly honored to invite my next speaker to the stage, Dr. Tien Wu, CEO of ASE Group. Tien, please come up. Thank you. Tien, how are you?
Marvell CEO:
Great to see you. It's an honor to share the stage with you. We've been working together a long time. You know, when I became CEO, we had a set of goals. We talked to a lot of suppliers. I knew you from my time as an executive at Maxim long before I was CEO of Marvell, we worked together there too. But one thing, maybe to explain to the audience as well – people sometimes don't realize, as a core supplier in this ecosystem, you have to make bets.
You have to bet on the companies you work with, bet on who you think will succeed. We're very grateful that ASE bet on Marvell early, and based on that decision, we've indeed been successful. I'm curious, could you share your perspective – what was your assessment of Marvell back then, what was your thought process, and where has our collaboration taken us today? Very interested to hear, Tien. Thank you.
ASE CEO:
I think the best way to describe it is: it's an evolutionary process. The initial decision wasn't actually that hard. Marvell is a very good company, with a great reputation, had been through many transitions, so Marvell's track record was there. But when you joined, the product portfolio was a bit aging. First, the business models had to align. ASE is in Taiwan, in manufacturing. The bets we look for are not just betting on your success, we are also betting on partners who can provide insight into what the next-generation architecture and technology requirements will be.
You know, companies in Taiwan invest in infrastructure and capital expenditure 10 years ahead of time, it's a big bet. We focus on one thing only: will the capacity we put in be needed, will it be fully utilized. That's how we make money. So it becomes critical to bet on companies we believe can give us deep insight into the future. That was the core logic behind that decision.
The last ten years, I've been really gratified. Everything we talked about, ten years ago was a dream, just a dream. And today, we are about to volume ship it.
You mentioned 40% growth for the next few years, I believe you can do it. So we are busy expanding capacity for you right now. Yes. And we are also very grateful, we've had a lot of strategic discussions over the last ten years – you made commitments to us, we invested for you, and over time we are producing more and more of your components.
I think that's the short story of how that decision was born.
Marvell CEO:
Yes, it's a great story indeed. Maybe one more question for you – the ecosystem here in Taiwan is very unique, as you said, it takes about a decade of investment to really see the return, and there's a powerful force forming here. How would you describe it to people here? Also, a lot of people globally are watching. What makes this possible here? Why is it so unique? And what makes it hard to replicate elsewhere in the world? Despite globalization trends, how should we view these dynamics? I think it's an interesting question.
ASE CEO:
I think you ask this because there is a lot of competitive force globally, and a lot of uncertainty. My view is, any enterprise needs to have a vision, and long-term consensus at the value level. In terms of business model, the entire Taiwan semiconductor industry is built on capacity utilization and innovation, with technology investment always ahead of industry trends. That is the core value of Taiwan. Whether it's fabless companies, or specific IDMs, they can fit into this model.
Behind that is economies of scale. Taiwan has accumulated forty years of development, transitioning from the PC era to wireless communications, mobile computing, to data centers, and now into high-performance computing (HPC). Forty years of experience has built a workforce of 350,000 semiconductor professionals, and 1.1 million high-tech talents, many of them right here. The value of that experience is incredibly precious. Combined with economies of scale and cluster efficiency – when you think of that workforce with years of experience, when you think of cluster efficiency, when you think of the scale advantage of capacity we've already invested in, these are our core competencies.
But there's one more thing. I think Taiwan, for better or worse, has fewer options than other regions like the US. Therefore, for most engineers after graduation, the choices aren't that many. Semiconductors and IT have become incredibly attractive career paths in Taiwan, but that's not necessarily the case elsewhere. Putting all this together, I think this ecosystem is extremely hard to replicate. Not impossible, but it would take many, many years.
Marvell CEO:
Very good, thank you so much. I really value this partnership. We're off, Tien. Thank you, Tien Wu, thank you.
Okay, so as we said, the future of AI and data centers is an all-optical connected infrastructure. You heard him say it himself, this will drive a wave of growth, innovation, scale, and manufacturing. But what does that inevitable future actually look like?
I mean, if you step back, and for a moment don't think about today, but imagine the world a decade from now – it will be a world where a lot of the copper connectivity has disappeared. Imagine, at some point in the future, data movement is completely fiberized. Then, distance is no longer a constraint, and that's a profound shift.
Today's servers, racks, and overall data center architecture are designed around the constraints of distance. Software workloads are actually optimized around those same constraints. But what if distance wasn't a problem?
When infrastructure is no longer limited by distance, how does the architecture itself change? What new capabilities emerge? Let's start with scale-up networks inside the rack. As we discussed earlier, with a full any-to-any connection configuration, we can connect as many processors together as possible inside a rack. Historically, the scale of this domain was limited by the reach of copper connectivity, but with optics, distance is no longer the limit.
Now, we can scale the scale-up domain from 72 or 144 XPUs/GPUs, to 1,000 or more, all connected with optics. The impact on workloads is massive. Today, AI workloads have to be broken into smaller sub-problems to fit into a scale-up cluster, because communication outside that cluster today is much slower, with much lower bandwidth. But an optically connected system can handle workloads that are an order of magnitude larger.
And it doesn't stop there. What happens when optical connectivity extends into the server itself? A modern AI server is built with a certain number of CPUs, XPUs, memory, and network interfaces. They are all integrated into the same system because of distance constraints. CPUs and XPUs need very high bandwidth access to memory, which means they have to be placed right next to each other on a motherboard, connected by copper traces.
But in the future, when those connections are all optical, distance is no longer a problem. We can imagine a fully disaggregated architecture: XPUs in one system, memory in another, general-purpose CPUs in a third – that opens up another possibility.
In today's systems, the ratio of CPU to XPU or GPU is fixed. Those ratios have to be determined when the system is built and deployed. But no two workloads need exactly the same ratio. Jensen actually mentioned this too – it means that at any given moment, some portion of the compute or memory in a computer might be underutilized for a specific workload, which is wasted cost. But once we disaggregate systems into separate compute pools and memory pools, and connect it all with optics, we can dynamically build dedicated systems in real time, optimized for any workload.
Imagine the data center of the future: a globally optically connected data infrastructure. Those rigid boundaries we have today, and the systems we have now, will start to disappear. Compute can be pooled, memory can be pooled, infrastructure can be dynamically composed at massive scale. For the first time, architects will be able to design AI systems around the needs of the model, not around the constraints of interconnect. That's where AI infrastructure is headed.
It's a distance-less data center, where compute, storage, networking, and photonics work together as a unified system, and the millions of resources inside a data center can work together as one machine. It's an architecture defined by workload needs, not by connectivity limits.
We believe this is the next era of computing infrastructure, and Marvell is helping build the connectivity foundation to make it possible.
Thank you very much for your time today.